




写在前面
Hello,大家好,我是小苏👦🏽👦🏽👦🏽
之前的博客中,我都为大家介绍的是计算机视觉的知识,随着ChatGPT的走红,越来越多的目光聚焦到NLP领域,那么今天准备和大家唠唠NLP的内容。其实呢,对于NLP,我也是初学者,之前只是有一个大概的了解,所以本系列会以一个初学者的视角带大家走进NLP的世界,如果博客中有解释不到位的地方,希望各位大佬指正。🍭🍭🍭
当然了,NLP的内容很多,你如果在网上搜NLP学习路线的话你会看的眼花缭乱,本系列主要会介绍一些重要的知识点,一些历史久远的模型就不介绍了,我个人觉得用处不大,我们的目标是像经典模型看齐,如GPT系列,BERT家族等等。🍡🍡🍡
本系列准备先从词向量为切入点,然后介绍RNN模型并手撸一个RNN;接着会介绍RNN的改进LSTM及ELMO模型;最后会详细介绍GPT和BERT,以及它们的相同点和不同点。🍬🍬🍬
让我们一起加油,走进NLP的世界叭。🚖🚖🚖
词向量
我们知道,NLP任务中我们处理的对象是一个个的词,但是计算机根本不认识我们的词啊,需要将其转换为适合计算机处理的数据类型。一种常见的做法是独热编码(one-hot编码),假设我们现在要对“秃”、“头”,“小”,“苏”四个字进行独热编码,其结果如下:
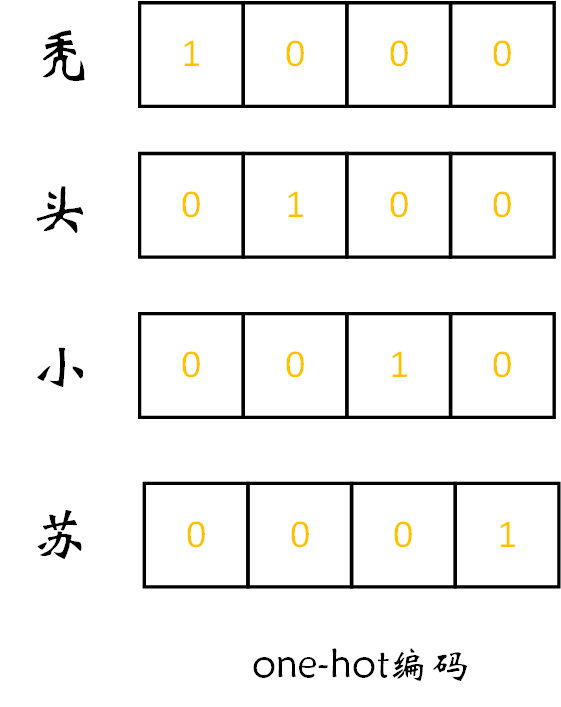
可以看出,上图可以用一串数字表示出“秃”、“头”,“小”,“苏”这四个汉字,如用1 0 0 0表示“秃”,用0 1 0 0表示“头”......
但是这种表示方法是否存在缺陷呢?大家都可以思考思考,我给出两点如下:
- 这种编码方式对于我这个案例来说貌似是还蛮不错的,但是大家有没有想过,对于一个文本翻译任务来说,往往里面有大量大量的汉字,假设有10000个,那么一个单独的字,如“秃”就需要一个1×10000维的矩阵来表示,而且矩阵中有9999个0,这无疑是对空间的一种浪费。
- 这种编码方式无法表示两个相关单词的关系,如“秃”和“头”这两个单词明显是有某种内在的关系的,但是独热编码却无法表示这种关系【余弦相似度为0,后文对余弦相似度有介绍】。
基于以上的两点,我觉得我们的对词的编码应该符合以下几点要求:
- 我们可以将词表示为数字向量。
- 我们尽可能的节省空间的消耗。
- 我们可以轻松计算向量之间的相似程度。
我们先来看这样的一个例子,参考:The Illustrated Word2vec🎅🏽🎅🏽🎅🏽🍚🍚🍚
现在正值秋招大好时机,大家的工作都找的怎么样了腻,祝大家都能找到令自己满意的工作。在投简历的过程中,我们会发现很多公司都会有性格测试这一环节,这个测试会咨询你一系列的问题,然后从多个维度来对你的性格做全面分析。其中,测试测试者的内向或外向往往是测试中的一个维度,假设我(Jay)的内向/外向得分为38(满分100),则我们可以绘制下图:
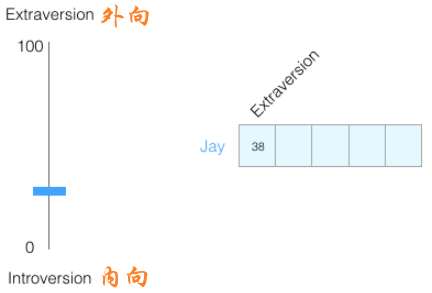
为了更好的表示数据,我们将数据限制到-1~1范围内,如下:
这样我们就可以对Jay这个人是否外向做一个大致的评价,但是人是复杂的,仅仅从一个维度来分析一个人的性格肯定是不准确的,因此,我们再来添加一个维度来综合评价Jay这个人的性格特点:
可以看到,现在我们就可以从两个维度来描述Jay这个人了,在上图的坐标系中就是一个坐标为(-0.4,0.8)的点,或者说是从原点到(-0.4,0.8)的向量。当然了,如何还有别人有这样的两个维度,我就能通过比较他们的向量来表示他们的相似性。
从上图可以和明显的看出,Person1和Jay更像,但是这是我们直观的感受,我们可不可以通过数值来反应他们之间的相似度呢,当然可以,一种常见的计算相似度的方法是余弦相似度cosine_similarity,结果如下:
🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷
不知道大家知不知道计算余弦相似度,这里简单介绍一下:
余弦相似度是一种用于衡量两个向量之间相似性的度量方法,通常在自然语言处理和信息检索等领域广泛使用。它计算两个向量之间的夹角余弦值,值越接近1表示两个向量越相似,值越接近-1表示两个向量越不相似,值接近0表示两个向量之间没有明显的相似性。
余弦相似度的计算公式如下:
🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷🌷 上面展示的是从两个维度刻画一个人的性格,但是在实际中比两维更多,国外心理学家研究了五个主要人格,所以我们可以将上面的二维扩展到五维,如下图所示:
显然,现在我们有五个维度的数据,我们无法通过平面向量的形式来观察不同人物之前的相似性,但是我们仍然可以计算他们之前的相似度,如下:
通过上面的性格测评小例子,我想告诉大家的是我们可以把诸如"外向/内向"、“自卑/自负”等性格特征表述成向量的形式,并且每个人都可以用这些种向量形式表示,同时我们可以根据这种向量的表述来计算每个人之前的相似度。
同样的道理,人可以,那么词也可以,我们把一个个词表示成这样的向量形式,这种向量表示形式就是词向量。那么词向量到底长什么样呢?我们一起来看看“King”这个词的词向量(这是在维基百科上训练好的),如下:
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
这一共有50个数字,即表示我们选择了50个维度的特征来表示“king”这个词,也即这个向量表示“king”这个词。同样的道理,别的单词也会有属于他们自己的向量表示,形式和上面的是一样的,都是50维,但是里面具体的值不同。为了方便展示不同词之间的联系,我们将表示“king”的词向量换一种方式展示,根据其值的不同标记成不同的颜色(若数值接近2,则为红色;接近0,则为白色;接近-2,则为蓝色),如下图:
当然了,我们用同样的道理,会得到其它词的词向量表示,如下:
可以看到,“Man”和“Woman”之前的相似程度似乎比它们和“King”之前的相似程度高,这也是符合我们直觉的,即“Man”和“Woman”之前的联系似乎比较大。
这就说明,经过把词变成词向量之后,我们可以发现不同词之前的相关程度了。这里你可能会问了,怎么把词变成词向量呢?不急,我们马上解答。🧃🧃🧃
我们再拿我们一开始“秃”、“头”,“小”,“苏”四个字为例,我们使用独热编码编码这四个字后,它们之间的余弦相似度都为0,无法表示它们之间的相关程度,因此使用独热编码作为词向量效果不好。那么改使用什么呢,一种可能的方案是Word Embedding。我们先来说说通过Word Embedding可以达到什么样的效果,同样拿“秃”、“头”,“小”,“苏”四个字为例,使用Word Embedding后它们的分布是这样的:

即“秃”和“头”在某个空间中离的比较近,说明这两个词的相关性较大。即Word Embedding可以从较高的维度去考虑一些词,那么会发现一些词之前存在某种关联。
那么如何进行Word Embedding,如何得到我们的词向量呢?首先我需要让大家认识到一点,进行Word Embedding,其实重点就是寻找一个合适的矩阵Q。然后将我们之前的one hot编码乘上Q,,比如“秃”的one hot 编码是1 0 0 0,假设我们寻找到了一个矩阵Q,
那么我们将它们两个相乘,就得到了“秃”的词向量:
词向量“秃”:
同理,我们可以得到其它几个词的词向量:
好了,到这里你或许明白了我们的目标就是寻找一个变化矩阵Q。那么这个Q又是怎么寻找的呢,其实呢,这个Q矩阵是训练出来的。一开始,有一种神经网络语言模型,叫做NNLM,它在完成它的任务的时候产生了一种副产物,这个副产物就是这个矩阵Q。【这里我们不细讲了,大家感兴趣的去了解一下,资料很多】后面人们发现这个副产物挺好用,因为可以进行Word Embedding,将词变成词向量嘛。于是科研人员就进一步研究,设计出了Word2Vec模型,这个模型是专门用来得到这个矩阵Q的。【后面我们也叫这个矩阵Q为Embedding矩阵】🥗🥗🥗
Word2Vec模型有两个结构,如下:
- CBOW,这种模型类似于完型填空,核心思想是把一个句子中间的某个词挡住,然后用这个词的上下文单词去预测这个被挡住的词。🍚🍚🍚
- Skip-gram,这个和CBOW结构刚好相反,它的核心思想是根据一个给定的词去预测这个词的上下文。🍚🍚🍚
它们的区别可以用下图表示:
至于它们具体是怎么实现的我不打算讲,感兴趣的可以去搜搜。我简单说说它的思路:在它们训练时,首先会随机初始化一个Embedding表和Context表,然后我们会根据输入单词去查找两个表,并计算它们的点积,这个点击表示输入和上下文的相似程度,接着会根据这个相似程度来设计损失函数,最后根据损失不断的调整两个表。当训练完成后,我们就得到了我们的Embedding表,也就是Q矩阵。🍗🍗🍗
RNN模型
上一小节我们介绍了词向量,它解决的是我们NLP任务中输入问题。下面我们将一起来唠唠NLP任务中的常见模型。🍄🍄🍄
RNN模型结构
RNN(循环神经网络)我想大家多少都有所耳闻吧,它主要用于解决时序问题,例如时间序列、自然语言文本、音频信号等。
话不多说,我们直接来看RNN的模型图,如下:
上面的图用一个循环表示RNN,其实看起来还是比较不舒服,那么我们把这个循环展开,其结构就会比较清晰了,如下图所示:
知道了RNN的大体结构,我觉得你或与会对模块A的结构很敢兴趣,那我劝你不要太敢兴趣。🧃🧃🧃因为模块A真的很简单,就是一个tanh层,如下:
enmmmm,就是这么简单,如果你对此结构还存有疑惑的话,那么字写看看后文的代码手撸RNN部分,或许能解决你的大部分疑惑。
到这里,其实RNN的模型结构就讲完了,是不是很简单呢。🍭🍭🍭那么下面讲什么呢?自然是RNN存在什么问题,这样才能过渡到后面更加牛*的网络嘛。🍄🍄🍄
那么RNN存在什么问题呢?那就是长距离依赖问题,何为长距离依赖呢?他和短距离依赖是相对的概念,我们来举个例子来介绍什么是长距离依赖,什么是短距离依赖:
-
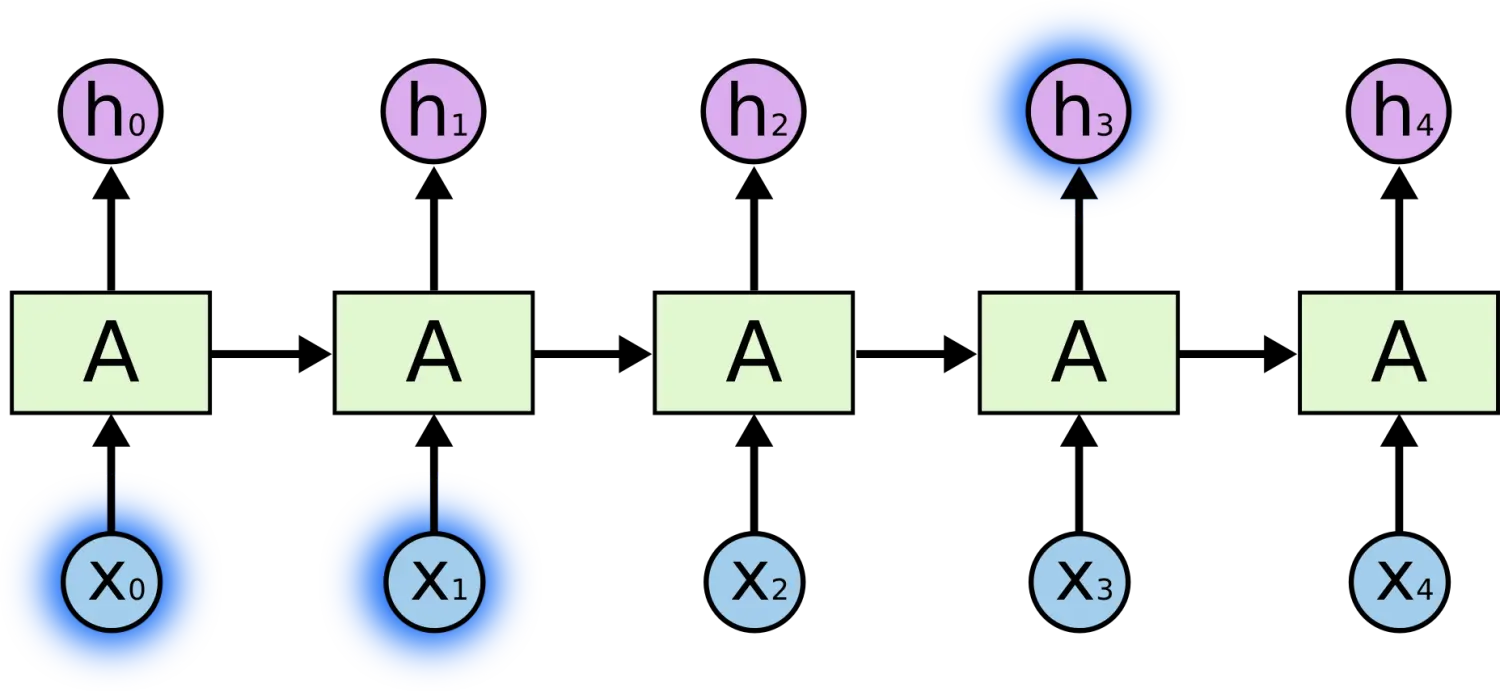
对于这样一句话:“我爱在足球场上踢__”,我们是不是很容易得到空格里的答案,因为在空格前几个字有足球场,所以我们知道这里要填“足球”。这种能根据上下文附近就判断预测答案的就是短距离依赖。【短距离依赖的图示如下】
-
对于这样一句话:“我爸爸从小就带我去足球场踢足球,我的爱好就是足球。我和爸爸关系非常好,经常带我一起玩耍,.......,真是一个伟大的父亲。长大后,我的爱好一直没变,现在我就要去踢__”,大家感受到了嘛,这里空格中要填的词我们要往上文找很就才可以发现,这种预测答案需要看上文很远距离找到答案的就是长距离依赖。
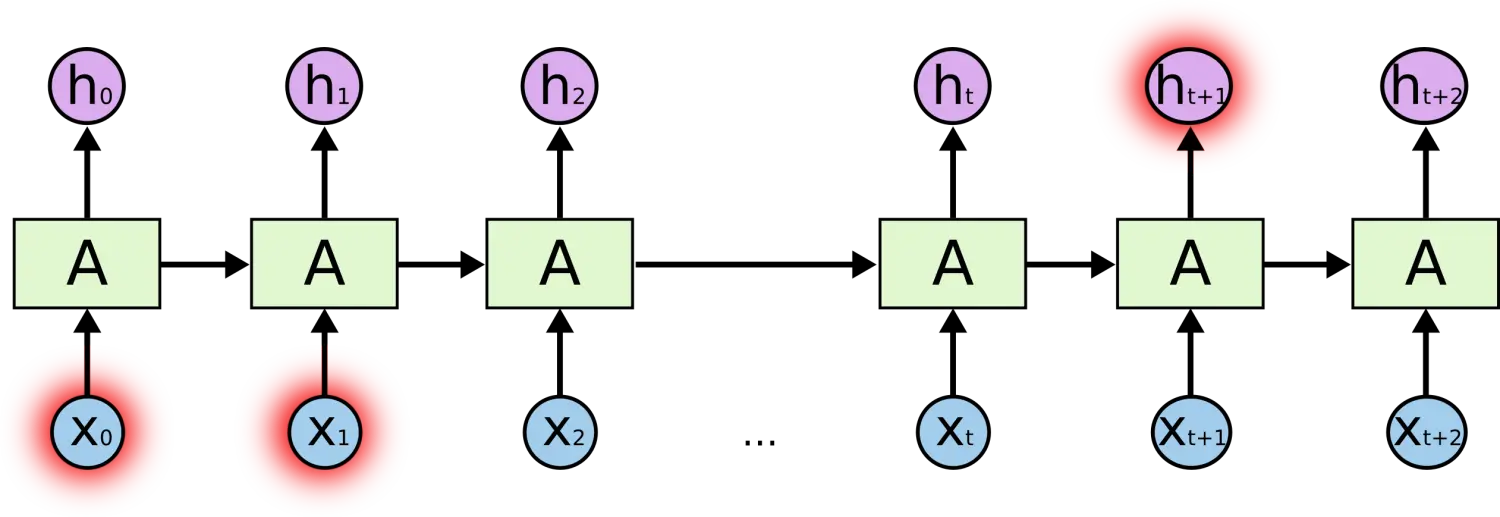
也就是说,RNN网络对于长距离依赖的问题效果很不好,因此我们后面会对RNN网络进行改进,进而提高其对长距离依赖的能力。🥝🥝🥝
手撸RNN
想必大家通过上文的讲述,已经对RNN的代码结构有了一定的认识,下面我们就来使用Pytorch来实现一个RNN网络,让大家对其有一个更加清晰的认识。🥂🥂🥂
这部分的思路是这样的,我先给大家调用一下官方封装好的RNN模型,展示模型输入输出的结果;然后再手撸一个RNN函数,来验证其结果是否和官方一致。
