




作者:火山引擎AML团队
模型训练痛点
关于模型训练的痛点,首先是技术上的。现在机器学习应用非常广泛,下表给出了几种典型的应用,包括自动驾驶、蛋白质结构预测、推荐广告系统、NLP 等。
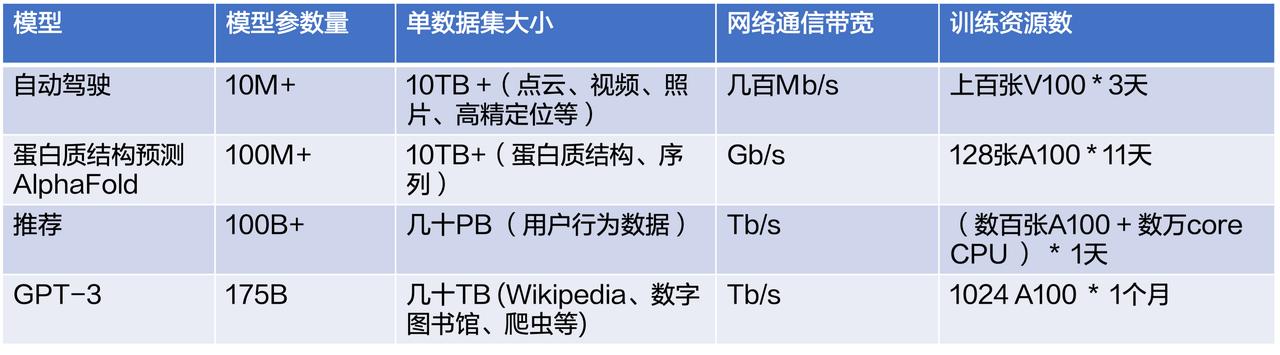
可以看到不同应用场景下的参数和数据集、模型训练过程中的网络通信带宽、训练资源数和时长都不尽相同。所以面对丰富的机器学习应用,我们的需求是多样的。针对这些需求,底层的计算、存储、网络等基础设施要提供强大的硬件,同时在这些硬件基础上还要提供强大的调度能力,才能为各种需求提供较好的服务,使集群利用率维持在较高水平。
模型训练的第二个痛点是偏管理上的。比如在算法问题上,一个方法比另外一好,其中的原因多种多样,可能是基础架构不同,也可能是算法不同。在字节跳动的实践中发现,基础架构对性能或迭代效率有影响,但大部分情况下对算法效果不应该有影响。我们不希望在算法对比过程中引入基础架构的差异,所以希望有统一的基础架构。而且基础架构本身投入比较大,做多套也没有必要。
其次,如果想对产品的某些地方进行改进,如何先复现实验结果?团队不同的人做了不同的实验,如何对这些实验进行对比?这些都是有挑战的事情。
这些管理问题其实也是机器学习模型训练过程中比较大的痛点。本文将针对这些痛点,介绍我们如何进行机器学习平台的架构设计。
云原生机器学习平台架构设计
我们主要在两方面做了投入:一是高性能计算和存储的规模化调度;二是模型分布式训练的加速。
高性能计算和存储的规模化调度——挑战
计算侧
在高性能计算方面,调度的挑战是非常大的。
前面已经说过,我们的需求多种多样,这就导致在计算侧,首先会有各种新硬件。比如有 CPU 也有 GPU,还有多种不同类型的网卡。
同时云原生的虚拟化也会产生损耗。火山引擎机器学习平台公有云上的系统,云原生本身会带来一些虚拟化损耗,比如网络和容器会进行一定的虚拟化,存储的分层池化也会带来负载均衡的问题。
繁多的分布式训练框架:火山引擎机器学习平台的用户很多,不同的任务有不同的分布式训练框架,包括数据并行的框架(TensorflowPS、Horovod、PyTorchDDP、BytePS 等),模型并行的框架(Megatron-LM、DeepSpeed、veGiantModel 等),HPC 框架(Slurm、MPI 等)以及其他框架(SparkML、Ray 等)。不同的训练框架有各自的调度和资源要求,这就给底层基础设施带来一些挑战。
存储侧
存储可以认为是机器学习的刚需,在存储侧面临的挑战也很大:
- 高性能和扩展性:现在的硬件计算能力越来越快,读数据的吞吐需要跟上高性能的计算,对存储的要求也就非常高,比如需要单租户百 Gb/s 的带宽吞吐以及亚毫秒级的延迟。同时随着大模型训练的普及,需要存储的容量能达到 PB 级别;为了提升模型训练的效率,需要数千个计算实例能同时访问的高性能共享存储。这些都给存储带来了非常大的压力。
- 易用性:在使用一些框架的时候我们希望读写存储能够像读本地文件一样方便,这就需要存储接口友好 , 代码零修改,兼容 POSIX。同时能便捷传输,方便数据上云下云。有一些客户对安全性有要求,客户之间的存储要进行隔离。
- 存储的成本也很重要。
高性能计算和存储的规模化调度
我们是如何应以上这些挑战的呢?
