




作者|覃量
Client AI 是字节跳动产研架构下属的端智能团队,负责端智能 AI 框架和平台的建设,也负责模型和算法的研发,为字节跳动开拓端上智能新场景。本文介绍的 Pitaya 是由字节跳动的 Client AI 团队与 MLX 团队共同构建的一套端智能工程链路。
什么是 ClientAI- Pitaya ?
-
ClientAI- Pitaya 定位
这些年,随着算法设计和设备算力的发展,AI 的端侧应用逐步从零星的探索走向规模化应用。行业里,FAANG、BATZ 都有众多落地场景,或是开创了新的交互体验,或是提升了商业智能的效率。
Client AI是字节跳动产研架构下属的端智能团队,负责端智能AI框架和平台的建设,也负责模型和算法的研发,为字节跳动开拓商业智能 新场景。
Pitaya则是由字节跳动的Client AI 团队与 MLX 团队共同构建的一套端智能工程链路 ,为端智能应用提供从开发到部署的全链路支持。
Pitaya的愿景是打造行业领先的端智能技术,助力字节智能商业化应用。我们通过 AI 工程链路为端智能业务提供全链路支持;通过 AI 技术方案,帮助业务提升指标、降低成本、改善用户体验。
迄今为止,Pitaya 端智能已经为抖音、头条、西瓜、小说等应用的 30+场景提供了端智能支持,让端智能算法包在手机端每天万亿生效次数的同时,错误率控制在不到十万分之一。

-
Pitaya 架构
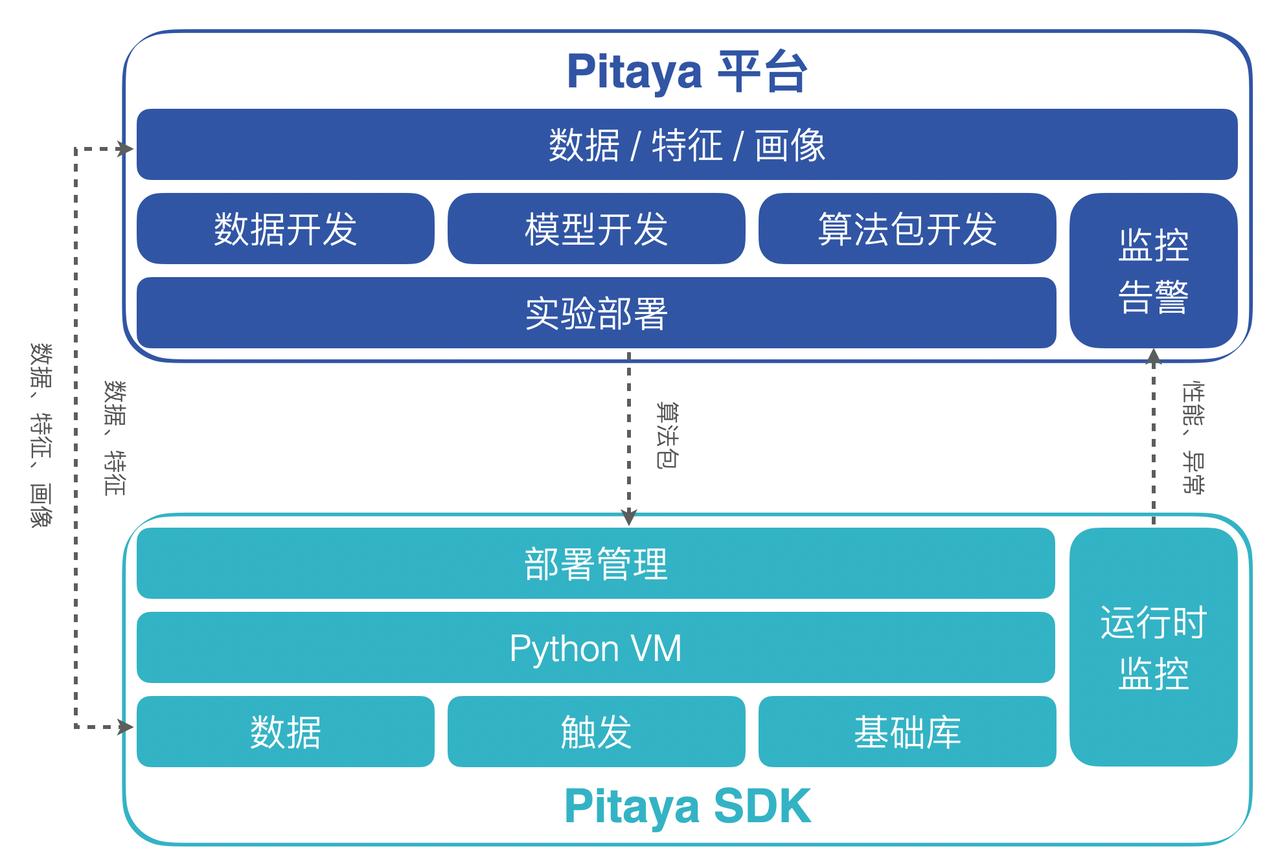
在这一节我们来详细介绍一下Pitaya 架构的两个最核心的部分:Pitaya平台和Pitaya SDK。
- Pitaya 平台为端上AI提供了工程管理、数据接入、模型开发、算法开发和算法包部署管理等一系列的框架能力。在端上算法策略开发过程中,Pitaya 平台支持在AB平台对端智能算法策略进行实验,验证算法策略的效果。除此之外,Pitaya 平台还支持对端上AI的效果进行实时的监控和告警配置,并在看板上进行多维度的分析与展示。
