




Split lock 是 CPU 为了支持跨 cache line 进行原子内存访问而支持的内存总线锁。
有些处理器比如 ARM、RISC-V 不允许未对齐的内存访问,不会产生跨 cache line 的原子访问,所以不会产生 split lock,而 X86 是支持的。
split lock 对开发者来说是很方便的,因为不需要考虑内存不对齐访问的问题,但是这同时也是有代价的:一个产生 split lock 的指令会独占内存总线大约 1000 个时钟周期,对比正常情况下的 ADD 指令约只需要小于 10 个时钟周期,锁住内存总线导致其他 CPU 无法访问内存会严重影响系统性能。
因此 split lock 的检测与处理就非常重要,现在的 CPU 支持检测能力,检测到如果在内核态会直接 panic,在用户态则会尝试主动 sleep 来降低 split lock 产生的频率,或者 kill 用户态进程,进而缓解对内存总线的争抢。
在引入了虚拟化后,会尝试在 Host 侧处理,KVM 通知 QEMU 的 vCPU 线程主动 sleep 降低 split lock 产生的频率,甚至 kill 虚拟机。以上的结论也只是截止目前 2022/4/19(下同)的情况,近 2 年社区仍对 split lock 的处理有不同的看法,处理方式也是改变了多次,所以以下的分析仅讨论目前的情况。
1. Split lock 背景
1.1 从 i++说起
我们假设一个最简单的计算模型,一个 CPU(单核、没有开启 Hyper-threading、没有 Cache),一块内存。上面运行一个 C 程序在执行i++,对应的汇编代码是add 1, i。
分析一下这里add指令的语义,需要两个操作数,源操作数 SRC 和目的操作数 DEST,实现的功能是DEST = DEST + SRC。这里 SRC 是立即数 1,DEST 是 i 的内存地址,CPU 需要先在内存中读出 i 的内容,然后加 1,最后把结果写入 i 所在的内存地址。总共产生了两次串行的内存操作。
如果计算架构复杂一点,有 2 个 CPU 核 CoreA 和 CoreB 的情况下,上面的i++代码就不得不考虑数据一致性的问题:
1.1.1 并发写问题
如果 CoreA 正在向 i 的内存地址中写入时,CoreB 同时向 i 的内存地址写入怎么办?
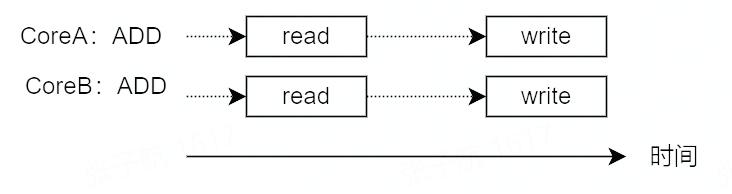
并发写相同内存地址其实很简单,CPU 从硬件上保证了基础内存操作的原子性。
具体的操作有:
- 读/写 1 byte
- 读/写 16 bit 对齐的 2 byte
- 读/写 32 bit 对齐的 4 byte
- 读/写 64 bit 对齐的 8 byte
1.1.2 写覆盖问题
如果 CoreA 从内存中读出 i 后,写入 i 所在内存地址前这段时间内,CoreB 向 i 的内存地址写入数据怎么办?
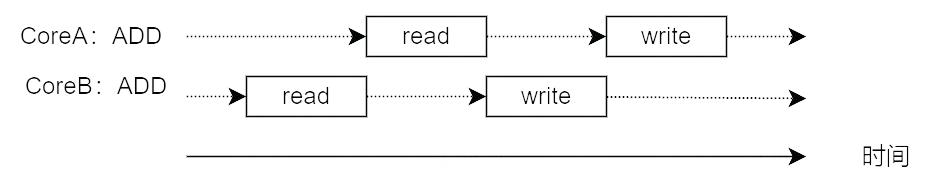
这种情况下会导致 CoreB 写入的数据被 CoreA 后面再写入的数据覆盖掉,使 CoreB 的写入数据丢失,而 CoreA 也不知道写入的数据已经在读出后被更新过了。
为什么会出现这个问题呢?就是因为 ADD 指令不是原子操作,会产生两次内存操作。
那怎么解决这个问题呢?既然 ADD 指令在硬件上不是原子的,那么就从软件上加锁来实现原子操作,使 CoreB 的的内存操作在 CoreA 的内存操作完成前不能执行。

对应方法就是声明指令前缀LOCK,汇编代码变为lock add 1, i。
1.2 总线锁
LOCK指令前缀声明后,随同执行的指令会变为原子指令。原理就是在随同指令执行期间,锁住系统总线,禁止其他处理器进行内存操作,使其独占内存来实现原子操作。
下面举几个例子:
1.2.1 QEMU 中的原子累加
QEMU 中的函数 qatomic_inc(ptr),把参数 ptr 指向的内存数据进行进行加 1。
#define qatomic_inc(ptr) ((void) __sync_fetch_and_add(ptr, 1))
原理是调用 GCC 内置的__sync_fetch_and_add 函数,我们手写一个 C 程序,看下__sync_fetch_and_add 的汇编实现。
int main() {
int i = 1;
int *p = &i;
while(1) {
__sync_fetch_and_add(p, 1);
}
return 0;
}
// add.s
.file "add.c"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $1, -12(%rbp)
leaq -12(%rbp), %rax
movq %rax, -8(%rbp)
.L2:
movq -8(%rbp), %rax
lock addl $1, (%rax)
jmp .L2
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Debian 6.3.0-18+deb9u1) 6.3.0 20170516"
.section .note.GNU-stack,"",@progbits
可以看到__sync_fetch_and_add 的汇编实现就是在 add 指令前声明了 lock 指令前缀。
1.2.2 Kernel 中的原子累加
Kernel 中的 atomic_inc 函数,把参数 v 指向的内存数据进行进行加 1。
static __always_inline void
atomic_inc(atomic_t *v)
{
instrument_atomic_read_write(v, sizeof(*v));
arch_atomic_inc(v);
}
static __always_inline void arch_atomic_inc(atomic_t *v)
{
asm volatile(LOCK_PREFIX "incl %0"
: "+m" (v->counter) :: "memory");
}
*#define LOCK_PREFIX LOCK_PREFIX_HERE "\n\tlock; "
可以看到,同样是声明了 lock 指令前缀。
1.2.3 CAS(Compare And Swap)
编程语言中的 CAS 接口为开发者提供了原子操作,实现无锁机制。
Golang 的 CAS
// bool Cas(int32 *val, int32 old, int32 new)
// Atomically:
// if(*val == old){
// *val = new;
// return 1;
// } else
// return 0;
TEXT ·Cas(SB),NOSPLIT,$0-17
MOVQ ptr+0(FP), BX
MOVL old+8(FP), AX
MOVL new+12(FP), CX
LOCK
CMPXCHGL CX, 0(BX)
SETEQ ret+16(FP)
RET
Java 的 CAS
inline jlong Atomic::cmpxchg (jlong exchange_value, volatile jlong* dest, jlong compare_value) {
bool mp = os::is_MP();
__asm__ __volatile__ (LOCK_IF_MP(%4) "cmpxchgq %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
// Adding a lock prefix to an instruction on MP machine
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
可以看到,CAS 同样是使用 lock 指令前缀来实现的,那么 lock 指令前缀具体是怎么实现的呢?
