




用影刀采集回来的数据,往往需要二次处理:去掉重复的商品、按价格排序、筛选出销量大于1000的、合并多张表格。
影刀自带的Excel指令能处理简单操作,但遇到筛选、去重、合并这些,用Python代码指令+Pandas更高效。
Pandas是Python的一个数据处理库,代码量少、运行快,处理1万行数据也就几秒钟。
我也是踩了“Excel指令逐行处理太慢”的坑之后,才转用Pandas的。
一、准备工作:安装Pandas
注意:影刀内置的Python环境可能没有pandas,需要先安装。
操作步骤:
- 打开影刀 → 设置 → 扩展中心 → Python包管理
- 搜索
pandas→ 安装(如果安装失败,用下面的方法) - 备选方案:在Python代码指令里写
import subprocess; subprocess.check_call(['pip', 'install', 'pandas'])(首次运行会安装,较慢)
验证安装:在Python代码指令里写import pandas as pd,如果不报错就成功了。
二、读取数据到Pandas
场景:把Excel或CSV读进Pandas的DataFrame(表格对象)。
操作步骤:
- 拖入“Python代码”指令,点亮Python图标
2. 写入代码
import pandas as pd
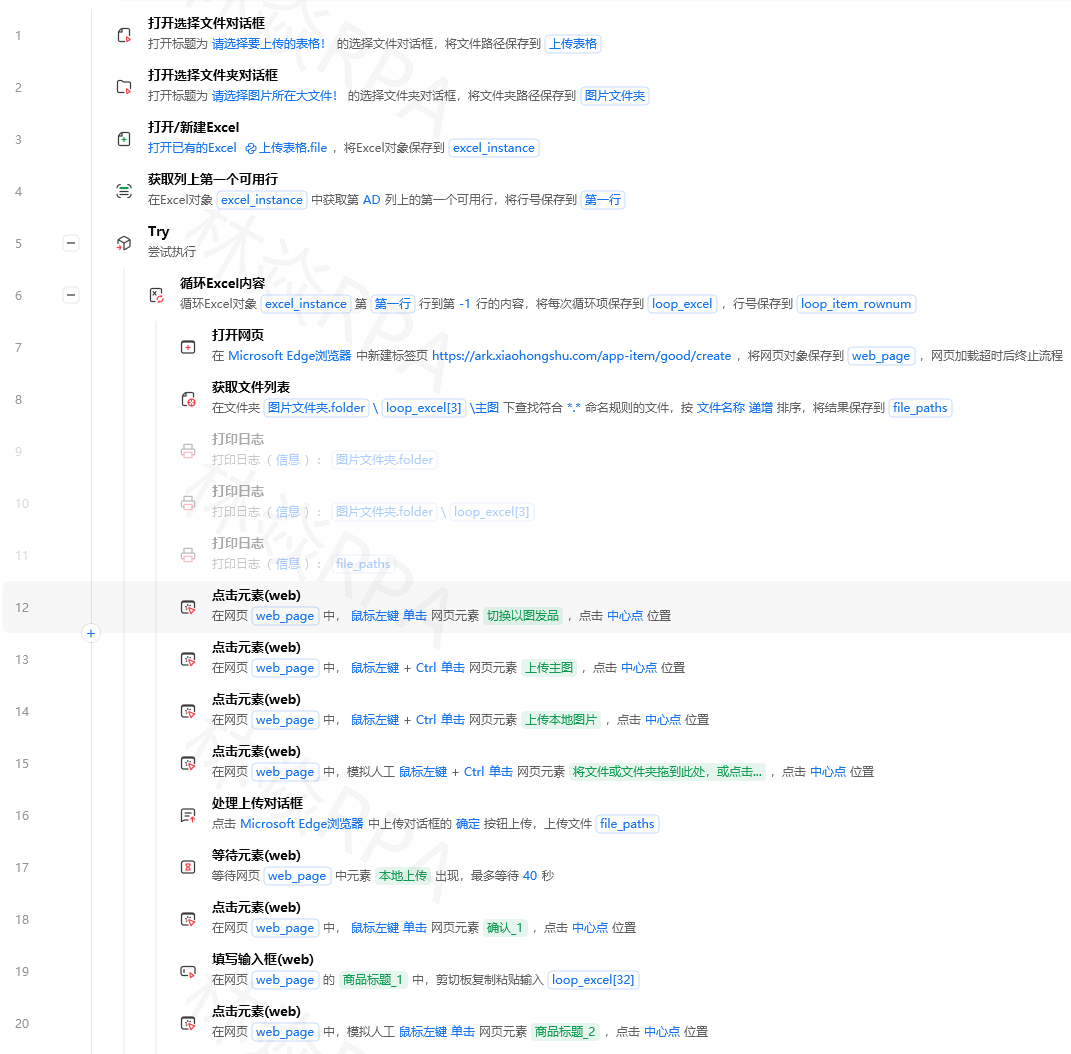
# 输入:文件路径(从影刀变量传入)
# 输出:df(表格对象)
# 读取Excel
df = pd.read_excel(file_path, sheet_name=0) # 0表示第一个sheet
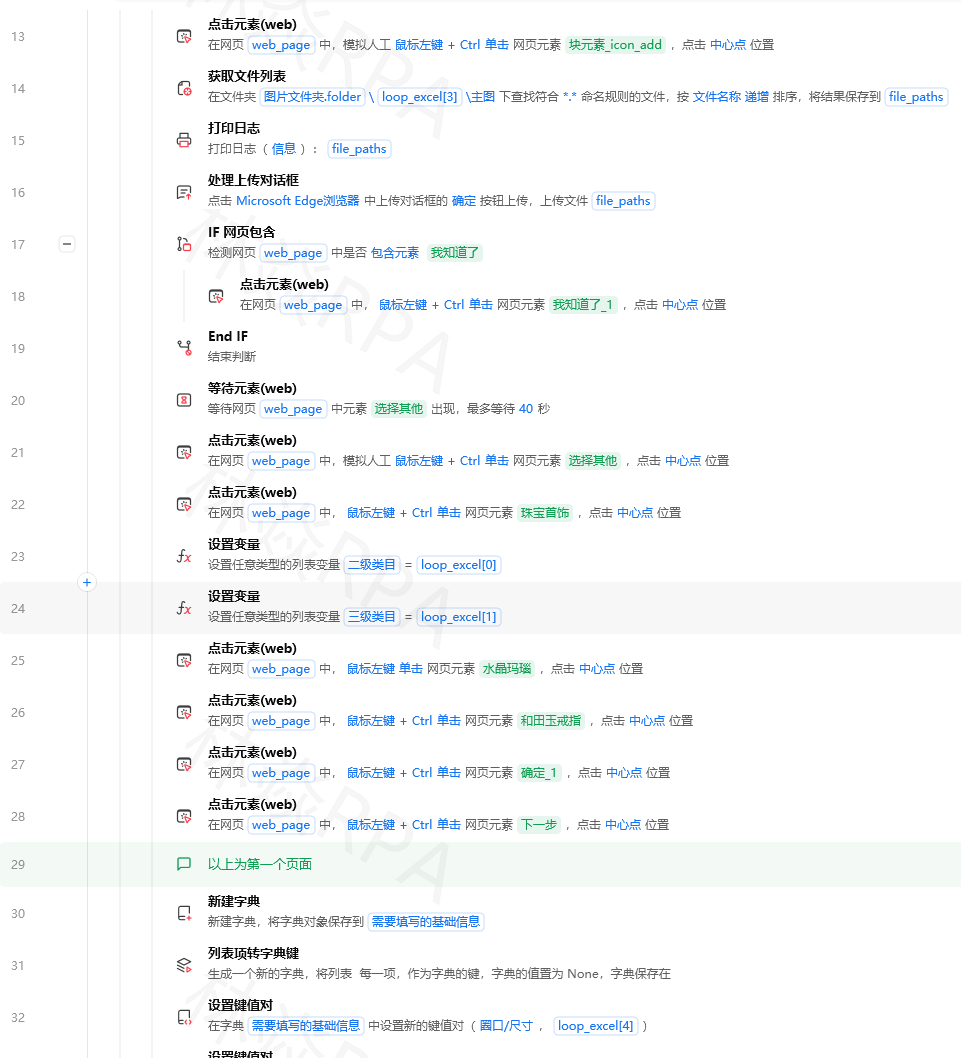
# 读取CSV(如果有)
# df = pd.read_csv(file_path, encoding='utf-8')
影刀变量传递:把文件路径作为输入参数传进去,再把df作为输出参数(类型选“通用值”)返回给影刀。
三、核心操作1:筛选数据
场景:只保留价格大于50元的商品。
# 筛选价格大于50
df_filtered = df[df['价格'] > 50]
# 多个条件:价格>50 且 销量>1000
df_filtered = df[(df['价格'] > 50) & (df['销量'] > 1000)]
# 模糊筛选:标题包含“连衣裙”
df_filtered = df[df['标题'].str.contains('连衣裙', na=False)]
# 反向筛选:排除某个值
df_filtered = df[df['店铺'] != '官方旗舰店']
四、核心操作2:排序
场景:按价格从低到高排序,价格相同按销量从高到低。
# 按价格升序(默认)
df_sorted = df.sort_values('价格')
# 按价格降序
df_sorted = df.sort_values('价格', ascending=False)
# 多列排序:价格升序+销量降序
df_sorted = df.sort_values(['价格', '销量'], ascending=[True, False])
五、核心操作3:去重
场景:商品ID重复的只保留第一条。
# 基于某一列去重(如商品ID)
df_deduplicated = df.drop_duplicates(subset=['商品ID'])