- Pitaya SDK为端智能算法包提供了在端上的运行环境,支持端上AI在不同设备上高效地运转起来。Pitaya SDK同时还支持在端上进行数据处理和特征工程,提供了为算法包和AI模型提供版本和任务管理、为端上AI运行的稳定和效果进行实时监控的能力。
-
Pitaya 平台
3.1 Pitaya Workbench
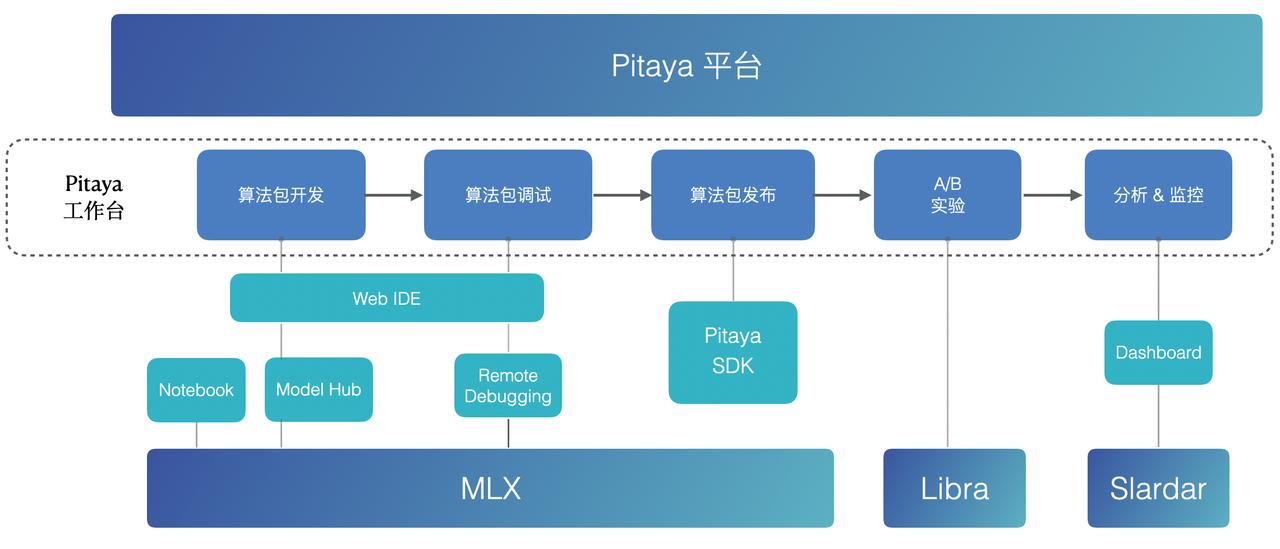
MLX: 字节通用机器学习平台
Libra: 字节大规模在线AB实验评估平台
*Slardar: 字节性能和体验保障的端监控APM平台
Pitaya 平台为算法包的开发、管理、调试、发布、部署、实验、监控提供了一套完善易用的Pitaya Workbench。
- 为了提高算法开发效率,Pitaya Workbench为算法工程师提供了一套可以方便配置数据、模型、算法的开发环境。
- 为了简化调试,Pitaya Workbench在 WebIDE 上实现了真机联调,支持断点、SQL 执行等能力。
- 为了验证AI策略效果,Pitaya平台打通了字节的 A/B 实验平台 ****Libra ,从而实现更灵活的实验环境设定。
- 为了保证端上AI的效果和稳定性,Pitaya平台提供监控告警能力来监控算法包的性能、成功率等运行指标,以及端上模型的准确率、AUC等模型效果指标,并在Dashboard中进行可视化展示。
3.2 机器学习平台
为了应对大数据 处理、深度学习 模型训练需求,Pitaya平台连通字节MLX平台,为通用机器学习场景提供一套自研的云端协作式 Notebook 解决方案。
