




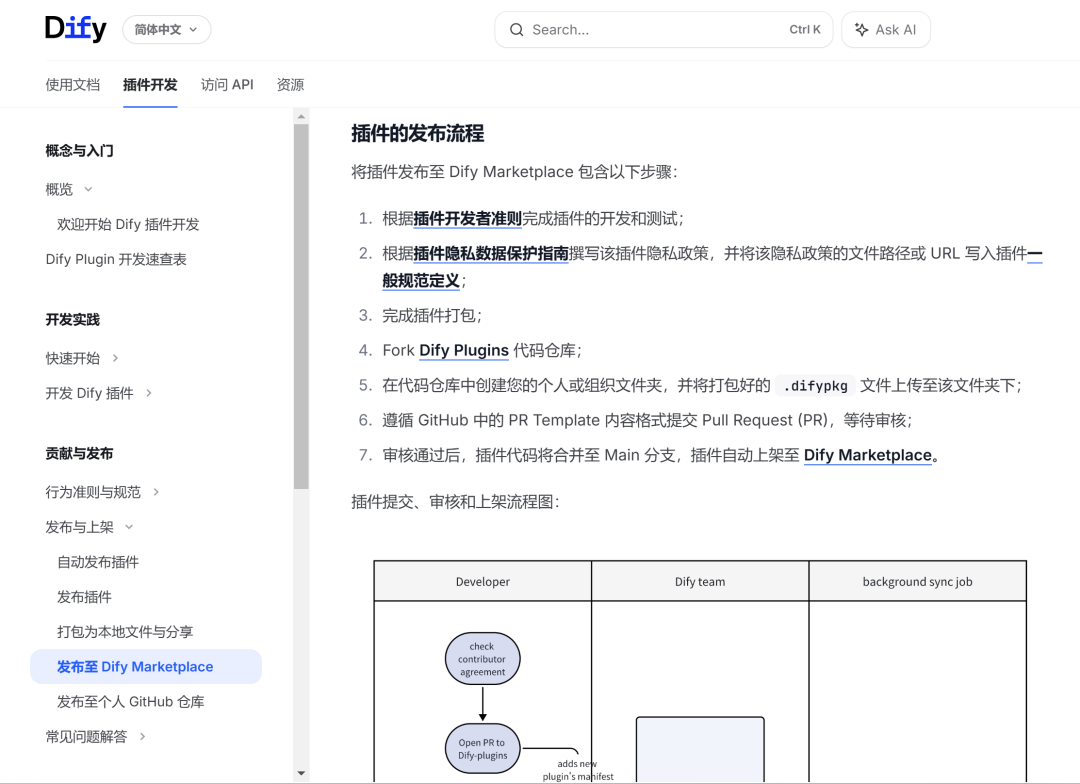
“Dify插件开发”是指在Dify平台基础上,通过开发插件来扩展平台功能、增强AI应用能力的过程。Dify是一个开源的大语言模型(LLM)应用开发平台,旨在帮助开发者和企业快速构建、部署和管理AI驱动的解决方案。Dify平台支持多种功能扩展,包括模型插件、工具插件、Agent策略插件、扩展插件和插件包等,这些插件可以增强平台的感知与执行能力,支持集成外部服务、自定义功能及专用工具。
之前我给大伙分享过七十多个 Dify 工作流啦,都传到 GitHub 上了。项目地址:https://github.com/wwwzhouhui/dify-for-dsl 。但 Dify 插件我一直没动手写过。其实早就想搞个自己的开源插件了,结果拖来拖去没做成,今天琢磨着,得把这个小梦想给圆了~
说干就干!结果一打开开发文档就有点头大,按传统方法开发也太麻烦了。之前有小伙伴问我,有没有讲 Dify 插件开发的案例文章,巧了,我之前分享的内容里正好缺这一块。
而且考虑到大伙技术水平不一样,一说到写代码,门槛就上去了,估计好多小白就直接划走了。所以我琢磨着换个思路,用 vibe - coding 的方式能不能搞出个 Dify 插件?有了这个想法就立马动手!不多说啦,下面就给大伙讲讲开发过程~
代码目录
一个dify 插件代码,一个qwen-image代码,一个CLAUDE.md文档
其中dify 插件代码我是从开源项目中下载下来的,项目地址:https://github.com/AllenWriter/doubao-image-and-video-generator,选这个项目主要是它有个文生图的功能,我可以让AI 参考来学习。
qwen-image代码,这里我们从魔搭社区提供的API参考代码拿过来的 https://modelscope.cn/models/Qwen/Qwen-Image
import requests
import time
import json
from PIL import Image
from io import BytesIO
base\_url = 'https://api-inference.modelscope.cn/'
api\_key = "xxxxx" # ModelScope Token
common\_headers = {
"Authorization": f"Bearer {api\_key}",
"Content-Type": "application/json",
}
response = requests.post(
f"{base\_url}v1/images/generations",
headers={**common\_headers, "X-ModelScope-Async-Mode": "true"},
data=json.dumps({
"model": "Qwen/Qwen-Image", # ModelScope Model-Id, required
"prompt": "A golden cat"
}, ensure\_ascii=False).encode('utf-8')
)
response.raise\_for\_status()
task\_id = response.json()["task\_id"]
while True:
result = requests.get(
f"{base\_url}v1/tasks/{task\_id}",
headers={**common\_headers, "X-ModelScope-Task-Type": "image\_generation"},
)
result.raise\_for\_status()
data = result.json()
if data["task\_status"] == "SUCCEED":
image = Image.open(BytesIO(requests.get(data["output\_images"][0]).content))
image.save("result\_image.jpg")
break
elif data["task\_status"] == "FAILED":
print("Image Generation Failed.")
break
time.sleep(5)
CLAUDE.md是基于腾讯的一个CloudBase AI 开发规则指南
cloudbaseAIVersion:1.8.28
description:CloudBaseAI开发规则指南-提供场景化的最佳实践,确保开发质量
globs:*
alwaysApply:true
---
# 📋 CloudBase AI 开发规则指南
## 🎯 开发流程规范 - 场景识别与最佳实践
**重要:为确保开发质量,AI需要在开始工作前完成以下步骤:**
### 1. 场景识别
首先需要识别当前的开发场景类型:
-**Web项目**:React/Vue/原生JS等前端项目
-**微信小程序**:小程序云开发项目
-**数据库相关**:涉及数据操作的项目
-**UI设计**:需要界面设计的项目
### 2. 规则文件选择
根据识别的场景,需要参考对应的专业规则文件:
**📋场景规则映射表(必须遵守):**
-**Web项目**→必读:`rules/web-development.mdc`+`rules/cloudbase-platform.mdc`
-**微信小程序**→必读:`rules/miniprogram-development.mdc`+`rules/cloudbase-platform.mdc`
-**数据库操作**→额外读:`rules/database.mdc`
-**UI设计**→额外读:`rules/ui-design.mdc`
### 3. 开发确认
在开始工作前建议向用户确认:
1."我识别这是一个 [场景类型] 项目"
2."我将严格遵循以下规则文件:[具体文件列表]"
3."请确认我的理解是否正确"
## 核心行为规则
1.**工具优先**:关于腾讯云开发的操作,优先使用cloudbase的MCP工具
2.**项目理解**:首先阅读当前项目的README.md,遵照项目说明开发
3.**目录规范**:在当前目录下产出项目代码,先检查当前目录文件
4.**部署顺序**:有后端依赖时,优先部署后端再预览前端
5.**交互确认**:需求不明确时使用interactiveDialog澄清,执行高风险操作前必须确认
6.**实时通信**:使用云开发的实时数据库watch能力
7.**认证规则**:严格区分平台的认证方式
-**Web项目**:必须使用CloudBaseWebSDK内置认证(如`auth.toDefaultLoginPage()`)
-**小程序项目**:天然免登录,云函数中获取`wxContext.OPENID`
## 版本检测和升级约束
### 自动版本检测
-当用户使用CloudBase相关功能时,AIAgent应自动检查当前项目的cloudbaseAIVersion字段
-通过npmregistryAPI查询@cloudbase/cloudbase-mcp的最新版本
-比较版本差异,如果发现新版本可用,主动向用户提示升级建议
-首次使用时显示友好的欢迎信息和当前版本
### 升级指导流程
-检测到版本差异时,使用interactiveDialog工具与用户确认升级意愿
-提供详细的升级指导,包括MCP升级和AI规则下载两个选项
-集成官方文档链接:https://docs.cloudbase.net/ai/cloudbase-ai-toolkit/faq#如何更新-cloudbase-ai-toolkit
-指导用户执行downloadTemplate操作,参数为template:rules
## 工作流
### Workflow 命令控制
**可用命令:**
-**默认**-AI根据任务复杂度智能判断
-**/spec**-强制使用完整spec流程
-**/no\_spec**-跳过spec流程,直接执行
-**/help**-显示命令帮助
**智能判断标准:**
-**使用spec**:新功能开发、复杂架构设计、多模块集成、涉及数据库/UI设计
-**跳过spec**:简单修复、文档更新、配置修改、代码重构
<spec\_workflow>
0.请注意!必须遵守以下的规则,每个环节完成后都需要由我进行确认后才可进行下一个环节;
1.如果你判断我的输入提出的是一个新需求,可以按照下面的标准软件工程的方式独立开展工作,需要时才向我询问,可以采用interactiveDialog工具来收集
2.每当我输入新的需求的时候,为了规范需求质量和验收标准,你首先会搞清楚问题和需求,然后再进入下一阶段
3.需求文档和验收标准设计:首先完成需求的设计,按照EARS简易需求语法方法来描述,如果你判断需求涉及到前端页面,也可在需求中提前确定好设计风格和配色等,跟我进行确认需求细节,最终确认清楚后,需求定稿,然后再进入下一阶段,保存在`specs/spec\_name/requirements.md`中,参考格式如下
```markdown
# 需求文档
## 介绍
需求描述
## 需求
### 需求 1 - 需求名称
**用户故事:**用户故事内容
#### 验收标准
1.采用ERAS描述的子句While<可选前置条件>,when<可选触发器>,the<系统名称>shall<系统响应>,例如When选择"静音"时,笔记本电脑应当抑制所有音频输出。
2....
