




写XPath时,contains()和text()能解决80%的问题。但剩下的20%,比如要排除某个元素、忽略多余空格、大小写不敏感、截取部分属性,就需要用到高级函数。
这7个函数,每个都能在特定场景下救你一命。
我也是遇到“文本里有换行符匹配不上”、“属性值大小写不一致”这种坑之后,才一个一个学过来的。
一、not() —— 排除法定位
场景:页面上有多个按钮,你要点“提交”,但有一个禁用的“提交”按钮和一个可用的。或者你想排除某个特定class。
语法:not(条件)
代码示例:
# 点击可用的提交按钮(排除disabled的)

//button[contains(text(),'提交') and not(@disabled)]
# 排除包含特定class的元素
//div[contains(@class,'item') and not(contains(@class,'ad'))]

# 排除文本为“查看更多”的链接
//a[not(text()='查看更多')]
# 排除隐藏元素
//span[not(contains(@style,'display:none'))]
实战案例:商品列表里混入了广告卡片,广告卡片的class包含sponsor,你要采集所有非广告商品。
//div[contains(@class,'product-card') and not(contains(@class,'sponsor'))]
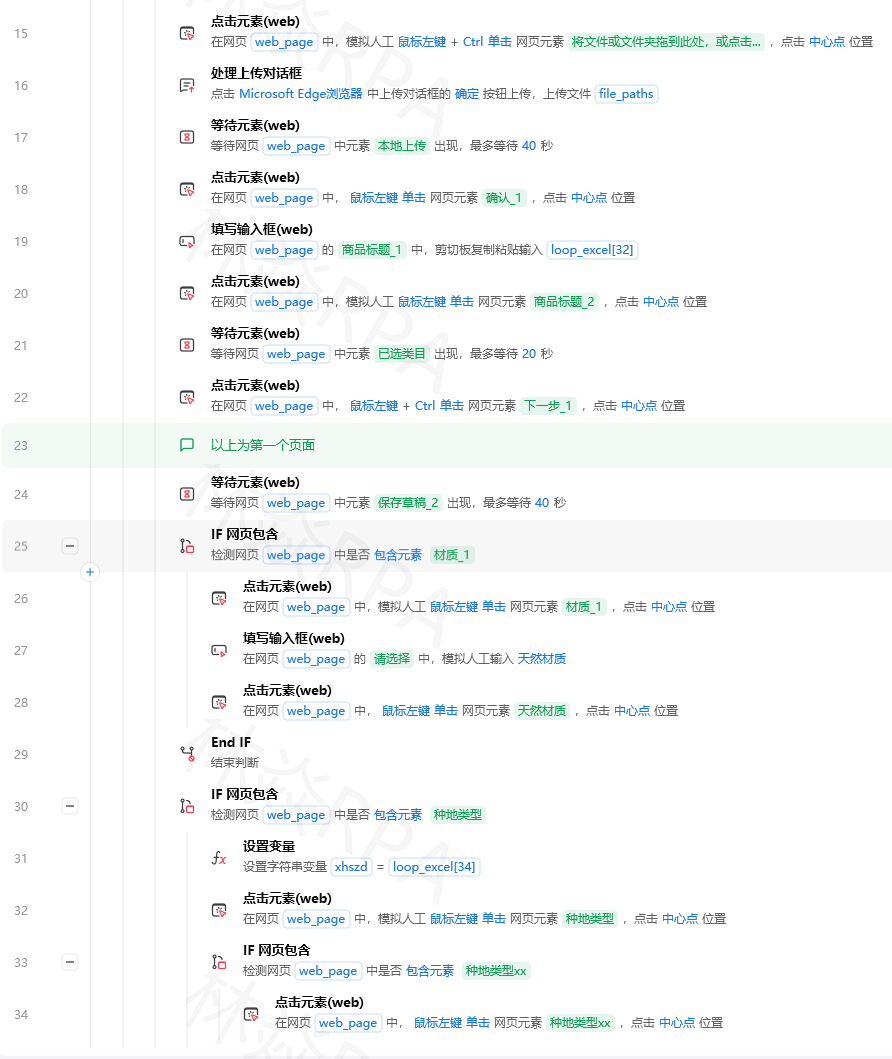
二、normalize-space() —— 去掉首尾空格和中间多余空格
场景:元素的文本是“ 连衣裙 ”或“连衣裙 女装”(多个空格),用text()='连衣裙'匹配不上。
语法:normalize-space(字符串) — 去掉首尾空格,并将中间连续空格压缩成一个空格。
代码示例:
# 匹配忽略首尾空格
//button[normalize-space(text())='提交']
# 匹配中间有多个空格的文本
//span[normalize-space()='连衣裙 女装'] # 实际文本“连衣裙 女装”也能匹配
