




当前 DataLeap 中已内置大量函数可供大部分场景使用,详细说明可点开公共函数说明进行查询。
但当自带的函数无法满足生产需要时,用户可考虑通过用户自定义函数的形式,完成所需的函数编写。 用户自定义函数为三类:
UDF(User Defined Scalar Function),用户自定义函数,只对单行数值产生作用;
UDAF(User-Defined Aggregation Function),用户定义聚合函数,可对多行数据产生作用,等同于SQL常用的SUM、AVG等聚合函数;
UDTF(User-Defined Table-Generating Function),用户定义表生成函数,用来解决输入一行输出多行的场景
本实验以DataLeap on Las为例,完成用户自定义函数(UDF)的编写与测试。
- 预计部署时间:40分钟
- 级别:中级
- 相关产品:大数据开发套件、湖仓一体分析服务LAS
- 受众: 通用
环境说明
- 已购买开通私有网络服务
- 已购买开通DataLeap产品
- 已购买开通湖仓一体LAS服务
- 子账户具备DataLeap相关权限(参考:https://www.volcengine.com/docs/6260/65408)
步骤1:编写自定义UDF并打包
本实验以基于Maven的Java工程为例。
Pom文件引入依赖如下:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
实现字符串截取UDF样例:
package demo;
import org.apache.flink.table.functions.ScalarFunction;
public class SUBSTR_UDF extends ScalarFunction {
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, end);
}
}
完成后,通mvn clean package命令完成程序打包。
步骤2:上传资源
打开DataLeap资源管理页面,将步骤一中准备好的程序进行上传。
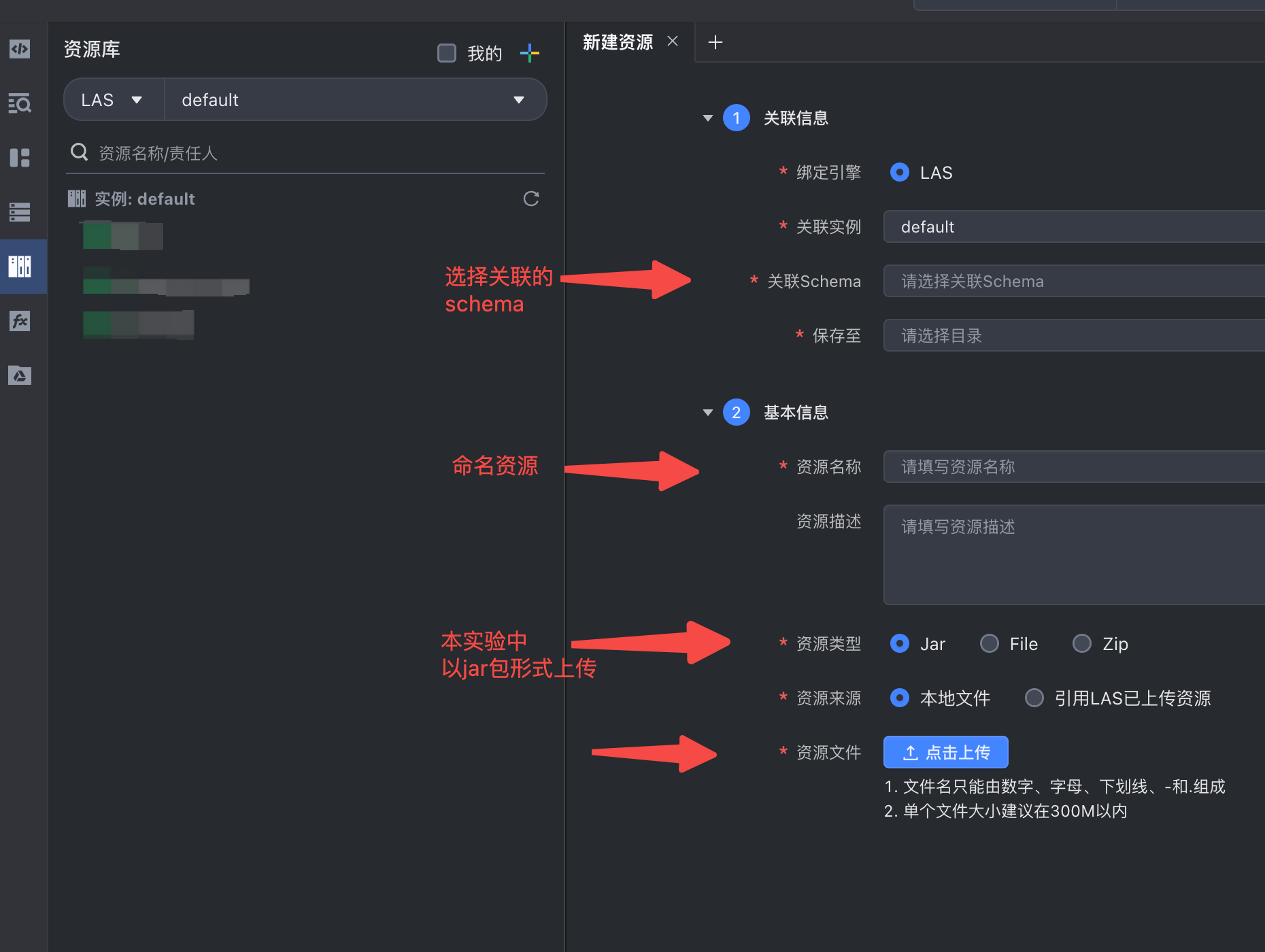
