




【干货分享】数据挖掘比赛中常见的评价指标解读以及应对方法——赶快拿去上分吧
入圈一年多,虽然奖没有获得几个,但是比赛见的确实不少,也算是见过世面了。既然是比赛那么就有评价指标,一般常见的二分类指标准确度,AUC等,也有不常见的指标比如Kappa,分段覆盖率等。理解评价指标是数据挖掘的第一步,也是能否取得Top名次的关键一步。今天我来介绍一下常用的评价指标,以及针对这些指标的优化方法。
一:二分类
首先从二分类开始开始,一般二分类比赛中的指标有准确度,F1,AUC,分段覆盖率。由于准确度太简单了,我们从F1开始介绍。
1:F1指标
需要了解F1指标我们首先需要了解下大名鼎鼎的混淆矩阵,如下图所示:
| 混肴矩阵 | 真实值 |
| 1 | 0 |
| 预测值 | 1 |
| 0 | FN |
注意 :T和F表示的是预测的是否正确,P和N表示的是预测值为1或者0(这四个符号经常容易记混)。
了解F1指标之前我们先要了解另外的两个概念,叫做精准度和召回率。其中精准度的计算公式为:
精准度(PPV)= TP/(TP+FP)
召回率的计算公式为:
召回率(TPR) =TP/(TP+FN)
精准度,召回度其实都是医学上的概念,医生负责把阳性的患者挑选出来,精准度就是医生挑选出来的患者(判定为阳性)中真实是阳性的概率。召回率是指医生挑选出来的阳性患者占总体阳性患者的占比。一般在数据挖掘的时候我们也会将召回率称之为覆盖率。
一般来看精准度与召回率之间是一种互斥的指标,当医生出手更多次的时候(判定为1的数量越多),那么判定错误的概率也就越大,因此精准率也就越低,但是可以将更多的阳性患者抽出来,因此召回率会增加。 **当召回率和精准率一样的时候说明你预测为1的数量和实际为1的数量是一样的,当召回率大于精准率,那么说明预测为1的数量多了,反正则少了。**
F1指标相当于召回率和精确率的一种权衡,它的计算公式是:
F1=2(PPVTPR)/(PPV+TPR)**
F1指标的处理方式:
上文介绍完了F1指标,现在我们来介绍下碰到这种指标该怎么处理。以lgb建模为例(一般数据挖掘比赛lgb用到的是最广泛的,我们下文的介绍都是以lgb建模为基础),选择metric为AUC,五折验证后我们可以得到oof(训练集的预测概率),prediction(测试集的预测概率)。我们都知道评价指标为F1的时候我们的提交结果只能有0和1,那么怎么把prediction (一般是概率)的结果转化为0和1呢?直接卡0.5的阈值?那也太年轻了。一般有以下两种方法。
1:线下阈值法
1from sklearn.metrics import f1_score
2def getyuzhi(oof,y):
3 """
4 oof 线下验证集的预测结果
5 y 训练集的真实结果
6 """
7 maxf1=0
8 yuzhi=0
9 for i in range(1,1000):
10 t=i/10000
11 tem=[0 if i<t else 1 for i in oof]
12 if f1_score(y,tem)>maxf1:
13 maxf1=f1_score(y,tem)
14 yuzhi=t
15 return yuzhi
根据线下的结果搜索阈值,然后将搜素到的阈值应用到线上去(我一般用的是简单的暴力搜索,在实际中也可以用更有效的搜索方法,我下文会介绍),我个人认为这是最合理的一种方法,当线下和线上不一致的时候,这种方法就更不适用了。遗憾的事,我最近在跟进的几个比赛都是这样的。因此下面还有另外一种方法。
2:线上拟合法
很多人看到线上拟合会觉得不能接受,但是这毕竟是第一种方法效果不好的情况下才采用了,正常来说第一种方法效果不好,几乎可以认定这个比赛线下线上同分布性并不好。线上拟合也分为两种,第一种如下
1"""查看线下0-1的分布"""
2print(len(y))
3print(sum(y))
4"""计算如果线上分布一致的话提交预测1的数量"""
5print(len(prediction)*sum(y)/len(y))
6temp=sorted(prediction)
7"""根据提交1的数量确定阈值"""
8yuzhi=temp[len(prediction)*sum(y)/len(y)]
9"""根据确定的阈值将预测结果划分为0-1"""
10prediction=[0 if i<yuzhi else 1 for i in prediction]
第一种就是 **假定线上的0-1分布和线下相近** ,这样卡阈值可以取得一个不错的结果。
还有另外一种就更直接,随机选择阈值去猜测线上实际1的数量,之后每次提交1的数量和猜测的相近。这种是 **假定AB榜分布** 相近。
2:分段覆盖率
这是一个大家可能非常不熟悉的评价指标,我也是在DC数据城堡的山东赛的公积金赛题中遇到的。介绍这个指标之前我再给大家普及一个概念:
(FPR)打扰率=FP/(FP+TN)
这个指标的意思是,本来为0但是为你预测为1的数量占本来为0的比例。直译就是被你打扰(本来是0,但你认为是1)的比例。
了解了这个概念后就可以引入分段覆盖率了,在已经得到oof(训练集的预测概率),prediction(测试集的预测概率)的情况下,卡不同的阈值,可以得到不同的FPR,阈值越小,预测为1的个数越多,预测将0预测为1的数量也就越多,这时候FPR的值也就越大,不同的FPR也对应了不同的覆盖率。下图就是FPR和覆盖率之间的关系,也就是大家都可能听过的ROC曲线,横坐标是打扰率,纵坐标为覆盖率。