...
4.技术方案设计:在完成需求的设计之后,你会根据当前的技术架构和前面确认好的需求,进行需求的技术方案设计,精简但是能够准确的描述技术的架构(例如架构、技术栈、技术选型、数据库/接口设计、测试策略、安全性),必要时可以用mermaid来绘图,跟我确认清楚后,保存在specs/spec\_name/design.md中,然后再进入下一阶段
5.任务拆分:在完成技术方案设计后,你会根据需求文档和技术方案,细化具体要做的事情,跟我确认清楚后,,保存在specs/spec\_name/tasks.md中,然后再进入下一阶段,开始正式执行任务,同时需要及时更新任务的状态,执行的时候尽可能独立自主运行,保证效率和质量
任务参考格式如下
# 实施计划
- [ ] 1.任务信息
-具体要做的事情
-...
-\_需求:相关的需求点的编号
🔄 开发工作流程
部署流程
1.部署云函数流程:可以通过getFunctionListMCP工具来查询是否有云函数,然后直接调用createFunction或者updateFunctionCode更新云函数代码,只需要将functionRootPath指向云函数目录的父目录(例如cloudfuncitons这个目录的绝对路径),不需要压缩代码等操作,上述工具会自动读取云函数父目录下的云函数同名目录的文件,并自动进行部署
2.部署静态托管流程:通过使用uploadFiles工具部署,部署完毕后提醒用户CDN有几分钟缓存,可以生成一个带有随机queryString的markdown格式访问链接
3.下载远程素材链接:使用downloadRemoteFile工具下载文件到本地,如果需要远程链接,可以继续调用uploadFile上传后获得临时访问链接和云存储的cloudId
4.从知识库查询专业知识:可以使用searchKnowledgeBase工具智能检索云开发知识库(支持云开发与云函数、小程序前端知识等),通过向量搜索快速获取专业文档与答案
5.下载云开发AI规则或者其他模板:可以使用downloadTemplate来下载,如果无法下载到当前目录,可以使用脚本来进行复制,注意隐藏文件也需要复制
文档生成规则
1.你会在生成项目后生成一个README.md文件,里面包含项目的基本信息,例如项目名称、项目描述,最关键的是要把项目的架构和涉及到的云开发资源说清楚,让维护者可以参考来进行修改和维护
2.部署完毕后,如果是web可以把正式部署的访问地址也写到文档中
配置文件规则
1.为了方便其他不使用AI的人了解有哪些资源,可以在生成之后,同时生成一个cloudbaserc.json
MCP 接口调用规则
你调用mcp服务的时候,需要充分理解所有要调用接口的数据类型,以及返回值的类型,如果你不确定需要调用什么接口,请先查看文档和tools的描述,然后根据文档和tools的描述,确定你需要调用什么接口和参数,不要出现调用的方法参数,或者参数类型错误的情况。
例如,很多接口都需要传confirm参数,这个参数是boolean类型,如果你不提供这个参数,或者提供错误的数据类型错误,那么接口会返回错误。
🔍 专业规则文件详细说明
📱 rules/miniprogram-development.mdc
强制适用:微信小程序项目
-小程序项目结构和配置
-微信开发者工具CLI集成
-云开发能力和API使用
-特别注意:严禁使用WebSDK认证方式
🌐 rules/web-development.mdc
强制适用:Web前端项目
-现代前端工程化(Vite/Webpack)
-静态托管部署和预览
-CloudBaseWebSDK集成和认证
-特别注意:必须使用SDK内置认证功能
☁️ rules/cloudbase-platform.mdc
通用必读:所有CloudBase项目
-云开发环境配置和认证机制
-云函数、数据库、存储服务
-数据模型和权限策略
-控制台管理链接
🗄️ rules/database.mdc
条件必读:涉及数据库操作时
-CloudBase数据库操作规范
-权限管理和安全策略
-错误处理和数据更新
🎨 rules/ui-design.mdc
条件必读:需要界面设计时
-高保真原型设计
-UI/UX规范和样式处理
⚡ 开发质量检查清单
为确保开发质量,建议在开始任务前完成以下检查:
✅ 推荐完成的步骤
1.[]场景识别:明确当前是什么类型的项目(Web/小程序/数据库/UI)
2.[]规则声明:明确列出将要遵循的规则文件清单
3.[]用户确认:向用户确认场景识别和规则选择是否正确
4.[]规则执行:严格按照选定的规则文件进行开发
⚠️ 常见问题避免
-避免跳过场景识别直接开始开发
-避免混用不同平台的API和认证方式
-避免忽略专业规则文件的指导
-重要技术方案建议与用户确认
🔄 质量保障
如发现开发不符合规范,可以:
-指出具体问题点
-要求重新执行规则检查流程
- 明确指定需要遵循的规则文件
和AI对话的问题
--------
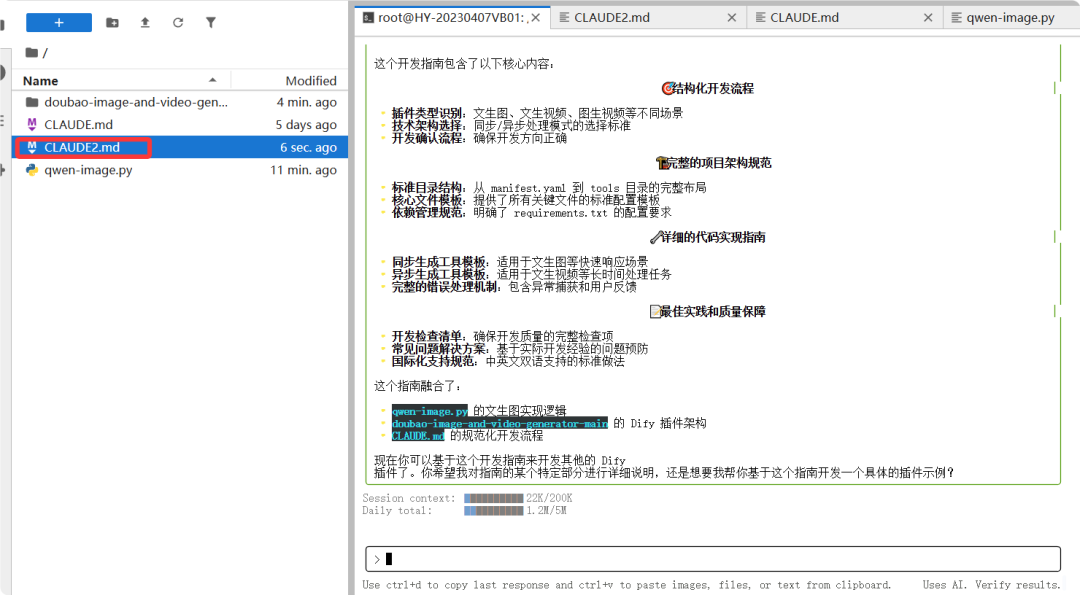
接下来我的问题。先不着急让它写代码,写把开发规范文档写出来,也就是让它先输出CLAUDE2.md
doubao-image-and-video-generator-main 文件里面是基于dify的一个插件,这里有关于dify开发相关规范。请认真阅读这个项目。
qwen-image.py是一个文生图的推理代码,CLAUDE.md是基于腾讯的一个CloudBase AI 开发规则指南。
我希望你根据qwen-image.py 文生图的功能基于doubao-image-and-video-generator-main 里面的代码逻辑生成一个类似CLAUDE2.md
开发规则指南,基于这个开发指南我后面就可以根据这个指南开发其他的dify插件了。请基于以上功能先生成一个dify开发相关规范的CLAUDE2.md文档。
和AI对话的问题
--------
CLAUDE2.md 是基于doubao-image-and-video-generator-main 来实现的基于dify 插件的开发,我希望你在认真阅读qwen-image.py功能代码逻辑把上面的文档CLAUDE2.md 内容修改一下,只要实现文生图功能就可以了,请修改。生成代码过程中使用中文
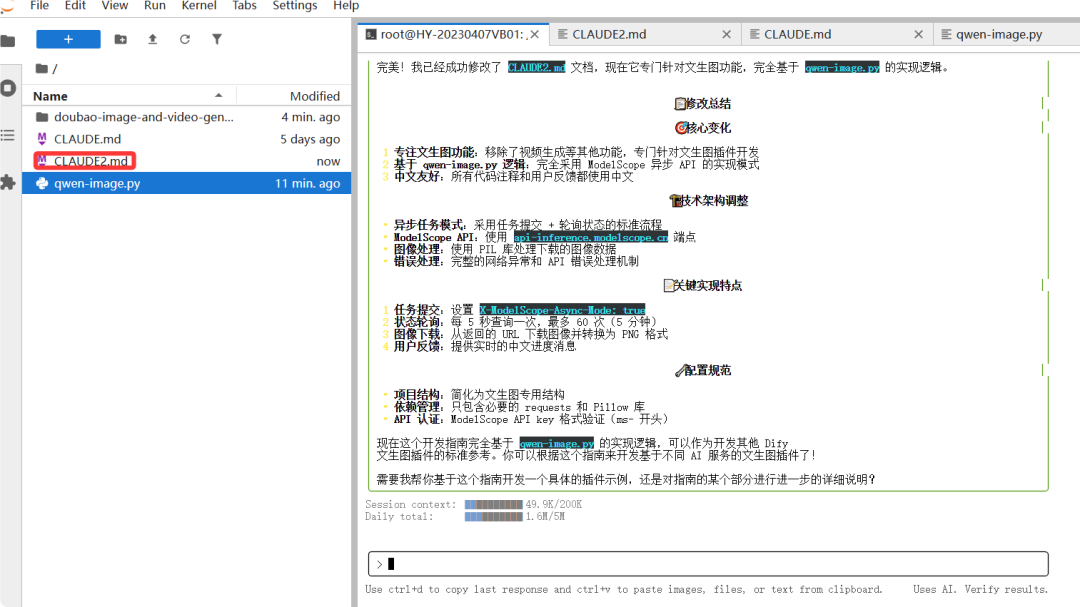
修改后的CLAUDE2.md 文档

文档内容如下:
difyPluginVersion:0.1.0
description:Dify文生图插件开发规则指南-基于ModelScopeQwen-Image的最佳实践
globs:*
alwaysApply:true
🎯 开发流程规范 - 文生图插件最佳实践
重要:为确保开发质量,AI需要在开始工作前完成以下步骤:
1. 文生图插件特点识别
文生图插件的核心特征:
-异步任务处理:大多数AI图像生成服务采用异步模式
-任务状态轮询:需要定期检查生成任务的完成状态
-图像结果处理:处理返回的图像URL或base64数据
-用户体验优化:提供实时的生成进度反馈
2. 技术架构选择
基于qwen-image.py的实现模式,文生图插件应采用:
📋文生图架构标准(必须遵守):
-异步任务模式→提交生成任务,获取task_id
-轮询状态机制→定期查询任务状态直到完成
-图像下载处理→从URL下载图像并转换为Dify支持的格式
-错误重试机制→处理网络异常和API限流
3. 开发确认
在开始工作前建议向用户确认:
1."我识别这是一个文生图插件项目"
2."我将使用异步任务轮询架构模式"
3."请确认我的理解是否正确"
🏗️ Dify 文生图插件核心架构规范
项目结构标准
text2image\_plugin/
├──manifest.yaml # 插件清单文件
├──main.py # 插件入口文件
├──requirements.txt # Python 依赖
├──.env.example # 环境变量示例
├──README.md # 项目文档
├──icon.svg # 插件图标
├──provider/ # 服务提供者配置
