




做拼多多店群或者竞品分析,需要批量采集搜索词下的商品数据。拼多多页面结构相对稳定,但有“已拼xx万件”这种带单位的销量,以及动态加载的商品列表。
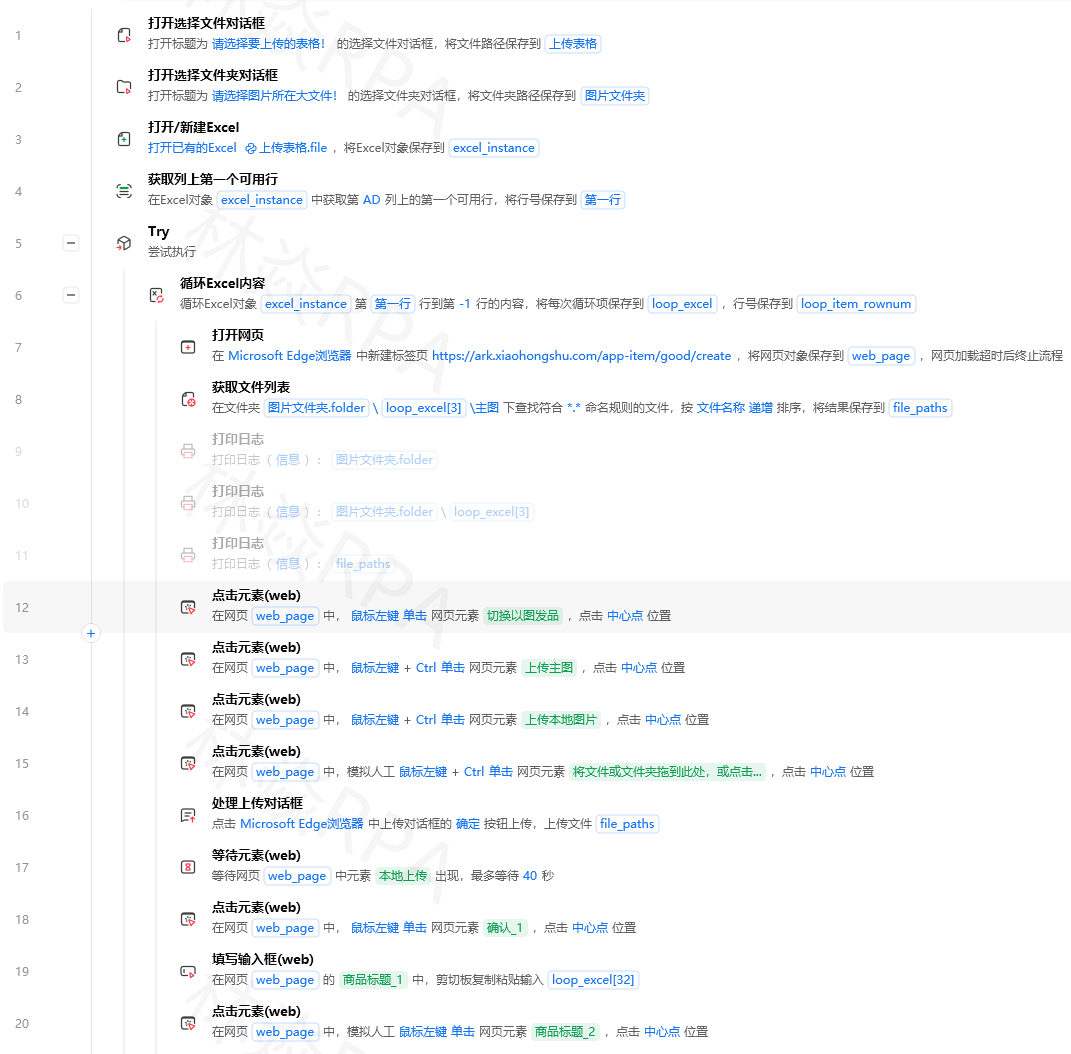
核心流程:打开拼多多 → 搜索关键词 → 获取商品列表容器 → 循环采集标题/价格/销量/店铺名 → 翻页 → 导出Excel。
一、整体流程结构
| 子流程 | 功能 |
|--------|------|
| A_Main | 主流程调度 |
| B01_Login | 登录(拼多多通常不需要强制登录,但登录后可以看更多) |
| C01_SearchAndCollect | 搜索+采集当前页+翻页 |
| D01_ExportToExcel | 导出Excel |
拼多多特点: 不需要登录也能搜索,但销量数据可能不完整。建议先扫码登录。
二、步骤1:登录拼多多(可选但推荐)
# B01_Login 子流程
打开网页:"https://mms.pinduoduo.com" # 商家后台,或直接用主站 "https://www.pinduoduo.com"
# 拼多多主站登录入口通常在右上角“个人中心”或“登录”
# 判断是否已登录(检查“个人中心”元素)
判断元素是否存在://div[contains(@class,'user-avatar')] → 存入“已登录”

如果 已登录 == False
# 点击登录按钮
点击元素://div[contains(text(),'登录')] 或 //a[contains(text(),'登录')]
# 等待二维码或手机号登录框
等待元素出现://div[@class='login-modal'],超时5秒
输出日志:"请扫码或输入账号密码,等待30秒"
固定等待:30秒
判断元素是否存在://div[@class='user-avatar'] → 存入“登录成功”
如果 登录成功 == False

输出日志:"登录失败,终止流程"
返回
否则
输出日志:"登录成功"
三、步骤2:搜索关键词
# C01_SearchAndCollect 子流程(部分)
# 输入参数:关键词(文本)
# 输出参数:商品列表(二维列表)
# 1. 在搜索框输入关键词
# 拼多多首页搜索框的典型XPath
等待元素出现://input[@class='search-input'],超时5秒
输入文本://input[@class='search-input'],内容={关键词},清空
# 2. 点击搜索按钮
点击元素://button[contains(text(),'搜索')] 或 //div[@class='search-btn']
# 3. 等待搜索结果加载
等待元素出现://div[@data-soc-coupon] 或 //div[@class='goods-container'],超时8秒
固定等待:1秒