MLX Notebook内置Spark 3.0以及Flink等大数据 计算引擎,和local、yarn、K8S等多种资源 队列,可以将多种数据源(HDFS / Hive / Kafka / MySQL)和多种机器学习引擎(TensorFlow, PyTorch, XGBoost, LightGBM, SparkML, Scikit-Learn)连接起来。同时MLX Notebook还在标准SQL的基础上拓展了MLSQL 算子,可以在底层将SQL查询编译成可以分布式执行的工作流,完成从数据抽取,加工处理,模型训练,评估,预测,模型解释的Pipeline 构建。
-
Pitaya ****SDK
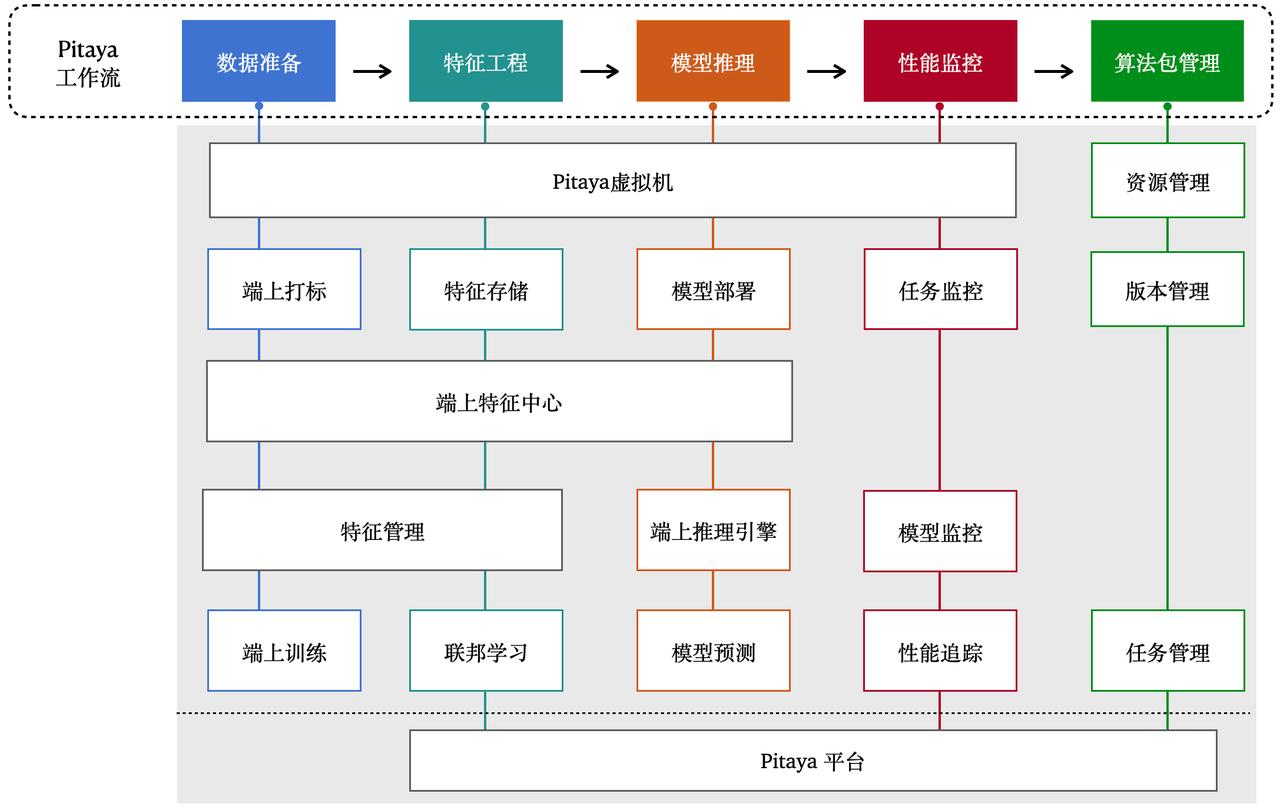
4.1 端上AI环境
4.1.1 端上虚拟机
Pitaya SDK 的核心是自研实现的端上虚拟机 - PitayaVM,为算法包和端上模型在手机端上运行提供了必要的环境。为了能够让虚拟机在端上运行,解决端上虚拟机存在的性能差、体积大的问题,Pitaya在保留了大部分的核心功能的同时,对虚拟机做了许多优化:
- 轻量:包体积影响用户更新升级率。通过对内核、标准库进行功能裁剪,优化代码实现,并开发自研工具对包体积进行详细解析,PitayaVM的包体积在保证核心功能的同时,包体积缩减到了原来的10% 以下,控制在了1MB以内。
- 高效:PitayaVM在保持轻量的同时,性能上也进行了对应的优化。在容器操作、数值统计场景处理的性能甚至超越了Android和iOS上的原生性能。同时虚拟机也支持并行执行算法代码,大幅度提升执行效率。除此之外,PitayaVM还支持通过JIT的方式优化在Android上的执行性能,开启JIT后可以提升将近30 % 的表现。
- 安全:PitayaVM使用自研的字节码和文件格式,确保文件和虚拟机的安全性。
对于严格要求体积的产品线(比如ToB业务),还可以选用Pitaya SDK的MinVM方案,通过自研轻量级解释器 , 在PitayaVM的基础上进行极致轻量优化,将包体积压缩到100KB以内。
4.2 端智能核心流程
4.2.1 数据准备