# 结合contains使用
//div[contains(normalize-space(), '热门推荐')]
注意:normalize-space()不加参数时,默认处理当前节点的文本内容。在影刀XPath引擎中,写成normalize-space(.)更稳妥。
三、translate() —— 大小写不敏感匹配
场景:页面上按钮文本可能是“Login”、“LOGIN”、“login”,你想统一匹配。
语法:translate(字符串, '大写字母', '小写字母') — 将大写转成小写(或反过来)。
代码示例:
# 将文本转为小写后再比较
//button[translate(text(), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz')='login']
# 更简洁的写法(只转换需要的字母)
//button[translate(text(), 'LOGI', 'logi')='login']
封装成可复用的模式(针对英文):
# 忽略大小写匹配“确定”按钮(英文OK)
//button[translate(text(), 'OK', 'ok')='ok']
# 匹配属性值大小写不敏感
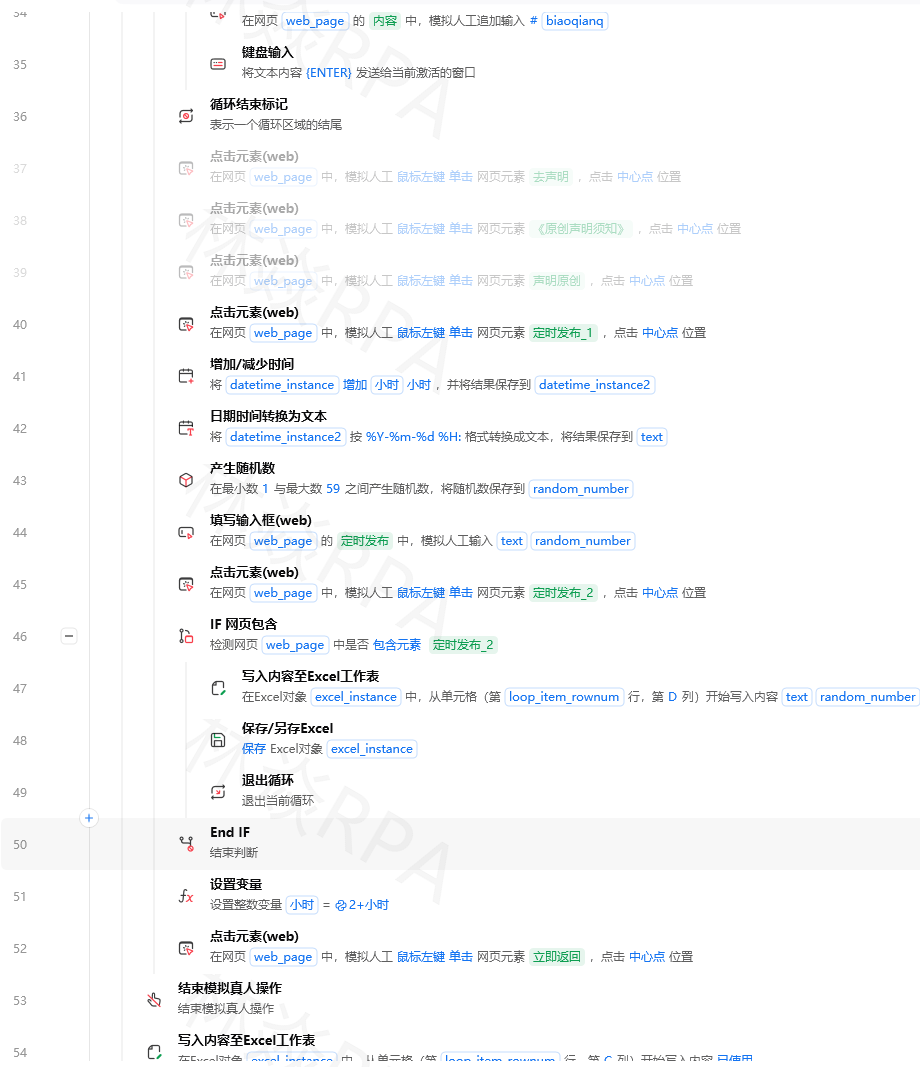
//input[translate(@type, 'TEXT', 'text')='text']
注意:中文没有大小写问题,这个函数主要处理英文和数字。如果你只需要处理少量字符,可以只列出可能出现的字母。
四、substring() —— 截取部分文本或属性
场景:元素的ID是btn_submit_123456,你想匹配btn_submit_开头的,但starts-with某些版本不支持。或者你想取文本的前几个字符。
语法:substring(字符串, 起始位置, 长度) — 位置从1开始。
代码示例:
# 匹配ID的前10个字符
//div[substring(@id, 1, 10)='btn_submit']
# 取文本的后4位(假设文本是“商品编号1234”)
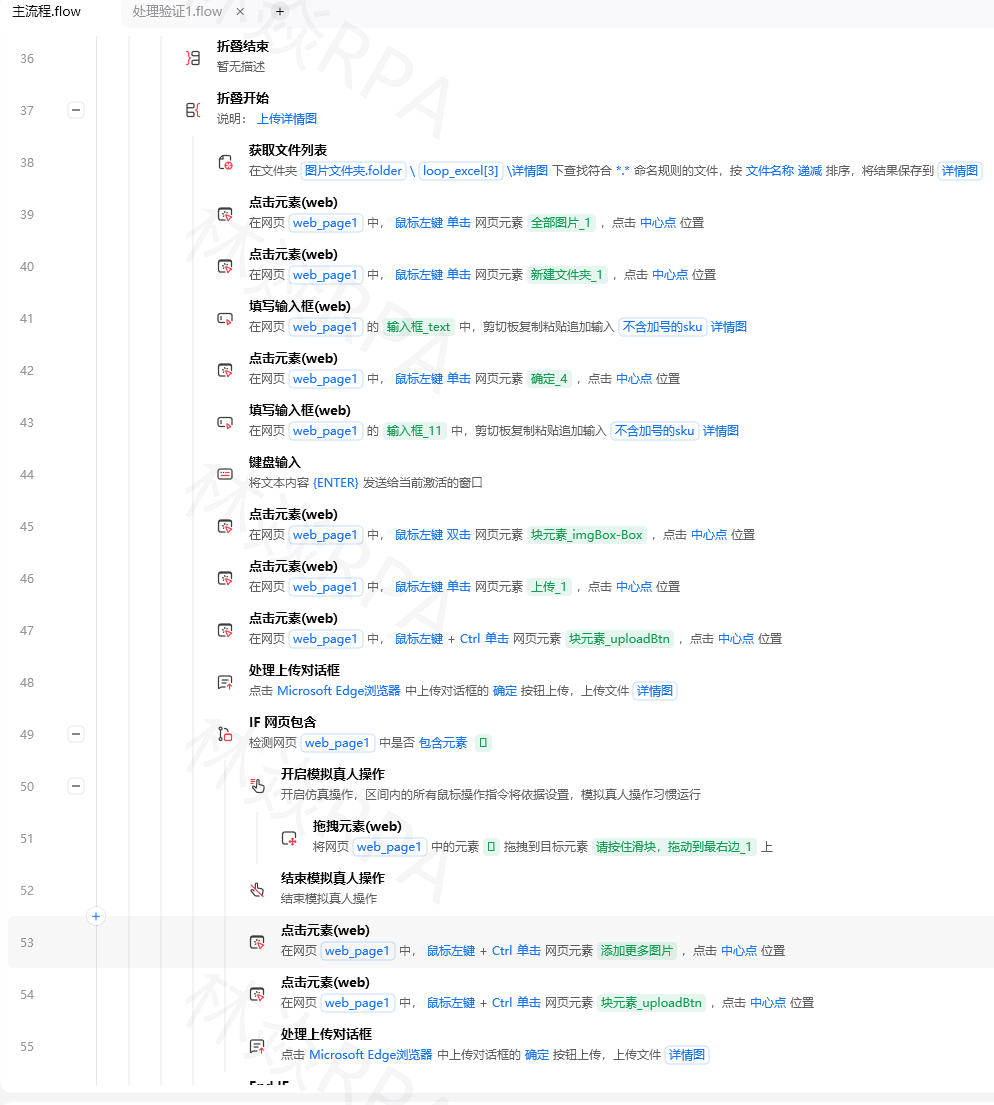