注意: 拼多多的商品容器class经常变,目前常见的是 //div[@data-soc-coupon],建议用“捕获元素”重新获取。
四、步骤3:采集当前页商品列表(核心)
采集字段
- 商品标题
- 价格(当前价)
- 已拼件数(销量,含“万”单位)
- 店铺名称
# 在当前页面采集
# 1. 获取所有商品容器
获取相似元素列表://div[@data-soc-coupon] → 存入“商品容器列表”
# 2. 循环每个容器
设置变量:当前页商品列表 = []
循环元素列表:商品容器列表,循环变量=当前容器
Try
# 标题
在当前元素下查找元素:.//a[contains(@class,'title')] → 获取文本 → 存入“标题”
# 价格(通常有“¥”符号)
在当前元素下查找元素:.//span[@class='price'] → 获取文本 → 存入“价格原始”
# 清洗价格:去掉¥和空格
从文本中提取内容:{价格原始},正则"[\d\.]+" → 存入“价格数字”
# 销量(“已拼10万+”或“已拼1234件”)
在当前元素下查找元素:.//div[contains(@class,'sales')] 或 .//span[contains(text(),'已拼')] → 获取文本 → 存入“销量原始”
# 清洗销量(用Python或正则)
# 店铺名
在当前元素下查找元素:.//div[contains(@class,'store')]//a → 获取文本 → 存入“店铺名”
# 拼成一行数据
设置变量:一行 = [标题, 价格数字, 销量原始, 店铺名]
当前页商品列表.append(一行)
Catch
输出日志:"采集单个商品失败:{异常信息}"
# 可选:记录失败行,继续下一个
设置输出参数:当前页商品列表 = {当前页商品列表}
销量清洗(Python代码指令)
销量文本可能是"已拼1.2万件"、"已拼5000件"、"10万+人拼团"。用Python转成数字。
# Python代码指令:清洗销量
# 输入:原始销量文本(如“已拼1.2万件”)
# 输出:销量数字(整数)
import re
def parse_sales(text):
if not text:
return 0
# 提取数字和小数点
match = re.search(r'[\d\.]+', text)
if not match:
return 0
num = float(match.group())
if '万' in text or 'w' in text.lower():
return int(num * 10000)
else:
return int(num)
output_销量数字 = parse_sales(原始销量文本)
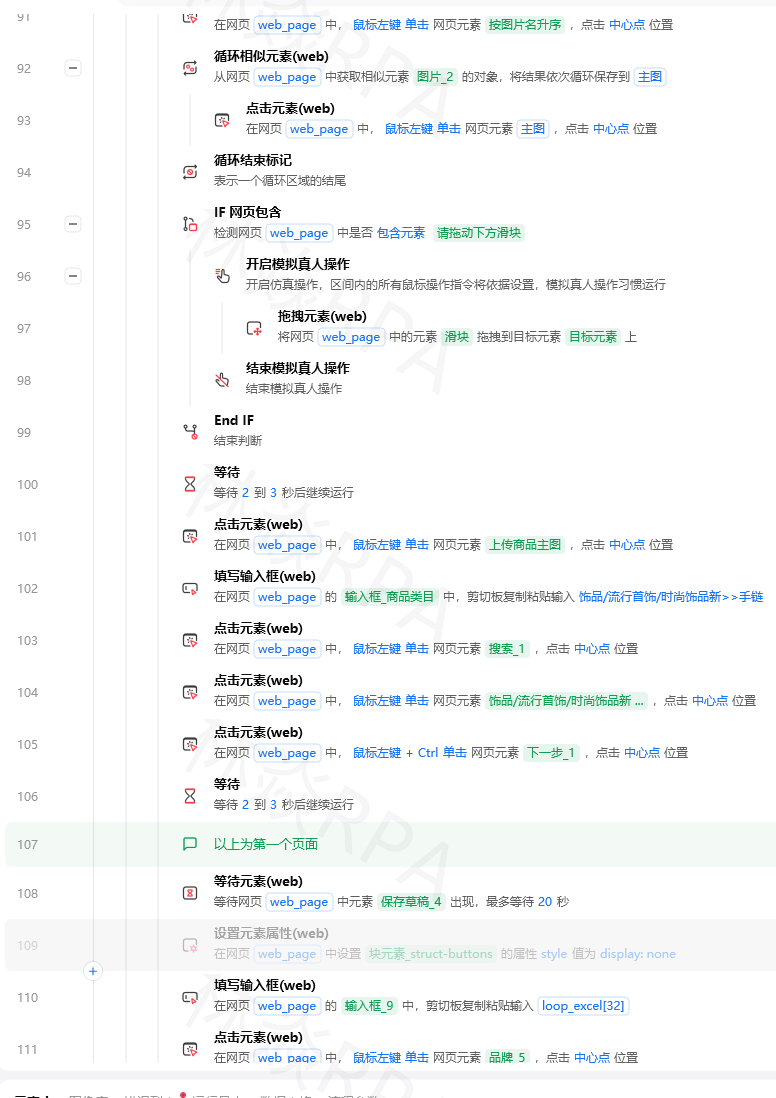
五、步骤4:翻页
拼多多搜索结果的翻页是典型的按钮式分页,有“下一页”按钮,最后一页按钮会变成灰色或消失。
