




快手电商(快手小店)的体量快速增长,采集商品数据用于选品、跟品、价格监控成为刚需。快手网页版(kwaixiaodian.com)相对抖音来说反爬稍弱,但页面加载方式和元素结构有自己的特点。
完整采集方案: 登录快手小店商家版或快手商城 → 搜索关键词 → 滚动/翻页加载商品列表 → 采集标题、价格、销量、店铺名 → 可选采集直播间当前讲解的商品 → 存入Excel。下面给出稳定可用的XPath和流程。
⚠️ 注意:快手小店网页版改版频率一般,建议使用已登录的Cookie,配合随机延迟控制采集频率。
第一步:捕获快手小店关键元素
以快手小店买家版(https://kwaixiaodian.com)或快手APP网页版商品搜索页为例:
# 搜索页 ====================================
# 1. 搜索框
//input[@placeholder='搜索商品' or contains(@class,'search-input')]

# 2. 搜索按钮
//button[contains(@class,'search-btn')]
# 3. 商品卡片容器
//div[contains(@class,'goods-card')] | //div[contains(@class,'product-item')]
# 4. 商品标题(相对于卡片)
.//div[contains(@class,'title')]//a | .//a[contains(@class,'title-link')]
# 5. 商品链接(相对于卡片)
.//a[contains(@class,'title-link')]/@href | .//a[contains(@class,'go-detail')]/@href

# 6. 价格(格式如“¥19.9”)
.//span[contains(@class,'price')]//span | .//div[contains(@class,'current-price')]
# 7. 原价/划线价

.//span[contains(@class,'old-price')] | .//span[contains(@class,'market-price')]
# 8. 销量(格式“已售1.2w”)
.//span[contains(@class,'sold')] | .//div[contains(@class,'sales-volume')]
# 9. 店铺名称
.//a[contains(@class,'shop-name')] | .//span[contains(@class,'store-name')]
# 10. 商品图片
.//img[contains(@class,'img')]/@src