Pitaya SDK提供了对数据准备流程的一系列支持。提供从设备、应用、业务、端上特征中心,云端设备画像平台、搜推广模块获取特征数据的能力。同时Pitaya SDK也支持在端上进行动态labeling来对数据进行标注,提升训练数据质量,进而提高端上模型效果。
4.2.2 端上特征工程
端上特征工程分成三个主要部分:「特征管理」、「端上特征存储」、「端上特征中心」。
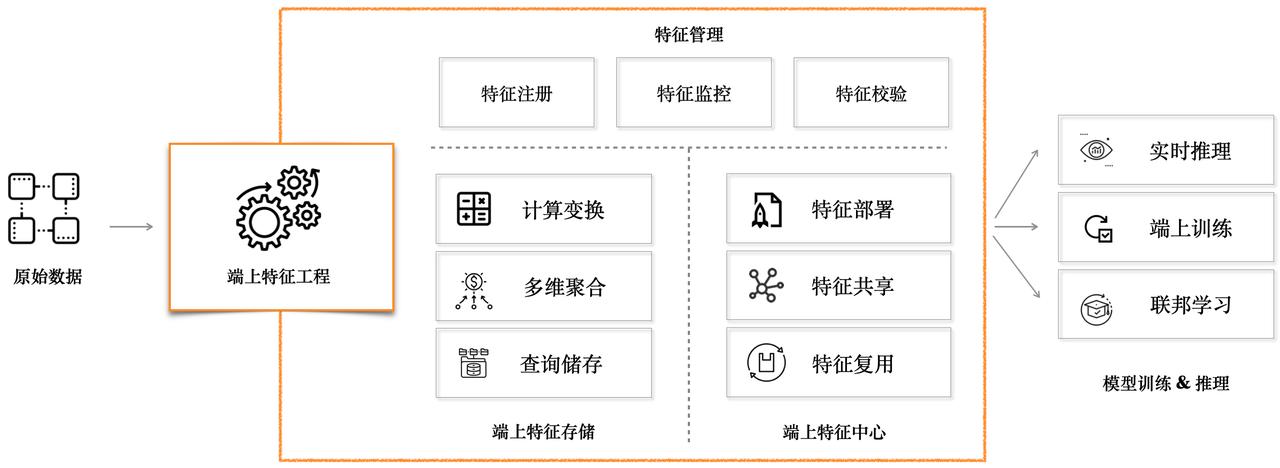
特征存储
Pitaya SDK提供了KV和SQL lite等多种方式的特征存储,在端上实现了类似于Redis和Hive的数据存储模块。同时Pitaya SDK也提供针对端上进行裁剪优化的numpy、MobileCV、MLOps等基础库,以兼容更多格式的数据、提供更复杂的端上数据处理能力。
Pitaya SDK提供的高时效、多维度、长序列特征和合规允许下的隐私数据,除了可以支持相当比例的端内决策,还可以进一步加工特征、样本,为云端模型推理、训练提供支持,进而支持CV、NLP、信息流等不同的端上智能场景。
端上特征中心
Pitaya SDK提供一个端上特征中心模块,通过对端上的丰富多样的特征数据进行多维度的整合和管理,来让不同的端上业务场景方便高效地消费、共享、定制、复用各自的特征数据。端上特征中心可以通过中心化部署的形式,自动化地通过时间、应用生命周期、甚至自定义的session来对特征数据进行整合和生产,然后提供给不同的模块进行使用,显著提高特征开发效率。同时由于数据的生产、消费都在本地,整个过程可以实现毫秒级的数据时效。
特征管理
端上数据来源丰富,特征生产灵活,可以经过端上特征工程处理后得到较复杂高阶的端上特征,还可以进行二次特征交叉后再提供给业务场景进行消费。针对端上特征的这种特性,Pitaya SDK在端上维护了一套特征管理机制,做到特征上下游生产可靠、可维护、可溯源。同时提供以下能力:
- 端上特征监控:特征管理模块对端上特征建立了一系列校准和监控,实时监控端上特征缺失、特征值异常、特征值偏移等情况,确保端上特征的正常生产。
- 端上特征地图:为了实现跨团队的特征共享与协作,特征管理模块提供端上特征地图的能力,让不同业务团队都可以通过特征地图对设备上的特征进行发现、检索、贡献和管理。端上特征地图提供一套添加和使用特征的标准规范, 并可以通过建立特征组,为特征添加metadata信息来最大化降低对特征含义的理解成本,提高特征建设和复用的效率。
4.2.3 端上模型推理
Pitaya SDK对AI模型在端上的部署和实际应用进行了深度优化,连通字节自研的高性能异构推理引擎框架,Client AI团队开发的机器学习决策树 推理引擎 ByteDT,以及TVM 引擎,让AI模型可以在端上进行快速部署和高性能推理。目前Pitaya SDK支持的端上推理引擎可以覆盖大部分端上AI场景,并提供完善的工具链支持,包括:
- 高兼容:支持将业务主流框架训练的模型(Caffe、Pytorch(ONNX)、TensorFlow(tflite)、XGBoost、CatBoost、LightGBM、...)转换成端上支持的模型格式并进行压缩量化。覆盖CV、Audio、NLP等多个业务领域的常用OP,在端上兼容全部安卓机型和iOS机型。
- 高通用:支持CPU/ GPU / NPU / DSP / CUDA等处理器、可以结合处理器硬件情况、当前系统资源占用情况进行择优选择与 调度。
- 高性能:支持多核并行加速和低比特计算(int8,int16,fp16),降低功耗的同时提升性能,整体性能在业界持续保持领先。
4.3 端智能核心配套能力
4.3.1 端监控
端监控模块提供对端上AI耗时、成功率、大盘稳定性和模型效果的主动监控。
客户端在推理任务运行过程中,会自动监控算法包运行关键链路上的性能并进行埋点,然后针对不同类型的埋点,上报到不同的平台进行相应的展示。