1.2.4 LOCK#信号
具体来说,代码中的指令前面声明了 LOCK 前缀指令后,处理器就会在指令运行期间产生 LOCK#信号,使其他处理器不能通过总线访问内存。
我们尝试从 8086 CPU 的引脚图中管中窥豹,了解下 LOCK#信号的原理。

8086 CPU 存在一个 LOCK 引脚(图中 29 号引脚),低电平有效。当声明 LOCK 指令前缀时,会拉低 LOCK 引脚电平,进行 assert 操作,此时其他设备无法获取系统总线的控制权。当 LOCK 指令修饰的指令执行完成后,拉高 LOCK 引脚电平进行 de-assert。
所以整个流程就清晰了,当想要通过非原子指令(例如 add)实现原子操作时,编程时需要在指令前声明 lock 指令前缀,运行时 lock 指令前缀会被处理器识别出来,并产生 LOCK#信号,使其独占内存总线,而其他处理器则无法通过内存总线访问内存,这样就实现了原子操作。所以也就解决了上面的写覆盖问题了。
看起来很好,不过这样又引入了一个新问题:
1.2.5 总线锁引起的性能下降问题
现在处理器的核越来越多,如果每个核都频繁的产生 LOCK#信号,来独占内存总线,这样其余的核不能访问内存,导致性能会有很大的下降,该怎么办?
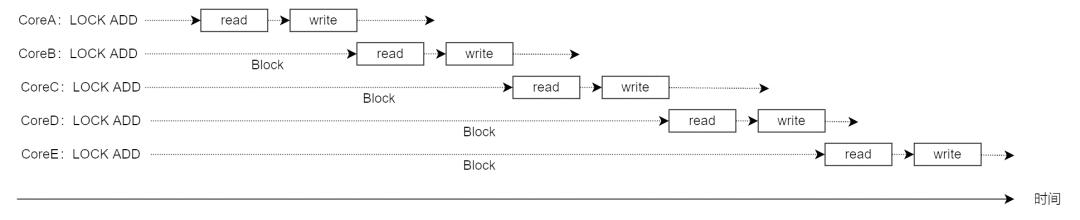
1.3 缓存锁
INTEL 为了优化总线锁导致的性能问题,在 P6 后的处理器上,引入了缓存锁(cache locking)机制:通过缓存一致性协议保证多个 CPU 核访问跨 cache line 的内存地址的多次访问的原子性与一致性,而不需要锁内存总线。
1.3.1 MESI 协议
先以常见的 MESI 简单介绍一下缓存一致性协议。MESI 分为四种状态:
- 已修改 Modified (M) 缓存行是脏的(dirty),与主存的值不同。如果别的 CPU 内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(S).
- 独占 Exclusive (E) 缓存行只在当前缓存中,但是干净的(clean)--缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。
- 共享 Shared (S) 缓存行也存在于其它缓存中且是干净的。缓存行可以在任意时刻抛弃。
- 无效 Invalid (I) 缓存行是无效的
MESI 协议状态机如下:
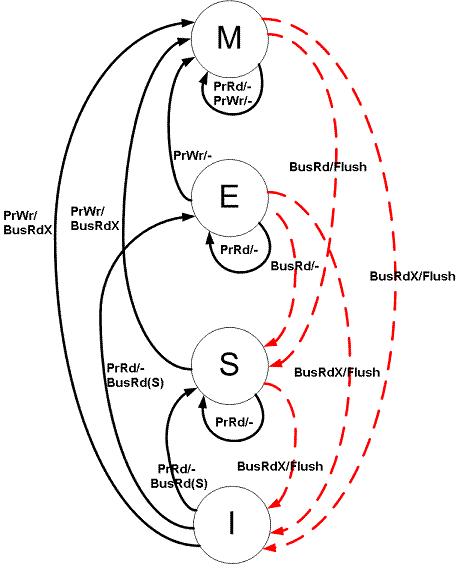
状态机的转换基于两种情况:
-
CPU 产生对 cache 的请求
a. PrRd: CPU 请求读一个缓存块
b. PrWr: CPU 请求写一个缓存块
-
总线产生对 cache 的请求
a. BusRd: 窥探器请求指出其他处理器请求读一个缓存块
b. BusRdX: 窥探器请求指出其他处理器请求写一个该处理器不拥有的缓存块
c. BusUpgr: 窥探器请求指出其他处理器请求写一个该处理器拥有的缓存块
d. Flush: 窥探器请求指出请求回写整个缓存到主存
e. FlushOpt: 窥探器请求指出整个缓存块被发到总线以发送给另外一个处理器(缓存到缓存的复制)
简单来说,通过 MESI 协议,每个 CPU 不仅知道自身对 cache 的读写操作,还进行总线嗅探(snooping),可以知道其他 CPU 对 cache 的的读写操作,所以除了自身对 cache 的修改也会根据其他 CPU 对 cache 的修改来改变 cache 的状态。
1.3.2 缓存锁原理
缓存锁是依赖缓存一致性协议来保证内存访问的原子性,因为缓存一致性协议会阻止被多个 CPU 缓存的内存地址被多个 CPU 同时修改。
下面我们以一个例子分析缓存锁是如何基于 MESI 协议实现内存读写的原子性。
我们还是假设有两个 CPU Core,CoreA 与 CoreB 进行分析。
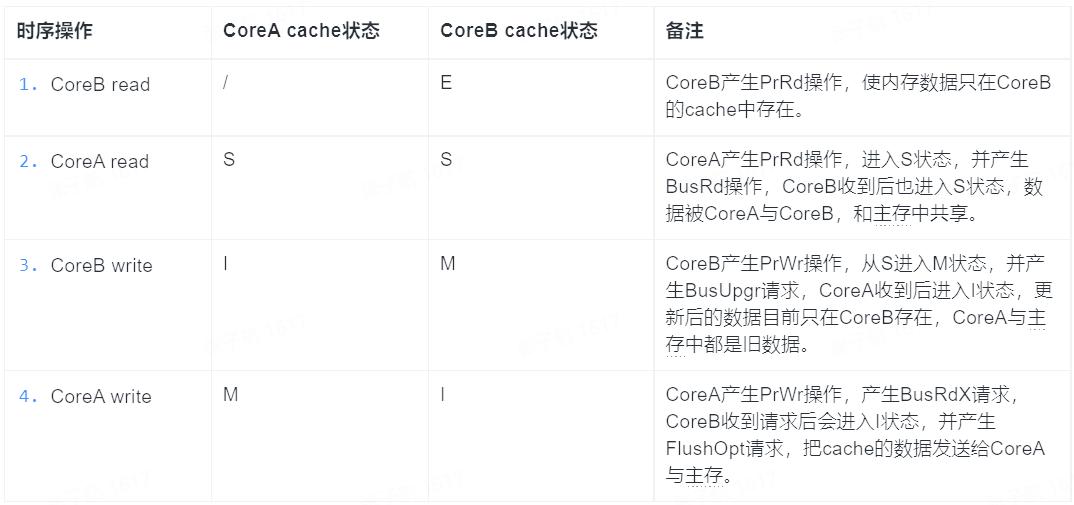
注意最后一个操作步骤 4,CoreB 修改 cache 中的数据后,当 CoreA 想再次修改时,会被 CoreB 嗅探到,只有等 CoreB 的数据同步到主存与 CoreA 后,CoreA 才会进行修改。
可以看到 CoreB 修改的数据没有丢失,被同步给了 CoreA 与主存。并且实现上述的操作没有锁内存总线,只是 CoreA 的修改操作被堵塞了一下,这相比锁整个内存总线是可控的。
上面是一个比较简单的情况,两个 CPU Core 的写入是串行的。那么如果在操作步骤 2 后,CoreA 与 CoreB 同时下发写请求呢?会产生两个 Core 的 cache 都进入 M 状态吗?
答案是否定的,MESI 协议保证了上面同时进入 M 的情况不会发生。根据 MESI 协议,一个 Core 的 PrWr 操作只能在其 cache 为 M 或 E 状态时自由的执行,如果是 S 状态,其他 Core 的 cache 必须先被设置为 I 状态,实现的方式是通过一个叫 Request For Ownership(RFO)的总线广播进行的,RFO 是一个总线事务,如果两个 Core 同时向总线进行 RFO 广播都想 Invalid 对方的 cache,总线会进行仲裁,最终结果会是只有一个 Core 广播成功,而另一个 Core 会失败,其 cache 会被设置为 I 状态。所以我们能看到,引入 cache 层后,原子操作由锁内存总线变为了由总线仲裁来实现。