好了,我们就先来使用官方定义好的RNN模型来实现,具体可以看这个连接:RNN🍵🍵🍵
import torch
import torch.nn as nn
bs, T = 2, 3 #批大小,输入序列长度
input_size, hidden_size = 2, 3 # 输入特征大小,隐含层特征大小
input = torch.randn(bs, T, input_size) # 随机初始化一个输入特征序列
h_prev = torch.zeros(bs, hidden_size) # 初始隐含状态
我们先来打印看一下input和h_prev以及它们的shape,如下:
我们来解释一下这些变量,input就是我们输入的数据,他的维度为(2, 3, 2),三个维度分别表示(bs, T, input_size),即(批大小,输入序列长度,输入特征大小)。我这样介绍大家可能还一头雾水,我结合input的打印结果给大家介绍,首先很明显这是一个维度为(2, 3, 2)的向量,这个大家都知道哈,不知道我就真没办法啦,去补补课吧。🍸🍸🍸那么这个向量的第一个维度是2,就代表我们1个batch有两条数据,每个都是(3, 2)维度的向量,如下:
这个和计算机视觉中的bs(batch_size)是一个意思啦,接下来我们来看每条数据,即这个(3,2)维的向量,以第一条为例:这个3表示输入序列长度,表示每条数据又有三个小部分构成,分别为[-0.0657, -0.9015]、[-0.0324, -0.5666]、[-0.2630, 2.4861]。这是什么意思呢,这表示我们的输入会分三次送入RNN网络中,分别是x0、x1、x2,不知道这样大家能否理解,我画个图大家就知道了,如下:
大家可能发现了,这个维度的3个数据就相当于3个词,分别一步步的送入RNN网络中,那么其实最后一个维度2,也就是输入特征大小也很好理解了,它就表示每个词的维度,就是我们前文所说的词向量,那么我们这里就是每个词向量有两个维度的特征。🍚🍚🍚
通过上文的介绍,我想大家了解input这个输入了,那么h_prev是什么呢,其是隐层的输出,也就是上图中的h0、h1、h2。
接着我们就来调用pytorch中RNN的API:
# 调用pytorch RNN API
rnn = nn.RNN(input_size, hidden_size, batch_first=True)
rnn_output, state_final = rnn(input, h_prev.unsqueeze(0))
batch_first=True这个参数是定义我们输入的格式为(bs, T, input_size)的,pytorch文档中都解释的很详细,大家自己去看一下就好。至于这个h_prev.unsqueeze(0)这里加了第一个维度,这是由于RNN API的输入要求是三维的向量,如下:
我们来看看输出的rnn_output和state_final的值和shape吧,如下:
rnn_output其实就是每个隐藏层的输出,而state_final则是最终的输出,在基础的RNN中,state_final的值就等于最后一个隐藏层的输出,我们从数值上也可以发现,如下:
为了方便大家理解,再画一个图,如下:【注意:图都是以batch中一条数据为例表示的】
那么上文就为大家介绍了如何使用pytorch官方API实现RNN,但是这样我们无法看到RNN内部是如何实现的,那么这样我们就来手动实现一个RNN。其实很简单,主要就是用到了一个公式,如下:
这个公式可以在pytorch官方文档中看到,其实不知道大家发现没有,其实这个公式和卷积神经网络的公式是很像的,只不过RNN这里有两个输入而已。还有一点和大家说一下,上图公式中含有转置,实现起来转置来转置去的会很绕,上面的公式其实和下面是一样的【上下两个维度其实变了】:
为了简便起见,我用不带转置的进行代码编写,大家先理解好这个,最后我也会把带转置的代码放出来,这时候理解带转置的可能更容易点。
# 手写一个rnn_forward函数,实现RNN的计算原理
def rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev):
bs, T ,input_size = input.shape
h_dim = weight_ih.shape[0]
h_out = torch.zeros(bs, T, h_dim)
for t in range(T):
x = input[:,t,:].unsqueeze(2)
w_ih_batch = weight_ih.unsqueeze(0).tile(bs, 1, 1)
w_hh_batch = weight_hh.unsqueeze(0).tile(bs, 1, 1)
w_times_x = torch.bmm(x.transpose(1, 2), w_ih_batch.transpose(1, 2)).transpose(1, 2).squeeze(-1)
w_times_h = torch.bmm(h_prev.unsqueeze(2).transpose(1, 2), w_hh_batch.transpose(1, 2)).transpose(1, 2).squeeze(-1)
h_prev = torch.tanh(w_times_x + bias_ih + w_times_h + bias_hh)
h_out[:,t,:] = h_prev
return h_out, h_prev.unsqueeze(0)
接着我们就可以将这里面的参数传入到rnn_forward函数中,如下:
custom_rnn_output, custom_state_final = rnn_forward(input, rnn.weight_ih_l0, rnn.weight_hh_l0, rnn.bias_ih_l0, rnn.bias_hh_l0, h_prev)
同样,我们来打印一下custom_rnn_output和custom_state_final,如下:
经过对比,你可以发现,使用官方API和使用我们自定义的函数实现的RNN的输出是一样,这就验证了我们方法的正确性。
下面给出带转置的,即
这个表达式的代码供大家参考,如下:
# custom 手写一个rnn_forward函数,实现RNN的计算原理
def rnn_forward(input, weight_ih, weight_hh, bias_ih, bias_hh, h_prev):
bs, T, input_size = input.shape
h_dim = weight_ih.shape[0]
h_out = torch.zeros(bs, T, h_dim)
for t in range(T):
x = input[:, t, :].unsqueeze(2)
w_ih_batch = weight_ih.unsqueeze(0).tile(bs, 1, 1)
w_hh_batch = weight_hh.unsqueeze(0).tile(bs, 1, 1)
w_times_x = torch.bmm(x.transpose(1, 2), w_ih_batch.transpose(1, 2)).transpose(1, 2).squeeze(-1)
w_times_h = torch.bmm(h_prev.unsqueeze(2).transpose(1, 2), w_hh_batch.transpose(1, 2)).transpose(1, 2).squeeze(-1)
h_prev = torch.tanh(w_times_x + bias_ih + w_times_h + bias_hh)
h_out[:, t, :] = h_prev
return h_out, h_prev.unsqueeze(0)
LSTM模型
上文为大家介绍RNN模型,大家掌握的怎么样呢?🥦🥦🥦在RNN的原理介绍部分,我们谈到其存在长距离依赖的问题,为了解决这一问题,LSTM应运而生。那就让我们一起来见识见识LSTM是怎么实现的,如下图所示:
其实LSTM的整个流程是和标准RNN差不多的,区别主要就在于结构A中,大家乍一看是不是觉得还挺复杂的呢,不用担心,我们一点点的来为大家解析。首先第一步我们需要了解图中的关键图标含义,如下:
LSTM的核心就是细胞状态,也就是下图中的。
这个细胞状态可以保持信息在上面流动而保持相对小的改变。LSTM最关键的结构就是精心设计了三个门结构,分别是遗忘门、输入门和输出门,下面分别来介绍:【加上介绍细胞状态】
- 遗忘门
- 输入门
- 细胞状态
上文介绍输入门时谈到了创建一个新的候选细胞状态,创建好好,我们就可以更新细胞状态了,如下图所示:
- 输出门
注1:LSTM模型原理就讲到这里了,不知道大家能否听懂。我认为LSTM的核心就是选择性的记住一些事,又选择性的忘记一些事,大家也不用特别纠结内部的结构为什么会是这样,为什么不这样设计。其实LSTM有很多变体,感兴趣的可以去看看,如果你决定你有什么改进的思路,大可以去试试,说不定会达到不错的效果。🍭🍭🍭
注2:本节就不带大家手写LSTM了,看兴趣的可以去看参考连接6。🍄🍄🍄
ELMO模型
在词向量那一小节中,我们介绍了可以由word2vec模型来得到词向量,但是呢,这样得到的词向量会存在一个问题,即无法处理NLP任务中的多义词问题。这是什么意思呢?我们来看下面两句话:
- 我想吃一个
苹果,补充补充维生素。 - 我想买一个
苹果,嘎嘎打游戏上分。
对于上面两句话,都有苹果这个词,我们一眼就能看出这两个苹果不是一种苹果,但是在使用word2vec对苹果这个词进行编码时是区分不开两个苹果的不同含义的。也就是说,对于苹果这个词,我们使用word2vec将其转化成词向量的时候只会产生一种固定的词向量,这个词向量包含了两种苹果的语义。也就是说,如果对于一个新句子,如我爱吃苹果,能够很容易的知道他是苹果(🍎),但是词向量却不会变,依旧包含两种语义。🌼🌼🌼
我想不用说,大家也知道这样不好,因为这样我们就无法区别很多词的含义了。更何况中文博大精深,多义词更是数不胜数,这样无法区分的情况自然是不妙滴。那么我们能不能采取一些措施来应对一下这种情况呢?我给出以下两点,大家看看可不可行:🍟🍟🍟
- 给每个单词分配多个向量,并通过训练的方式学出每个单词对应的不同的向量。
- 先学习每个单词的基础向量,然后当这个单词应用在某一个上下文的时候,我们做动态的调整。
行不行呢,大家觉得行不行呢?我也不卖关子了,其实这两种方式都是可以的。先来说第一种方式,就是训练的前就给单词分配多个向量,这样学习出来的苹果就有多个向量了,一个向量可以表示水果苹果,一个向量可以表示手机苹果。但是呢,这种方式回大大增加计算成本,不同多义词的不同语义之间可能出现数据不平衡的问题,更为重要的是,我们往往也很难事先穷究单词的所有语义,就拿苹果来说,它也会是一手歌的名字(小苹果),也可能会是一个人的名字总之,这种方式存在一定的缺陷。🍚🍚🍚
上面说了第一种方法不好,那么现在再来谈谈第二种方法,自然就是不错了哈哈哈。这种方式便是这节我们要讲的ELMO模型的核心思想——事先学习一个单词的词向量(word Embedding),然后在使用这个词向量的时候,根据单词的上下文的语义去适当的调整词向量的表示,这样经过调整后的词向量就能够表达这个词在上下文中的含义了,也就解决了多义词的问题了。