//span[substring(text(), string-length(text())-3)='1234']
# 截取中间部分(从第3位开始取5位)
//span[substring(@data-code, 3, 5)='12345']
实战案例:商品SKU编码格式固定为SKU_ABC_123,你要匹配以SKU_开头且第5-7位是ABC的。
//div[starts-with(@data-sku, 'SKU_') and substring(@data-sku, 5, 3)='ABC']
五、string-length() —— 判断文本长度
场景:你要找评论内容长度大于10个字符的,或者排除空评论。
语法:string-length(字符串)
代码示例:
# 找长度大于0的评论(排除空评论)
//div[contains(@class,'comment') and string-length(text())>0]
# 找长度刚好为11的手机号
//span[string-length(text())=11 and string(number(text()))=text()]
# 排除短标题
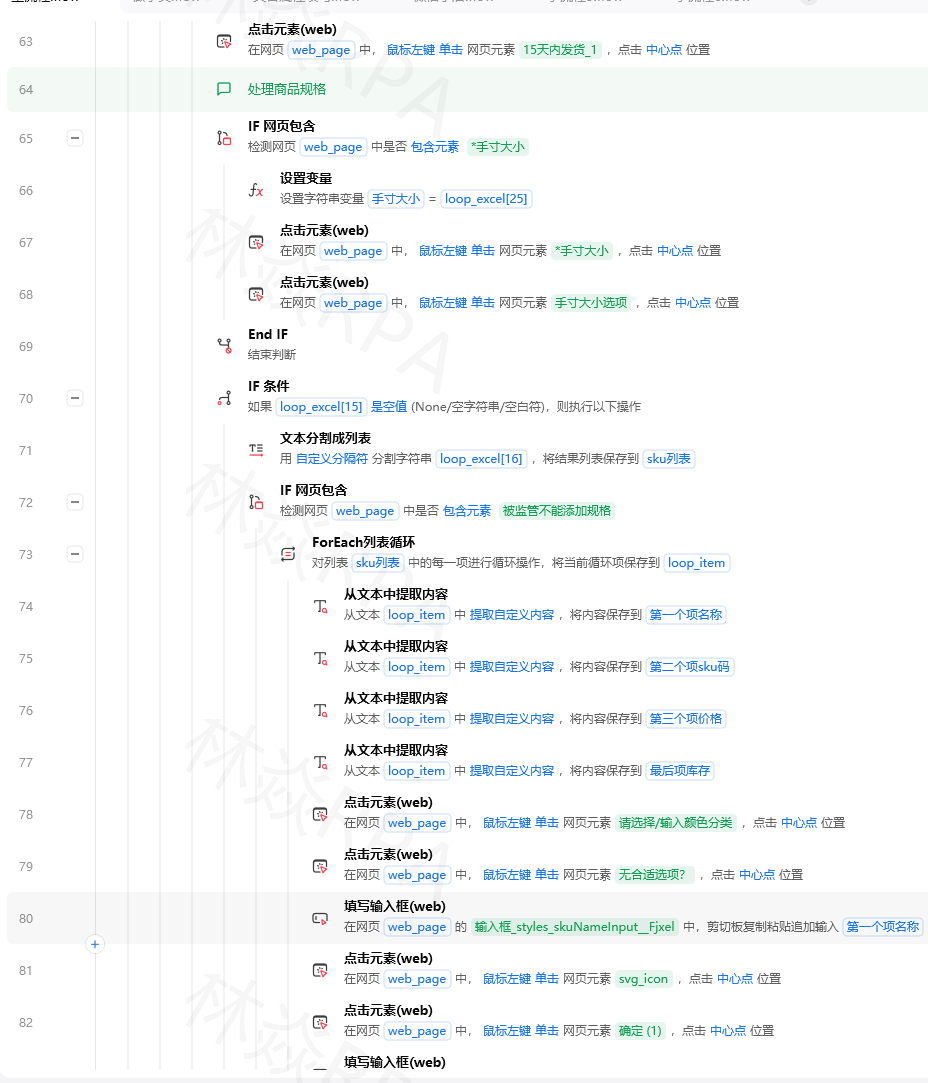
//a[string-length(@title)>5]
六、last() 和 position() —— 动态索引
场景:你要取最后一个商品、倒数第二个、或者前三个中的第二个。
语法:last()表示最后一个的位置,position()表示当前节点在列表中的序号。
代码示例:
# 取最后一个商品卡片
(//div[@class='product-card'])[last()]
# 取倒数第二个按钮
(//button)[last()-1]
# 取前三项中的第二项
(//li)[position()=2 and position()<=3]
# 每隔一项取一个(奇数位置)
//tr[position() mod 2 = 1]
注意:last()和position()必须在方括号内使用,且通常配合()包裹整个路径。
