




Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads
论文原文:Bridging the Archipelago between Row-Stores and Column-Stores for Hybrid Workloads
随着数据量暴增,我们的上层应用对“数据分析”的需求越来越多,现在主要分为两类数据应用:
- OLTP(Online Transaction Processing)
- OLAP(Online Analytical Processing)
而且这两类数据应用的边界非常非常明显,例如
- OLTP中一般有“事务”的概念,且一个事务中多为混合操作(read/write/update/delete),而OLAP中根本没有“事务”的概念,基本上可以认为只有read/scan操作。
- OLTP应用在存储侧的layout一般为行存,OLAP应用则一般为列存
因为OLTP和OLAP的差异,现有的数据分析系统(或者说数据分析的pipeline)一般是部署两套独立的系统。OLTP系统用于执行事务,要求低时延 & 高吞吐,而OLAP系统用来执行历史数据分析(查询),最终出报表,两个系统之间通过后台的数据迁移工具或者MQ来传送数据。
但是以上提到的系统结构显然存在一些问题:
- 系统存在time lag。 OLTP和OLAP系统之间要通过第三方工具传递数据,数据量越大会导致同步的lag越大,限制了系统的能力(例如会要求用户K分钟后才能在刚写入的数据上做查询分析)
- 系统的存储代价较高。 要在OLTP和OLAP的系统各存一份同一内容但不同layout的数据,甚至中间传输的MQ也可能要持久化一份数据
- 管控面的overhead较大。 因为要同时部署 & 维护2个系统(甚至还要维护MQ)
- 使用成本较高。 对于应用开发者来说,如果要做一个混合操作(既要实时插入数据,又要对新老混合的数据做查询),同时跟两个系统交互意味着要学两种query pattern,还要学会怎么整合起来输出最终结果,比较麻烦(当然这个也是可以解决的,可以在执行引擎上层多套一个统一的SQL查询引擎,参考apache calcite)
所以,基于混合分析的需求和现有系统的缺点,更好的做法也许是开发一套混合的系统,同时兼顾OLTP和OLAP,这也就是我们所说的HTAP(Hybrid Transaction-Analytical Processing)。