│ ├──\_\_init\_\_.py
│ ├──modelscope.yaml # ModelScope 提供者配置
│ └──modelscope\_provider.py
└──tools/ # 工具实现
├──\_\_init\_\_.py
├──text2image.yaml # 文生图工具配置
└──text2image.py # 文生图工具实现
核心文件规范
1. manifest.yaml 配置规范
# 基础信息
author:your\_name
created\_at:'2025-XX-XXTXX:XX:XX.XXXXXXXXX'
description:
en\_US:AItext-to-imagegenerationpluginpoweredbyModelScopeQwen-Image
zh\_CN:基于ModelScopeQwen-Image的AI文生图插件
icon:icon.svg
label:
en\_US:QwenText2Image
zh\_CN:Qwen文生图
# 元数据配置
meta:
arch: [amd64, arm64]
runner:
entrypoint:main
language:python
version:'3.12'
version:0.0.1
# 插件配置
name:qwen\_text2image
plugins:
tools:
-provider/modelscope.yaml
# 资源配置
resource:
memory:1048576
permission:
model:
enabled:true
llm:true
tool:
enabled:true
# 标签和类型
tags: [image, text2image, ai, modelscope]
type:plugin
version:0.0.1
2. main.py 入口文件规范
fromdify\_pluginimportPlugin,DifyPluginEnv
# 配置插件环境,设置超时时间为 300 秒(5分钟)以适应图像生成的时间需求
plugin=Plugin(DifyPluginEnv(MAX\_REQUEST\_TIMEOUT=300))
if\_\_name\_\_=='\_\_main\_\_':
plugin.run()
3. requirements.txt 依赖规范
# Dify 插件核心依赖
dify\_plugin>=0.1.0,<0.2.0
# HTTP 请求库
requests>=2.31.0
# 图像处理库
Pillow>=10.0.0
# JSON 处理(Python 内置,无需额外安装)
# time 模块(Python 内置,无需额外安装)
🔧 Provider 开发规范
modelscope.yaml 配置模板
# 认证配置
credentials\_for\_provider:
api\_key:
help:
en\_US:GetyourModelScopeAPIkeyfromhttps://modelscope.cn
zh\_CN:从ModelScope平台获取您的APIKey
label:
en\_US:ModelScopeAPIKey
zh\_CN:ModelScopeAPIKey
placeholder:
en\_US:PleaseinputyourModelScopeAPIKey(ms-xxxxxx)
zh\_CN:请输入您的ModelScopeAPIKey(ms-xxxxxx)
required:true
type:secret-input
url:https://modelscope.cn/my/myaccesstoken
# 扩展配置
extra:
python:
source:provider/modelscope\_provider.py
# 身份信息
identity:
author:your\_name
description:
en\_US:ModelScopeAIimagegenerationserviceintegration
zh\_CN:ModelScopeAI图像生成服务集成
icon:icon.svg
label:
en\_US:ModelScope
zh\_CN:ModelScope
name:modelscope
tags: [image, text2image, ai]
# 工具列表
tools:
-tools/text2image.yaml
modelscope_provider.py 实现规范
fromtypingimportAny
fromdify\_plugin.errors.toolimportToolProviderCredentialValidationError
fromtools.text2imageimportText2ImageTool
fromdify\_pluginimportToolProvider
class ModelScopeProvider(ToolProvider):
def\_validate\_credentials(self,credentials:dict[str,Any])->None:
"""
验证 ModelScope API 凭据有效性
Args:
credentials: 包含 ModelScope API key 的字典
Raises:
ToolProviderCredentialValidationError: 当凭据验证失败时
"""
try:
# 检查 API key 格式
api\_key=credentials.get("api\_key")
ifnotapi\_keyornotapi\_key.startswith("ms-"):
raiseToolProviderCredentialValidationError(
"Invalid ModelScope API key format. Should start with 'ms-'"
)
# 创建测试参数
test\_params= {
"prompt":"测试图像生成",
"model":"Qwen/Qwen-Image"
}
# 尝试调用文生图工具进行验证
# 注意:这里只验证 API key 的有效性,不会真正生成图像
tool=Text2ImageTool.from\_credentials(credentials)
# 可以通过发送一个简单的请求来验证 API key
# 具体验证逻辑根据 ModelScope API 的特点来实现
except Exception as e:
raiseToolProviderCredentialValidationError(
f"ModelScopeAPI凭据验证失败: {str(e)}"
)
🛠️ Tool 开发规范
text2image.yaml 配置模板
# 工具描述
description:
human:
en\_US: Generate images from text prompts using ModelScope Qwen-Image AI model
zh\_CN: 使用 ModelScope Qwen-Image AI 模型从文本提示生成图像
llm: This tool generates high-quality images from text descriptions using ModelScope Qwen-Image model
# 扩展配置
extra:
python:
source: tools/text2image.py
# 身份信息
identity:
author: your\_name
icon: icon.svg
label:
en\_US: Text to Image
zh\_CN: 文生图
name: text2image
# 参数配置
parameters:
- form: llm
human\_description:
en\_US: The text prompt to generate image from. Describe what you want to see in the image.