七、count() —— 统计子元素数量
场景:你要找那些有至少3个规格选项的商品,或者找图片数量大于5的图集。
语法:count(节点集)
代码示例:
# 找规格选项数量大于3的商品
//div[contains(@class,'product') and count(.//button[contains(@class,'size')]) > 3]
# 找评论数大于10的帖子
//div[contains(@class,'post') and count(.//div[@class='comment']) > 10]
# 找有图片的商品(至少一张图)
//div[count(.//img) > 0]
八、实战:组合使用高级函数
场景:采集商品列表,要求:
- 排除广告卡片(class不含
ad) - 标题文本去掉首尾空格后长度大于5
- 价格标签转为小写后包含
usd - 取前10个商品中的偶数位置
XPath:
(//div[contains(@class,'product-card') and not(contains(@class,'ad')) and string-length(normalize-space(.//h3))>5 and contains(translate(.//span[@class='price'], 'USD', 'usd'), 'usd')])[position() mod 2 = 0 and position() <= 10]
拆解:
//div[contains(@class,'product-card')— 基础卡片and not(contains(@class,'ad'))— 排除广告and string-length(normalize-space(.//h3))>5— 标题长度and contains(translate(.//span[@class='price'], 'USD', 'usd'), 'usd')— 价格含usd(大小写不敏感)- 外层用
()包起来,加[position() mod 2 = 0 and position() <= 10]— 取前10个中的偶数位置