专为 AI 优化的高性能计算集群
大型模型的训练需要具备高性能与高可用性的计算集群支撑。因此我们搭建了火山引擎 AI 异构计算平台,提供面向 AI 场景优化的超算集群。
- 超大算力池: 搭载英伟达 Tesla A100 80GB/A30/V100/T4;2TB CPU Mem;单一集群 2000+ GPU 卡,提供 1 EFLOPS 算力。
- 超强网络性能: 机内 600GBps 双向 NVLink 通道,800Gbps RDMA 网络高速互联,支持 GPU Direct Access。
- 并行文件系统 vePFS: 百 Gb 带宽,亚毫秒延迟,支持数亿小文件随机读取。
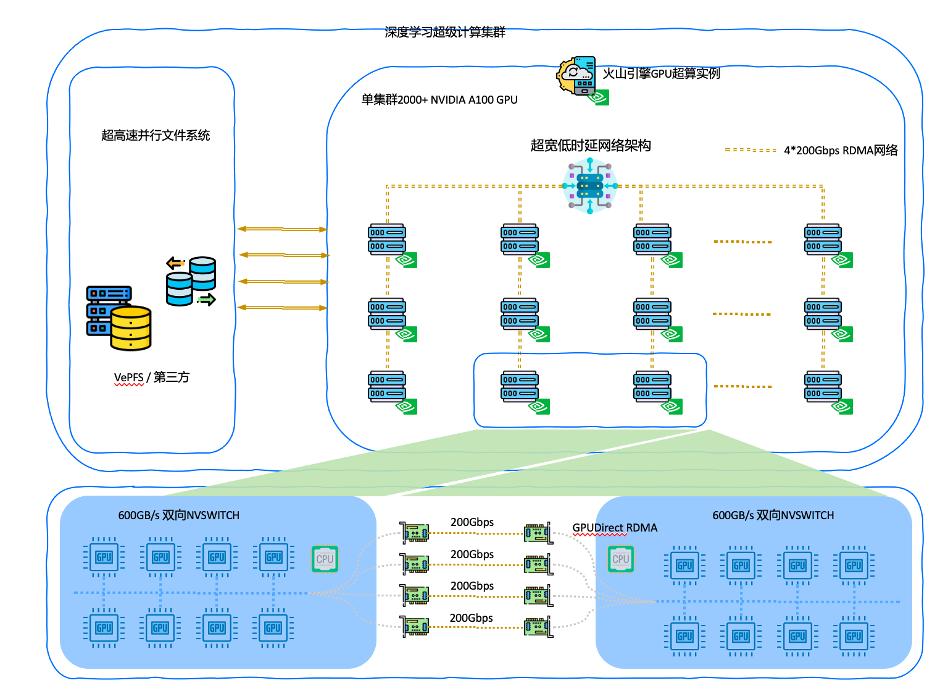
资源池化,按需弹性创建计算资源
在强大的硬件之上,调度侧首先需要对资源(包括计算资源和存储资源)进行池化。火山引擎机器学习平台有一个大的计算池,里面有大量 GPU 和 CPU。在保证不同用户计算容器间的隔离的前提下,不同的 toB 客户共享整个资源池,从而提高集群的利用率,保证每个客户的申请率可接近 100%。
平台提供的资源包括虚拟机资源、裸金属资源。有的资源之间需要一些亲和性,有的资源就是单独的任务。除了正常的训练资源,还有一些开发机的资源。因为开发机资源如果不做池化,往往会带来比较大的资源浪费。
编排调度引擎
机器学习的调度需求比较复杂。比如一次分布式训练,有 Worker、Server 和 Scheduler 角色的实例。在调度时,它需要 Gang 调度的能力,所有实例(或其中某一种角色的实例)要么都起来,要么都不起来。同时在训练过程中还需要网络的亲和性。例如同一个分布式训练的容器,申请到的资源能在一台机器肯定是最好。申请多台机器时,这些机器之间的网络连接肯定是越近越好。所以在调度上我们有一些相应的调度策略,包括多队列调度(排队、抢占)、Gang 调度、堆叠调度等。