分段覆盖率就是在指定打扰率的情况下的覆盖率。比如山东赛题中的优化指标是打扰率为0.001,0.005,0.01下的加权覆盖率。对于这种指标怎么进行优化呢?或者怎么进行预测才能取得好的结果呢?其实我目前也在做这个赛题,差不多弃赛了,我并没有很好的方法,只能说说自己的看法。
PS:下文有点长,可能有点废话,不喜欢直接跳过。(为了方便跳过,我放在了代码块中)
1预测还是使用AUC作为模型的metric,
2但是该指标与AUC有一些不同,下文是我的一点分析
3
4覆盖率:就是你预测的真且对了的除以所有的真的,
5打扰率:就是你预测的真且错了的除以所有的假的
6现在假设总的负样本1000个。
7打扰率为0.001下的覆盖率,指的是在尾部的1000个假的中,
8你指预测错了一个的情况下,你的覆盖率。
9
10假设本来你的预测结果全部为假,阈值为1,随着阈值慢慢变小,
11在你的预测结果中出现了1,但是这些1真实情况下也是1。
12
13随着阈值再次减少,你预测的1中有些真实情况下却是0,这时候你出现了第一个预测错误,
14假如所有样本中就10000个假的。
15
16阈值继续减少,此时出现了10个真实情况下为0但是在阈值之上的样本了。
17那么这时候你的打扰率吧就为0.001。
18
19现在计算覆盖率。从正常角度来说,阈值上面的值越多,代表着你的覆盖率越高,
20因此此时的覆盖率=(阈值上的数量-10)/样本总体为真的数量
21意味着我们在阈值慢慢变小的情况下,需要尽可能地推迟预测为1但实际为0样本的出现。
22
23假设打扰率在0.0001的情况下,覆盖率为0.5。那么表示现在阈值上面有110个,
24这是我们预测为正,但是100个为正样本,10个为负样本。
25如果我们可以剔除掉1个负样本的话,可能就可以重新增加5个正样本,
26这时候阈值上面的样本就是115(105个正,10个负)。
27此时覆盖率达到52.5%。
28
29总结来说,非常害怕在预测得分高的情况下出现实际标签为0的情况,非常影响得分。
3:AUC指标
上文提到了ROC曲线,其实曲线下的面积就是AUC的值,也可以是覆盖率在打扰率在0到1上的积分。可以看到如果需要AUC的值尽可能地大,那么在打扰率很小的时候覆盖率就要尽可能地大。AUC指标一般是最常用也是我认为最好地指标了,因为它不需要任何的其它后处理操作。直接在lgb的metric中设置AUC就好。
二:多分类
多分类问题我见的比较少,所以我在这里就介绍一个,也是我去年在厦门国际银行比赛中遇到的(这个比赛的 TOP开源我已经放到这个公众号里面了,如果想看的话可以稍微翻一翻),那就是kappa。
首先我们还是先看看kappa是怎样的(以三分类为例)
| 混肴矩阵 | 实际类别 |
| 1 | 0 |
| 预测类别 | 1 |
| 0 | 70 |
| -1 | 30 |
首先计算准确度:
ranh
然后计算Pe,计算公式是每类预测正确的数目乘以该类别本来的数目的平方除以样本总量的平方。
最后kappa值的为:
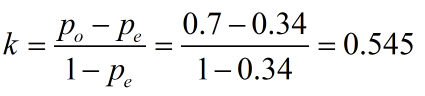
上文就是kappa公式的介绍,也并不复杂,但是对于这样一个指标我们怎么应对呢?首先请大家看一下我在该比赛的应对方法:
1from sklearn.metrics import cohen_kappa_score
2from sklearn.metrics import accuracy_score
3def kappa(preds, y\_true):
4 """
5 preds:是训练集的预测结果
6 y\_true:是真实的结果
7 """
8 rate=[0.6+i/200 for i in range(20)]
9 rate1=[1+i/200 for i in range(40) ]
10 rate=rate[::-1]
11 for i in rate:
12 for j in rate1:
13 xxx=preds.copy()
14 xxx[:,2]=i*xxx[:,2]
15 xxx[:,0]=j*xxx[:,0]
16 pred = np.argmax(xxx, axis=1)
17 score = cohen_kappa_score(y_true, pred)
18 print(collections.Counter(pred))
19 print(accuracy_score(y_true, pred))
20 print("阈值1:",i,"阈值2:",j," 分数:",score," 比例",collections.Counter(pred))
我这种方法就是线下搜索的方法,根据线下的结果调整0,1,-1的三个值的预测结果(扩大或者减小某一列的值),然后使用np.argmax的方法将预测结果转化为0,-1,1。比较输出的kappa分数,获得得分最高的两个阈值i,j(采用2个参数就可以调整三列的比例了,如果是四分类,那么则需要三个参数)。同理,在测试集中也这样,ccc就是测试集最终提交的结果。
1x2=predictions.copy()
2x2[:,2]=i*x2[:,2]
3x2[:,0]=j*x2[:,0]
4xxx=x2
5ccc=np.argmax(xxx,axis = 1)
在该比赛中我用这个方法搜索相比不搜索可以提高2个百分点。因此在上一篇文章中我才会说到,搜索kappa才是该比赛上分最直接的方法。
看了我的搜索方法,是不是觉得很low,其实我也觉得,在该比赛初赛结束后我学习到了另外一种搜索方法(感谢OTTO成员在群里分享)。
