




前言
在搜索场景中,我们建议单个分片的大小为 20 GB,在日志记录场景中,建议值为 50 GB。过多的分片会带来集群管理负担,如果索引保存的数据量较小,我们建议您缩小主分片数,重新设定合理的主分片数。 与 _split API 相反,Elasticsearch 提供了 _shrink API 来缩小主分片数。关于 _split API,您可以参考[1]。
使用限制
- 索引必须为只读状态
- 所有的分片必须在同一个节点上
- 索引的健康状态必须为 green
操作步骤
步骤一:查看索引的分片信息
我们可以使用如下命令来查看一个具体的索引的分片信息:
GET _cat/shards/kibana_sample_data_ecommerce_1?v
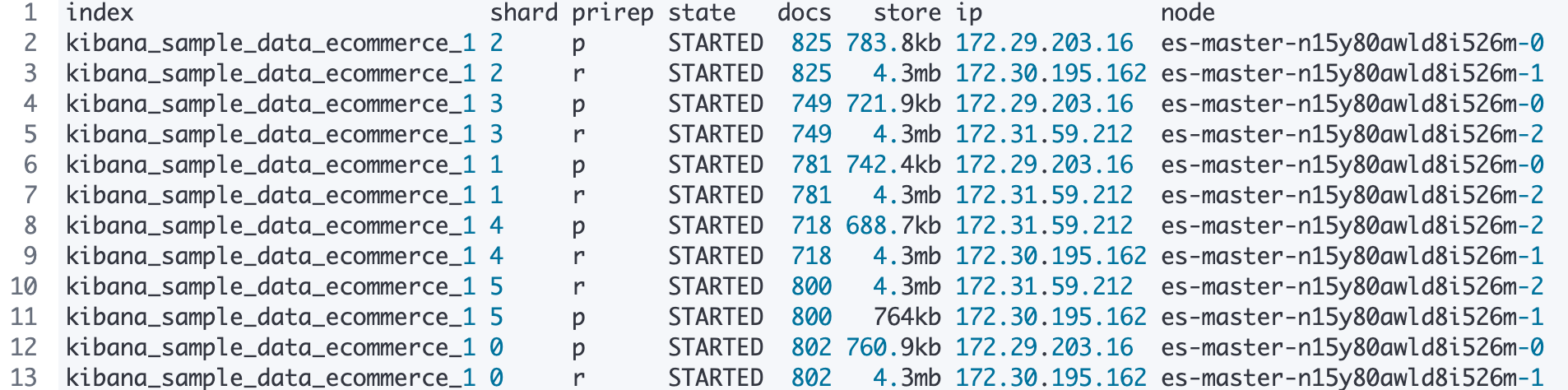
在我的环境中,运行上述命令输出截图如下:可以看到 kibana_sample_data_ecommerce_1 索引有 6 个主分片,每个主分片有一个副本分片。分片分布于三个 Elasticsearch node 上。
步骤二:满足先决条件
前面我们提到了使用 shrink API 的相关限制,在步骤二中,我们需要保证索引只读,同时将索引分片集中于同一个节点上,可以使用如下命令:
PUT kibana_sample_data_ecommerce_1/_settings
{
"settings": {
"index.number_of_replicas": 0,
"index.routing.allocation.require._name": "es-master-n15y80awld8i526m-0",
"index.blocks.write": true
}
}
再次运行完上述命令之后,查看索引的分片信息如下:可以看到kibana_sample_data_ecommerce_1 只有 6 个主分片,且全部集中于 es-master-n15y80awld8i526m-0 这个节点中。

步骤三:使用 _shrink index API 缩小分片数
您可以运行如下命令来缩小主分片数:
POST kibana_sample_data_ecommerce_1/_shrink/kibana_sample_data_ecommerce_shrink
{
"settings": {
"number_of_replicas": 0,
"number_of_shards": 1,
"index.codec": "best_compression",
"index.routing.allocation.require._name": null,
"index.blocks.write": null
},
"aliases": {
"my_test_alias": {}
}
}
输出如下:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "kibana_sample_data_ecommerce_shrink"
}
步骤五:查看进度信息
您可以使用如下语句来查看任务执行进度,输出中会有百分比信息:
GET _cat/recovery/kibana_sample_data_ecommerce_shrink?human&detailed=true
参考文档
[1] https://opensearch.org/docs/2.0/opensearch/rest-api/index-apis/shrink-index/ 如果您有其他问题,欢迎您联系火山引擎技术支持服务