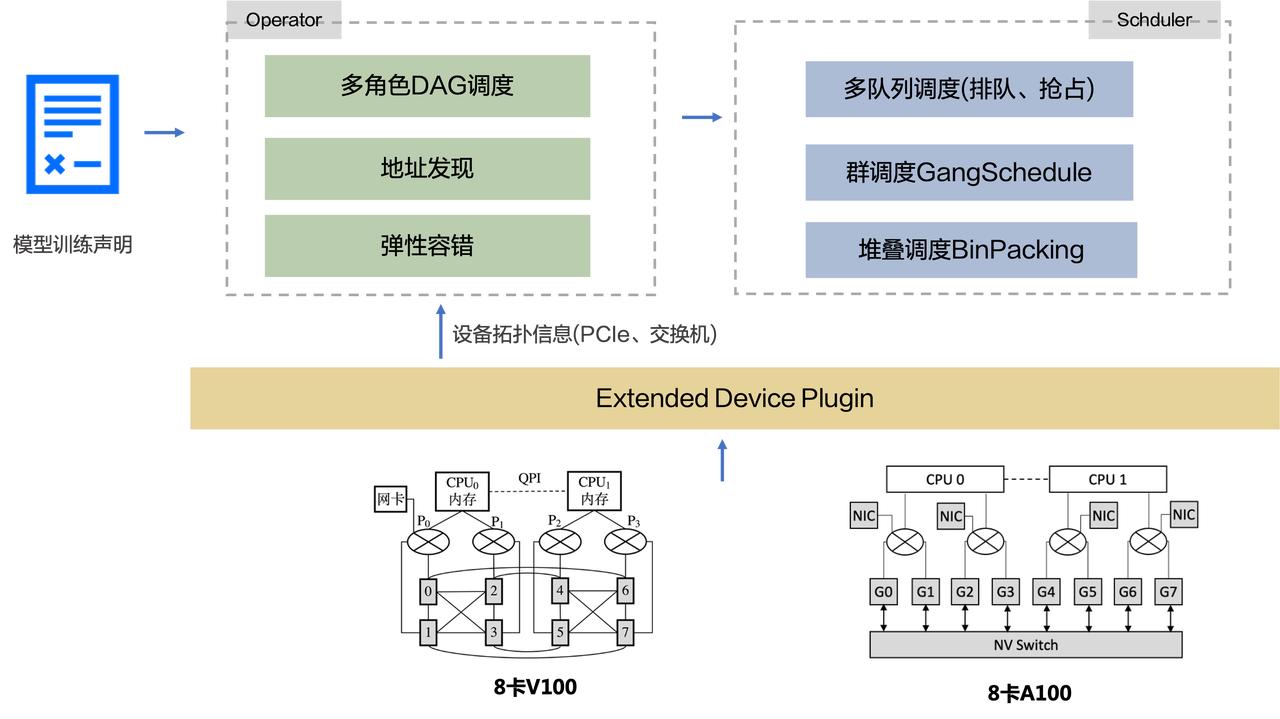
云原生存储
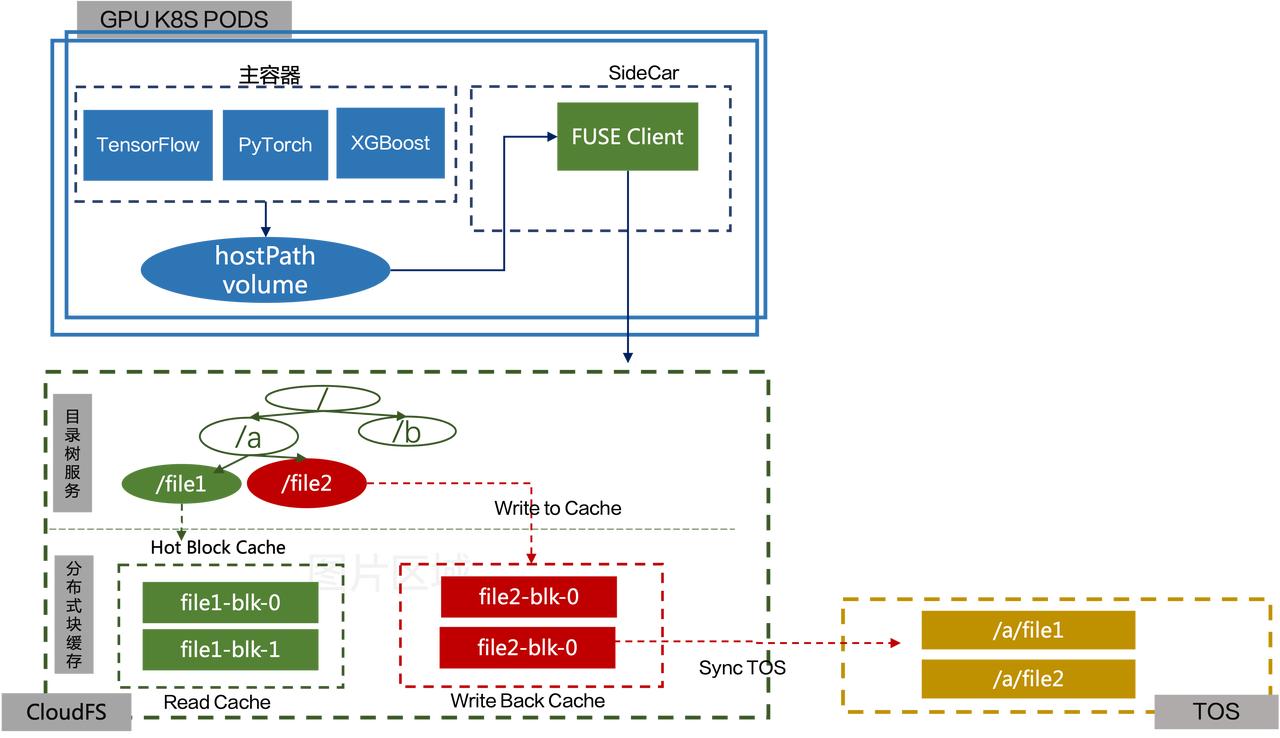
TOS 是我们的底层存储,其容量非常大。直接通过程序读 TOS 往往不太方便,需要有一层缓存的能力。因此我们加了一层 CloudFS 来提供程序和 TOS 之间的透明缓存加速。CloudFS 提供了:
- FUSE Client:提供 Posix 文件系统接口,支持模型训练场景常用 API;同时提供 PageCache,百 GB 的数据集,第 2 个 epoch 获得内存级性能。
- 分布式 Blob 缓存:和 GPU 机器就近部署,保证百 Gbps 带宽和亚毫秒级延迟保障;支持 warmup 预热,解决首个 epoch 性能问题。
- 分布式目录树服务:为平铺的 TOS 文件建立目录树结构;可支撑百万 QPS,专为小文件优化。
这里我们用一个实验来证明整体损耗情况。
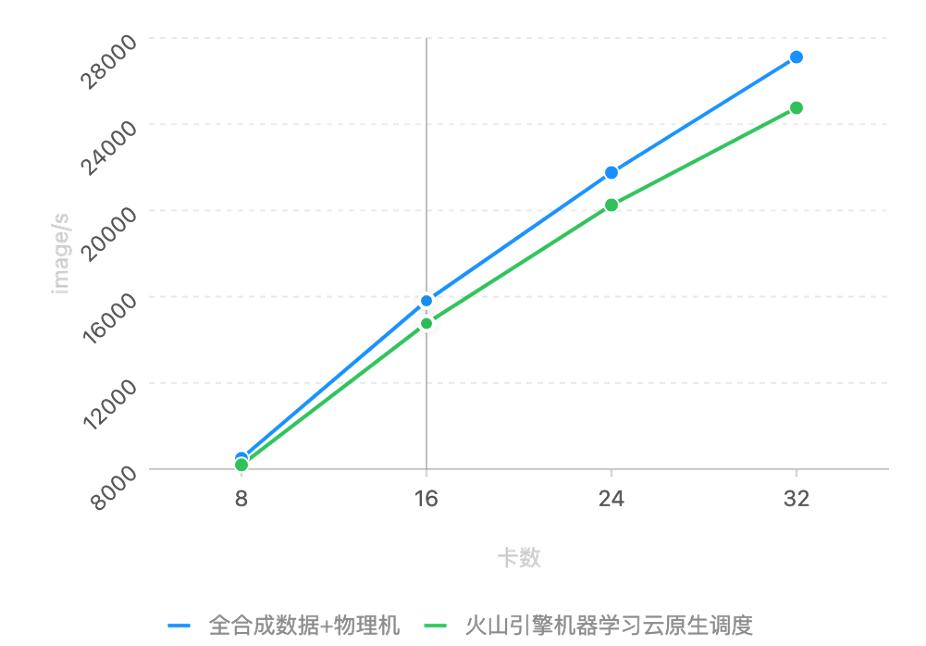
该实验是一个多机多卡的分布式训练场景。图中的蓝线表示没有任何的文件 IO,因为数据都是 mock 的,不需要从磁盘上读。另外它基于物理机,所以没有虚拟化的损耗。绿线是真实的训练场景,数据需通过 IO 读进来。它是基于云原生的系统,有一些网络虚拟化。
从图中可以看到绿线和蓝线非常接近,说明我们整体的 IO 和虚拟化带来的损耗其实非常小。
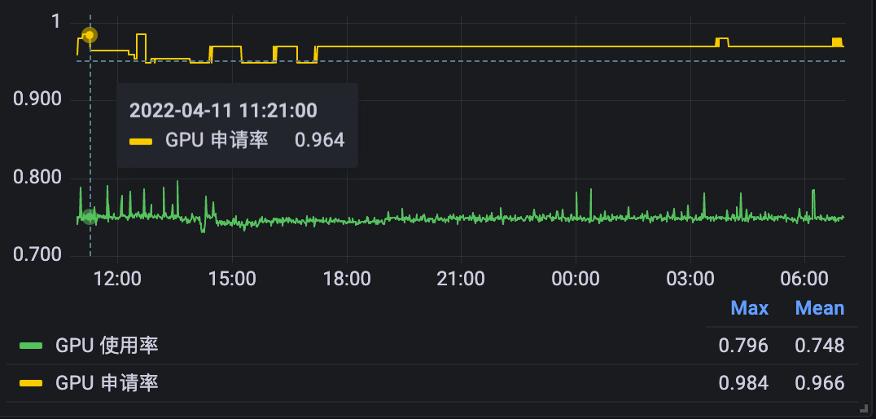
上图是某真实用户的线上申请率,可以看到申请率可以达到 95% 以上。这里的利用率其实是由客户的代码自己决定的。
模型分布式训练加速
在分布式训练中,加速方式主要从计算、通信、显存三个角度考虑。
