




Kafka MirrorMaker 是 Kafka 官网提供的跨数据中心流数据同步方案,其实现原理是通过从 Source 集群消费消息,然后将消息生产到 Target 集群从而完成数据迁移操作。用户只需要通过简单的consumer配置和producer配置,启动MirrorMaker,即可实现实时数据同步。
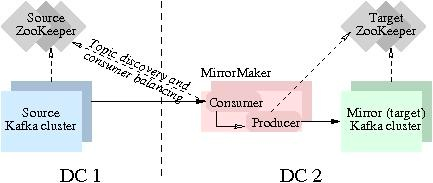 本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产环境会更加复杂,如果您有迁移类的需求,欢迎咨询技术支持服务。
本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的Source Kafka版本为2.12,基于本地机器搭建。现实生产环境会更加复杂,如果您有迁移类的需求,欢迎咨询技术支持服务。
- 预计部署时间:40分钟
- 级别:高级
- 相关产品:消息队列Kafka
- 受众: 通用
环境说明 #
- 已购买开通私有网络服务
- 已购买开通火山引擎Kafka产品
- 消息队列Kafka已绑定公网IP(可参考:https://www.volcengine.com/docs/6439/107774)
- 本地Source Kafa状态正常
步骤1:本地Kafka创建测试Topic #
以下我们将以名称为“testTopic”的Topic为例演示。 创建Topic命令:
kafka-topics.sh \
--create \
--zookeeper localhost:2181 \ #根据实际情况填写
--replication-factor 1 \
--partitions 1 \
--topic testTopic
创建成功后可以通过以下命令对topic进行检查
bin/kafka-topics.sh \
--list \
--zookeeper localhost:2181 #根据实际情况填写
执行结果如下:

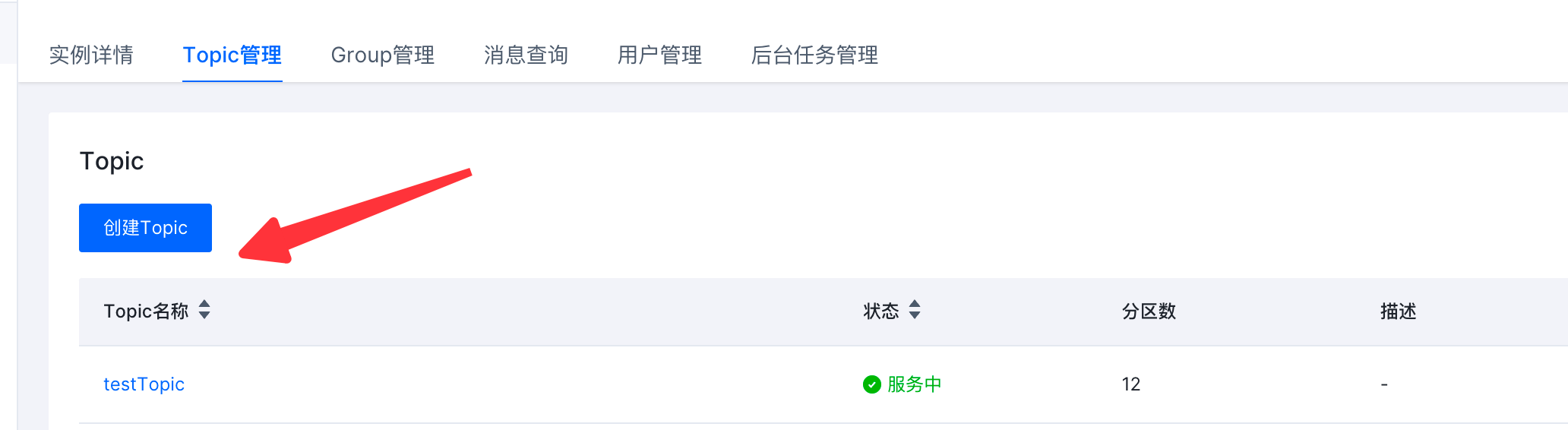
步骤2:同步创建火山Kafka Topic #
在火山创建好Kafka实例后,在“Topic管理”页签下,创建与Source集群需要迁移topic的同名topic。注意分区数最好与原集群分区保持一致。
步骤3:下载SASL_SSL证书 #
在下载SASL_SSL证书前,先确认用于访问的用户是否已经存在:
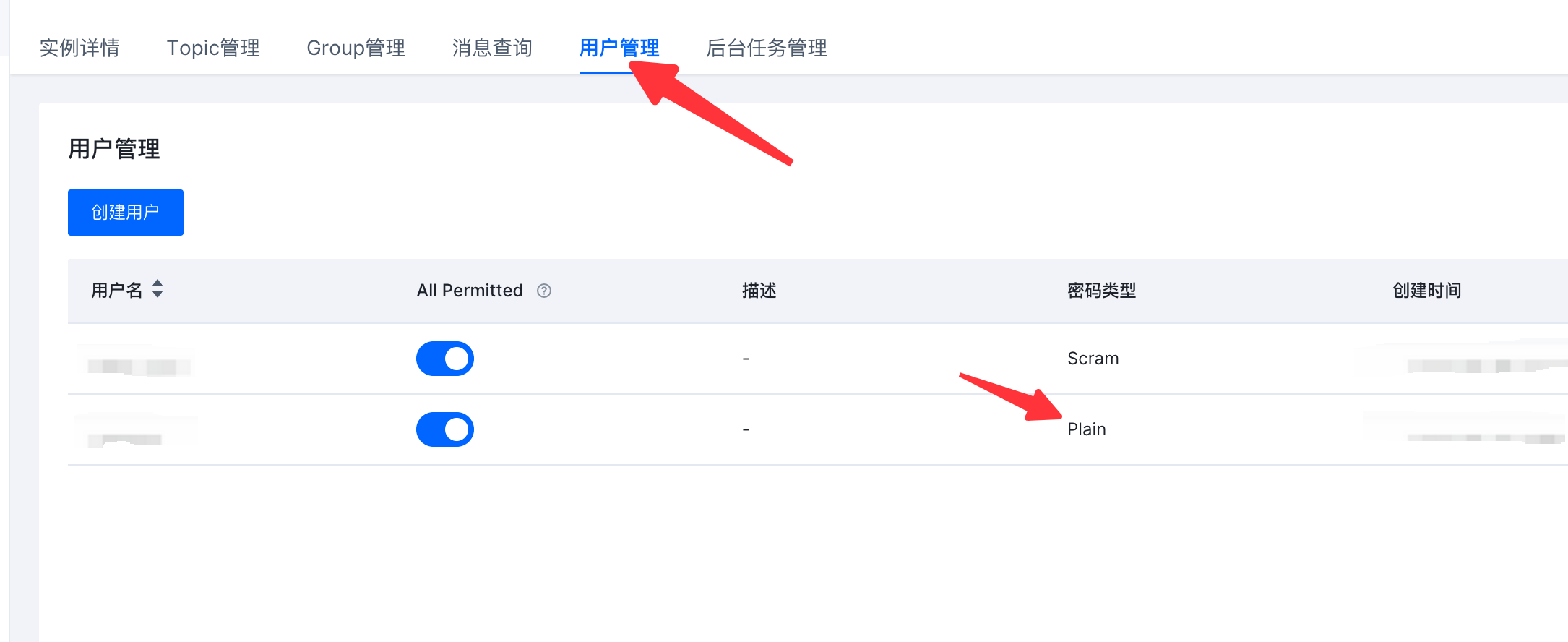 如果未建立,请先创建用户。
确认完成后,在“实例管理”页签下下载SASL_SSL证书
如果未建立,请先创建用户。
确认完成后,在“实例管理”页签下下载SASL_SSL证书
 关于使用SASL_SSL可参考:https://www.volcengine.com/docs/6439/122807