九、函数支持度速查(影刀环境)
| 函数 | 支持度 | 备注 |
|---|---|---|
not() | ✅ 完全支持 | 常用 |
normalize-space() | ✅ 支持 | 推荐用normalize-space(.) |
translate() | ⚠️ 部分支持 | 简单转换可用,复杂可能失效 |
substring() | ✅ 支持 | 位置从1开始 |
string-length() | ✅ 支持 | - |
last() | ✅ 支持 | - |
position() | ✅ 支持 | - |
count() | ✅ 支持 | - |
matches()(正则) | ❌ 不支持 | 用contains代替 |
常见问题/易错速查
| 问题 | 原因 | 解决方法 |
|---|---|---|
normalize-space()没效果 | 没加参数 | 写成normalize-space(.) |
translate()报错 | 转换字符串太长 | 只转换必要的字母,如translate(., 'US', 'us') |
substring索引从0开始? | 记混了 | XPath索引从1开始,不是0 |
count()返回数字但没法直接比较 | 数值比较用>、< | 直接写count(...) > 3即可 |
| 组合函数后XPath验证超时 | XPath太复杂 | 拆成多步,或用影刀指令代替 |
推荐资源
XPath函数参考:搜索“XPath 1.0 Functions”,W3Schools有完整列表。
影刀测试:在捕获元素界面,用“验证”功能测试复杂XPath,报错会提示具体位置。
最后说一句:
这些高级函数我并不是每次都用,但遇到特殊需求时能救命。建议先把normalize-space()和not()记住,这两个最常用。translate()的大小写转换其实可以用影刀指令做——先获取文本,用Python转小写再比较,比写复杂XPath更直观。优先保证可读性,太长的XPath拆成多步指令也不丢人。
作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。