在计算侧:因为 GPU 训练用的非常多,所以我们有一个高性能算子库,自主研发了很多中细粒度高性能算子,包括 norm、attention 等,这些算子的性能往往比好的开源实现有非常明显的提升。
在通信上:我们开源了 BytePS 的通信框架。BytePS 同时利用了 CPU 和 GPU 两种异构资源来加速通信,在对拓扑的探测上做了细致和智能的优化,并且支持异步和同步两种训练模式。
在显存侧:主要针对超大模型的场景,我们也开源了 veGiantModel,支持混合并行的策略,包括数据并行,Tensor 并行和流水线并行;可根据参数量、计算量自动切分流水线。veGiantModel 的底层是基于 BytePS 做加速的。
下面对 BytePS 和 veGiantModel 展开做介绍。
BytePS 通信优化
分布式机器学习领域当中,有两种常见的通信训练架构:一种是 PS 架构,在推荐广告场景使用比较广泛。另一种是 All-Reduce,在基于 GPU 的同步训练场景使用较多。BytePS 综合了这两种通信的特点,同时利用了异构的 GPU 和 CPU 机器,在集群中能提供比以上两种现有架构更高的通信效率。
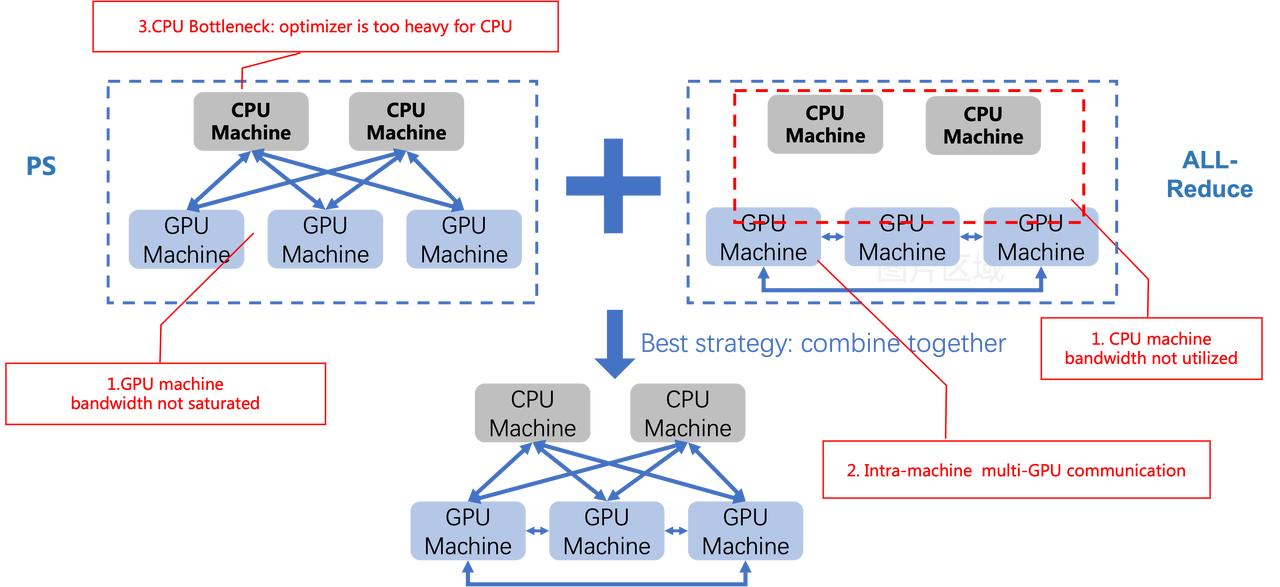
BytePS 跨机通信的核心优化思路,在于充分利用每一台 GPU/CPU 机器的网络带宽。为了实现这一点,BytePS 设计了一套精确的梯度分配方案,将要通信的梯度恰到好处地分配给所有 GPU 和 CPU 机器执行规约操作。从通信流量上看,相当于同时结合了 PS 和 All-Reduce 两种通信模式。
BytePS 机内通信的核心优化思路,在于充分结合机器内部 GPU 以及网卡互联的拓扑,在关键的 PCIe 瓶颈路径上避免流量的竞争,以此使网卡带宽能够被充分打满。
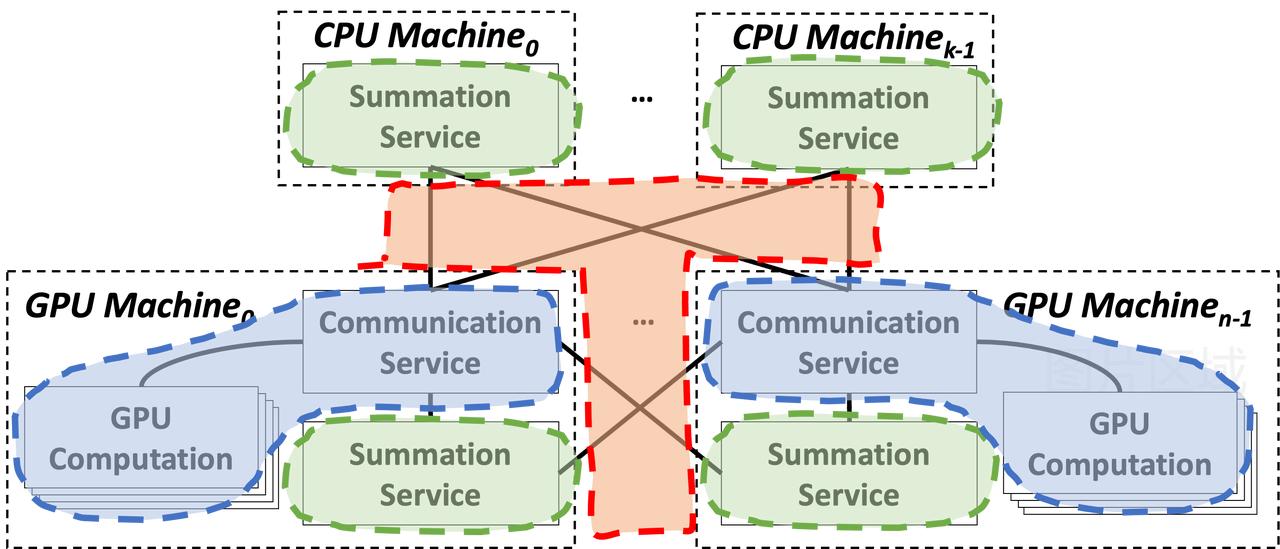