# 基于多列去重(如标题+价格组合相同才算重复)
df_deduplicated = df.drop_duplicates(subset=['标题', '价格'])
# 保留最后一条(默认保留第一条,改keep='last')
df_deduplicated = df.drop_duplicates(subset=['商品ID'], keep='last')
六、核心操作4:合并多张表格
场景:每天采集一张Excel,月底要合并成一张总表。
# 方法一:上下拼接(行数增加,列不变)
df_total = pd.concat([df1, df2, df3], ignore_index=True)
# 方法二:左右合并(类似Excel的VLOOKUP,基于共同列)
# 例如:df1有商品ID和标题,df2有商品ID和价格,按商品ID合并
df_merged = pd.merge(df1, df2, on='商品ID', how='left')
# how可选:left/right/inner/outer
批量合并文件夹内所有Excel:
import os
import pandas as pd
# 输入:文件夹路径
folder_path = "C:/data/"
all_dfs = []
for file in os.listdir(folder_path):
if file.endswith('.xlsx'):
df = pd.read_excel(os.path.join(folder_path, file))
all_dfs.append(df)
df_total = pd.concat(all_dfs, ignore_index=True)
七、核心操作5:新增列与计算
场景:根据价格和销量计算总销售额。
# 新增一列:销售额 = 价格 * 销量
df['销售额'] = df['价格'] * df['销量']
# 新增列:价格区间(文本)
df['价格区间'] = df['价格'].apply(lambda x: '高' if x > 100 else '低')
# 新增列:提取标题中的品牌(假设格式“品牌+商品名”)
df['品牌'] = df['标题'].str.split().str[0]
八、完整实战:从采集到清洗的流程
场景:从拼多多采集了1000条商品原始数据,需要清洗后写入新表。
原始数据列:商品标题、价格(带¥符号)、销量(如"3.5w")、店铺名
处理要求:
- 去掉价格中的¥,转成数字
- 销量"3.5w"转成35000
- 筛选出销量>5000的商品
- 按价格降序排序
- 写入新Excel
Python代码(单条指令完成):
import pandas as pd
import re
# 输入:原始数据DataFrame(从影刀传入)
# 输出:处理后的DataFrame
def clean_price(price_str):
# 去掉¥和空格,转成数字
num = re.search(r'(\d+\.?\d*)', str(price_str))
return float(num.group(1)) if num else 0
def clean_sales(sales_str):
# "3.5w" -> 35000
match = re.search(r'(\d+\.?\d*)(\w?)', str(sales_str))
if not match:
return 0
num = float(match.group(1))