那么实现一个HTAP系统的主要难点是什么?论文里提到的是:系统要同时执行OLAP任务和OLTP任务,OLAP任务会同时访问即时 & 历史数据,OLTP任务也很可能会update新 & 老数据,一旦OLAP和OLTP任务要访问的数据有读写交叉,要协调两边的任务比较麻烦。现有的HTAP系统的架构一般是实现两个相对独立的子模块,一侧是row-store存储层对接OLTP执行引擎,另一侧是column-store对接OLAP执行引擎,然后再实现一个coordinator(sync method)来协调两侧。笔者认为,这么做无非是把外边的多套子系统称为子模块,取消了原本的后台数据同步机制,整合到一个黑盒里,称为HTAP数据库罢了。这么做的话数据仍然要存两份(row & column),管控面的麻烦从外部转移到内部而已,并没有什么实际的架构创新。
所以,本论文提出了一种新的想法,不再“分而治之”,而是要构建一个统一的存储层,使用统一的data layout来管理表数据,这种layout里的“热数据”会针对OLTP特点优化存储结构,而“冷数据”会针对OLAP特点优化存储结构,然后根据时间推移或者query pattern的变化来自动迁移数据的存储结构。
NSM
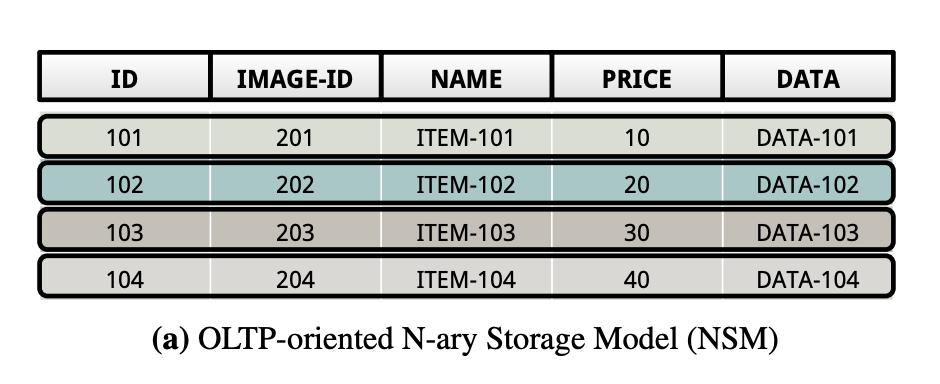
全称N-ary Storage Model,俗称行存,就是将表里面的行连续存放,同一行的数据存到一起,一行接一行。
NSM对write-only的workload比较友好,因为每插入一行,就相当于在一个连续空间的末尾顺序写入所有数据,但是对read-only的workload比较不友好,特别是不需要读所有列的时候,相当于做大量的随机读。
DSM
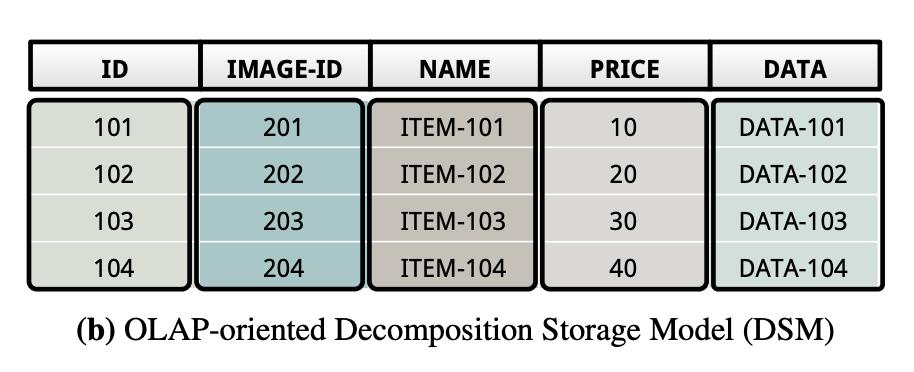
全称Decomposition Storage Model,俗称列存,就是将表里面的一列(一个字段)的数据存到一起,一个文件里存的都是同一列的,有N列就存成N个文件。
DSM对read-only的workload比较友好,无论是读一列还是读多列,因为读一列就是读一整个文件,但是对write-only的workload比较不友好,因为每插入一行,假如该行有N列,相当于要写N个文件,存在IO次数放大。