为此,BytePS 设计了一个 Communication Service 模块,位于 GPU 机器上,它的作用一是负责机内流量的聚合,二是负责跨机负载分配和梯度的分发。相应地,BytePS 在每个 GPU 和 CPU 机器上,都设置了一个 Summation Service,负责接收来自其他机器的梯度并做规约聚合,再将结果返回给发送端。该 Summation Service 模块只需运行在 CPU 上,而优化器更新参数的部分则被分配到GPU 上进行,以此克服在 CPU 上更新参数会遇到的内存带宽瓶颈问题。
BytePS 的整体架构以及 Communication Service 和 Summation Service 的交互方式如下所示。红色部分表示跨机通信,蓝色部分表示机内通信,绿色则是纯 CPU 部分的操作和优化。
我们评估了单机 8 卡,到 256 块 GPU 的扩展能力。分别使用 TensorFlow、MXNet 和 PyTorch 实现了当前主流的 CV 和 NLP 模型。结果表明,BytePS 在所有情况下都有增益,且规模越大收益就越高;额外添加 CPU Server 节点时,还可以获得进一步增益。总体而言,BytePS 在典型任务上的性能超过 All-Reduce 和 PS 高达 84% 和 245%。
BytePS 已经开源,地址:https://github.com/bytedance/byteps


GPU: V100, NVLink, 100Gbps NIC CPU: 96 Core, 512G
veGiantModel
在进行大模型训练时,通讯量大和跨机容易成为 Tensor 并行策略的瓶颈,而流水线并行策略在阶段过多时容易产生气泡,切分不均匀。针对这两个问题,我们研发了 veGiantModel 这个高性能混合并行框架,能大幅降低系统压力。