unit = match.group(2).lower()
if unit == 'w':
return int(num * 10000)
else:
return int(num)
# 清洗
df['价格_数字'] = df['价格'].apply(clean_price)
df['销量_数字'] = df['销量'].apply(clean_sales)
# 筛选销量>5000
df_filtered = df[df['销量_数字'] > 5000]
# 按价格降序
df_sorted = df_filtered.sort_values('价格_数字', ascending=False)
# 只保留需要的列
df_result = df_sorted[['商品标题', '价格_数字', '销量_数字', '店铺名']]
# 重命名列(中文)
df_result.columns = ['商品标题', '价格', '销量', '店铺']
九、写回Excel
# 写回Excel
df_result.to_excel('C:/result/清洗后商品.xlsx', index=False)
# 如果要在影刀里继续用,把df_result作为输出参数返回
注意:to_excel需要安装openpyxl,如果报错,在Python包管理安装openpyxl。
十、Pandas vs 影刀Excel指令对比
| 操作 | Pandas代码量 | 影刀Excel指令 | 10万行性能 |
|---|---|---|---|
| 筛选价格>50 | 1行 | 循环+判断+写入新表 | Pandas快100倍 |
| 按列去重 | 1行 | 需要字典记录+循环 | Pandas秒级 |
| 多表合并 | 2行 | 逐个打开复制粘贴 | Pandas极快 |
| 简单读写 | 2行 | 2-3个指令 | 差不多 |
常见问题/易错速查
| 问题 | 原因 | 解决方法 |
|---|---|---|
| import pandas报错 | pandas没安装 | 去Python包管理安装 |
| 读取中文列名报错 | Excel编码问题 | 加参数encoding='utf-8' |
| to_excel报错 | 缺少openpyxl | 安装openpyxl包 |
| df为空 | 文件路径不对或sheet名错 | 打印df.shape看看 |
| 数据量大时影刀卡死 | 整个df在输出参数里传输太大 | 不返回df,直接在Python里写文件 |
推荐资源
Pandas官方10分钟教程:搜索“10 minutes to pandas”,有中文版,学10个常用函数就够了。
我常用的Pandas速查(存下来):
df.head():看前5行df.info():看每列类型和空值df.describe():看统计摘要df['列名'].unique():看有哪些唯一值df.isnull().sum():看每列空值数量
最后说一句:
我之前一直用影刀Excel指令逐行处理,处理5000条数据要跑3分钟。改用Pandas后,同样的数据5秒搞定。学习成本其实很低——会df[df['价格']>50]就能做筛选了。
建议:采集回来的原始数据先存成一个原始表,然后用Python代码指令+Pandas做清洗,输出最终表。这样流程清晰,修改清洗逻辑也方便。
作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。