如果声明了 LOCK 指令前缀,那么对应的 cache 地址会被总线锁定,在上面的例子中,其他 Core 在访问时会等到指令执行结束后再进行访问,也即变为了串行操作,实现了对 cache 读写的原子性。
那么总结一下缓存锁:在代码指令前面声明了 LOCK 指令前缀,想要原子访问内存数据,如果内存数据可以被缓存在 CPU 的 cache 中,运行时通常不会在总线上产生 LOCK#信号,而是通过缓存一致性协议、总线仲裁机制与 cache 锁定来阻止两个或以上的 CPU 核,对同一块地址的并发访问。
那么是不是所有的总线锁都可以被优化为缓存锁呢?答案是否定的,不能被优化的情况就是 split lock。
1.4 Split lock
由于缓存一致性协议的粒度是一个 cache line,当原子操作的数据跨 cache line 时,依赖缓存锁机制无法保证数据一致性,会退化为总线锁来保证一致性,这种情况就是 split lock,split 也可以理解为访存的 cache 被 split 为两个 line。
比如有如下数据结构:
struct Data {
char padding[62]; // 62字节
int32_t value; // 4字节
} __attribute__((packed)) // 按实际字节对齐
被缓存到 cache line 大小为 64 字节的 cache 中时,value 成员会跨 cache line。
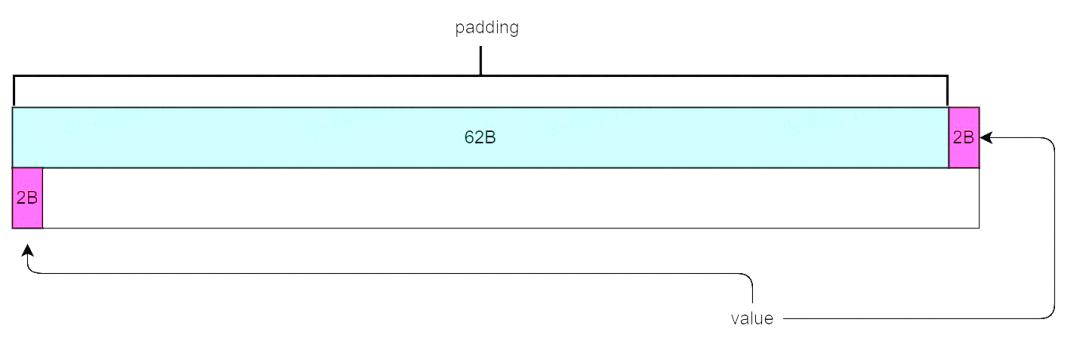
此时如果想要通过LOCK ADD 指令操作 Data 结构中的 value 成员,就无法通过缓存锁解决,只能走老路,锁总线来保证数据一致性。
而锁总线会引起严重的性能下降,访存延迟增加百倍左右,如果是内存密集型业务,性能会下降 2 个数量级。所以在现代 X86 处理器中,要避免写出会产生 split lock 的代码,并有能力检测出 Split lock 的产生。
2. 避免产生 Split lock
回顾一下 Split lock 的产生条件:
- 对数据执行原子访问
- 要访问的数据在 cache 中跨 cache line 存储
因为原子操作是比较基础的操作,所以我们以数据跨 cache line 存储为介入点进行分析。
如果数据只存储在一个 cache line 中,那就可以解决问题。
2.1 编译器优化
我们前面的数据结构中有用到 __attribute__((packed)) 这个 GCC 的特性,表示不进行内存对齐优化。
如果不引入 __attribute__((packed)),使用内存对齐优化时,编译器会对内存数据进行填充,比如在 padding 后填入 2 字节,使 value 的内存地址可以被 4 字节整除,从而达到对齐。被缓存到 cache 中时 value 也就不会跨 cache line 了。
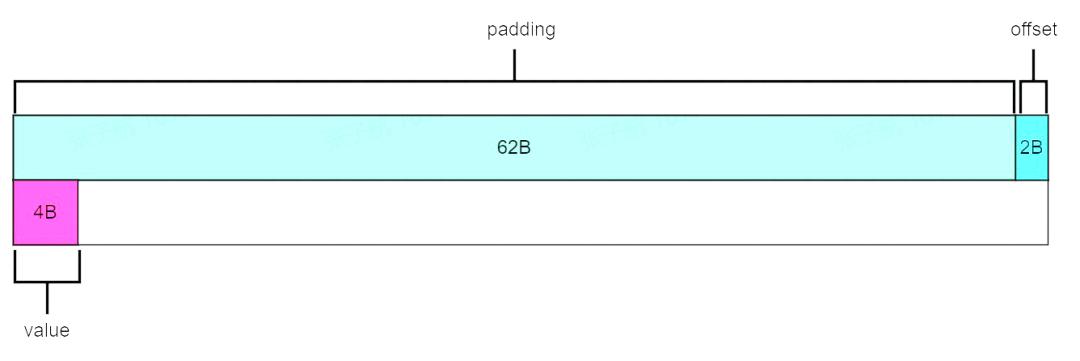
既然编译器可以优化后可以通过内存对齐避免跨 cache line 访问,为什么还要引入 __attribute__((packed))呢?
这是因为通过 __attribute__((packed)) 强制按数据结构对齐,也有好处。比如基于数据结构的网络通信,不需要填充多余字节等。
2.2 注意事项
我们在编写代码过程中,有以下几点需要注意:
- 有条件的情况下,尽量使用编译器的内存对齐优化。
- 在不能使用编译器优化时,考虑好结构体成员的大小与声明先后顺序。
- 在产生可能不对齐的内存访问时,尽量不要使用原子指令来进行访问。
3. Split lock 的检测与处理
3.1 使用场景
- 硬实时系统:当硬实时应用运行在一些核上,另一个普通程序运行在其他核上,普通程序可以产生 bus lock 来打破硬实时的要求。
- 云计算:多租户运行在一个物理机上,一个虚拟机内产生 bus lock 可以干扰其他虚拟机的性能。
下面主要针对云环境,自底向上进行分析。
3.2 硬件检测支持
当尝试 split lock 操作时会产生 Alignment Check (#AC) exception,当获取 bus lock 并执行后会产生 Debug(#DB) trap。
硬件这里区分下了 split lock 与 bus lock:
- split lock 指操作数跨两个 cache line 的原子操作
- bus lock 有两类情况可以产生,要么是 writeback 内存的 split lock,要么是非 writeback 内存的任何 lock 操作
概念上,split lock 是 bus lock 的一种,split lock 倾向于跨 cache line 访问,bus lock 倾向锁总线的操作。
3.2.1 相关寄存器(MSR)
发生 split lock 和 bus lock 时是否产生对应的 exception,可以由特定的寄存器控制,下面是相关的控制寄存器。
- MSR_MEMORY_CTRL/MSR_TEST_CTRL:33H 这个 MSR 的 bit 29,控制 split lock 引起的#AC exception。
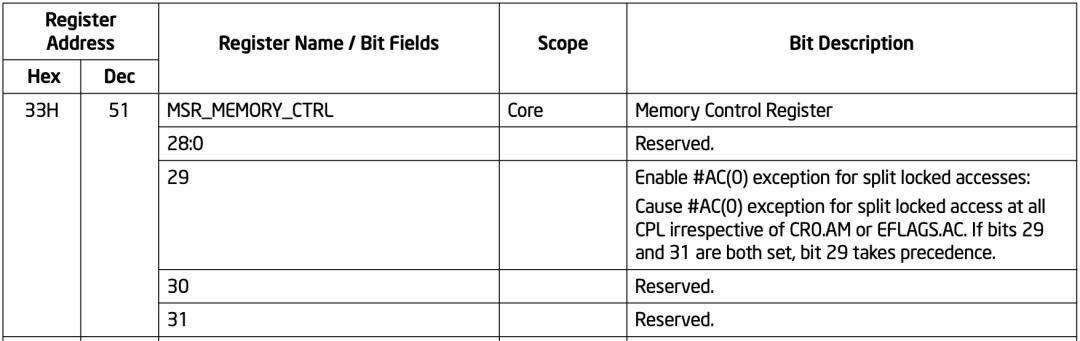
- IA32_DEBUGCTL:这个 MSR 的 bit 2,控制 bus lock 引起的#DB exception。

3.3 内核处理支持