# 详情页 ====================================
# 11. 详情页标题
//h1[contains(@class,'title')] | //div[contains(@class,'product-title')]
# 12. 详情页价格
//div[contains(@class,'price-wrap')]//span[contains(@class,'current')]
# 13. 评价数
//span[contains(@class,'comment-count')] | //div[contains(@class,'rate-count')]
# 14. 商品参数(品牌、发货地等)
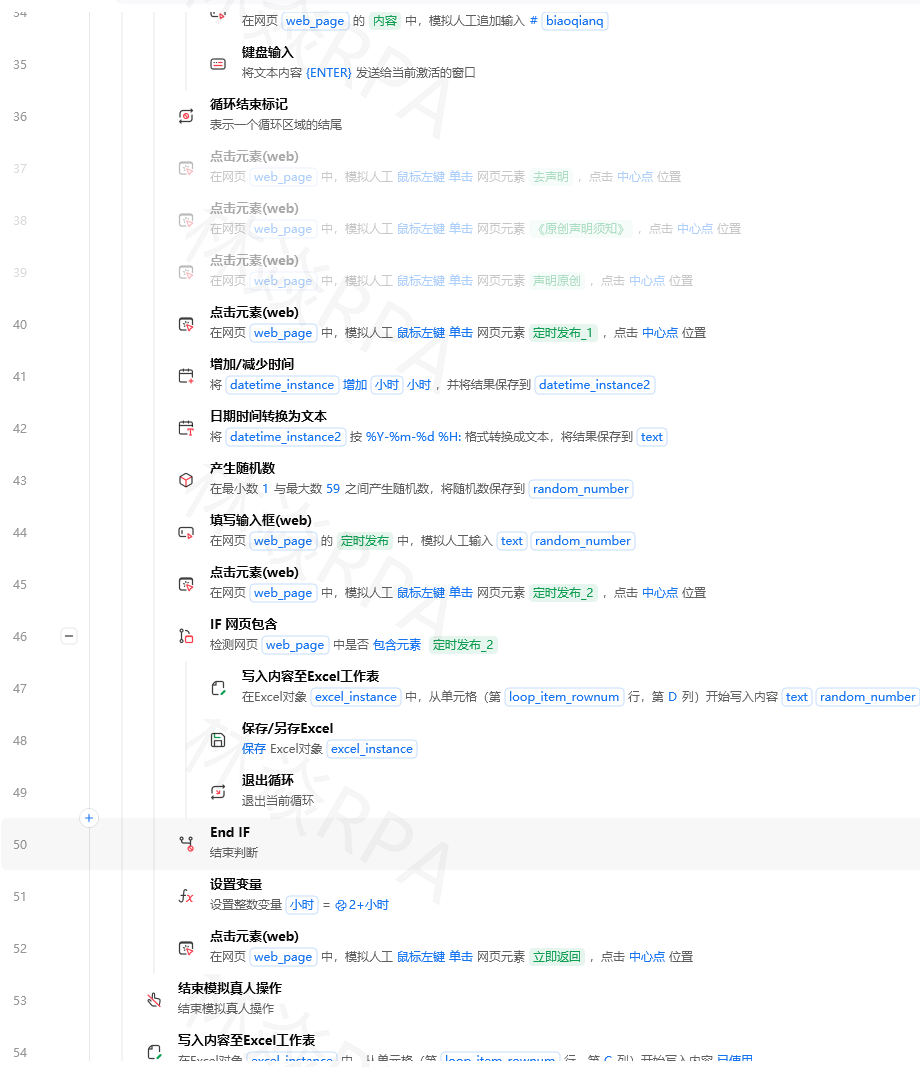
//div[contains(@class,'params')]//li
# 直播间 ====================================

# 15. 直播间商品卡片(正在讲解的商品)
//div[contains(@class,'live-product-card')]

# 16. 直播间商品当前价格
.//span[contains(@class,'live-price')]
⚠️ 注意:快手小店的class名相对稳定,但不同入口(商家版vs买家版)可能有差异。建议先用XPath Helper在目标页面上验证。
第二步:登录与保持会话
快手小店网页版未登录也能搜索商品,但部分商品和价格可能被隐藏。建议用Cookie保持登录。
A_登录快手小店子流程:
流程参数:
- 输出:是否成功
打开网页("https://kwaixiaodian.com")
等待元素出现("搜索框", 超时=10)
# 判断是否已登录(通过是否存在“我的订单”或用户头像)
Try:
判断元素是否存在("//div[contains(@class,'user-avatar')] | //span[contains(text(),'我的订单')]", 超时=2)
如果存在:
输出日志("已登录")
返回 True
Catch:
输出日志("未登录")
# 尝试加载Cookie
${cookie} = 读取文件内容("D:\\kuaishou_cookie.txt")
如果 ${cookie} != "":
清除Cookie()
设置Cookie(${cookie})
刷新网页()
固定等待(2)
判断元素是否存在("//div[contains(@class,'user-avatar')]") → ${已登录}
返回 ${已登录}
首次登录时,手动完成登录后,用“获取Cookie”指令保存到文件。
第三步:搜索商品并滚动加载