veGaintModel 利用 NVLink/NVSwitch 的超高速带宽和 BytePS 做通信优化,支持机内 Tensor 并行和跨机数据并行。同时 veGiantModel 可根据参数量、计算量自动切分流水线,以计算覆盖通讯,减少气泡,支持跨机流水线并行。
相比 Megatron 和 DeepSpeed 这两个主流模型并行训练框架,veGiantModel 的性能有 30+% 的提升。
目前 veGiantModel 已经开源,地址 https://github.com/volcengine/veGiantModel
开发过程的标准化和团队协作
最后介绍一下火山引擎机器学习平台如何解决开发过程中,特别是算法团队管理过程中的一些痛点。
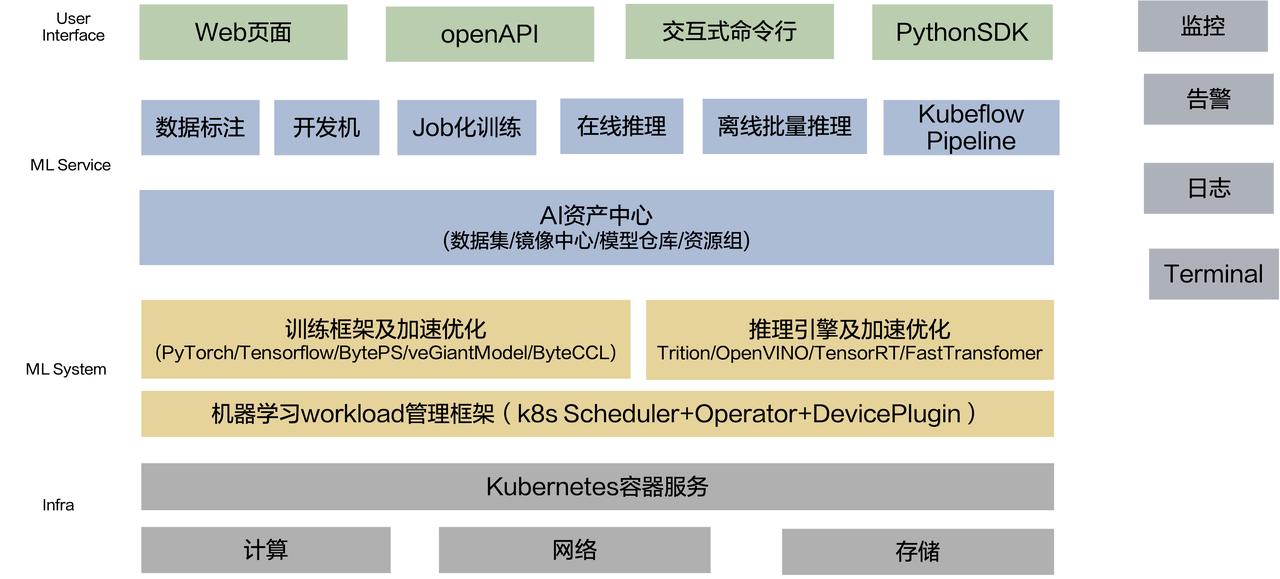
以上是火山引擎机器学习平台的功能示意图。
在用户界面层,平台支持 Web 页面、openAPI、交互式命令行、PythonSDK 等开发方式。
往下一层我们提供了丰富的机器学习功能,包括数据标注、开发机、Job 化训练、离线批量推理、Kubeflow Pipeline 等。
平台底层接入了不同的训练框架,提供不同的加速方案。同时平台也提供监控、告警、日志等功能。
通过火山引擎一站式云原生机器学习平台,就可以实现开发过程标准化。这里我举个例子。很多团队有开发机的需求,但是开发机本身对集群利用率的影响非常大。如果做得不好,会导致大量的卡没有真实跑训练,造成了资源浪费。为了解决这个问题,我们提供了可以对齐 VM 语义的开发机,可以做到:
- 关机语义,重启不丢状态;
- 数据动态挂载:云盘、vePFS、TOS、NAS;
- 无需理解 K8s 容器网络端口逻辑。
开发机基于 Docker 镜像创建开发环境,易用性极强,能一键拉起在线 VSCode、JuypterLab 等 Web IDE。