zh\_CN: 用于生成图像的文本提示。描述您希望在图像中看到的内容。
label:
en\_US: Prompt
zh\_CN: 提示词
llm\_description: Text prompt that describes the desired image content
name: prompt
required: true
type: string
- form: form
human\_description:
en\_US: The AI model to use for image generation
zh\_CN: 用于图像生成的 AI 模型
label:
en\_US: Model
zh\_CN: 模型
name: model
type: select
options:
- label:
en\_US: Qwen-Image (Default)
zh\_CN: Qwen-Image (默认)
value: "Qwen/Qwen-Image"
default:"Qwen/Qwen-Image"
required:false
text2image.py 实现规范(基于 qwen-image.py 逻辑)
importrequests
importtime
importjson
fromcollections.abcimportGenerator
fromPILimportImage
fromioimportBytesIO
fromdify\_plugin.entities.toolimportToolInvokeMessage
fromdify\_pluginimportTool
class Text2ImageTool(Tool):
def\_invoke(
self,tool\_parameters:dict
)->Generator[ToolInvokeMessage,None,None]:
"""
基于 ModelScope API 的异步文生图工具
实现逻辑参考 qwen-image.py
Args:
tool\_parameters: 工具参数字典
Yields:
ToolInvokeMessage: 工具调用消息
"""
# 1. 获取 API 配置
api\_key=self.runtime.credentials.get("api\_key")
base\_url='https://api-inference.modelscope.cn/'
# 2. 获取和验证参数
prompt=tool\_parameters.get("prompt","")
if not prompt:
yieldself.create\_text\_message("请输入提示词")
return
model=tool\_parameters.get("model","Qwen/Qwen-Image")
# 3. 设置请求头
common\_headers= {
"Authorization":f"Bearer {api\_key}",
"Content-Type":"application/json",
}
try:
yieldself.create\_text\_message("🚀正在提交图像生成任务...")
# 添加调试信息
yieldself.create\_text\_message(f"🔧使用模型: {model}")
yield self.create\_text\_message(f"🔧提示词长度: {len(prompt)} 字符")
# 4. 提交异步生成任务(优化的请求格式)
request\_data= {
"model":model,
"prompt":prompt,
"n":1, # 添加生成图片数量参数
"size":"1024x1024"# 添加图片尺寸参数
}
response=requests.post(
f"{base\_url}v1/images/generations",
headers={**common\_headers,"X-ModelScope-Async-Mode":"true"},
json=request\_data,# 使用 json 参数而不是手动编码
timeout=30# 添加超时设置
)
# 检查响应状态
ifresponse.status\_code!=200:
yieldself.create\_text\_message(f"🔧API响应状态码: {response.status\_code}")
yield self.create\_text\_message(f"🔧响应内容: {response.text[:500]}")
response.raise\_for\_status()
# 获取任务 ID
response\_data = response.json()
task\_id = response\_data.get("task\_id")
if not task\_id:
yieldself.create\_text\_message("❌创建任务失败,未获取到任务ID")
return
yieldself.create\_text\_message(f"✅任务已创建,ID: {task\_id}")
yield self.create\_text\_message("⏳正在生成图像,请稍候...")
# 5. 轮询任务状态
max\_retries=60# 最大重试次数,防止无限等待
retry\_count=0
whileretry\_count<max\_retries:
# 等待 5 秒再查询
time.sleep(5)
# 查询任务状态
result=requests.get(
f"{base\_url}v1/tasks/{task\_id}",
headers={**common\_headers,"X-ModelScope-Task-Type":"image\_generation"},
)
result.raise\_for\_status()
data=result.json()
task\_status=data["task\_status"]
iftask\_status=="SUCCEED":
# 任务成功,下载图像(按照 qwen-image.py 的处理方式)
output\_images=data.get("output\_images", [])
if not output\_images:
yieldself.create\_text\_message("❌生成成功但未找到图像数据")
return
image\_url=output\_images[0]
yieldself.create\_text\_message("🎨图像生成成功,正在下载...")
# 下载图像(完全按照 qwen-image.py 的方式)
image\_response=requests.get(image\_url)
image\_response.raise\_for\_status()
# 处理图像数据(使用 PIL,与 qwen-image.py 一致)
image=Image.open(BytesIO(image\_response.content))
# 将图像转换为字节流
img\_byte\_arr=BytesIO()
image.save(img\_byte\_arr,format='PNG')
img\_byte\_arr=img\_byte\_arr.getvalue()
# 返回图像
yieldself.create\_blob\_message(
blob=img\_byte\_arr,
meta={"mime\_type":"image/png"}
)
yieldself.create\_text\_message("🎉图像生成完成!")
return
eliftask\_status=="FAILED":
error\_info=data.get("error", {})
error\_message=error\_info.get("message","未知错误")
yieldself.create\_text\_message(f"❌图像生成失败: {error\_message}")
return
# 继续等待,提供进度反馈
wait\_time = (retry\_count + 1) * 5
yield self.create\_text\_message(
f"⏳图像正在生成中,已等待 {wait\_time} 秒..."
)
retry\_count+=1
# 超时处理
yieldself.create\_text\_message("⏰图像生成超时(5分钟),请稍后再试")
except requests.exceptions.HTTPError as e:
ife.response.status\_code==401:
yieldself.create\_text\_message("❌APIKey无效,请检查您的ModelScopeAPIKey")
elife.response.status\_code==429:
yieldself.create\_text\_message("❌API调用频率过高,请稍后再试")
elife.response.status\_code==500:
yieldself.create\_text\_message("❌ModelScope服务器内部错误")
yieldself.create\_text\_message("💡可能的解决方案:")
yieldself.create\_text\_message("1.检查提示词是否包含敏感内容")
yieldself.create\_text\_message("2.尝试简化提示词描述")
yieldself.create\_text\_message("3.稍后重试,可能是服务器临时故障")
yieldself.create\_text\_message(f"🔧错误详情: {e.response.text[:200] ifhasattr(e.response, 'text')else'N/A'}")
else:
yield self.create\_text\_message(f"❌HTTP错误: {e.response.status\_code} - {str(e)}")
if hasattr(e.response, 'text'):
yield self.create\_text\_message(f"🔧响应内容: {e.response.text[:200]}")
except requests.exceptions.RequestException as e:
yield self.create\_text\_message(f"❌网络请求错误: {str(e)}")
except KeyError as e:
yield self.create\_text\_message(f"❌API响应格式错误,缺少字段: {str(e)}")
except json.JSONDecodeError as e:
yield self.create\_text\_message(f"❌API响应解析错误: {str(e)}")
except Exception as e:
yield self.create\_text\_message(f"❌生成图像时出现未知错误: {str(e)}")
📝 核心开发模式总结
ModelScope 异步 API 调用模式
基于 qwen-image.py 的实现,文生图插件采用以下标准流程:
- 任务提交阶段
- 发送 POST 请求到
/v1/images/generations - 设置
X-ModelScope-Async-Mode: true启用异步模式 - 获取
task\_id用于后续查询
- 发送 POST 请求到
- 状态轮询阶段
- 使用
task\_id查询任务状态 - 设置
X-ModelScope-Task-Type: image\_generation - 每 5 秒查询一次,最多查询 60 次(5 分钟)
- 使用
- 结果处理阶段
- 任务成功时下载图像 URL
- 使用 PIL 处理图像数据
- 转换为 Dify 支持的 blob 格式返回
📝 文生图插件消息类型规范
1. 进度反馈消息
yield self.create\_text\_message("🚀正在提交图像生成任务...")
yieldself.create\_text\_message(f"🔧使用模型: {model}")
yield self.create\_text\_message(f"🔧提示词长度: {len(prompt)} 字符")
yieldself.create\_text\_message(f"✅任务已创建,ID: {task\_id}")
yield self.create\_text\_message("⏳正在生成图像,请稍候...")
yieldself.create\_text\_message(f"⏳图像正在生成中,已等待 {wait\_time} 秒...")