快手小店搜索结果页是滚动加载(无限滚动),一次加载20个左右。
C_搜索快手商品子流程:
流程参数:
- 输入:关键词、目标数量(默认100)
- 输出:商品列表(二维数组)
输出日志("【快手搜索】关键词:" + ${关键词})
打开网页("https://kwaixiaodian.com")
等待元素出现("搜索框", 超时=8)
输入文本("搜索框", ${关键词}, 模式="模拟输入")
固定等待(0.5)
点击元素("搜索按钮")
等待元素出现("商品卡片容器", 超时=10)
# 可选:按销量排序(如果有)
Try:
点击元素("//div[contains(@class,'sort')]//span[contains(text(),'销量')]")
固定等待(1)
Catch:
输出日志("未找到销量排序按钮")
# 滚动加载
${所有卡片} = 调用子流程(C_滚动加载快手, 输入=${目标数量})
# 解析卡片
${结果} = 调用子流程(C_解析快手卡片, 输入=${所有卡片})
返回 ${结果}
C_滚动加载快手子流程:
流程参数:
- 输入:目标数量
- 输出:卡片元素列表
${卡片列表} = 创建空列表()
${已采集ID} = 创建空列表()
${上次数量} = 0
${连续无新增} = 0
条件循环(${卡片列表}.长度 < ${目标数量} 且 ${连续无新增} < 3):
获取相似元素列表("商品卡片容器") → ${当前卡片列表}
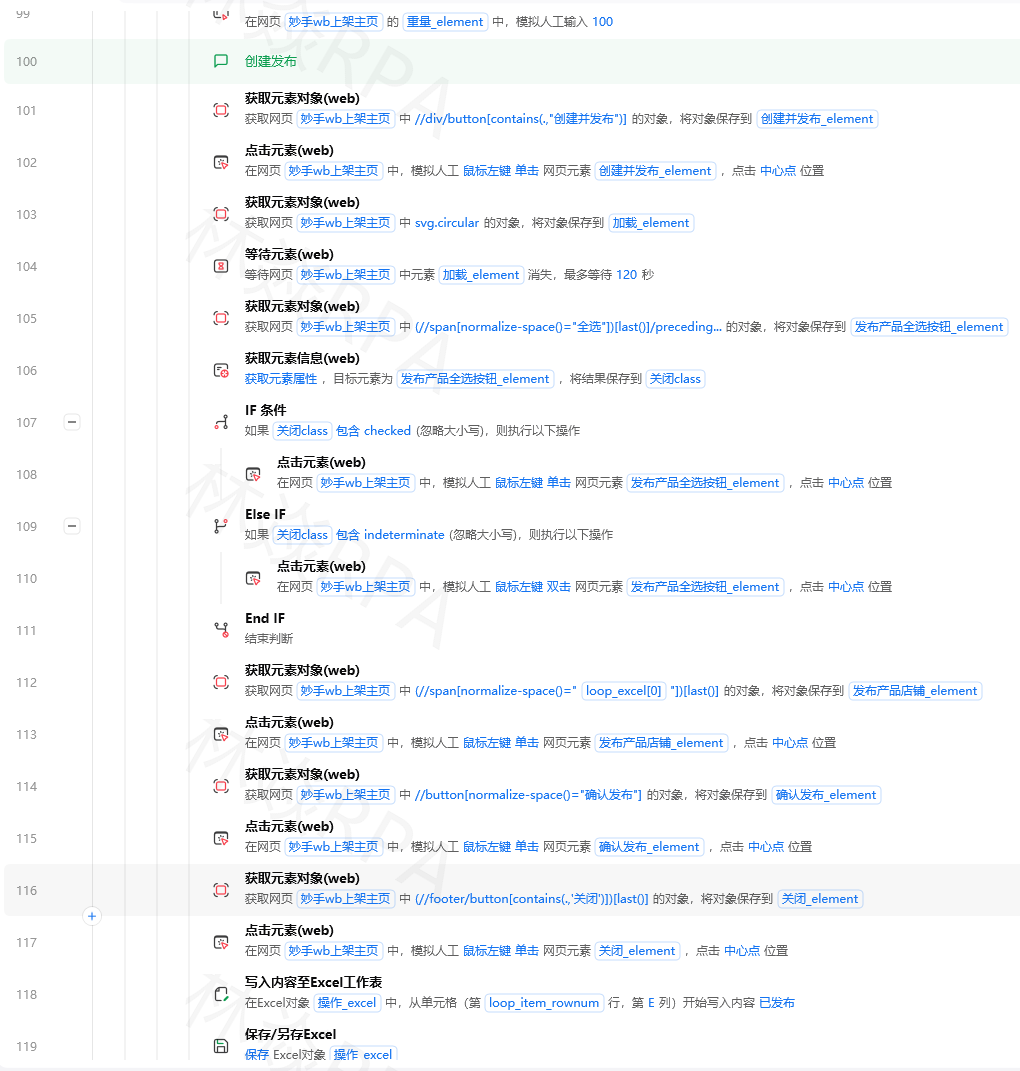
# 合并新卡片,通过商品链接去重
元素列表循环(${当前卡片列表}):
${卡片} = 当前元素
Try:
# 尝试获取商品ID或链接
相对于元素(${卡片}) → 捕获链接元素
${链接} = 获取属性(链接元素, "href")
${商品ID} = 提取正则(${链接}, r'/item/(\d+)')
如果 ${商品ID} != "" 且 ${已采集ID} 不包含 ${商品ID}:
添加元素到列表(${卡片列表}, ${卡片})
添加元素到列表(${已采集ID}, ${商品ID})
Catch:
# 无法获取ID,直接用卡片对象
添加元素到列表(${卡片列表}, ${卡片})
${当前数量} = ${卡片列表}.长度
如果 ${当前数量} > ${上次数量}:
${上次数量} = ${当前数量}
${连续无新增} = 0
否则:
${连续无新增} = ${连续无新增} + 1
# 滚动到底部加载更多
滚动页面(方向=向下, 距离=600)
调用子流程(D_随机等待, 输入=1.2)
返回 ${卡片列表}
C_解析快手卡片子流程:
流程参数:
- 输入:卡片元素列表
- 输出:二维列表 [[标题,价格,销量,店铺,链接], ...]