# 在C01_SearchAndCollect中,采集完当前页后,判断翻页
设置变量:还有下一页 = True
设置变量:当前页码 = 1
循环条件:还有下一页 == True
# 采集当前页(调用子流程采集)
调用子流程:C02_CollectCurrentPage → 输出参数:当前页数据
全部数据 = 全部数据 + 当前页数据
# 判断“下一页”按钮是否存在且未禁用
# 拼多多“下一页”按钮通常在底部分页栏
判断元素是否存在://a[contains(text(),'下一页') and not(contains(@class,'disabled'))] → 存入“可翻页”
如果 可翻页 == True
点击元素://a[contains(text(),'下一页')]
# 等待新页面加载(等待商品容器出现)
等待元素出现://div[@data-soc-coupon],超时8秒
当前页码 = 当前页码 + 1
输出日志:"进入第{当前页码}页"
否则
还有下一页 = False
输出日志:"已到最后一页,共{当前页码}页"
# 安全限制,最多翻20页
如果 当前页码 >= 20
还有下一页 = False
输出日志:"达到最大翻页数20,停止"
六、步骤5:导出Excel
# D01_ExportToExcel
Excel Workbook打开
文件路径:"C:\拼多多商品采集.xlsx"
自动创建
存入“工作簿”
# 写入表头
写入行数据到表格:起始"A1",行数据["商品标题","价格","销量(件)","店铺名","采集关键词","采集时间"]
# 循环写入全部数据(全部数据是二维列表)
循环列表:全部数据,循环变量=一行
追加行到表格:行数据={一行} + [关键词, 当前时间]
Excel Workbook保存并关闭
输出日志:"导出完成,共{全部数据的长度}条商品"
七、完整代码示例(精简版)
# ========== A_Main ==========
设置变量:关键词列表 = ["女装", "男鞋", "手机壳"]
设置变量:全部结果 = []
调用子流程:B01_Login
循环列表:关键词列表
调用子流程:C01_SearchAndCollect
输入参数:关键词={当前列表项}
输出参数:商品数据
全部结果 = 全部结果 + 商品数据
调用子流程:D01_ExportToExcel
输入参数:数据列表={全部结果}
# ========== C01_SearchAndCollect ==========
# 输入:关键词
# 输出:商品数据列表
输出日志:"开始采集关键词:{关键词}"
# 搜索
输入文本://input[@class='search-input'],内容={关键词}
点击元素://button[contains(text(),'搜索')]
等待元素出现://div[@data-soc-coupon],超时8秒