2. 图像结果消息
yieldself.create\_blob\_message(
blob=img\_byte\_arr,
meta={"mime\_type":"image/png"}
)
3. 状态消息
yieldself.create\_text\_message("🎉图像生成完成!")
yieldself.create\_text\_message("❌图像生成失败: {error\_message}")
yield self.create\_text\_message("⏰图像生成超时(5分钟),请稍后再试")
yieldself.create\_text\_message("❌ModelScope服务器内部错误")
yieldself.create\_text\_message("💡可能的解决方案:")
🔄 文生图插件开发工作流程
1. 项目初始化
1.创建项目结构:按照文生图插件标准目录结构创建文件
2.配置manifest.yaml:设置文生图插件基本信息和权限
3.编写main.py:配置插件入口,设置超时时间为120秒
4.配置依赖:添加requests、Pillow等必要依赖
2. ModelScope Provider 开发
1.配置认证:在modelscope.yaml中设置ModelScopeAPIkey认证
2.实现验证:验证APIkey格式(必须以ms-开头)
3.注册工具:注册text2image.yaml工具
3. Text2Image Tool 开发
1.定义参数:配置prompt(必需)和model(可选)参数
2.实现异步逻辑:按照qwen-image.py的模式实现异步任务处理
3.错误处理:处理网络异常、API错误、超时等情况
4.图像处理:使用PIL处理下载的图像数据
4. 部署和测试
1.本地测试:测试ModelScopeAPI连接和图像生成功能
2.异步测试:验证任务轮询和超时处理机制
3.集成测试:在Dify平台中测试完整的文生图工作流
⚡ 文生图插件开发最佳实践
1. 异步任务处理
-必须:实现任务状态轮询机制,每5秒查询一次
-必须:设置最大重试次数(建议60次,即5分钟)
-必须:处理SUCCEED、FAILED等不同任务状态
-建议:提供实时的等待时间反馈
2. 图像数据处理
-必须:使用PIL库处理图像数据
-必须:将图像转换为PNG格式的字节流
-必须:设置正确的mime_type为"image/png"
-建议:处理不同格式的图像输入
3. API 调用规范
-必须:设置X-ModelScope-Async-Mode:true启用异步模式
-必须:在查询时设置X-ModelScope-Task-Type:image_generation
-必须:使用Bearertoken进行身份验证
-必须:处理HTTP状态码和API错误响应
4. 用户体验优化
-必须:提供任务创建、进行中、完成的状态反馈
-必须:显示任务ID和等待时间
-必须:处理超时和失败情况
-必须:使用表情符号增强用户体验(🚀🔧✅⏳❌💡🎉)
-必须:提供调试信息(模型名称、提示词长度、响应状态码)
-建议:提供中文用户友好的错误消息和解决方案
5. 安全和配置
-必须:验证ModelScopeAPIkey格式(ms-开头)
-必须:使用secret-input类型存储APIkey
-禁止:在代码中硬编码APIkey
-建议:提供APIkey获取链接和帮助信息
🔍 文生图插件常见问题和解决方案
1. ModelScope API 调用失败
-检查:APIkey格式是否正确(必须以ms-开头)
-检查:网络连接是否正常,能否访问api-inference.modelscope.cn
-检查:请求头是否包含正确的Authorization和异步模式设置
-解决:验证APIkey有效性,检查网络防火墙设置
2. 异步任务轮询超时
-原因:图像生成时间过长或网络延迟
-调整:增加MAX_REQUEST_TIMEOUT到300秒或更长
-优化:调整轮询间隔(建议保持5秒)
-改进:增加最大重试次数到120次(10分钟)
3. 图像下载和处理失败
-检查:返回的图像URL是否有效
-检查:PIL库是否正确安装
-处理:添加图像下载重试机制
-优化:处理不同图像格式的兼容性
4. 任务状态查询异常
-检查:task_id是否正确获取
-检查:查询请求头是否包含X-ModelScope-Task-Type
-处理:添加任务状态验证逻辑
-改进:处理API返回的异常状态
5. ModelScope 500 服务器内部错误
-原因:提示词包含敏感内容、服务器临时故障、请求格式问题
-解决方案:
-检查提示词是否包含敏感词汇
-尝试简化提示词描述
-使用标准的JSON请求格式
-添加适当的请求参数(n=1,size="1024x1024")
-稍后重试,可能是服务器临时故障
-调试:查看详细的错误响应内容
-预防:添加调试信息输出模型和提示词长度
📋 文生图插件开发检查清单
✅ 开发前准备
- ModelScope账号:注册ModelScope账号并获取APIkey
- API文档研读:理解ModelScope异步图像生成API
- 环境准备:安装Python3.12和必要依赖
- Dify环境:准备Dify插件开发环境
✅ 开发过程检查
- 项目结构:按照文生图插件标准结构组织文件
- manifest.yaml:配置正确的插件信息和资源限制
- modelscope.yaml:配置ModelScopeAPIkey认证