以 v5.17 版本为例进行分析。当前版本内核支持一个相关启动参数 split_lock_detect,配置项和对应功能如下:
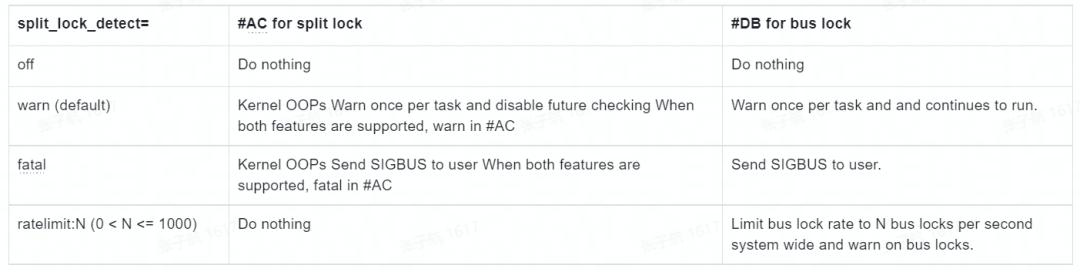
实现 split_lock_detect 主要分为 3 部分:配置、初始化、处理,下面我们逐项分析一下源码:
3.3.1 配置
-> start_kernel
-> sld_setup
-> split_lock_setup
-> __split_lock_setup
-> sld_state_setup
内核启动时,会先进行 sld(split lock detect)的 setup。
static void __init __split_lock_setup(void)
{
if (!split_lock_verify_msr(false)) {
pr_info("MSR access failed: Disabled\n");
return;
}
rdmsrl(MSR_TEST_CTRL, msr_test_ctrl_cache);
if (!split_lock_verify_msr(true)) {
pr_info("MSR access failed: Disabled\n");
return;
}
/* Restore the MSR to its cached value. */
wrmsrl(MSR_TEST_CTRL, msr_test_ctrl_cache);
setup_force_cpu_cap(X86_FEATURE_SPLIT_LOCK_DETECT);
}
static bool split_lock_verify_msr(bool on)
{
u64 ctrl, tmp;
if (rdmsrl_safe(MSR_TEST_CTRL, &ctrl))
return false;
if (on)
ctrl |= MSR_TEST_CTRL_SPLIT_LOCK_DETECT;
else
ctrl &= ~MSR_TEST_CTRL_SPLIT_LOCK_DETECT;
if (wrmsrl_safe(MSR_TEST_CTRL, ctrl))
return false;
rdmsrl(MSR_TEST_CTRL, tmp);
return ctrl == tmp;
}
#define MSR_TEST_CTRL 0x00000033
__split_lock_setup 中尝试 enable/disable 33H MSR 进行 verify,结束也并没有 enable split lock #AC exception,而是仅留下一个全局变量 msr_test_ctrl_cache 当作后面操作这个 MSR 的 cache 使用。
static void __init sld_state_setup(void)
{
enum split_lock_detect_state state = sld_warn; // 默认配置
char arg[20];
int i, ret;
if (!boot_cpu_has(X86_FEATURE_SPLIT_LOCK_DETECT) &&
!boot_cpu_has(X86_FEATURE_BUS_LOCK_DETECT))
return;
ret = cmdline_find_option(boot_command_line, "split_lock_detect",
arg, sizeof(arg));
if (ret >= 0) {
for (i = 0; i < ARRAY_SIZE(sld_options); i++) {
if (match_option(arg, ret, sld_options[i].option)) {
state = sld_options[i].state;
break;
}
}
}
sld_state = state;
}
static inline bool match_option(const char *arg, int arglen, const char *opt)
{
int len = strlen(opt), ratelimit;
if (strncmp(arg, opt, len))
return false;
/*
* Min ratelimit is 1 bus lock/sec.
* Max ratelimit is 1000 bus locks/sec.
*/
if (sscanf(arg, "ratelimit:%d", &ratelimit) == 1 &&
ratelimit > 0 && ratelimit <= 1000) {
ratelimit_state_init(&bld_ratelimit, HZ, ratelimit);
ratelimit_set_flags(&bld_ratelimit, RATELIMIT_MSG_ON_RELEASE);
return true;
}
return len == arglen;
}
sld_state_setup 做的是解析出内核启动参数 split_lock_detect 的配置(可以看到默认的配置是 warn 级别),如果是 ratelimit 配置,会使用内核的 ratelimit 库初始化一个 bld_ratelimit 全局变量给 handle 阶段用。
3.3.2 初始化
-> start_kernel
-> init_intel
-> split_lock_init