步骤3:定义函数
打包程序上传好之后,我们将基于该资源定义我们需要的函数。具体操作可参考下图:
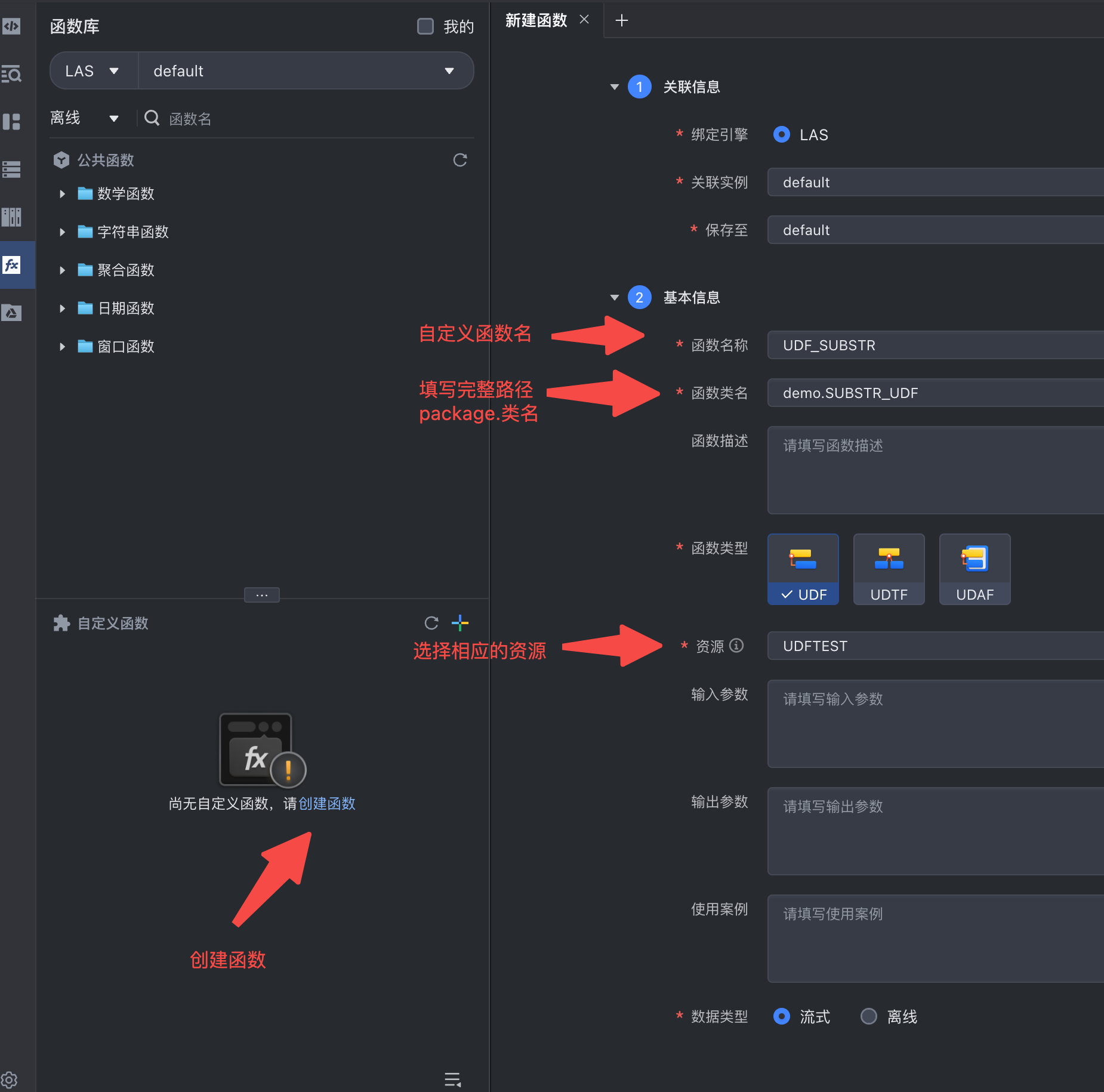 值得注意的是,用户类名指的是我们程序中函数实现部分的路径。比如本案例中在demo包下的SUBSTR_UDF类中实现了函数逻辑,此处将填写为:demo.SUBSTR_UDF。
值得注意的是,用户类名指的是我们程序中函数实现部分的路径。比如本案例中在demo包下的SUBSTR_UDF类中实现了函数逻辑,此处将填写为:demo.SUBSTR_UDF。
步骤4:引入函数并创建Flink-SQL任务
CREATE TEMPORARY function '对应的Schema'.UDF_SUBSTR AS '对应的包.类名';
CREATE TEMPORARY TABLE student_sink (
id INT,
name STRING,
subject STRING,
score INT
)
WITH ('connector' = 'blackhole');