关于使用SASL_SSL可参考:https://www.volcengine.com/docs/6439/122807
步骤4:修改Mirror Maker 生产者/消费者配置 #
consumer生产者的配置(consumer.properties)一般在kafka目录下的config目录下。修改如下:
bootstrap.servers=localhost:9092 # 需要根据实际情况修改
group.id=test-consumer-group # 需要根据实际情况修改
同样,producer消费者的配置(producer.properties)也在此config目录下,该文件有较大修改:
bootstrap.servers= SASL接入点(公网) # 需要根据实际情况修改
接入点的获取途径如下:
 外网访问,需要添加SASL认证信息:
外网访问,需要添加SASL认证信息:
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="替换用户名" password="替换密码";
sasl.mechanism=PLAIN
security.protocol=SASL_SSL
ssl.truststore.location=/xxx/Kafka.client.truststore.jks #根据实际情况替换证书路径
ssl.truststore.password=KafkaTrustStorePass
ssl.endpoint.identification.algorithm=
步骤5:启动MirrorMaker #
文件配置修改完成后,通过下方命令启动MirrorMaker,实现本地Kafka与火山Kafka联通
kafka-mirror-maker.sh \
--consumer.config ../config/consumer.properties \ #根据实际情况指定consumer.properteis
--producer.config ../config/producer.properties \ #根据实际情况指定producer.properties
--whitelist "testTopic"
步骤6:启动Producer生产数据 #
接下来,我们启动生产者对测试的topic(testTopic)进行消息生产
kafka-console-producer.sh \
--broker-list localhost:9092 \ #根据实际情况填写
--topic testTopic

步骤7:数据同步结果检查 #
在火山引擎Kafka实例“消息查询”页签,我们可以查询testTopic最近的数据,如下图可以看到是有数据写入的。此时数量上和我们写入的数量一致。
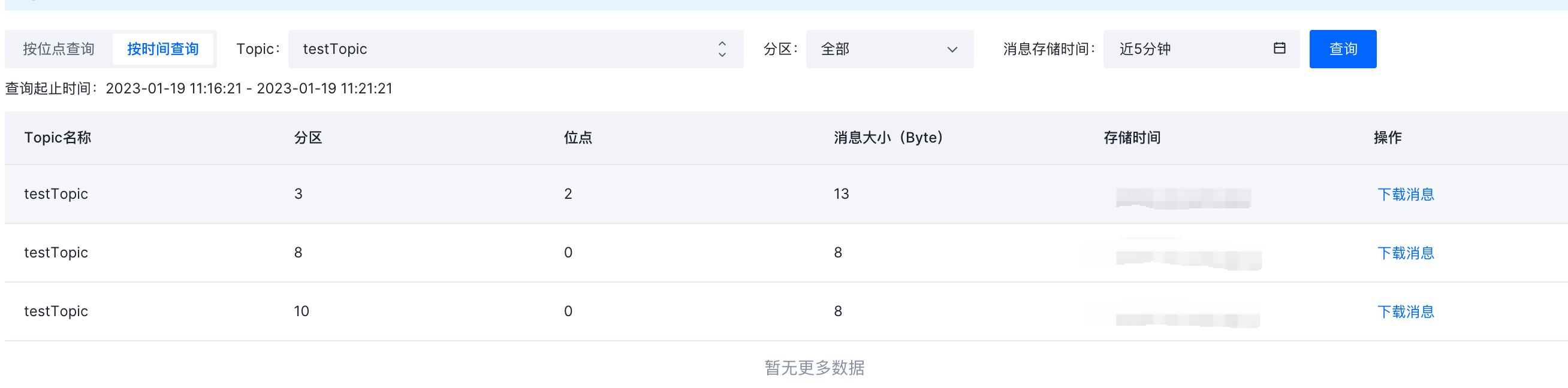 由于火山对下载的消息进行了 Base64 编码传输(或可通过升级实例解决编码造成的),因此很难确认消息是否正确性、完整性。