-> bus_lock_init
setup 完成基本的 verify 和获取启动参数配置后,会尝试进行硬件 enbale 操作。
3.3.2.1 split lock init
static void split_lock_init(void)
{
/*
* #DB for bus lock handles ratelimit and #AC for split lock is
* disabled.
*/
if (sld_state == sld_ratelimit) {
split_lock_verify_msr(false);
return;
}
if (cpu_model_supports_sld)
split_lock_verify_msr(sld_state != sld_off);
}
split lock 的 init 中,如果发现配置的参数是 ratelimit,会 disable split lock 的硬件检测。其他非 off 参数(warn、fatal)则会 enable 硬件。
3.3.2.2 bus lock init
static void bus_lock_init(void)
{
u64 val;
/*
* Warn and fatal are handled by #AC for split lock if #AC for
* split lock is supported.
*/
if (!boot_cpu_has(X86_FEATURE_BUS_LOCK_DETECT) ||
(boot_cpu_has(X86_FEATURE_SPLIT_LOCK_DETECT) &&
(sld_state == sld_warn || sld_state == sld_fatal)) ||
sld_state == sld_off)
return;
/*
* Enable #DB for bus lock. All bus locks are handled in #DB except
* split locks are handled in #AC in the fatal case.
*/
rdmsrl(MSR_IA32_DEBUGCTLMSR, val);
val |= DEBUGCTLMSR_BUS_LOCK_DETECT;
wrmsrl(MSR_IA32_DEBUGCTLMSR, val);
}
#define DEBUGCTLMSR_BUS_LOCK_DETECT (1UL << 2)
bus lock 的 init 中,如果 CPU 不支持 bus lock 则不会 enable bus lock 的硬件检测,如果 CPU 同时支持 split lock 与 bus lock 的硬件检测并且配置参数还是 warn 或 fatal 时也不会 enable 硬件。
所以从代码看 enable CPU 的 bus lock 检测情况有两种:一是 CPU 支持 bus lock 检测的情况下并且配置参数指定为 ratelimt,二是 CPU 不支持 split lock 检测但支持 bus lock 检测并且配置参数非 off。
3.3.3 处理
3.3.3.1 split lock handle
DEFINE_IDTENTRY_ERRORCODE(exc_alignment_check)
{
char *str = "alignment check";
if (notify_die(DIE_TRAP, str, regs, error_code, X86_TRAP_AC, SIGBUS) == NOTIFY_STOP)
return;
if (!user_mode(regs)) // 如果不是用户态
die("Split lock detected\n", regs, error_code);
local_irq_enable();
if (handle_user_split_lock(regs, error_code))
goto out;
do_trap(X86_TRAP_AC, SIGBUS, "alignment check", regs,
error_code, BUS_ADRALN, NULL);
out:
local_irq_disable();
}
bool handle_user_split_lock(struct pt_regs *regs, long error_code)
{
if ((regs->flags & X86_EFLAGS_AC) || sld_state == sld_fatal)
return false;
split_lock_warn(regs->ip);
return true;
}
static void split_lock_warn(unsigned long ip)
{
pr_warn_ratelimited("#AC: %s/%d took a split_lock trap at address: 0x%lx\n",
current->comm, current->pid, ip);
/*
* Disable the split lock detection for this task so it can make
* progress and set TIF_SLD so the detection is re-enabled via
* switch_to_sld() when the task is scheduled out.