在 Job 化训练上,前面已经提到了我们有一些分布式框架多角色编排,以及硬件和各种软件的加速方案。同时我们对实验进行数据收集、归档和对比分析,把每一次迭代中涉及到的数据开发环境、代码、产生的模型和日志等数据都进行存储,使用户可以方便复现每次迭代的情况,同时也可以把输出的日志导入 OLAP 引擎中进行分析,从而比较不同实验的效果。这样就可以方便地衡量大家的实际工作情况。
最佳实践
最后介绍一个火山引擎机器学习平台真实客户的最佳实践——在自动驾驶场景中的方案。
该客户之前使用的传统方式遇到了一些痛点:
- 机器分配到人,人肉管理成本高,利用率低;
- 没办法跑大规模分布式训练,模型迭代速度慢;
- 样本数据量大,对象存储、NAS 等多套存储,数据手工拷贝,数据管理成本高。
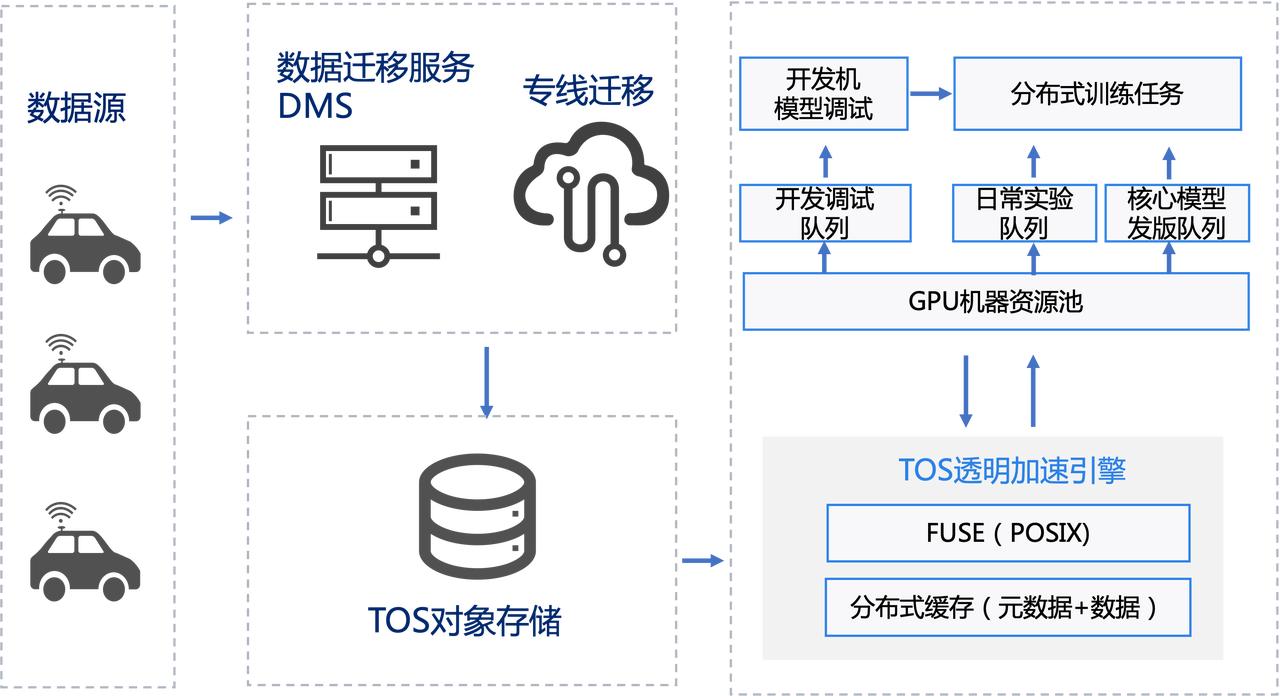
使用火山引擎机器学习平台的方案后:
- 资源池化,排队调度,降低资源闲置;
- BytePS 加速 Onboard 模型(16 卡到 48 卡),收敛速度(96 小时到 30 小时);
- 数据加速,分层存储:
- 数据迁移到 TOS:单价便宜,数据 ETL 写入方便;
- 训练过程中使用 CloudFS 的透明缓存加速。
客户可以方便进行合理的 GPU 资源管理和调度,同时也缩短了算法迭代周期 ,资源利用率提升达到 30%。
火山引擎机器学习平台目前对外公测中,欢迎大家试用 https://www.volcengine.com/product/ml-platform
Q&A
Q:AML 和火山引火山机器学习平台是什么关系?云上卖的平台就是基于 AML 在内部构建的平台吗?
A:云上机器学习平台是由 AML 团队开发的,所以这两者的关系就是 AML 团队开发了这个平台。
AML 团队本身有一些训练任务跑在火山引擎机器学习平台上。平台的核心开发团队和站内是一样的,我们提供的一些加速方案在站内也得到了充分的使用。只是在平台面向外部用户时,界面可能和站内的不一样,但底层的技术都是相通的。