${结果} = 创建空列表()
元素列表循环(${卡片列表}):
${卡片} = 当前元素
# 标题
Try:
相对于元素(${卡片}) → 捕获标题元素
${标题} = 获取文本(标题元素)
${标题} = 去除首尾空格(${标题})
Catch:
${标题} = ""
# 链接
Try:
相对于元素(${卡片}) → 捕获链接元素
${链接} = 获取属性(链接元素, "href")
如果 字符串包含(${链接}, "//"):
${链接} = "https:" + ${链接}
否则:
${链接} = "https://kwaixiaodian.com" + ${链接}
Catch:
${链接} = ""
# 价格
Try:
相对于元素(${卡片}) → 捕获价格元素
${价格文本} = 获取文本(价格元素)
${价格} = 调用子流程(D_清洗价格, 输入=${价格文本})
Catch:
${价格} = 0
# 销量
Try:
相对于元素(${卡片}) → 捕获销量元素
${销量文本} = 获取文本(销量元素)
${销量} = 调用子流程(D_清洗销量, 输入=${销量文本})
Catch:
${销量} = 0
# 店铺
Try:
相对于元素(${卡片}) → 捕获店铺元素
${店铺} = 获取文本(店铺元素)
Catch:
${店铺} = ""
添加元素到列表(${结果}, [${标题}, ${价格}, ${销量}, ${店铺}, ${链接}])
返回 ${结果}
第四步:采集商品详情页(评价数、参数)
C_快手详情页子流程:
流程参数:
- 输入:商品URL
- 输出:评价数、商品参数(品牌、发货地)
输出日志("进入详情页:" + ${商品URL})
打开网页(${商品URL}, 方式="新建标签页")
等待元素出现("详情页标题", 超时=8)
# 评价数
Try:
获取文本("//span[contains(@class,'comment-count')] | //div[contains(@class,'rate-count')]") → ${评价文本}
${评价数} = 调用子流程(D_提取数字, 输入=${评价文本})
Catch:
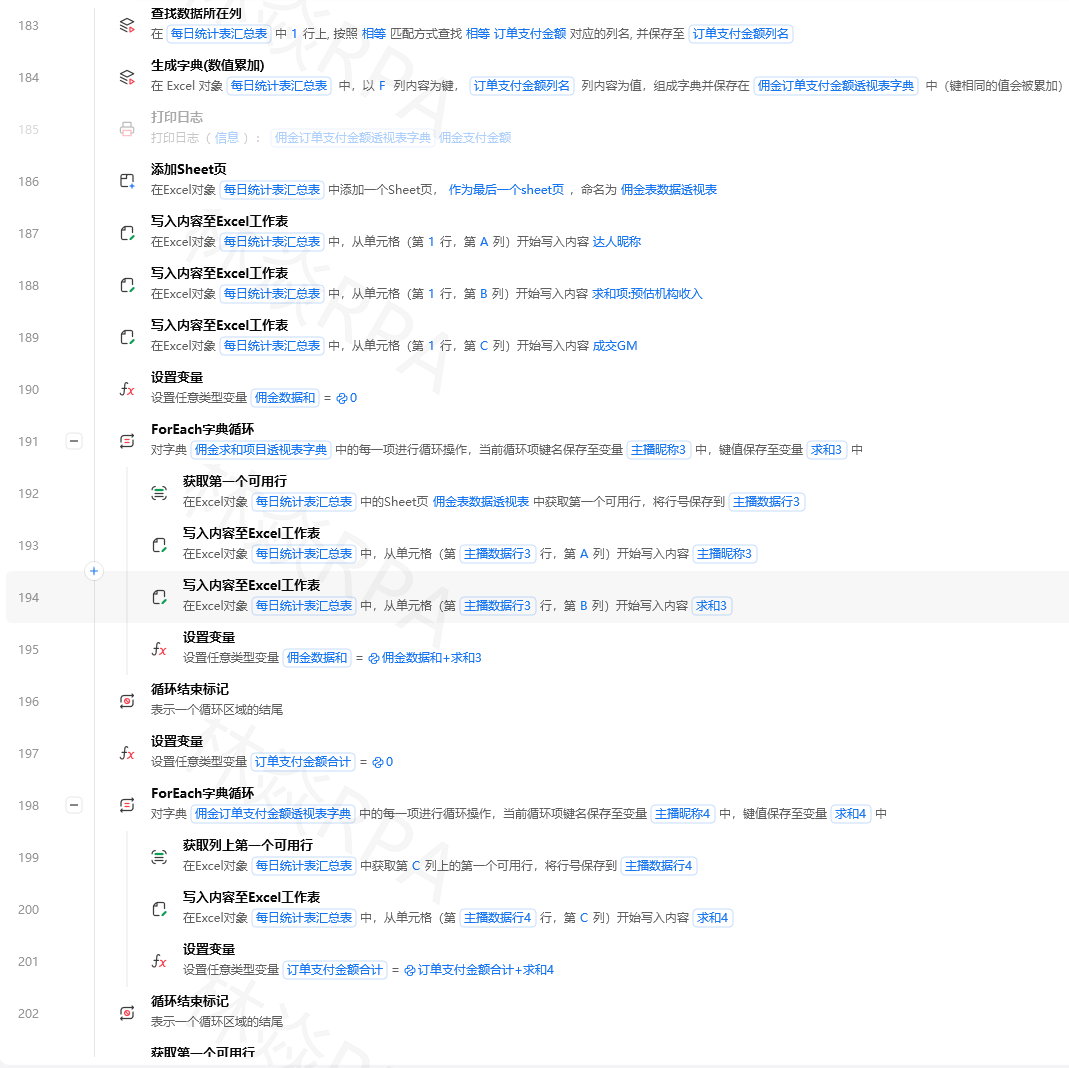
${评价数} = 0
# 商品参数(如“品牌:xxx”,“发货地:xxx”)
Try:
获取文本("//div[contains(@class,'params')]//li[contains(text(),'品牌')]") → ${品牌行}
${品牌} = 分割文本(${品牌行}, ":" )[1] 如果存在
Catch:
${品牌} = ""
关闭标签页()
返回 [${评价数}, ${品牌}]
第五步:采集直播间正在讲解的商品
快手直播间的商品卡片会动态切换,可以通过定时抓取获取当前讲解的商品信息。