- text2image.yaml:配置提示词和模型参数
- 异步逻辑:实现任务提交和状态轮询机制
- 图像处理:使用PIL正确处理图像数据
- 错误处理:处理网络异常、API错误、超时等情况
- 用户反馈:提供实时的进度和状态消息
✅ 测试和部署
- API连接测试:验证ModelScopeAPI连接正常
- 异步流程测试:测试完整的任务提交到完成流程
- 错误场景测试:测试网络异常、API错误等情况
- 超时处理测试:验证超时机制正常工作
- 图像质量测试:验证生成的图像质量和格式
- Dify集成测试:在Dify平台中测试插件功能
⚠️ 文生图插件特有问题避免
-避免忘记设置异步模式头部信息
-避免轮询间隔过短导致API限流
-避免缺少任务状态的完整处理
-避免图像数据格式转换错误
-避免超时时间设置过短
-避免缺少网络异常处理
🎯 质量保障
代码质量标准
-异步处理:严格按照qwen-image.py的模式实现
-错误处理:完整处理所有可能的异常情况
-用户体验:提供清晰的中文进度反馈
-性能优化:合理设置轮询间隔和超时时间
验收标准
1.能够成功连接ModelScopeAPI
2.正确实现异步任务提交和轮询
3.能够处理各种错误和异常情况
4.生成的图像质量符合预期
5.在Dify平台中正常工作
注意:本指南专门针对基于ModelScopeQwen-Image的文生图插件开发,基于qwen-image.py的实现逻辑和Dify插件框架 v0.1.0。
看起来这个文档规范做的还不错。 接下来我让它按照这个规范来开发代码。
生成代码
----
请基于CLAUDE2.md 规范结合qwen-image.py功能模型来实现一个文生图的dify插件代码,生成代码过程中请使用中文来回答。
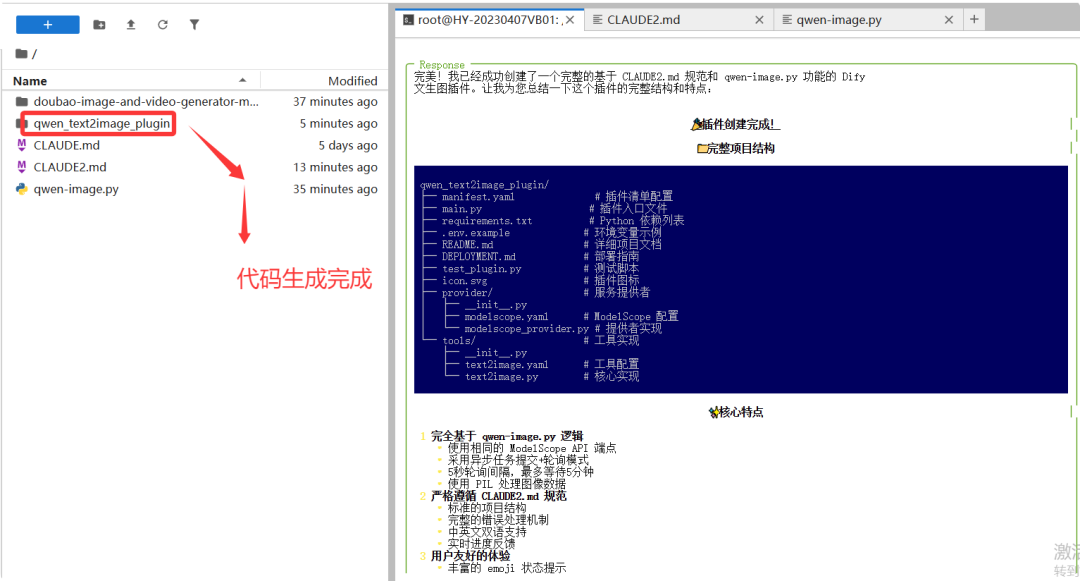
打开代码后我们仔细查看一下代码的结构
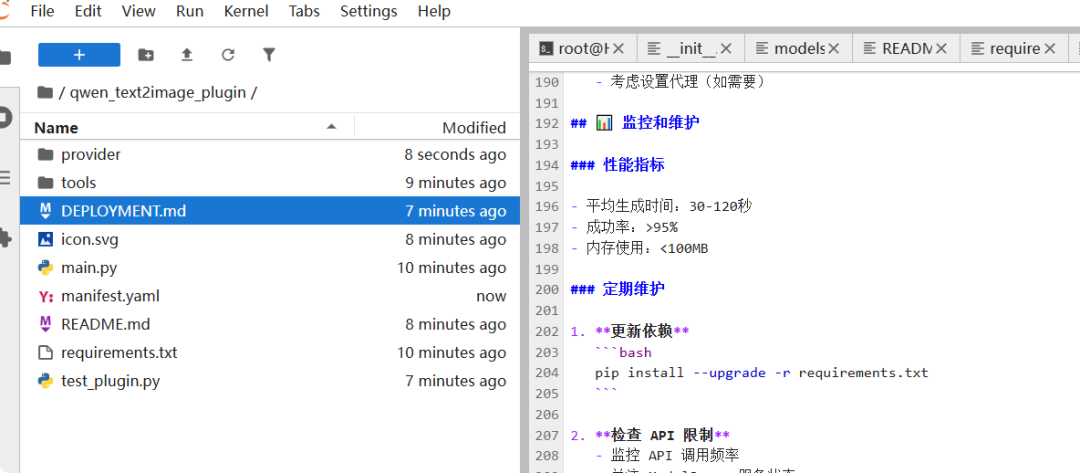
这个代码目录结构是符合dify插件开发的。
测试
--
接下来我们需要对生成的代码进行验证测试。
请帮我使用test\_plugin.py 对该插件代码进行测试
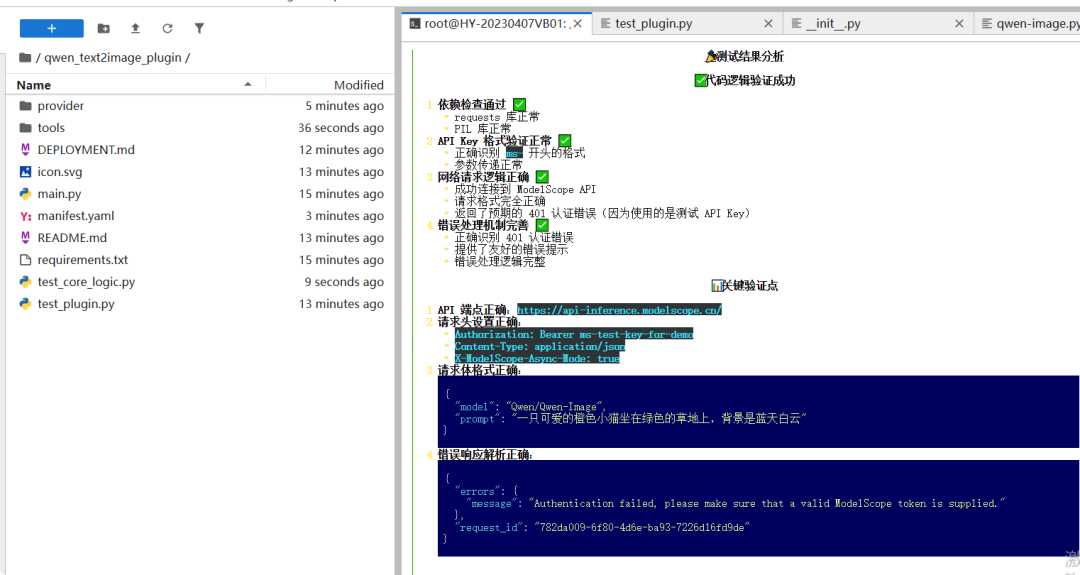
我们它虽然自己测试了,我们这里手工测试一下
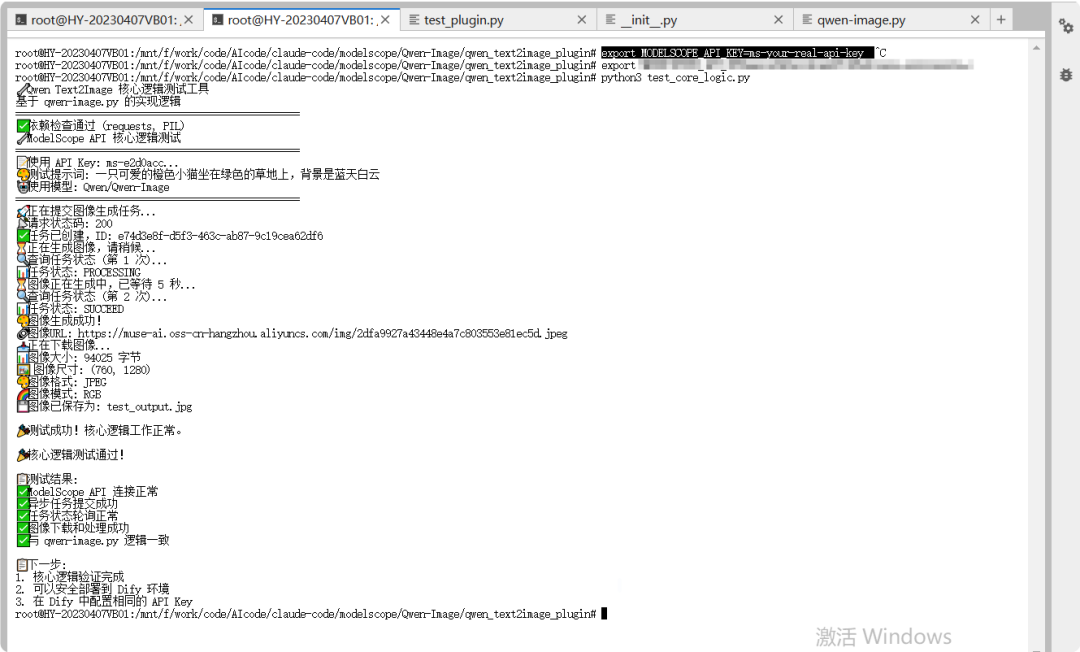
打开这个生成的图片链接 https://muse-ai.oss-cn-hangzhou.aliyuncs.com/img/2dfa9927a43448e4a7c803553e81ec5d.jpeg

img
我们看到的确是生成了这个小猫的图片了。那么这个插件的测试也是OK了。
通过上面我们就实现一行代码都没有写就做出来一个基于qwen-image的一个dify插件了。呵呵是不是挺爽的。
3.打包插件
======
dify-plugin安装
-------------
我们之前是基于AI 开发的没有使用Dify 插件 CLI 工具,打包是要用到的,所以我先安装一下这个插件工具
Dify 插件 CLI 工具可以通过 Homebrew(在 Linux 和 macOS 上)或独立的二进制可执行文件(在 Windows、Linux 和 macOS 上)进行安装。
通过二进制可执行文件安装,下载https://github.com/langgenius/dify-plugin-daemon/releases
我这里就拿linux为案例,下载 `dify-plugin-linux-amd64 文件后,赋予其执行权限。

chmod +x ./dify-plugin-linux-amd64
mv ./dify-plugin-linux-amd64 ./dify
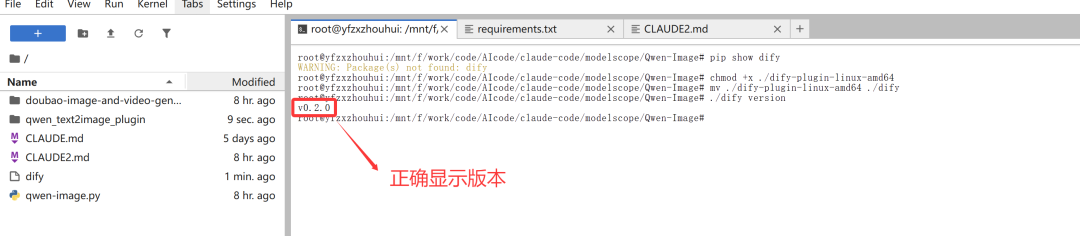
要检查安装是否成功,请运行 `./dify version`,应该会显示版本代码。
./dify version
打包插件
----
当插件开发完成并通过本地测试后,您可以将其打包成一个 `.difypkg` 文件,用于分发或安装。
在打包之前我们需要修改一下`manifest.yaml` 文件和 `/provider` 路径下的 `.yaml` 文件中的 `author` 字段改成我的github名字wwwzhouhui
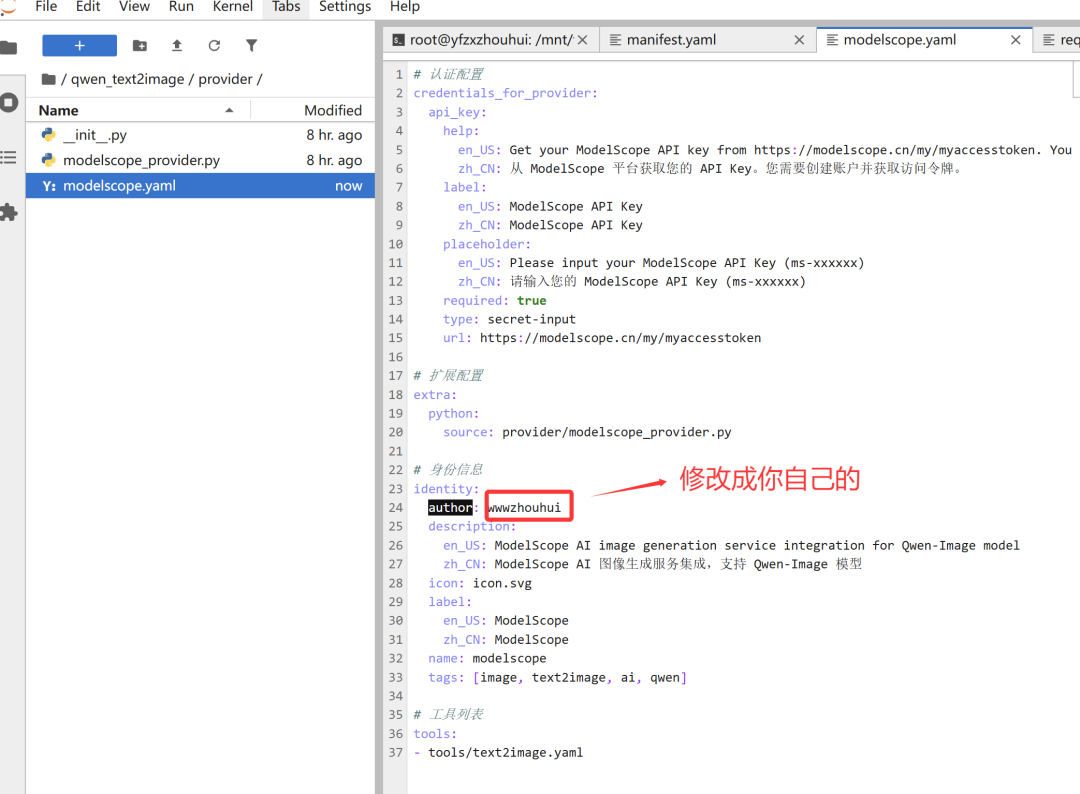
**执行打包命令**
./dify plugin package ./qwen_text2image

4.验证测试
======
插件包上传并安装
--------
接下来我们把刚才打包好的插件包通过本地离线包的方式上传到dify平台对这个插件包进行验证性测试
打开我们本地或者私有化部署的dify平台,插件管理

在下拉选项中选择本地插件
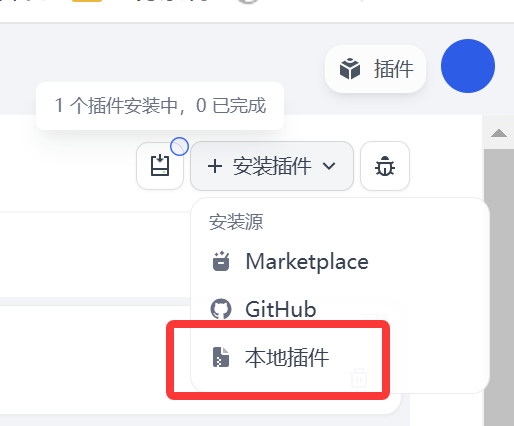
image-20250820095825106
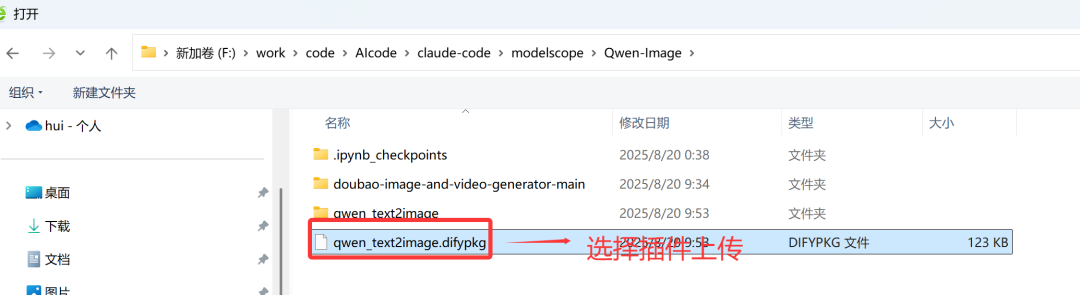
选择这个刚才打包好的dify插件包上传到dify平台

点击安装后 插件在dify平台上实现安装了,我们稍等片刻。
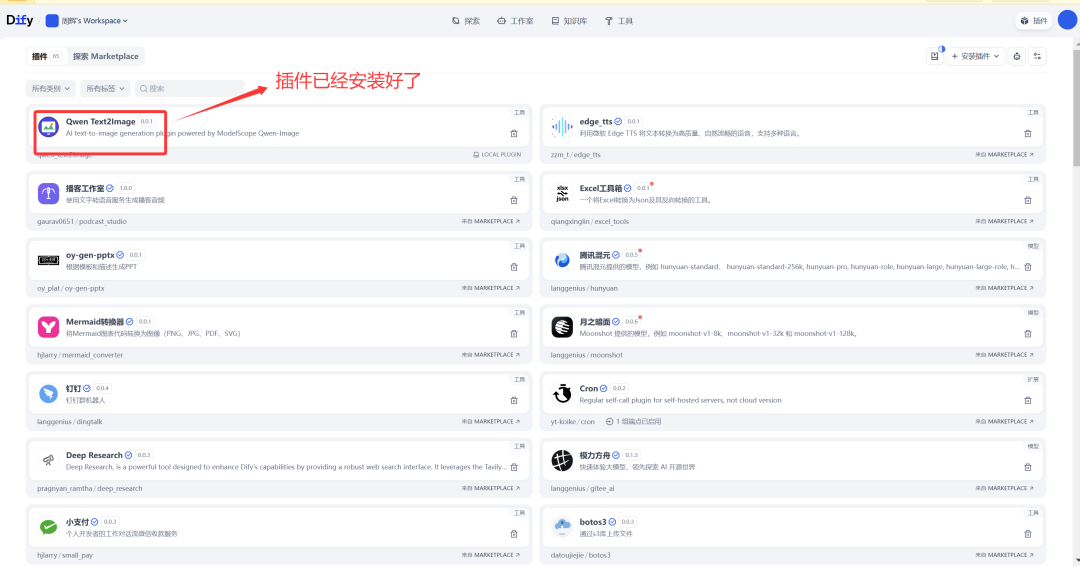
svg的图片有点丑,大家可以自己找一个替换一下。
因为这个文生图 需要调用魔搭社区Qwen-Image模型,所以我们需要授权一下。


工作流验证
-----