ELMO模型采用了预训练+特征融合的方式,即采用了俩阶段过程,两个阶段如下:
- 第一阶段使用基于LSTM模型设计的结构进行预训练
- 第二阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的词向量作为新特征补充到下游任务中。
下面我们分别来看ELMO的两个阶段,第一阶段主要来分析ELMO的模型,如下:
若上图模型训练的目标是根据单词 的==上下文==去正确预测单词 , 之前的单词序列 Context-before 称为上文,之后的单词序列 Context-after 称为下文。
从图中可以看出,ELMO模型使用的基础结构是LSTM,还是一个两层双向的LSTM**(伪双向)**。
你或许会问,两层的LSTM是什么意思???enmmm,其实就是两个单层的LSTM的叠加,从上图中可以看出,第一层LSTM接受输入序列并产生一个中间的输出序列。然后,第二层LSTM接受第一层的输出作为其输入,并产生最终的输出。这种堆叠LSTM的结构有助于网络更好地捕捉数据中的抽象特征和时序关系,因为第二层LSTM可以进一步建模第一层LSTM的输出。
你或许会问,双向的LSTM是什么???可以看到,上图左端的结构的输入是从左到右的,是正方向编码器;而上图右端的输入是从右向左的,是反方向编码器。这就是双向LSTM。🥗🥗🥗
你或许会问,双向的LSTM有什么用???其实呢,它和单向的LSTM用处是一样的,可以用来预测单词,但是双向的LSTM可以根据单词上下文去预测单词,而普通的LSTM只可以通过上文去预测,多数情况下根据上下文预测单词会更准确些。🥗🥗🥗
你或许会问,根据上下文去预测单词,还预测个嘚啊,这不就是看着答案去做题嘛。🍋🍋🍋确实是这样,如果是纯纯的双向LSTM,确实会存在这种问题,但是ELMO虽然采用了双向结构,却是一个伪双向,不会产生see itself的问题。【后面讲的ERAT就是真正的双向,后面在来介绍其是怎么解决see itself的问题的】🍄🍄🍄
你或许会问,什么是伪双向啊???大家注意到图中正方向编码器和反方向编码器都有一个虚线框框住了嘛,其表示正方向编码器和反方向编码器是独立训练的,只是最后训练好将两个方向的loss进行相加。即无论是正方向编码器还是反方向编码器,一个是从左向右预测,一个是从右往左预测,其实本质都是一个单向的LSTM。总而言之,LSTM的伪双向有以下两个关键点:
- 对于每个方向上的单词来说,因为两个方向彼此独立训练,故在一个方向被encoding的时候始终是看不到它另一侧的单词的,从而避免了see itself的问题
- 而再考虑到句子中有的单词的语义会同时依赖于它左右两侧的某些词,仅仅从单方向做encoding是不能描述清楚的,所以再来一个反向encoding,故称双向
那么其实到这里ELMO的结构就介绍的差不多了,那么如果我们训练好这个网络后,可以得到什么呢?比如你输入一个“我爱吃苹果”这句话,那么ELMO网络会对句子中的每个单词输出三个词向量,分别为:
- 最底层的单词的word Embedding
- 第一层双向LSTM得到的对应单词的Embedding
- 第二层双向LSTM得到的对应单词的Embedding
这三个Embeding往往包含单词不同的信息,这和计算机视觉中卷积很像,越深层的网络越能得到单词的语义信息,如下:
也就是说,ELMo 的第一阶段的预训练过程得到了三个不同的词向量,这些词向量都会应用在后面的下游任务中。🍡🍡🍡
这里,我还是想强调补充一点,就是为什么ELMO可以识别多语义问题?🥱🥱🥱
其实这个答案就是由于ELMO的双向LSTM结构,因为这个结构会使得每个单词考虑了当前单词的上下文信息,从而使得得到的Embedding向量具有了上下文的信息。🌱🌱🌱
这样在我们进行下游任务的时候,会先将输入送到训练好的ELMO网络中,这时ELMO会根据当前的输入的上下文信息得到合适的词向量,然后应用这个词向量进行下游任务。🍀🍀🍀
上面介绍了ELMO的第一阶段即预训练阶段的过程,下面将来介绍如何将预训练好的网络,应用到下游任务当中去,如下图所示🍖🍖🍖
上图很清晰的展示了ELMO预训练摸摸胸如何在下游任务中使用,以下游任务为QA(提问解答)问题为例,对于问句X,有以下几步进行下游任务:
- 将句子X作为训练好的ELMO网络的输入,经过ELMO网络后我们会得到三个Embedding。
- 分别给予三个Embedding一个权重a,根据这个权重将三个Embedding通过加权和的方式整合成一个新的Embedding,这个权重可以学习得来。【这个就非常像CV中的特征金字塔等结构来融合不同层的信息】
- 再将上一步整合后的Embedding作为X句在自己任务的那个网络中对应单词的输入,以此作为新的特征给下游任务使用。
这整个就是ELMO的全部内容了,大家仔细的消化消化,多揣摩揣摩,一定会有收获的。🥗🥗🥗
Transformer模型
前面为大家介绍了RNN、LSTM、ELMO模型,大家学的怎么样了呢?这节要为大家介绍Transformer模型了,我实在是太开心啦!!!
开心???为什么???因为这个我之前写过啦,不用一个字一个字的敲咯。🍉🍉🍉大家可以点击下方链接阅读:
关于这篇文章我也想简单说两句,这篇文章从知识的输入,到文章结构的安排,再到作图,下笔直至最后的完成花费了两周时间,参考了很多资料,把一些资料中比较好的观点融入文章之中,用通俗的语言带你了解transformer,希望大家阅读后能够有所收获!