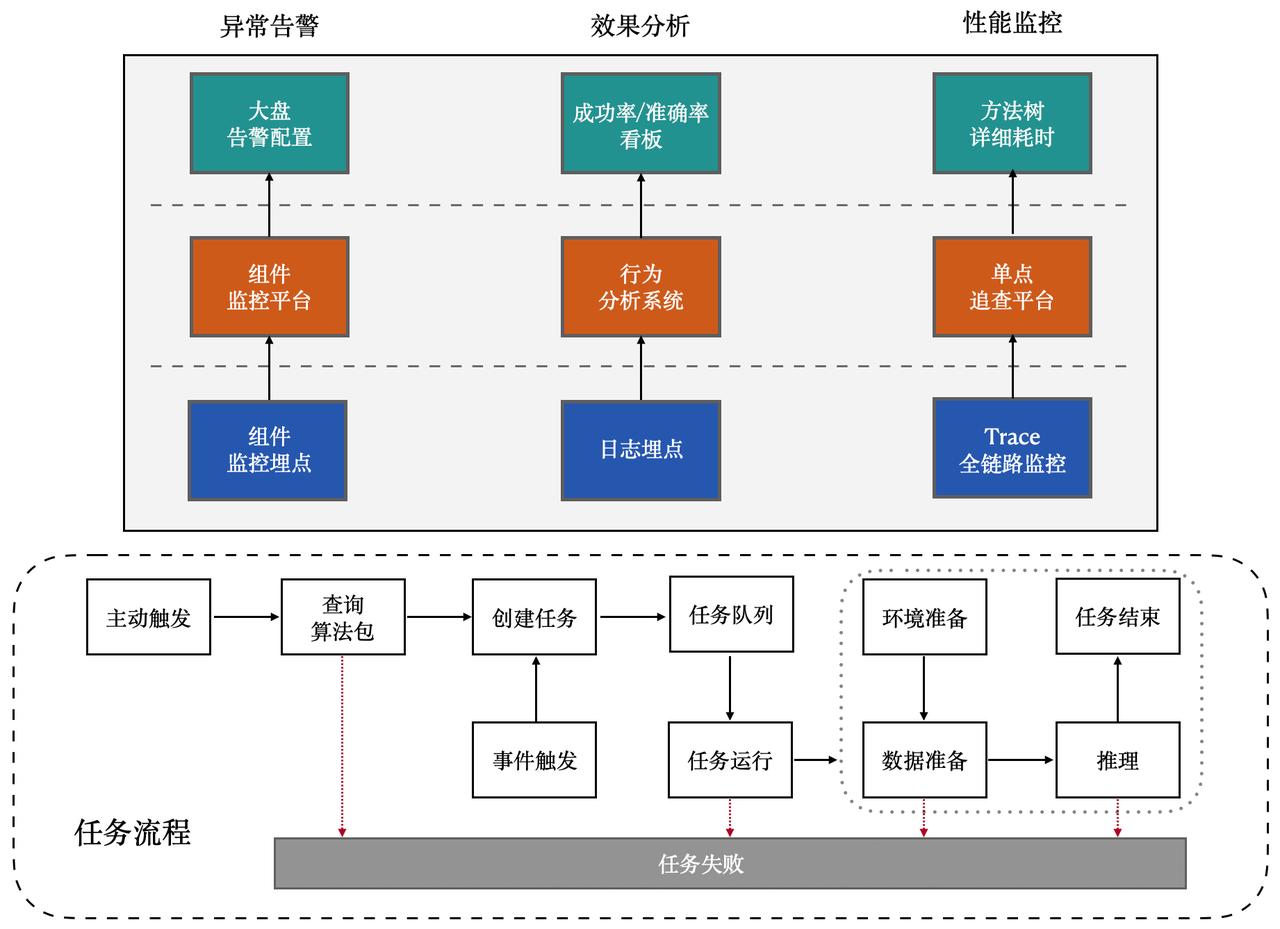
对应不同的平台,端监控支持:
- 在组件监控平台上,通过自定义配置的形式为大盘的稳定性,比如整体算法包运行耗时、人均触发次数等指标定制化告警配置以及告警频率。
- 在行为分析系统上,埋点算法包运行结果和行为,通过 报表/看板 展示算法包运行成功率、模型推理准确度等信息。
- 在单点追查平台上,针对推理耗时太长的问题,查看方法树的详细耗时。
4.3.2 算法包管理
资源管理
资源管理具备对算法包的更新、下线、版本兼容等能力,让算法包能够自动丝滑地部署在端上;同时还维护了一整套的客户端AI运行环境。经过长时间的磨练,我们提供了这些功能:
- 定制下发:支持按需下发和手动下发等不同的下发方式,兼顾可用性 和用户体验。
- 灵活触发:支持多种算法包触发方式,可以通过定时、事件、以及自定义的方式在业务期望的时机点去执行端上AI模型或策略。
- 环境隔离:针对不同算法包的不同环境依赖,以及相同依赖不同版本之间的兼容性,提供了模块隔离的环境;同时提供模块缓存和释放能力,避免模块频繁切换,兼顾了运行速度和内存占用。
任务管理
由于数据和模型都在端上进行计算和推理,不需要依赖网络,也没有网络延迟。因此端上AI相比云端AI的耗时低非常多,使得端上AI可以做到频率更高,响应更快。任务管理专门对应端上AI的特性进行设计,支持了多种能力:
- 高并发:支持多任务并发、多 线程 调度的任务管理模式来给AI任务保证一个高效的运行环境。
- 熔断 保护:为了保证业务核心场景的稳定性,Task Management模块支持熔断保护,对于连续N次运行失败,或者连续N次导致崩溃的算法包,我们会进行熔断,暂时阻止其运行。
- 优先 调度:当业务场景较多时,高频触发推理任务可能导致任务堆积。为了保证高优任务的优先级,我们支持通过优先级对任务进行调度;此外,实时性较高的场景下,我们还支持合并处于待执行状态的中间任务,保证任务响应的实时性。