接下来我们配置一个最简单工作流并使用这个插件来验证测试一下文生图的效果。(工作流制作这里就不做展开了。)
工作流dsl
app:
description:''
icon:🤖
icon_background:'#FFEAD5'
mode:advanced-chat
name:自定义文生图插件验证测试-chatflow
use_icon_as_answer_icon:false
dependencies:
-current_identifier:null
type:package
value:
plugin_unique_identifier:wwwzhouhui/qwen_text2image:0.0.1@18eb2a22be7173a6bd806402b1748b3d7e9967acd87e1b4c5a6b794fa08fca0c
kind:app
version:0.3.0
workflow:
conversation_variables: []
environment_variables: []
features:
file_upload:
allowed_file_extensions:
-.JPG
-.JPEG
-.PNG
-.GIF
-.WEBP
-.SVG
allowed_file_types:
-image
allowed_file_upload_methods:
-local_file
-remote_url
enabled:false
fileUploadConfig:
audio_file_size_limit:500
batch_count_limit:10
file_size_limit:100
image_file_size_limit:100
video_file_size_limit:500
workflow_file_upload_limit:10
image:
enabled:false
number_limits:3
transfer_methods:
-local_file
-remote_url
number_limits:3
opening_statement:''
retriever_resource:
enabled:true
sensitive_word_avoidance:
enabled:false
speech_to_text:
enabled:false
suggested_questions: []
suggested_questions_after_answer:
enabled:false
text_to_speech:
enabled:false
language:''
voice:''
graph:
edges:
-data:
isInIteration:false
isInLoop:false
sourceType:start
targetType:tool
id:1755656337314-source-1755657278812-target
source:'1755656337314'
sourceHandle:source
target:'1755657278812'
targetHandle:target
type:custom
zIndex:0
-data:
isInLoop:false
sourceType:tool
targetType:answer
id:1755657278812-source-answer-target
source:'1755657278812'
sourceHandle:source
target:answer
targetHandle:target
type:custom
zIndex:0
nodes:
-data:
desc:''
selected:false
title:开始
type:start
variables: []
height:53
id:'1755656337314'
position:
x:80
y:282
positionAbsolute:
x:80
y:282
selected:false
sourcePosition:right
targetPosition:left
type:custom
width:244
-data:
answer:'{{#1755657278812.text#}}
{{#1755657278812.files#}}
'
desc:''
selected:false
title:直接回复
type:answer
variables: []
height:123
id:answer
position:
x:740
y:282
positionAbsolute:
x:740
y:282
selected:true
sourcePosition:right
targetPosition:left
type:custom
width:244
-data:
desc:''
is\_team\_authorization:true
output\_schema:null
paramSchemas:
-auto\_generate:null
default:null
form:llm
human\_description:
en\_US:Thetextprompttogenerateimagefrom.Describewhatyouwant
toseeintheimageindetail.Forexample"A golden cat sitting on
a red sofa in a cozy living room".