这篇文章也收获了一小笔奖金,一个微果C1的投影仪和500元激励,嘻嘻嘻。🍭🍭🍭
同时这篇文章也收获一些好评和一键三连,所以自己也是非常开心滴。🥂🥂🥂
说了这么多,不是炫耀哈哈哈,也不是凑字数啊,我想说的是我们应该更加注重文章的质量,这样其实不论是读者还是自己都会受益良多,是双赢的结果。🍡🍡🍡当然了,如果大家对Transformer感兴趣的话可以去读读看,还是比较容易理解的,一起加油。🍻🍻🍻
GPT
终于讲到GPT了,我想现在没有人对这玩意陌生的叭,随着22年底ChatGPT的一炮走红,震惊了全世界,可以说是颠覆式的研究成果了。那么GPT的底层原理到底是怎么样的呢?不用急,跟随我的步伐一步步的来学习。🥗🥗🥗
如果还有没尝试过ChatGPT的小伙伴,一定要去试试,会极大程度提高你的生产力。注册教程可以点击☞☞☞查看详情。🍄🍄🍄
ChatGPT并不是从0-1凭空出现的,而是经过不断的优化改进,最终实现出如此惊艳的效果。本节将为大家介绍初代GPT的结构,后续文章会陆续更新GPT系列的发展史,敬请期待。🍄🍄🍄
我们先来看看GPT的全称叫什么,即“Generative Pre-Training”,翻译即生成式的预训练。我们来解释一下这个名称“生成式的预训练”,所谓生成式,表示该模型可以用于文本生成任务;而预训练则表示该模型先通过大规模的文本数据集进行训练,然后再用于下游任务。【这个和计算机视觉中的预训练含义是一样的】🍭🍭🍭
上文说到,GPT采用了预训练的方式来训练模型,其主要有两个阶段,如下:
- 阶段一:利用语言模型进行预训练
- 阶段二:通过Fine-tuning对下游任务进行微调
下图展示了GPT预训练的过程,我们一起来看看:
从上图中我们可以发现GPT的结构是这样的,如下:
大家有没有发现这个结构是和前文所述的ELMO模型非常类似的,当然了,也有一些差异,如下:
- 特征提取器使用的不是LSTM,而是特征提取能力更强的Transformer。【自GPT之后,几乎所有模型都开始使用Transformer架构来进行特征提取】
- GPT的预训练任务任然是语言模型,但是采用的是单向的语言模型。
大家听了以上两点,可能懂了一点,但也没完全懂,下面我将针对这两点做一个更细致的解释。
点1 :这里使用了Transformer架构,他的具体结构是什么样的呢?我们先来说结论:**GPT中的Transformer结构就是把Encoder中的Multi-Head Attention替换成了Masked Multi-Head Attention。**如下图所示:
看到上文的话不知道大家能否理解,我觉得你要是熟悉Transformer结构应该就能够理解了,Transformer结构主体由一个Encoder结构和一个Decoder结构构成,Encoder结构中使用了Multi-Head Attention,而Decoder中使用了Masked Multi-Head Attention。这里具体细节我就不说了,不清楚的可以去看我关于Transformer的博客介绍。我也贴一张Transformerd的结构图,方便大家对比,如下:
大家注意一下我说的是GPT中的Transformer结构就是把Encoder中的Multi-Head Attention替换成了Masked Multi-Head Attention。,大家可以对比一下结构,看看我的表述是否正确。网上也有一些说法说是GPT中的Transformer结构就是Transformer中的Decoder结构,其实还是存在一些问题的,因为Decoder结构中采用了两个连续的Masked Multi-Head Attention+LN结构,而GPT的Transformer中只使用了一个。【大家这里注意一下就好,在一些博客和平时交流中知道这么一回事就行,在后文我也会采取GPT采用的是Transformer中Decoder的说法,因为字少哈哈哈。🍄🍄🍄】
大家可能还注意到在GPT的Transformer结构中还有一个
12×的字眼,其表示这个结构重复12次。为了大家能更深入了解GPT的Transformer结构,可以看一下如下代码:
from .attention import tf, MultiHeadAttention class TransformerBlock(tf.keras.layers.Layer): def __init__(self, embedding_dimension, num_heads, feed_forward_dimension, dropout_rate=0.1): super(TransformerBlock, self).__init__() self.attention = MultiHeadAttention(embedding_dimension, num_heads) self.feed_forward_network = tf.keras.Sequential([ tf.keras.layers.Dense(feed_forward_dimension, activation='relu'), tf.keras.layers.Dense(embedding_dimension) ]) self.layer_normalization = [ tf.keras.layers.LayerNormalization(epsilon=1e-6), tf.keras.layers.LayerNormalization(epsilon=1e-6) ] self.dropout = [ tf.keras.layers.Dropout(rate=dropout_rate), tf.keras.layers.Dropout(rate=dropout_rate) ] def call(self, inputs): attention_output = self.dropout[0](self.attention(inputs)) residual_output = self.layer_normalization[0](inputs + attention_output) feed_forward_output = self.dropout[1](self.feed_forward_network(residual_output)) output = self.layer_normalization[1](residual_output + feed_forward_output) return output大家可以阅读一下代码,看看是不是和我们上面所说的结构一致呢。需要注意的是上述代码家了一个Dropout结构,对整体的结构不影响。