C_采集直播间商品子流程:
流程参数:
- 输入:直播间URL、采集时长(秒)
- 输出:商品历史列表
打开网页(${直播间URL}, 方式="新建标签页")
等待元素出现("直播间商品卡片", 超时=10)
${结果} = 创建空列表()
${已采集商品ID} = 创建空列表()
${开始时间} = 获取当前时间戳()
${结束时间} = ${开始时间} + ${采集时长}
条件循环(获取当前时间戳() < ${结束时间}):
# 获取当前正在讲解的商品
Try:
获取文本("直播间商品卡片//div[contains(@class,'title')]") → ${商品标题}
获取文本("直播间商品卡片//span[contains(@class,'price')]") → ${价格文本}
${价格} = 调用子流程(D_清洗价格, 输入=${价格文本})
# 尝试获取商品ID(从链接或属性)
${商品ID} = 调用子流程(C_获取直播间商品ID)
如果 ${商品ID} != "" 且 ${已采集商品ID} 不包含 ${商品ID}:
添加元素到列表(${已采集商品ID}, ${商品ID})
添加元素到列表(${结果}, [获取当前时间(), ${商品标题}, ${价格}])
输出日志("采集到新商品:" + ${商品标题})
Catch:
输出日志("未检测到商品卡片")
# 每5秒采集一次
固定等待(5)
关闭标签页()
返回 ${结果}
⚠️ 注意:直播间商品ID获取可能需要解析页面JS,较复杂。如果只做记录,可以用标题+价格组合去重。
第六步:数据清洗函数
D_清洗价格(Python):
import re
price_str = input_data.get('price', '')
match = re.search(r'[\d.]+', price_str)
if match:
result = float(match.group())
else:
result = 0.0
D_清洗销量(Python):
import re
sales_str = input_data.get('sales', '')
# 支持 "已售1.2w", "1.2万", "1234"
match = re.search(r'(\d+(?:\.\d+)?)\s*[w万]', sales_str)
if match:
result = int(float(match.group(1)) * 10000)
else:
match = re.search(r'(\d+)', sales_str)
result = int(match.group(1)) if match else 0
D_提取数字(Python):
import re
text = input_data.get('text', '')