1from sklearn.metrics import cohen_kappa_score
2from functools import partial
3import scipy as sp
4
5def kappa\_loss(weight, oof, y):
6 oof = weight*oof
7 loss = cohen_kappa_score(y, np.argmax(oof, axis=1))
8 return -loss
9
10def get\_weights(oof, y):
11 size = np.unique(y).size
12 loss_partial = partial(kappa_loss, oof=oof, y=y)
13 initial_weights = [1. for _ in range(size)]
14 weights_ = sp.optimize.minimize(loss_partial, initial_weights, method='Nelder-Mead')
15 return weights_['x']
16weights = get_weights(oof, y)
其实思路都是一样的,只是这种搜索方法更加快速和精确一些,还有就是逼格更高。这种搜索方法在之前以kappa为评价指标的比赛中就开源过了,只是本人入圈比较晚,不知道,没准最后痛失决赛与这个有关,现在分享给大家,供大家一起学习。
另外我在kaggle上搜kappa的时候,发现了另外一种kappa的搜索方法,不过它是应用与回归问题中的。在有些多分类问题中,分类之间存在很明显的大小关系,比如预测年龄学历等,这时候采用回归来预测不失为可行的方法。下面附上回归预测中搜索kappa值的代码:
1import numpy as np
2import pandas as pd
3import os
4import scipy as sp
5from functools import partial
6from sklearn import metrics
7from collections import Counter
8
9class OptimizedRounder(object):
10 def \_\_init\_\_(self):
11 self.coef_ = 0
12 def \_kappa\_loss(self, coef, X, y):
13 X_p = np.copy(X)
14 for i, pred in enumerate(X_p):
15 if pred < coef[0]:
16 X_p[i] = 0
17 elif pred >= coef[0] and pred < coef[1]:
18 X_p[i] = 1
19 elif pred >= coef[1] and pred < coef[2]:
20 X_p[i] = 2
21 elif pred >= coef[2] and pred < coef[3]:
22 X_p[i] = 3
23 else:
24 X_p[i] = 4
25 ll = metrics.cohen_kappa_score(y, X_p, weights='quadratic')
26 return -ll
27 def fit(self, X, y):
28 loss_partial = partial(self._kappa_loss, X=X, y=y)
29 initial_coef = [0.5, 1.5, 2.5, 3.5]
30 self.coef_ = sp.optimize.minimize(loss_partial, initial_coef, method='nelder-mead')
31 def predict(self, X, coef):
32 X_p = np.copy(X)
33 for i, pred in enumerate(X_p):
34 if pred < coef[0]:
35 X_p[i] = 0
36 elif pred >= coef[0] and pred < coef[1]:
37 X_p[i] = 1
38 elif pred >= coef[1] and pred < coef[2]:
39 X_p[i] = 2
40 elif pred >= coef[2] and pred < coef[3]:
41 X_p[i] = 3
42 else:
43 X_p[i] = 4
44 return X_p
45 def coefficients(self):
46 return self.coef_['x']
47optR = OptimizedRounder()
48optR.fit(valid_predictions, targets)
49coefficients = optR.coefficients()
50valid_predictions = optR.predict(valid_predictions, coefficients)
51test_predictions = optR.predict(test_predictions, coefficients)
以上就是这次介绍的全部评价指标了,希望可以用来帮助大家上分,如果想更加深入地了解其它指标的话,欢迎下面留言。最后希望比赛方真诚一点,少弄点稀奇古怪的指标。
想了解更多机器学习、竞赛知识,关注微信公众号ChallengeHub!也可以加入qq群一起讨论「微信群需要后台回复」。