- 防卡死:算法代码动态性较高,可能会引入死循环,端上若运行包含死循环代码的推理任务,会导致资源持续占用。为此我们开发了卡死检测功能,检测到死循环后,会在解释器层面退出死循环,并清理环境和恢复解释器,以保证正常任务 调度。
4.3.3 联邦学习
为了保障用户的数据隐私,Pitaya SDK提供Pitaya 联邦学习 模块,支持在不上传任何隐私数据的情况下训练AI模型。在这个过程中,AI模型训练只依赖于经过隐私保护和加密技术处理后的端上模型更新结果,用户相关的数据不会被传送到云端保存,也无法反推出原始数据信息,实现了模型训练和云端数据存储的解耦。除此之外,Pitaya SDK还支持直接在端上进行模型训练、部署和迭代,来实现千人千模或者千人百模的用户个性化模型。
为了保证用户体验,Pitaya FL在端上实现了一套自动 调度方案,只有在设备同时满足空闲、充电以及有wifi连接状态下才会进行联邦学习 训练,整个过程不会对设备造成任何影响。
未来Pitaya建设
字节Client AI团队的端智能架构 Pitaya目前已经为端智能提供了一套完善成熟的开发平台,为端智能开发workflow中的各项环节都提供了完整易用的功能模块,并在SDK里提供了业界领先的端上虚拟机、特征、监控、推理引擎支持。
在未来的几个月,字节 Pitaya会致力于进一步建设端到端的 AI 工程链路,覆盖开发、迭代、监控流程,提升业务 AI 算法研发能效。同时我们计划在目前已经趋近成熟的端智能架构上,沉淀更多可复用的 AI 应用能力,实现 AI 能力在应用间、To B 的高效迁移,将端上AI进行规模化应用。
Client AI团队一直在招募杰出人才,包括端智能算法工程师、端智能应用工程师(iOS/Android)、端智能数据研发工程师等岗位,来让我们在这个领域上创造自己的影响力。如果你对端智能有热情,动力,经验,欢迎加入我们团队,一起探索端智能的可能性~