点2:GPT采用的是单向的语言模型是什么意思?语言模型训练的任务目标是根据w_i单词的上下文去正确预测单词w_i , w_i之前的单词序列Context-before称为上文,w_i之后的单词序列Context-after称为下文。再使用ELMO做语言模型训练的时候,预测单词w_i时同时考虑了该单词的上下文,而GPT只采用这个单词的上文来进行预测,抛弃了下文。为什么GPT看不到下文的信息呢,这就是因为GPT的Transformer结构使用了Masked Multi-Head Attention结构,其遮挡住了后面单词的信息,Multi-Head Attention和Masked Multi-Head Attention的区别如下:
上文为大家介绍的是模型的基本架构,当我们用此模型进行训练就完成了第一阶段的任务,即实现了模型的预训练,那么接下来如何进行第二阶段的任务——通过Fine-tuning对下游任务进行微调呢?如下图所示:
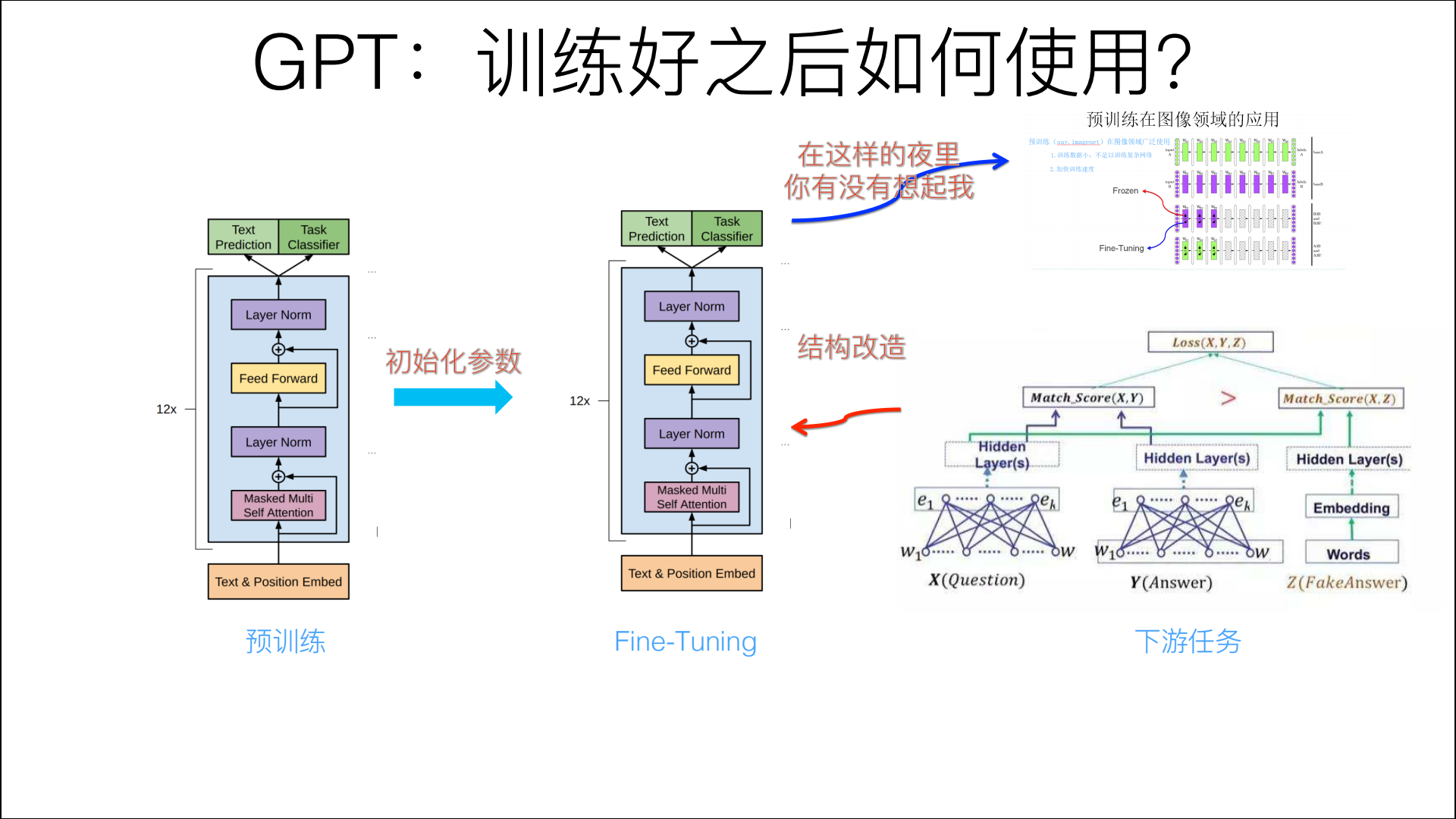
上图展示了下游任务如何进行微调。在ELMO模型中,其下游任务的网络结构是可以任意设计的,因为其用到的是ELMO模型训练出的词向量;而在GPT中,下游任务的网络结构可不能修改了,必须要和GPT预训练时保持一致,因为GPT在做下游任务时,下游任务的网络结构的初始化参数就是已经训练好的GPT网络的参数,这样你就可以利用预训练好的知识来应对你的下游任务了,相当于开局就送神装了,当你训练你的下游任务时,只需要进行微调就可以了。【这部分其实是很好理解的,就是计算机视觉任务中的迁移学习嘛🥗🥗🥗】
论文链接:GPT1🍁🍁🍁
本节就先为大家介绍到这里,后续会为大家介绍更多版本的GPT。🍄🍄🍄
BERT
这一节来为大家介绍大名鼎鼎的BERT了,我想任何一个NLPer都不会没有听过BERT的大名叭。BERT,其实他是美国少儿节目中的一个人名,他长这样:

所以大家在搜BERT时,可能会经常看到上图这样的一个封面,果然,起名字还是很重要的。说起名字,我们还是先看看BERT的全称叭——Pre-training of Deep Bidirectional Transformers for Language Understanding。🍚🍚🍚
从BERT的全称中我们可以看出什么?我觉得有以下两点是比较关键的:
Pre-training:说明BERT和GPT一样都是一个预训练的模型Deep Bidirectional Transformers:说明BERT采用了一个双向的Transfomer结构
针对以上两点,第一点表明EBRT是一个预训练模型,也即分为预训练阶段+微调阶段,这和GPT的预训练是差不多的,后文我们在简单介绍下。我们主要来看看BERT的结构是怎么样的,如下:
不知道大家看到这个图有没有熟悉的感觉,要是有那就太好了,没有的话我们就一起来看看。我们上文已经为大家介绍了ELMO模型和GPT模型,下面我们将三个模型放一起看看三者的区别:
有没有发现他们三个实在是太像了,在上节介绍GPT时,我们说到,GPT和ELMO非常类似。今天这节的主角是BERT,那我们就来说说BERT和ELMO、GPT的区别和联系。
-
BERT和ELMO
- ELMO采用LSTM作为特征提取器,而BERT采用的是Transformer中的编码器结构。【这个可以从BERT的结构图可以看出,每一个Trm都是一个Transformer的编码器】🥗🥗🥗
- ELMO采用的是伪双向编码,即使用从左向右和从右向左的两个LSTM网络,它们分别独立训练,最好将训练好的两个方向的编码拼接。【有关ELMO的伪双向编码在ELMO模型那节有详细介绍】而BERT采用的是一个完全的双向编码,即完全可以看到某个单词的前后信息。
-
BERT和GPT
- GPT采用Transformer的解码器作为特征提取器。【这个在GPT小节提到说解码器有些不妥,大家注意一下就好】而BERT采用的是Transformer的编码器作为特征提取器。
- GPT采用的是单向编码,而BERT采用的是双向编码。
总的来说,BERT可以说是近年NLP邻域具有里程碑意义的模型,它借鉴了ELMO、GPT等模型的思想(借鉴了ELMO的双向编码、GPT的Transformer结构),是集大成者。
读到这里,不知道大家是否会存在一些疑惑,我列一些我能想到的,希望可以帮到大家。
什么是单向编码,什么是双向编码?
其实这个很好理解,单向编码就是只考虑一个方向的信息,而双向编码则会考虑两个方向即上下文的信息。我举个例子,对于这句话“今天天气很__,我要去踢足球”,现在要考虑在__填什么词。对于单向编码只会看到__前面的句子,即“今天天气很”,那么此时__填入的可能是“糟糕”、“不错”、“好”等等词;但是对于双向编码来说,它还可以看到后文“我要去踢足球”,那么__里的词应该是积极的,比如“不错”、“好”。从这里可以看出,其实双向编码对于句子的理解能力更好。🥂🥂🥂
为什么GPT要采用Transformer的解码器做特征提取,而BERT要采用Transformer的编码器做特征提取?