*/
sld_update_msr(false);
set_tsk_thread_flag(current, TIF_SLD);
}
#AC exception 产生后,如果不是用户态,会调用 die,进入 panic 流程。
如果是在用户态,那么配置为 fatal 时就会向当前用户态进程发送 SIGBUS 信号,用户态进程不手动捕获 SIGBUS 就会被 kill。
如果是用户态,配置为 warn 时,会打印一条警告日志并输出当前进程信息,同时 disable split lock 的检测,并通过设置当前进程 flags 的 TIF_SLD 位表示这个进程已经被检测过一次了。
-> context_switch
-> __switch_to_xtra
void __switch_to_xtra(struct task_struct *prev_p, struct task_struct *next_p)
{
unsigned long tifp, tifn;
tifn = read_task_thread_flags(next_p);
tifp = read_task_thread_flags(prev_p);
if ((tifp ^ tifn) & _TIF_SLD)
switch_to_sld(tifn);
}
void switch_to_sld(unsigned long tifn)
{
sld_update_msr(!(tifn & _TIF_SLD));
}
在 context_switch 进行进程切换时,如果 prev 进程和 next 进程的 flags 中 TIF_SLD 位不同,那么就会进行 split lock detect 的切换,切换的依据是 next 进程的 TIF_SLD 位。
举个例子,CPU 0 上进程 A 在触发了一次 split lock 的 warn 检测后,CPU 0 的 split lock 检测会被 disable,避免频繁产生警告日志,进程 A 的 flags 置位 TIF_SLD,进程 A 执行完成后,切换到进程 B 运行在 CPU 0 上,切换时由于 A 与 B 的 flags 的 TIF_SLD 位不同,我们就再根据进程 B 的 flags 来 enable split lock 的检测,进程 B 执行完成后,再次切换到进程 A 运行时,会再 disable split lock。
上面的机制就实现了每个进程只 warn once 的需求。
3.3.3.2 bus lock handle
static __always_inline void exc_debug_user(struct pt_regs *regs,
unsigned long dr6)
{
/* #DB for bus lock can only be triggered from userspace. */
if (dr6 & DR_BUS_LOCK)
handle_bus_lock(regs);
}
void handle_bus_lock(struct pt_regs *regs)
{
switch (sld_state) {
case sld_off:
break;
case sld_ratelimit:
/* Enforce no more than bld_ratelimit bus locks/sec. */
while (!__ratelimit(&bld_ratelimit))
msleep(20);
/* Warn on the bus lock. */
fallthrough;
case sld_warn:
pr_warn_ratelimited("#DB: %s/%d took a bus_lock trap at address: 0x%lx\n",
current->comm, current->pid, regs->ip);
break;
case sld_fatal:
force_sig_fault(SIGBUS, BUS_ADRALN, NULL);
break;
}
}
#DB trap 产生后,warn 和 fatal 的流程和#AC 基本差不多,我们这里重点分析 ratelimit,这也是引入 bus lock 的一个强需求。
强制把 bus lock 产生的频率降低到配置的 ratelimit。原理就是如果频率超出设定,就直接 sleep 20 ms,直到频率降下来(这里的频率是整个系统产生 bus lock 的频率)。
降频过后通过编译器的 fallthrough 流入 sld_warn case 产生一条警告日志。
4. 虚拟化环境的检测与处理
前面的分析都是针对物理机上的内核与用户态程序(VMX root mode)。在虚拟化环境中需要再考虑一些问题,比如如果 split lock 来自于 Guest 中,Host 如何检测?怎么避免对其他 Guest 的影响?如果直接在 Host 上 enable bus lock ratelimit,可能会影响没有准备好的 Guest。如果直接把 split lock 的检测开关暴露给 Guest,Host 或其他 Guest 怎么处理等等。
CPU 可以在 VMX mode 下支持 split lock 检测的#AC trap,后面具体怎么做由 hypervisor 决定。大部分 hypervisor 会直接把 trap 转发到 Guest 中,如果 Guest 没有准备好,可能会产生 crash。之前的 VMX 版本中就有这个问题。
因此首先就要让 hypervisor 正确处理 trap。
4.1 虚拟化环境处理流程
下面是虚拟化环境对 split lock 与 bus lock 的整体处理流程图:
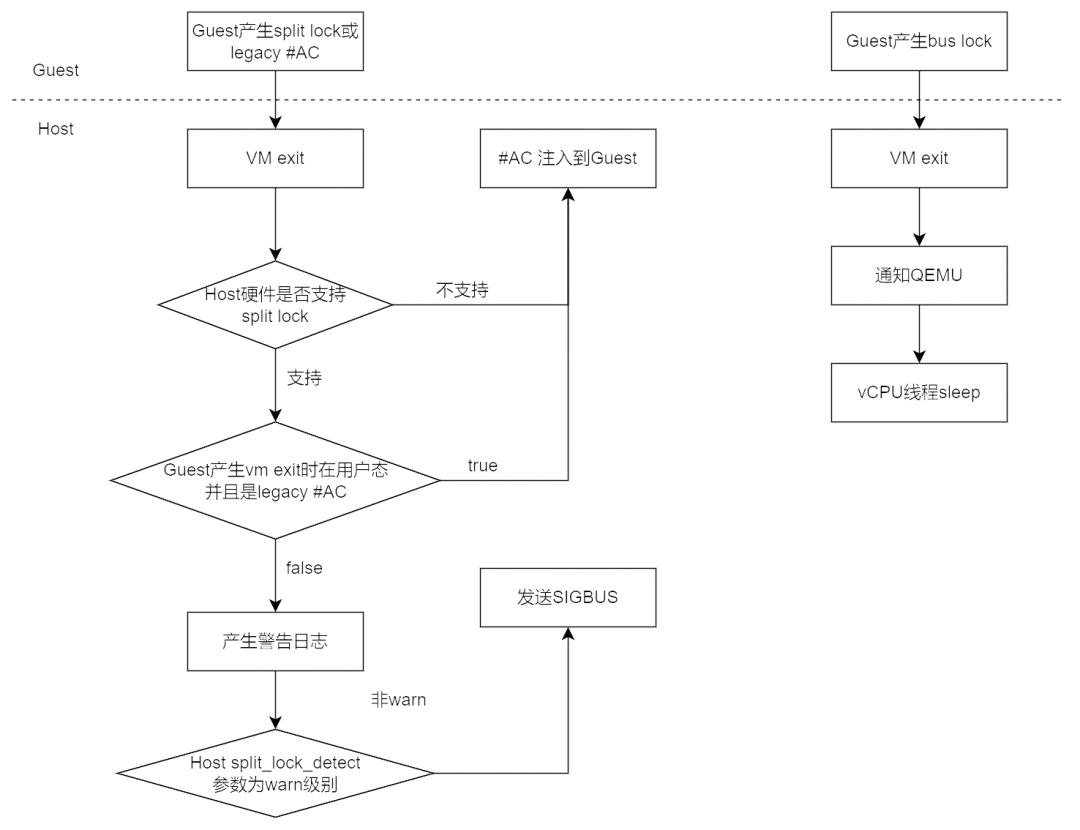
Guest 中尝试 split lock 操作,会 vm exit 到 kvm 中,如果硬件不支持 split lock 检测或者为 legacy #AC,会把#AC 注入给 Guest 处理,如果硬件支持检测,那么会根据配置产生警告,甚至尝试 SIGBUS。
Guest 进行 bus lock 后,会 vm exit 到 kvm 中,kvm 通知 QEMU,vCPU 线程会主动进行 sleep 降频。
下面我们再自底向上进行分析。
4.2 硬件支持
4.2.1 split lock

#AC exception 被包含在 NMI exit reason 里面。
4.2.2 bus lock

在 VMX non-root mode 下,CPU 检测到 bus lock 后会产生 VM exit,reason 为 74。
