




做电商采集,Excel是个好东西,但一过万行就卡,一过十万行直接崩。我最早做拼多多店群的时候,每天采集50个店铺的订单数据,Excel打开要等半分钟,筛选一下卡5秒,保存一次等10秒——一天光等Excel响应的时间加起来快一个小时。
后来换成SQLite数据库,同样的数据量,查询、筛选、汇总秒出。而且再也不用担心“文件损坏打不开”这种事了。
数据库听起来像是技术人员才用的东西。但其实SQLite就是“Excel的升级版”——不需要装任何东西,影刀里几行Python代码就能跑起来。今天就把数据库操作从零开始讲一遍。
一、什么时候该换数据库
先别急着上手。不是所有场景都需要数据库。下表帮你判断:
| 数据量 | 用什么 | 理由 |
|---|---|---|
| < 5,000行 | Excel | 简单直观,够用 |
| 5,000 ~ 5万行 | Excel(分sheet) | 还能撑 |
| > 5万行 | SQLite | 本地无安装,文件即数据库 |
| > 10万行 或 多人协作 | MySQL | 并发读写、远程访问 |
另一个触发条件:需要做跨表查询(JOIN)、复杂条件筛选时,SQL比在Excel里折腾函数和透视表简洁得多。
我自己的判断标准:如果Excel打开一个文件需要等5秒以上,就该换数据库了。
二、SQLite上手(不需要装任何东西)
SQLite是Python自带的,不需要额外安装任何软件。在影刀的“Python代码”指令里直接跑就行。
连接数据库/创建数据库文件
# 连接SQLite数据库
# 输入:数据库文件路径(如果文件不存在会自动创建)
# 输出:数据库连接对象
import sqlite3
# 创建/连接数据库文件
conn = sqlite3.connect(r"D:\数据\商品库.db")
cursor = conn.cursor()
# 建表
cursor.execute("""
CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
商品名称 TEXT NOT NULL,
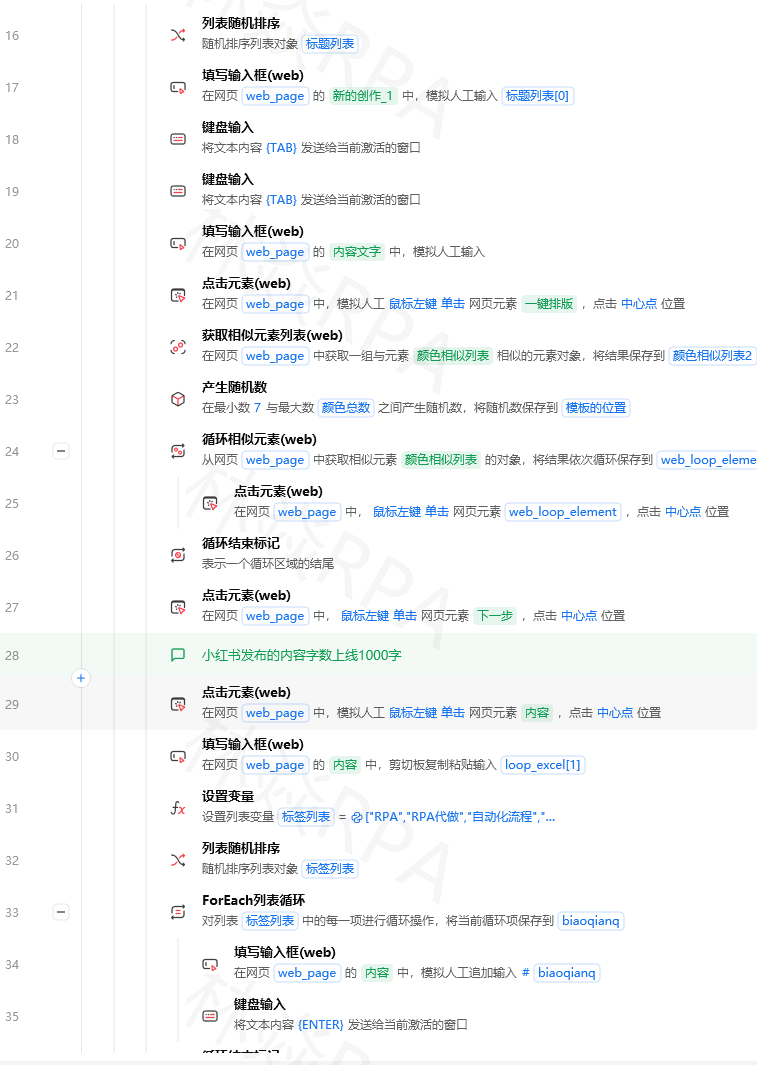
价格 REAL,
销量 INTEGER,
平台 TEXT,
采集时间 TEXT
)
""")
conn.commit()
print("数据库和表已就绪")
一个关键细节:conn = sqlite3.connect(r"D:\数据\商品库.db")这行代码,如果D:\数据\文件夹不存在,会报错。运行之前先确保文件夹已创建。路径里的r表示原始字符串,反斜杠不用写两个。
插入数据
单条插入(不推荐批量用,速度慢):
cursor.execute(
"INSERT INTO products (商品名称, 价格, 销量, 平台, 采集时间) VALUES (?, ?, ?, ?, ?)",

("连衣裙A", 128.0, 5200, "拼多多", "2026-06-29 15:30")
)
conn.commit()
批量插入(推荐) :
# 把采集到的数据批量写入
data = [
("连衣裙A", 128.0, 5200, "拼多多", "2026-06-29"),
("T恤男", 89.0, 3100, "拼多多", "2026-06-29"),
("运动鞋", 299.0, 8900, "拼多多", "2026-06-29"),
]
cursor.executemany(
"INSERT INTO products (商品名称, 价格, 销量, 平台, 采集时间) VALUES (?, ?, ?, ?, ?)",
data
)
conn.commit()
print(f"插入 {len(data)} 条数据")