其实它们特征提取器的不同,是因为它们的任务和目标不同。对于GPT来说,其旨在生成自然语言文本,例如生成文章、回答问题、完成句子等。因此,它的任务是基于输入文本的信息生成下一个单词或一段文本。为了完成这一任务,GPT采用了Transformer架构的解码器部分,由于解码器中存在Musk Multi-Head Attention的缘故,使得GPT看不到未来的信息。对于BERT来说,其任务是预训练一个深度双向的语言表示,以便于各种自然语言处理任务的下游任务(如文本分类、命名实体识别、句子关系判断等)。BERT关注的是理解文本的含义和上下文,而不是生成文本。为了实现这一目标,BERT采用了Transformer架构的编码器部分。编码器通过双向处理输入文本,从而更好地理解单词的上下文关系和语境,而不受生成顺序的限制。
注:GPT和BERT也没有好坏之分,它们只是处理的任务和目标不同。但是显然GPT的任务其实更难一些,因为其只能看见现有信息,无法看到未来。现在随着ChatGPT的出现,就能发现当时OpenAI团队似乎就在下一盘大棋。
看到这里,我想你对BERT的结构已经比较清楚了,就是一个两层的双向Transformer Encoder嘛。下面我们一起来BERT是怎么进行训练的,当然了,BERT也是预训练模型,分为两个阶段进行训练:
- 阶段一:使用大规模无标签语料,训练BERT基础语言模型
- 阶段二:对下游任务进行微调
那么BERT是如何训练的呢,它其实实现了两个训练任务,分别是语言掩码模型(MLM)和下句预测(NSP),这也算是BERT的两个创新之处,我们分别来看一下:
-
语言掩码模型MLM
我们上文说到,BERT采用的是双向编码,之所以采用双向编码,是因为作者认为双向编码的性能、参数规模和效率更加优异。但是双向编码会存在see itself的问题呀,就是能看到参考答案。
注意:大家回顾一下我在介绍ELMO模型时,是不是也谈及了see itself问题呢?ELMO模型是怎么解决的呢?——其通过的是两个方向彼此独立训练两个LSTM模型后再拼接的方式,实际上是一种伪双向模型,从而避免了see itself的问题。但是BERT可没有采用这种伪双向的方式,而是直接使用Transformer Encoder做一个完全双向的模型,这就会导致BERT存在see itself的问题。🍚🍚🍚
大家不要问为什么作者不采用伪双向+Transformer Decoder的结构,问就是效果没有完全双向的效果好。🥗🥗🥗
既然BERT存在see itself的问题,那么他是怎么做的呢?——答案就是MLM(Masked Language Model),什么是MLM呢,其实就是指在训练的时候随机从输入语料上Mask掉一些单词,然后通过的上下文预测该单词。大家有没有觉得非常像CBOW的思想,即完形填空。🍭🍭🍭
上述随机被Mask的单词被称为掩码词,在训练过程中,输入数据随机选择15%的词用于预测,即作为掩码词。但是这样的设计会存在一些问题,即在预训练和微调之间造成了不匹配,因为 [MASK] 标记在微调期间不会出现。
那么怎样缓解这样的弊端呢,BERT是这样做的:
对于随机选择的15%的掩码词再做以下调整
-
80%的词向量输入时被替换为
-
10%的词的词向量在输入时被替换为其他词的词向量
-
另外10%保持不动
论文中也给出了关于此的小例子,如下图所示:
这样做的好处是我告诉模型,句子可能是对的,也可能是错的,也可能是被Mask的,有的地方你需要预测,没有的地方你也需要判断是否正确,也就是说,模型需要预测所有位置的输出。
-
-
下句预测(NSP)
NSP全称为“Next Sentence Prediction”,即下句预测,其任务是判断句子B是否是句子A的下文,如果是的话输出’IsNext‘,否则输出’NotNext‘。
为什么要做这个任务呢?因为在很多自然语言处理的下游任务中,如问答和自然语言推断,都基于两个句子做逻辑推理,而语言模型并不具备直接捕获句子之间的语义联系的能力,或者可以说成单词预测粒度的训练到不了句子关系这个层级,为了学会捕捉句子之间的语义联系,BERT 采用了下句预测(NSP )作为无监督预训练的一部分。
具体怎么做NSP任务呢?BERT 输入的语句将由两个句子构成,这两句是从预料中随机抽取的,其中:
- 50% 的概率将语义连贯的两个连续句子作为训练文本,符合IsNext关系
- 另外50%是第二个句子从语料库中随机选择出一个拼到第一个句子后面,它们的关系是NotNext
论文中也给出了相关的事例,如下图所示:
我对上图中的符合做一些解释:
- [CLS]:对于一个句子最前面的起始标识。【在CV中的VIT就有这个标识,不知道大家是否还记得,VIT就是借鉴了BERT。】
- [MASK]:这就是我们在MLM中所说的掩码标识符
- [SEP]:表示两个句子的分隔符
- ##:这个设计到BERT划分词的标准,其不是根据单词划分的,对于一些常见的词根会单独划分,这样会大大减少字典数量,##这个符合表示flight和less是一个单词。
其实到这里MLM和NSP就介绍完了,上面我们看到对于一句话有各种符号,那么我们的输入是如何设计的呢,这部分我们就来看看BERT对输入的处理,如下图所示:
从上图可以看出,对于Input中的每个词,都有三个Embedding,分别如下:
- 单词Embedding:这就是我们之前所说的词向量嘛,大家注意一下这里也要对标识符进行Embedding。
- 句子Embedding:用于区分两个句子,其只有两个值,0和1。0表示前一个句子,1 表示后一个句子。对于上图中的输入我们来看看其句子Embedding的表示,如下图所示:
- 位置信息Embedding:这个我就不多介绍了,在Transformer小节做了详细的介绍,不清楚的可以去看一下。但要注意的是在Transformer中我们的位置编码是使用三角函数表示,这里采用的是可学习的位置编码,关于可学习的位置编码,我在VIT有所介绍,不清楚的点击☞☞☞前去阅读。
上面介绍的是BERT的预训练过程,下面来说说下游任务微调部分,直接上论文的图,如下:
其实微调很简单,都是利用之前训练的BERT模型,这部分我不打算逐字介绍了,推荐大家去看李宏毅老师的这个视频:BERT下游任务改造
最后我们来看看BERT的效果怎么样,如下图所示:
不用我多说了叭,BERT确实厉害,但是其参数量是巨大的,普通人可跑不起来,接下来让我们来看看BERT的参数量。论文中给出了BERT的两种结构,分别是和,参数量分别达到了恐怖的110M和340M,如下图所示:
这里的M的数值也可以从论文中看到,如下图所示:
论文链接:BERT🍁🍁🍁
参考连接
如若文章对你有所帮助,那就🛴🛴🛴
InfoQ首发链接:CVer从0入门NLP——GPT是如何一步步诞生的