可以通过客户端消费如下(客户端下载与使用可参考:https://www.volcengine.com/docs/6439/122807):
由于火山对下载的消息进行了 Base64 编码传输(或可通过升级实例解决编码造成的),因此很难确认消息是否正确性、完整性。
可以通过客户端消费如下(客户端下载与使用可参考:https://www.volcengine.com/docs/6439/122807):
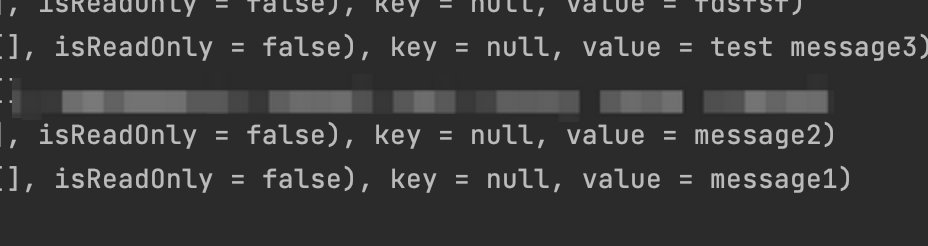 经过检查,消息与发送端数据保持一致。
经过检查,消息与发送端数据保持一致。
(1)MirrorMakker启动报错:java.lang.OutOfMemoryError: Java heap space 解决方法:修改 /bin/kafka-run-class.sh,找到 Memory options处,默认设置是256M,将其修改为如下值:
if [ -z "$KAFKA_HEAP_OPTS" ]; then
KAFKA_HEAP_OPTS="-Xmx1024M -Xms512M"
fi
保存退出。
(2)kafka生产者启动后报错:Error while fetching metadata with correlation 解决方法:修改 config\server.properties,修改内容如下:
listeners=PLAINTEXT://localhost:9092
advertised.listeners=PLAINTEXT://localhost:9092
重启kafka即可。
--consumer.config # 消费者配置,详情参考kafka consumer配置 --producer.config # 生产者配置,详情参考kafka producer配置 --whitelist #需要mirror的topic,支持Java正则表达式,例如'AAA,BBB’ --blacklist #不需要拷贝的topic,支持Java正则表达式 --num.producers #producer数量,默认为1 --num.streams #consumer数量,默认为1 --queue.size #consumer和producer之间缓存的queue size,默认10000 详情见:https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=27846330
1)whitelist和blacklist支持正则表达式。比如需要包含两个topic可以这样写,--whitelist 'A|B' or --whitelist 'A,B' ,或者想迁移所有topic可以这样写 --whitelist '*' 2)注意在迁移之前创建好相关topic以及规划好partition数量。 3)老版本和新版本迁移主要考虑consumer和producer的兼容性。 4)开始之前配置好限流,防止影响原来集群的正常工作。