executemany比循环执行execute快几十倍。采集几千条数据,用executemany一秒写完,用循环可能要几十秒。
从Pandas DataFrame直接写入(高级)
如果你已经在影刀里用Pandas处理过数据,可以直接把DataFrame写入SQLite,一行代码搞定:
import pandas as pd
import sqlite3
# 假设你有一个采集好的DataFrame
df = pd.DataFrame(采集数据)
conn = sqlite3.connect(r"D:\数据\商品库.db")
df.to_sql("products", conn, if_exists="append", index=False)
conn.close()
if_exists="append"表示如果表已存在就追加数据,"replace"表示替换整个表。
三、MySQL连接与ODBC配置
MySQL适合多人协作、数据量大、需要远程访问的场景。连接MySQL比SQLite多一个步骤——安装ODBC驱动。
第一步:确认影刀位数并安装ODBC
- 打开影刀 设置 → 关于影刀,看自己是32位还是64位
- 去MySQL官网下载对应版本的 Connector/ODBC
- 官网地址:
dev.mysql.com/downloads/connector/odbc/ - 32-bit就是32位,64-bit就是64位
- 官网地址:
- 下载后一直下一步安装就行
第二步:配置ODBC数据源
- 打开Windows的ODBC数据源管理器(开始菜单搜“ODBC”)
- 点击 添加,选择 MySQL ODBC XX Unicode Driver
- 填写信息:数据源名称、IP地址、账号、密码、数据库名
- 点击 Test 测试,提示成功即可
第三步:在影刀里连接数据库
影刀有专门的“连接数据库”指令。
- 在右侧指令面板搜索“连接数据库”,拖入流程
- 点击 配置向导
- 32位影刀可以直接下拉选择ODBC里配置好的数据源
- 64位影刀需要点击 提供程序,选择绿色框,再选ODBC上配置好的信息
配置参数说明:
| 参数 | 说明 |
|---|---|
| 数据库地址 | IP形式(127.0.0.1)或域名形式 |
| 账号 | MySQL登录用户名 |
| 密码 | MySQL登录密码 |
| 数据库名 | 要操作的数据库名称 |
配置好后,把返回的“数据库连接对象”存到一个变量里(比如$数据库)——后续所有操作都依赖这个对象。
四、影刀数据库操作指令
影刀内置了数据库操作指令,不需要写SQL。
插入数据(单条)
- 数据库池对象:传入
$数据库 - 表名:填表名
- 数据字典:
{"name": "张三", "age": 25, "job": "运营"}
批量插入数据
- 数据库池对象:传入
$数据库 - 表名:填表名
- 字段列表:
['name', 'age', 'job'] - 数据列表:
[['张三',25,'运营'], ['李四',30,'设计']](必须是二维列表)
查询数据
- 数据库池对象:传入
$数据库 - 表名:填表名
- where条件:不用写WHERE关键字,直接写条件语句,如
name = '测试' - 字段列表:
['name', 'age'],为空则查全部
更新数据
- 数据库池对象:传入
$数据库 - 表名:填表名
- 数据字典:要更新的字段和值
- 主键条件:指定哪条记录
五、实战案例:采集商品数据存入SQLite
把前面所有知识点串起来——采集拼多多商品数据,存入SQLite数据库。
# 1. 采集数据(网页自动化)
打开网页("https://shop.pinduoduo.com")
采集商品列表 → $商品数据列表 # 格式:[["连衣裙",128,5200], ["T恤",89,3100], ...]