设置变量:商品数据列表 = []
设置变量:当前页 = 1
设置变量:还有下一页 = True
循环条件:还有下一页 == True
# 采集当前页容器
获取相似元素列表://div[@data-soc-coupon] → 容器列表
循环元素列表:容器列表
Try
在当前元素下查找元素:.//a[contains(@class,'title')] → 获取文本 → 标题
在当前元素下查找元素:.//span[@class='price'] → 获取文本 → 价格原
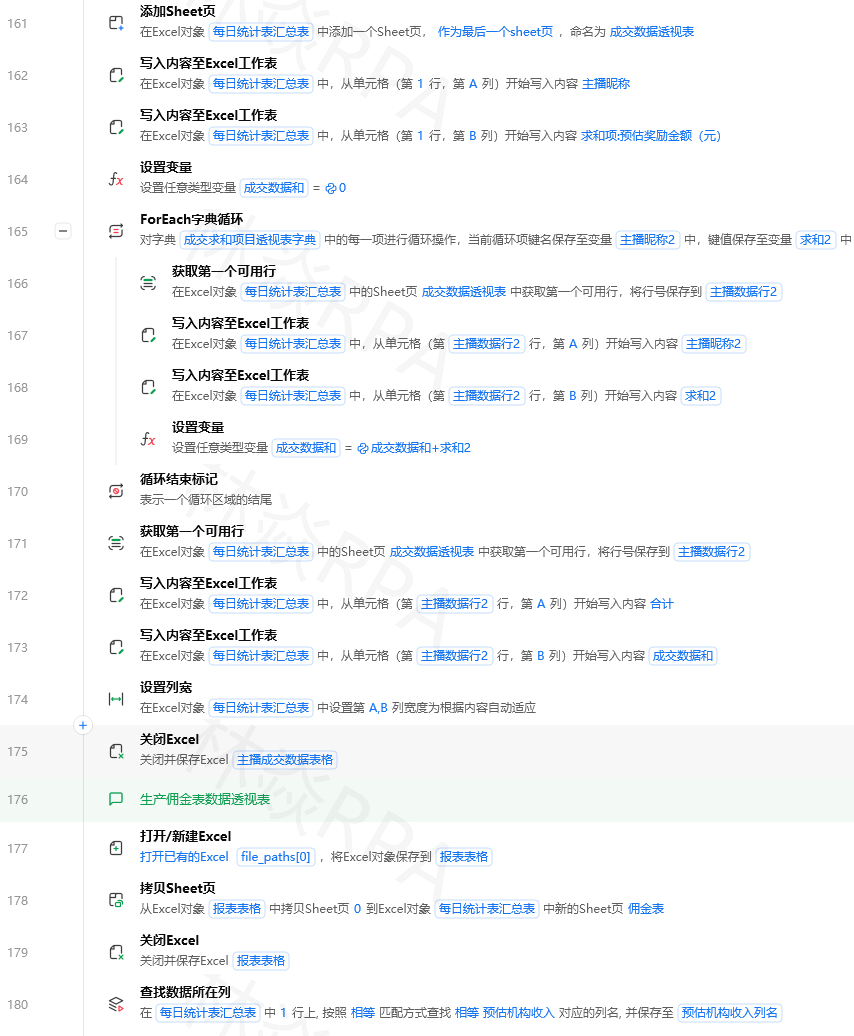
价格 = re.findall(r'[\d\.]+', 价格原)[0] # 用Python代码
# 销量和店铺类似...
商品数据列表.append([标题, 价格, 销量, 店铺])
Catch
输出日志:"采集单条失败"
# 翻页
判断元素是否存在://a[contains(text(),'下一页') and not(contains(@class,'disabled'))] → 可翻页
如果 可翻页 == True
点击元素://a[contains(text(),'下一页')]
等待元素出现://div[@data-soc-coupon],超时8秒
当前页 = 当前页 + 1
否则
还有下一页 = False
设置输出参数:商品数据列表 = {商品数据列表}
八、易错速查表
| 问题 | 原因 | 解决方法 |
|---|---|---|
| 搜索后采集不到商品 | 商品容器XPath失效 | 重新捕获元素,更新XPath |
| 价格取到空 | 价格在子标签里或class有空格 | 用contains(@class,'price') |
| 销量显示“1.2万”无法排序 | 数据带单位 | 用Python正则转换数字 |
| 翻页到底部还点下一页 | 禁用判断不准确 | 检查“下一页”按钮最后一页是否变成span或class='disabled' |
| 拼多多弹出验证码 | 访问频率太高 | 加随机延时2-5秒,降低速度 |
| 社区版时长不够 | 批量采集数据量大 | 减少关键词数量,分批次跑 |
九、优化建议
- 登录态保持:首次运行登录后,下次检查cookie,避免重复登录。
- 价格区间筛选:可以在URL上加参数,如
?price=0-50。 - 多关键词并行:如果创业版,可以用多线程同时跑(谨慎,易风控)。
- 异常重试:在采集循环内加try-catch,单条失败不影响整页。
推荐资源
- 影刀官方帮助中心:搜索“拼多多采集”有现成模板
- 拼多多反爬策略:建议每次操作间隔2-3秒,模拟真人
- 我的经验:拼多多的商品容器用
data-soc-coupon属性定位比较稳定,比class更可靠
作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。