INSERT INTO student_sink
SELECT 555,
demo_tpc_ds_2022_11_07_59.UDF_SUBSTR('abcdefgh', 0, 1),
demo_tpc_ds_2022_11_07_59.UDF_SUBSTR('abcdefgh', 2, 4),
68
步骤5:作业调试并提交
填写运行参数(主要为Las队列的选择,本案例中关于JobManager、TaskManager等参数选默认值1)
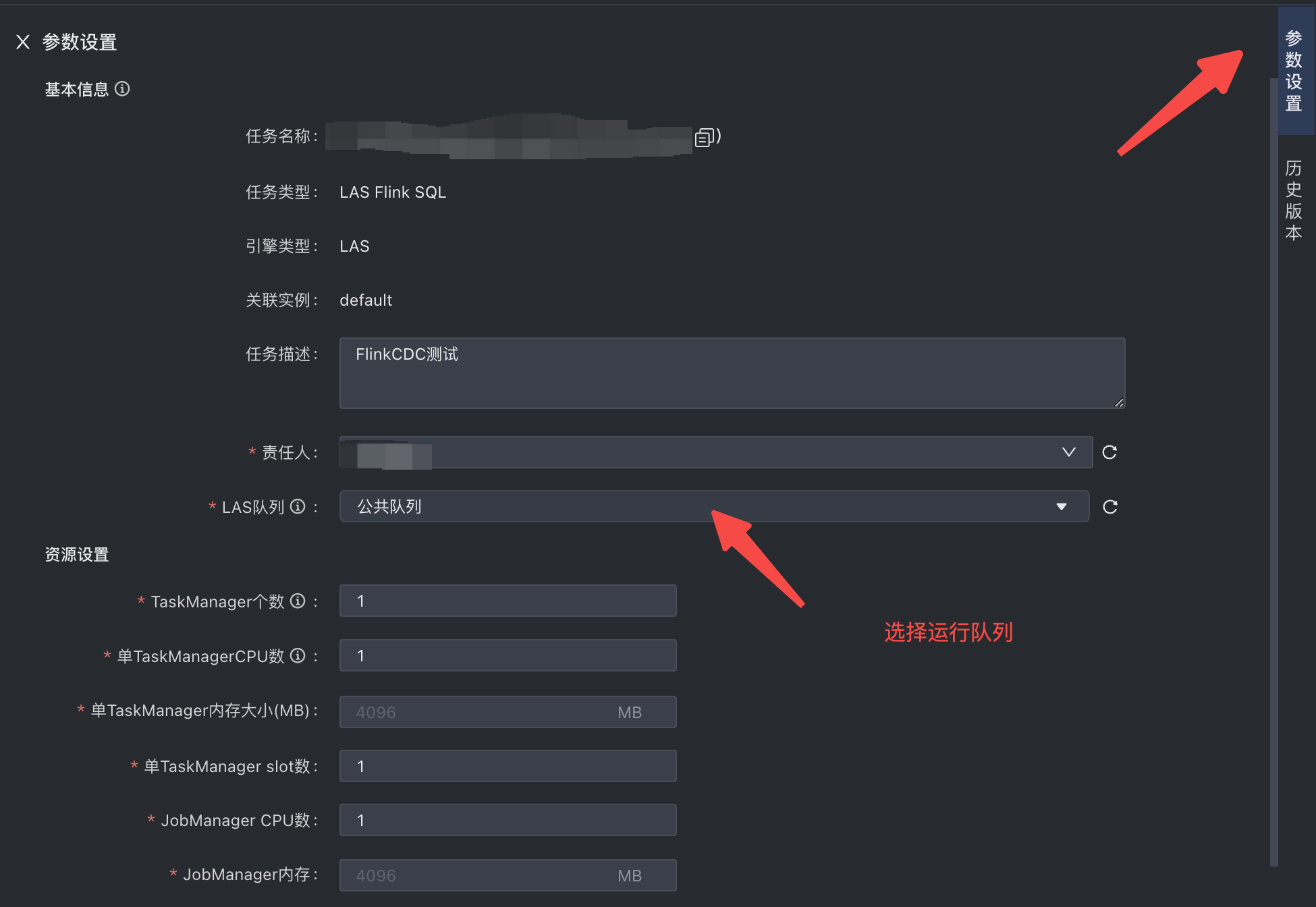
调试并提交。调试结果如下:
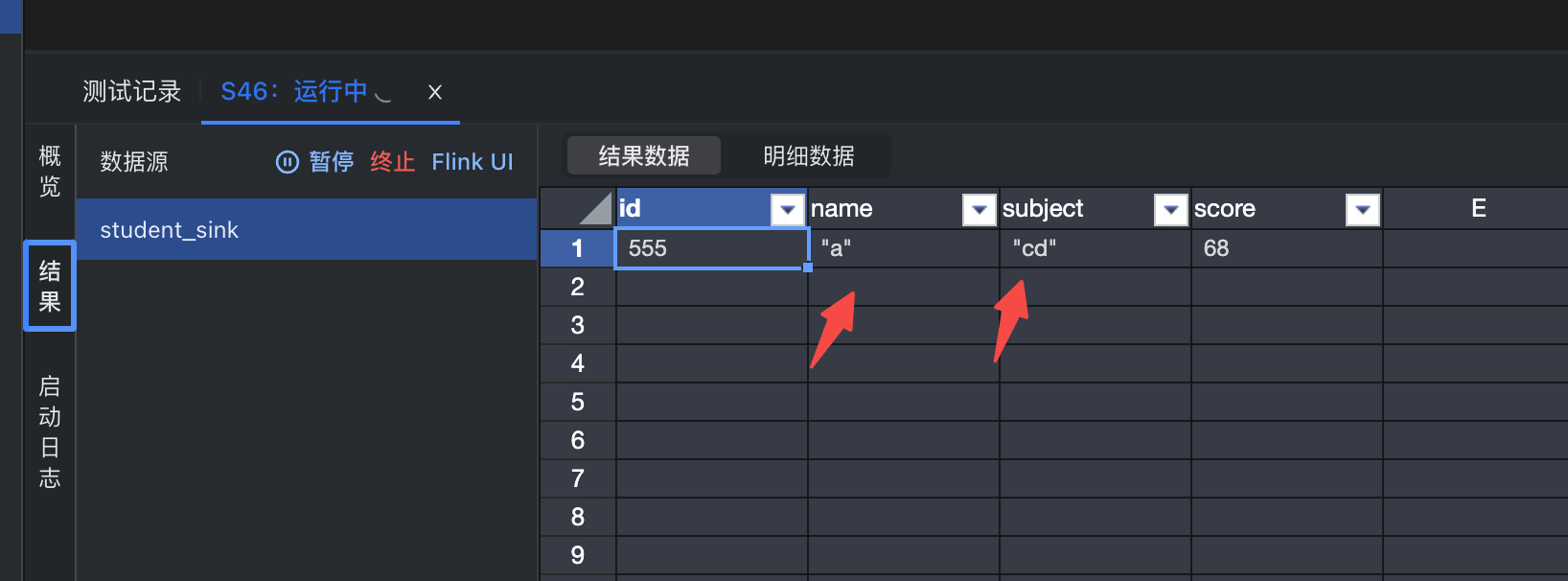
关于LAS的作业编写与调试,可参考:https://www.volcengine.com/docs/6260/80007 对于UDF常见问题,可参考:https://www.volcengine.com/docs/6492/101898
如果您有其他问题,欢迎您联系火山引擎技术支持服务