ja\_JP:Thetextprompttogenerateimagefrom.Describewhatyouwant
toseeintheimageindetail.Forexample"A golden cat sitting on
a red sofa in a cozy living room".
pt\_BR:Thetextprompttogenerateimagefrom.Describewhatyouwant
toseeintheimageindetail.Forexample"A golden cat sitting on
a red sofa in a cozy living room".
zh\_Hans:Thetextprompttogenerateimagefrom.Describewhatyouwant
toseeintheimageindetail.Forexample"A golden cat sitting on
a red sofa in a cozy living room".
label:
en\_US:Prompt
ja\_JP:Prompt
pt\_BR:Prompt
zh\_Hans:Prompt
llm\_description:Textpromptthatdescribesthedesiredimagecontentin
detail.Themorespecificanddescriptive,thebetterthegeneratedimage
quality.
max:null
min:null
name:prompt
options: []
placeholder:null
precision:null
required:true
scope:null
template:null
type:string
-auto\_generate:null
default:Qwen/Qwen-Image
form:form
human\_description:
en\_US:TheAImodeltouseforimagegeneration.Qwen-Imageisthedefault
andrecommendedmodel.
ja\_JP:TheAImodeltouseforimagegeneration.Qwen-Imageisthedefault
andrecommendedmodel.
pt\_BR:TheAImodeltouseforimagegeneration.Qwen-Imageisthedefault
andrecommendedmodel.
zh\_Hans:TheAImodeltouseforimagegeneration.Qwen-Imageisthedefault
andrecommendedmodel.
label:
en\_US:Model
ja\_JP:Model
pt\_BR:Model
zh\_Hans:Model
llm\_description:''
max:null
min:null
name:model
options:
-icon:''
label:
en\_US:Qwen-Image(Recommended)
ja\_JP:Qwen-Image(Recommended)
pt\_BR:Qwen-Image(Recommended)
zh\_Hans:Qwen-Image(Recommended)
value:Qwen/Qwen-Image
placeholder:null
precision:null
required:false
scope:null
template:null
type:select
params:
model:''
prompt:''
provider\_id:wwwzhouhui/qwen\_text2image/modelscope
provider\_name:wwwzhouhui/qwen\_text2image/modelscope
provider\_type:builtin
selected:false
title:TexttoImage
tool\_configurations:
model:
type:constant
value:Qwen/Qwen-Image
tool\_description:Generatehigh-qualityimagesfromtextpromptsusingModelScope
Qwen-ImageAImodel.Supportvariousimagestylesanddetaileddescriptions.
tool\_label:TexttoImage
tool\_name:text2image
tool\_parameters:
prompt:
type:mixed
value:'{{#sys.query#}}'
type:tool
version:'2'
height:121
id:'1755657278812'
position:
x:384
y:282
positionAbsolute:
x:384
y:282
selected:false
sourcePosition:right
targetPosition:left
type:custom
width:244
viewport:
x:34
y:87.5
zoom: 1

一个简单的基于dify的文生图的插件就这么做完了。
说明:在实际AI生成代码中也不是一次性就能搞定的,中间也有一些错误,大家耐心和AI聊天就行了。有错误不担心就发给AI ,反正就和它聊,聊一聊这个插件就聊出来了。
dify工作流体验地址
工作流地址:https://dify.duckcloud.fun/chat/p9oMffkOcyMxYRAl备用地址(http://14.103.204.132/chat/p9oMffkOcyMxYRAl)
5.后续
====
考虑到这个插件是本地打包上传开发的,我们后面希望分享到插件市场上给更多人使用,这样我们也可以参考https://docs.dify.ai/plugin-dev-zh/0322-release-to-dify-marketplace 把插件发布到Dify Marketplace,详细步骤这里就不做展开,大家看官方文档来操作就可以了。
6.总结
====
今天主要带大家了解并制定了基于 Dify 开发文生图插件的规范指南,该指南以 ModelScope 的 Qwen-Image 模型为基础,完整覆盖了插件开发的全流程。这份指南的搭建涉及多个关键环节:项目结构设计(明确 manifest、provider、tool 等核心文件的组织方式)、异步任务处理(实现任务提交、状态轮询、结果获取的标准化逻辑)、图像处理流程(基于 PIL 库的图像下载与格式转换)、错误处理机制(覆盖网络异常、API 错误、超时等各类场景)以及用户体验优化(提供实时进度反馈与友好提示)。
通过这套规范指南,开发者能够快速搭建符合 Dify 平台标准的文生图插件,同时具备良好的扩展性 —— 小伙伴们可以基于此框架扩展更多 AI 生成类插件,如视频生成、图像风格转换等,进一步丰富 Dify 的功能场景。在实际验证中,遵循该指南开发的插件能够稳定对接 ModelScope API,实现从文本提示到图像生成的完整流程,有效解决了插件开发中异步任务处理、跨平台集成等常见问题。
感兴趣的小伙伴可以按照这份指南尝试开发自己的 Dify 文生图插件,甚至拓展更多创意功能。今天的分享就到这里结束了,我们下一篇文章见。
项目我已经放到github上面了,地址https://github.com/wwwzhouhui/qwen\_text2image。 觉得项目不错,麻烦点个赞。
[免费玩转 AI 编程!Claude Code Router + Qwen3-Code 实战教程](https://mp.weixin.qq.com/s?__biz=Mzg3OTYzMjc1NQ==&mid=2247489059&idx=1&sn=69eb2d3d240ddfe649f5c469fe67048b&scene=21#wechat_redirect)
[超算挑战赛实战!AI 一键生成中医药科普短视频,青少年轻松学药材](https://mp.weixin.qq.com/s?__biz=Mzg3OTYzMjc1NQ==&mid=2247489022&idx=1&sn=9d0c9a1a64cc06cc5f43100b6ae29574&scene=21#wechat_redirect)
[dify案例分享-100% 识别率!发票、汇票、信用证全搞定的通用票据识别工作流](https://mp.weixin.qq.com/s?__biz=Mzg3OTYzMjc1NQ==&mid=2247488979&idx=1&sn=9fe6a5622a53769fbdf3d2b90cab8bc5&scene=21#wechat_redirect)
[dify案例分享-AI 助力初中化学学习:用 Qwen Code+Dify 一键生成交互式元素周期表网页](https://mp.weixin.qq.com/s?__biz=Mzg3OTYzMjc1NQ==&mid=2247488953&idx=1&sn=5b30bd417e117c9608637af9d5b675d7&scene=21#wechat_redirect)
[dify案例分享-AI 助力初中化学学习:用 Qwen Code+Dify 一键生成交互式元素周期表网页](https://mp.weixin.qq.com/s?__biz=Mzg3OTYzMjc1NQ==&mid=2247488953&idx=1&sn=5b30bd417e117c9608637af9d5b675d7&scene=21#wechat_redirect)