match = re.search(r'\d+', text)
result = int(match.group()) if match else 0
第七步:完整主流程(批量关键词)
B_快手采集主流程:
# 1. 登录
调用子流程(A_登录快手小店) → ${登录成功}
如果 ${登录成功} == False:
输出日志("登录失败,请手动登录后重试")
停止流程()
# 2. 读取关键词列表
打开Excel("快手关键词.xlsx")
读取列数据到列表(列="A", 起始行=2) → ${关键词列表}
关闭Excel()
# 3. 创建结果文件
打开Excel("快手采集结果_" + 当前日期() + ".xlsx")
追加行到表格(["关键词", "标题", "价格", "销量", "店铺", "链接"])
# 4. 循环采集
列表循环(${关键词列表}):
${关键词} = 当前项
输出日志("处理关键词:" + ${关键词})
调用子流程(C_搜索快手商品, 输入=[${关键词}, 100]) → ${商品列表}
列表循环(${商品列表}):
${一行} = [${关键词}] + 当前项
追加行到表格(${一行})
调用子流程(D_随机等待, 输入=3)
关闭Excel()
输出日志("全部完成")
常见问题速查
| 问题 | 原因 | 解决方法 |
|---|---|---|
| 搜索后没有商品 | 未登录或关键词无结果 | 先登录;换关键词测试 |
| 滚动加载只加载一次 | 页面一次性加载全部 | 快手可能用分页而非无限滚动,改用点击“下一页” |
| 销量总是0 | 销量元素未捕获 | 检查页面,部分商品不显示销量,默认0 |
| 直播间商品采集不到 | 商品卡片动态刷新 | 增加等待时间,用死循环持续检测 |
| 详情页评价数不准 | 只显示“累计评价”文字 | 用正则提取数字,如果没有就0 |
| 触发滑块验证 | 访问频率过高 | 每个关键词间隔5秒以上,使用代理 |
反爬建议
- 使用登录Cookie,降低验证码概率
- 随机等待:每次请求间隔1-3秒
- 单个关键词采集不超过100个商品
- 如需大量采集,使用指纹浏览器+住宅代理
推荐资源
- 快手小店官网:https://kwaixiaodian.com
- 快手电商开放平台:https://open.kwaixiaodian.com(有API,但需申请)
- 影刀社区搜索“快手”,有部分采集模板
我的经验:快手小店的网页采集难度低于抖音,社区版30分钟大约能采集400-600个商品(不进详情页)。直播间商品采集需要实时运行,建议用创业版定时任务单独跑。快手对自动化相对友好,是新手练习电商采集的好平台。
作者:林焱
本文为《影刀RPA学习手册》系列文章之《快手商品数据采集与直播间商品抓取》,内容源于实操经验的整理与分享。