Q:字节的大规模机器学习平台在数据科学家协作时,如何度量各自的资源消耗?
A:资源消耗其实很容易度量。在火山引擎机器学习平台上有详细的 dashboard 监控你申请的卡的利用率、CPU 利用率、内存利用率、GPU 利用率等等,GPU 利用率还有更细致的指标,包括 SM 利用率、功耗、有没有降频等等。大家在训练的时候也可以看到这样的监控,甚至如果你的资源利用率不高,平台还会帮助自动缩容。
Q:开发机重启后原来的进程还能继续吗?还是就相当于关机了?
A:这个跟 VM 的开关机是一样的。原来的进程我理解应该是不在了,但是原来的环境,比如在本地存的文件,在操作系统上安装的应用,这些都是现成的。如果使用开发机训练,其实是没有必要关机的,因为训练过程中利用率是保持住的。
Q:模型推理的加速需要从哪些方面去做?
A:推理加速有几个方面:
- 手工算一次:这种方式肯定是立竿见影的,但是写手工算子对能力有要求,所以一般只会对最重要的模型写手工算子。比如我们主要对 transformer 的手工算子写得很多,而且速度写得也还可以。
- 自动编译:很多长尾模型,不可能每个都去写手工算子。所以对自动编译我们也投入了比较大的精力。
- 除了加速以外,我们觉得推理本身的资源利用率也很重要。比如有的客户一个模型服务的用户不是特别多,但一个模型占一张卡,整体利用率就很难提升上去。在字节内部,我们在推理卡的混部上花了比较多的精力,我们有虚拟卡,也有基于 MPS 的混部能力,可以提高推理的整体利用率。
Q:对于用在搜索广告推荐领域的大规模稀疏模型,AML 平台上有一些深度的针对性优化吗?
A:我们内部的搜广推场景,底层的通信、机器等硬件层面和 CV、语音、NLP 是差不多的方案,谈不上要针对性的优化。如果要针对性的优化,就是我们要不要开源针对搜广推的 GPU 训练代码的问题,因为它的优化都在代码里面。所以在机器学习平台这一层,其实不一定要对它进行什么特别针对性的优化。