# 2. 连接SQLite数据库
Python代码:
import sqlite3
conn = sqlite3.connect(r"D:\数据\商品库.db")
cursor = conn.cursor()
# 建表(如果不存在)
cursor.execute("""
CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY AUTOINCREMENT,
商品名称 TEXT,
价格 REAL,
销量 INTEGER,
采集时间 TEXT
)
""")
conn.commit()
# 批量插入采集到的数据
# 从影刀变量获取数据:$商品数据列表
data = $商品数据列表 # 影刀变量传递到Python
cursor.executemany(
"INSERT INTO products (商品名称, 价格, 销量, 采集时间) VALUES (?, ?, ?, ?)",
data
)
conn.commit()
conn.close()
print(f"成功插入 {len(data)} 条数据")
# 3. 输出日志
输出日志("数据已存入数据库")
数据流转:影刀采集 → 存入变量 → Python读取变量 → 写入SQLite。整个过程不需要中间Excel文件。
六、进阶玩法:影刀魔法指令+SQLite价格监控
影刀有一个“追踪网站商品价格并对比”的魔法指令,零代码实现价格监控:
- 连接数据库:自动连接至SQLite数据库,为存储和对比价格数据做准备
- 确保数据表就绪:智能检查并创建价格记录表(如不存在),确保数据有处可存
- 自动对比:提取商品价格,自动保存到SQLite数据库并与历史价格对比,实时判断是否降价
这个方案支持零代码操作,非常适合不会写SQL的非技术人员。
七、常见SQL语句速查
| 操作 | SQL语句 |
|---|---|
| 查所有 | SELECT * FROM 表名 |
| 条件查 | SELECT * FROM 表名 WHERE 条件 |
| 插入 | INSERT INTO 表名 (字段1,字段2) VALUES (值1,值2) |
| 批量插入 | INSERT INTO 表名 (字段1,字段2) VALUES (?, ?) + executemany |
| 更新 | UPDATE 表名 SET 字段=值 WHERE 条件 |
| 删除 | DELETE FROM 表名 WHERE 条件 |
| 建表 | CREATE TABLE IF NOT EXISTS 表名 (字段定义) |
八、五个容易踩的坑
坑一:路径不存在导致连接失败
现象:sqlite3.connect()报错,说无法创建数据库文件。
解决方法:运行前确保文件夹已创建。或者在Python代码里用os.makedirs()自动创建。
坑二:批量插入的数据格式不对
现象:影刀的“数据库批量插入数据”指令报错,提示需要二维数组。
原因:传入的数据不是二维列表格式。
解决方法:检查数据是否为[['值1','值2'], ['值3','值4']]格式。如果不是,用影刀的“列表转换”指令处理一下。
坑三:插入的列与数据库不匹配
现象:批量插入报错,说列数不对或字段不存在。
解决方法:在“数据库批量插入数据”指令里明确指定字段列表,确保和数据的顺序一致。
坑四:ODBC驱动版本不对
现象:影刀连不上MySQL,配置ODBC时报错。
原因:影刀是32位的但装了64位ODBC,或者反过来。
解决方法:先确认影刀位数(设置→关于影刀),再下载对应版本的ODBC驱动。
坑五:忘记关闭数据库连接
现象:数据库文件被锁定,下次写入失败。
解决方法:在流程的Finally块里加“关闭数据库”指令,确保无论如何都会释放连接。
常见问题速查
| 问题 | 排查方向 |
|---|---|
| SQLite连不上 | 检查文件夹是否存在、路径是否有中文 |
| MySQL连不上 | 检查ODBC驱动版本是否匹配影刀位数 |
| 批量插入失败 | 检查数据是否为二维列表、字段列表是否匹配 |
| 数据库被锁定 | 检查是否有其他流程占用、是否忘记关闭连接 |
| 查询结果为空 | 检查表名是否正确、WHERE条件是否写对 |
推荐资源
- 影刀官方帮助文档搜索“数据库”或“连接数据库”
- 影刀官方帮助文档“数据库批量插入数据”指令说明
- 影刀官方社区“影刀通过odbc连接mysql,32/64位配置详细教程”
- 影刀社区搜索“MySQL”或“SQLite”,有大量实战案例
- MySQL官方ODBC驱动下载:
dev.mysql.com/downloads/connector/odbc/
#影刀RPA #RPA自动化 #数据库操作 #SQLite #MySQL #数据采集
作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。如果这篇文章对你有帮助,欢迎点赞收藏,下一篇我们聊“截图与OCR文字识别的完整方案”。