




问题描述
LAS 产品中提供了 pyspark 的方式提交作业。如果用户本地有 python 工程,工程中引入了需要 pip install 或自己开发的模块,这种情况直接使用 LAS 的命令窗口提交是无法满足要求的。本文将主要阐述如何处理这种场景。
问题分析
此类问题需要通过打包代码与打包 python 虚拟环境的方式解决。
解决方案
我们通过案例说明该问题解决方式。 (1)打包一个名称为 pythonCode.zip 的工程,里面只包含代码 test.py 代码,test.py 代码内容如下:
import pandas as pd
df = pd.DataFrame({'address': ['四川省 成都市','湖北省 武汉市','浙江省 杭州市']})
res = df['address'].str.split(' ', expand=True)
res.columns = ['province', 'city']print(res)
(2)打包 python 自定义虚拟环境,命名为 python379.zip,打包命令如下:
#构造python版本为本地python3对应的python版本
virtualenv --python=$(which python3) --clear python379
#进入到该环境下
source python333/bin/activate
#安装koalas
echo 'koalas' > requirements.txt
pip install -r requirements.txt
#打包独立环境,产出zip包
python379.zipcd python333 && zip -r python333.zip *
#退出
deactivate
(3)通过 DataLeap 资源管理上传代码包和虚拟环境包
(4)通过如下方式调用步骤1中的代码
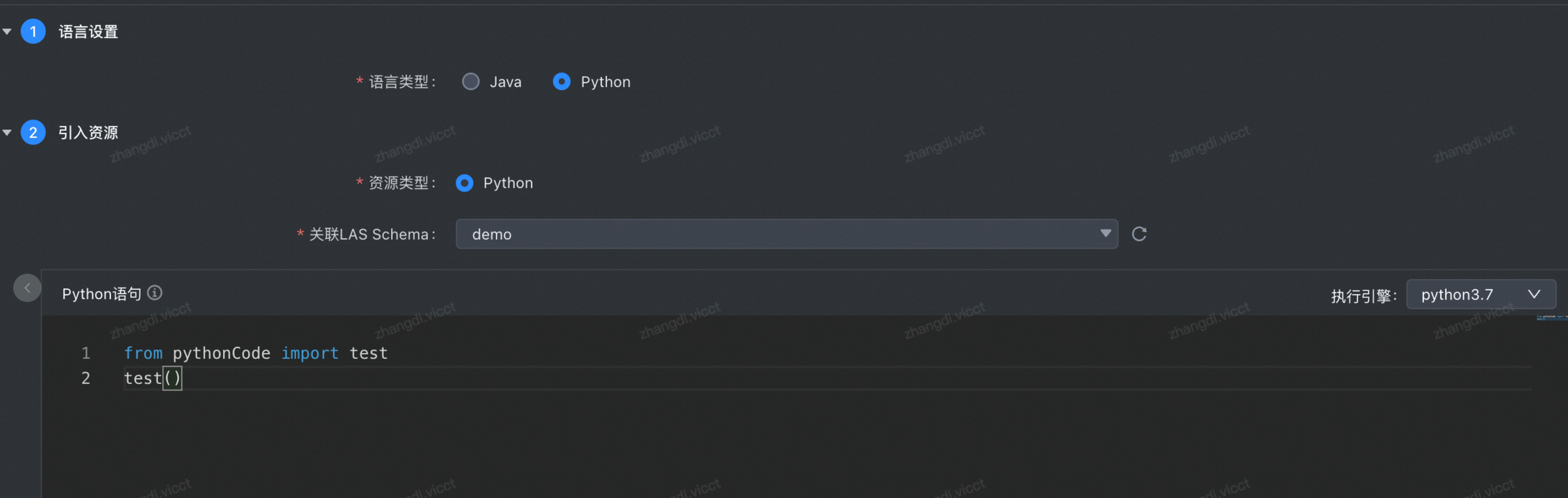
【说明】 代码格式为:
from 代码包名称 import 代码文件名称
作业参数:
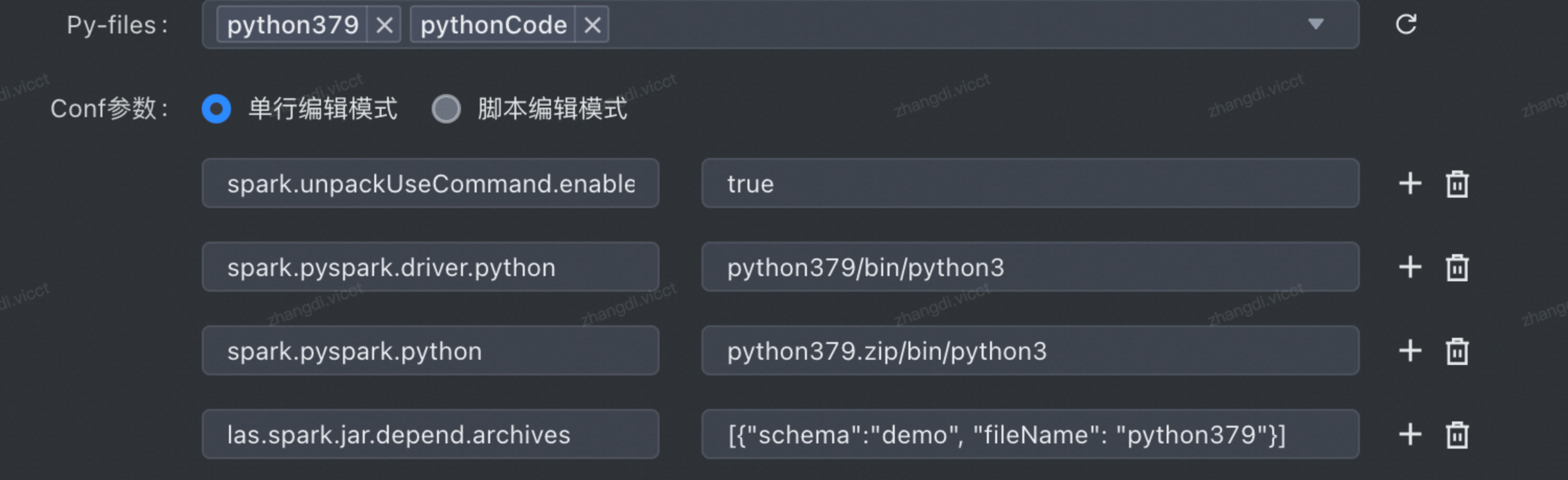
填写参数格式如下:
| 参数名 | 值 |
|---|---|
| spark.unpackUseCommand.enabled | true |
| spark.pyspark.driver.python | python379/bin/python3 (前缀为资源名) |
| spark.pyspark.python | python379.zip/bin/python3 (前缀为资源名+.zip) |
| las.spark.jar.depend.archives | [{"schema":"您当前的schema","fileName":"python379(python虚拟环境打包的名称)"}] |
运行结果为:

如果您有其他问题,欢迎您联系火山引擎技术支持服务