4.3 KVM 支持
-> vmx_handle_exit
-> __vmx_handle_exit
-> kvm_vmx_exit_handlers
-> handle_exception_nmi // split lock
-> handle_bus_lock_vmexit // bus lock
4.3.1 split lock
static int handle_exception_nmi(struct kvm_vcpu *vcpu)
{
switch (ex_no) {
case AC_VECTOR:
if (vmx_guest_inject_ac(vcpu)) {
kvm_queue_exception_e(vcpu, AC_VECTOR, error_code);
return 1;
}
/*
* Handle split lock. Depending on detection mode this will
* either warn and disable split lock detection for this
* task or force SIGBUS on it.
*/
if (handle_guest_split_lock(kvm_rip_read(vcpu)))
return 1;
}
// Guest handle
bool vmx_guest_inject_ac(struct kvm_vcpu *vcpu)
{
if (!boot_cpu_has(X86_FEATURE_SPLIT_LOCK_DETECT))
return true;
return vmx_get_cpl(vcpu) == 3 && kvm_read_cr0_bits(vcpu, X86_CR0_AM) &&
(kvm_get_rflags(vcpu) & X86_EFLAGS_AC);
}
// KVM handle
bool handle_guest_split_lock(unsigned long ip)
{
if (sld_state == sld_warn) {
split_lock_warn(ip);
return true;
}
pr_warn_once("#AC: %s/%d %s split_lock trap at address: 0x%lx\n",
current->comm, current->pid,
sld_state == sld_fatal ? "fatal" : "bogus", ip);
current->thread.error_code = 0;
current->thread.trap_nr = X86_TRAP_AC;
force_sig_fault(SIGBUS, BUS_ADRALN, NULL);
return false;
}
Guest 内部产生 split lock 操作时,由于是#AC exception,会 VM exit 出来。
这里首先要说明一下#AC exception 本身有两种类型:
- legacy #AC exception
- split lock #AC exception
KVM 根据 Host 和 Guest 状态最终产生两种行为:
- 让 Guest 处理:把#AC 注入到 Guest 中。
- 如果硬件不支持 split lock 检测,无条件注入到 Guest 中。
- 如果 Host enable 了 split lock 检测,则只有在产生#AC exception 为 Guest 用户态且为 legacy #AC 情况下才会注入到 Guest 中。
- 让 HOST 处理:产生警告甚至发送 SIGBUS。
- 不注入到 Guest 中时,Host 如果配置的是 warn 则每个 vCPU 线程只 warn 一次,如果配置的是 fatal 则产生 SIGBUS。
4.3.2 bus lock
#define EXIT_REASON_BUS_LOCK 74
static int (*kvm_vmx_exit_handlers[])(struct kvm_vcpu *vcpu) = {
[EXIT_REASON_BUS_LOCK] = handle_bus_lock_vmexit,
}
static int handle_bus_lock_vmexit(struct kvm_vcpu *vcpu)
{
/*
* Hardware may or may not set the BUS_LOCK_DETECTED flag on BUS_LOCK
* VM-Exits. Unconditionally set the flag here and leave the handling to
* vmx_handle_exit().
*/
to_vmx(vcpu)->exit_reason.bus_lock_detected = true;
return 1;
}
union vmx_exit_reason {
struct {
u32 basic : 16;
u32 reserved16 : 1;
u32 reserved17 : 1;
u32 reserved18 : 1;
u32 reserved19 : 1;
u32 reserved20 : 1;
u32 reserved21 : 1;
u32 reserved22 : 1;
u32 reserved23 : 1;
u32 reserved24 : 1;
u32 reserved25 : 1;
u32 bus_lock_detected : 1;
u32 enclave_mode : 1;
u32 smi_pending_mtf : 1;
u32 smi_from_vmx_root : 1;
u32 reserved30 : 1;
u32 failed_vmentry : 1;
};
u32 full;
};
VM exit 后,执行根据 reason 74 索引的函数 handle_bus_lock_vmexit,其中仅仅是把 exit_reason 的 bus_lock_detected 置位。
static int vmx_handle_exit(struct kvm_vcpu *vcpu, fastpath_t exit_fastpath)
{
int ret = __vmx_handle_exit(vcpu, exit_fastpath);
/*
* Exit to user space when bus lock detected to inform that there is
* a bus lock in guest.
*/
if (to_vmx(vcpu)->exit_reason.bus_lock_detected) {
if (ret > 0)
vcpu->run->exit_reason = KVM_EXIT_X86_BUS_LOCK;
vcpu->run->flags |= KVM_RUN_X86_BUS_LOCK;
return 0;
}
return ret;
}
执行完__vmx_handle_exit 后,检测到 bus_lock_detected 置位后会设置返回给用户态的 exit_reason 和 flags。
4.4 QEMU 支持
以 v6.2.0 版本为例进行分析:
-> kvm_cpu_exec
-> kvm_vcpu_ioctl
-> kvm_arch_post_run
-> kvm_arch_handle_exit
int kvm_arch_handle_exit(CPUState *cs, struct kvm_run *run)
{
switch (run->exit_reason) {
case KVM_EXIT_X86_BUS_LOCK:
/* already handled in kvm_arch_post_run */
ret = 0;
break;
}
}
MemTxAttrs kvm_arch_post_run(CPUState *cpu, struct kvm_run *run) {
if (run->flags & KVM_RUN_X86_BUS_LOCK) {
kvm_rate_limit_on_bus_lock();
}
}
static void kvm_rate_limit_on_bus_lock(void)
{
uint64_t delay_ns = ratelimit_calculate_delay(&bus_lock_ratelimit_ctrl, 1);
if (delay_ns) {
g_usleep(delay_ns / SCALE_US);
}
}
QEMU 通过 KVM 返回值了解到 Guest 中有 bus lock 产生,进入 kvm_rate_limit_on_bus_lock 中,也是通过 sleep 实现 ratelimit,达到降低 Guest 产生 bus lock 频率的效果。
Host 上的 ratelimit 是通过 split_lock_detect 启动参数来控制的,那么 Guest 呢?
int kvm_arch_init(MachineState *ms, KVMState *s) {
if (object_dynamic_cast(OBJECT(ms), TYPE_X86_MACHINE)) {
X86MachineState *x86ms = X86_MACHINE(ms);
if (x86ms->bus_lock_ratelimit > 0) {
ret = kvm_check_extension(s, KVM_CAP_X86_BUS_LOCK_EXIT);
if (!(ret & KVM_BUS_LOCK_DETECTION_EXIT)) {
error_report("kvm: bus lock detection unsupported");
return -ENOTSUP;
}
ret = kvm_vm_enable_cap(s, KVM_CAP_X86_BUS_LOCK_EXIT, 0,
KVM_BUS_LOCK_DETECTION_EXIT);
if (ret < 0) {
error_report("kvm: Failed to enable bus lock detection cap: %s",
strerror(-ret));
return ret;
}
ratelimit_init(&bus_lock_ratelimit_ctrl);
ratelimit_set_speed(&bus_lock_ratelimit_ctrl,
x86ms->bus_lock_ratelimit, BUS_LOCK_SLICE_TIME);
}
}
}
static void x86_machine_get_bus_lock_ratelimit(Object *obj, Visitor *v,
const char *name, void *opaque, Error **errp)
{
X86MachineState *x86ms = X86_MACHINE(obj);
uint64_t bus_lock_ratelimit = x86ms->bus_lock_ratelimit;
visit_type_uint64(v, name, &bus_lock_ratelimit, errp);
}
static void x86_machine_class_init(ObjectClass *oc, void *data)
{
object_class_property_add(oc, X86_MACHINE_BUS_LOCK_RATELIMIT, "uint64_t",
x86_machine_get_bus_lock_ratelimit,
x86_machine_set_bus_lock_ratelimit, NULL, NULL);
}
#define X86_MACHINE_BUS_LOCK_RATELIMIT "bus-lock-ratelimit"
QEMU 对 Guest bus lock 的 ratelimit 从启动参数 bus-lock-ratelimit 中获取。
4.5 Libvirt 支持
Libvirt 支持 QEMU 的 bus-lock-ratelimit 启动参数目前还没 upsteam:
https://listman.redhat.com/archives/libvir-list/2021-December/225755.html
5. 总结
由于 X86 硬件的特性,支持跨 cache line 的原子语义,实现上需要用 split lock 维持原子性,但这却需要以整个系统的访存性能为代价。开发者逐渐意识到这个 feature 害人不浅,尽量不去使用,比如内核的开发者保证自己不会产生 split lock,甚至不惜内核 panic。而用户态程序则会产生警告,然后降低程序的执行频率或者由内核进行 kill。虚拟化环境由于软件栈较多,会尽量由 Host 侧 KVM 与 QEMU 处理,进行告警甚至 kill 虚拟机,或通知 QEMU 进行降频。
References
- https://www.agner.org/optimize/instruction_tables.pdf
- https://www.kernel.org/doc/html/latest/x86/buslock.html
- https://en.wikipedia.org/wiki/Cache_coherence
- https://lwn.net/Articles/790464/
- https://lwn.net/Articles/850011/
- https://lwn.net/Articles/816918/
- https://lore.kernel.org/all/20200410115517.176308876@linutronix.de/T/#mb0a765c7b9799d1a06d54d31f4a47db15c01ecde
- https://lore.kernel.org/all/20200131200134.GD18946@linux.intel.com/T/#u
关于我们
我们是字节跳动基础架构内核与虚拟化团队,既对内服务字节跳动的业务,也负责构建火山引擎云计算平台的底层系统。我们的职责包括:虚拟化平台和底层 OS 的研发、优化虚拟化与内核的性能来提高系统的资源利用率、支撑定位虚拟化与内核问题提高稳定性,进行虚拟化与内核的前沿技术探索。
我们的 base 包括杭州、北京、深圳、成都,欢迎扫描下方二维码加入我们!

对文章信息或招聘相关咨询可以联系 wangnan.light@bytedance.com