FSM
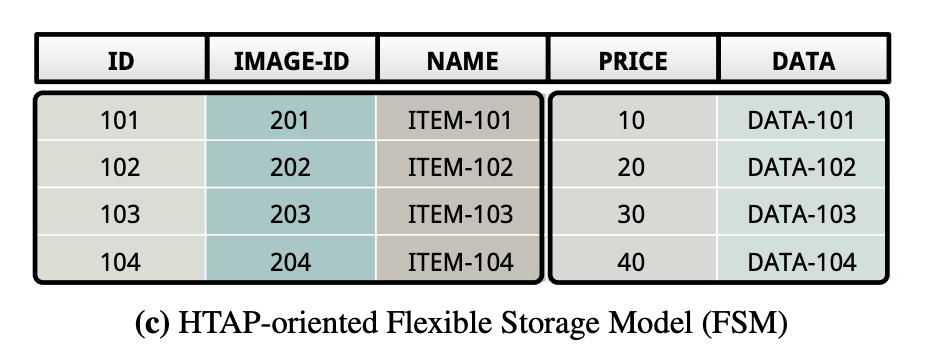
因为NSM和DSM在不同场景各有优劣,所以如果我们要做HTAP系统,就应该汲取它们各自的优点,设计一种比较平衡的layout,即FSM,全称Flexible Storage Model。
Query Pattern
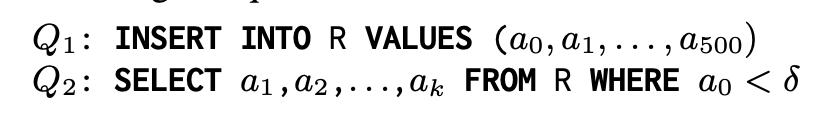
Storage Layout
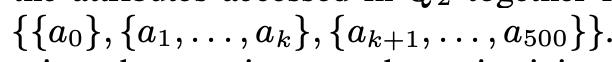
Result
上面提到了FSM,其意义在于汲取行存和列存的优点,那到底FSM的具体结构是怎样的呢?实际上笔者认为,FSM正如它的名字,并没有一个“标准”的实现,更多强调“Flexible” 。接下来我们就看看作者在论文中提出的一种灵活的存储结构——Tile-Based Architecture。
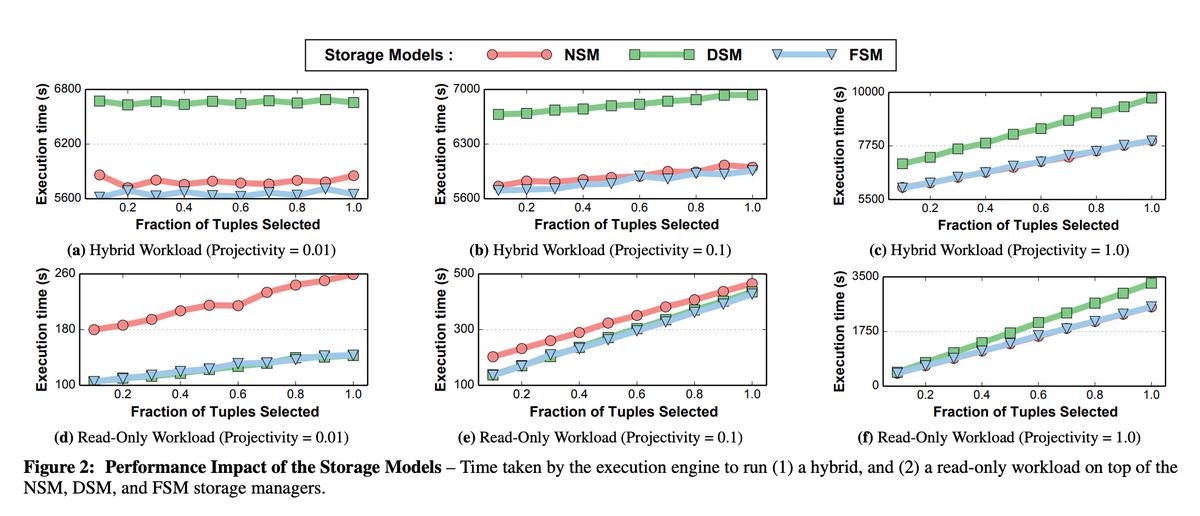
物理层
- 表:一个N行 * M列的二维矩阵
- Tile Tuple:可以理解为一个1行 * B列的向量,其中B <= M
- Tile:可以理解为一个A行 * B列的二维矩阵,其中A <= N,B <= M,一个Tile包含了A个Tile Tuple
- Tile Group:可以理解为多个Tile的集合,Tile Group = {Tile#0, Tile#1, ..., Tile#N}
*NOTE:同一个Tile Group内的所有Tile有着相同的行数,一张表由多个Tile Group组成。
一言以蔽之:先把一张表横向切成多个Tile Group,然后在每个Tile Group内按自定义规则纵向切成多个Tile,每个Tile包含多行Tile Tuple。
逻辑层
如果把底层数据按照上述的物理Tile结构存储,貌似确实能汲取行存和列存的一些优点,但是这对于执行引擎来说会带来更多负担。因为执行引擎得感知存储结构,在制定执行计划时要先知道具体有哪些Tile Group,每个Tile Group内又是怎么划分Tile的,这样就造成了强耦合。
所以应该在执行引擎层和物理存储层之间加一层逻辑存储层,由抽象层来跟执行引擎层做整齐划一的交互。(笔者注,参考Linux内核VFS的思想,各种FS百花齐放,但是接了一层VFS,在抽象层做统一就可以了)
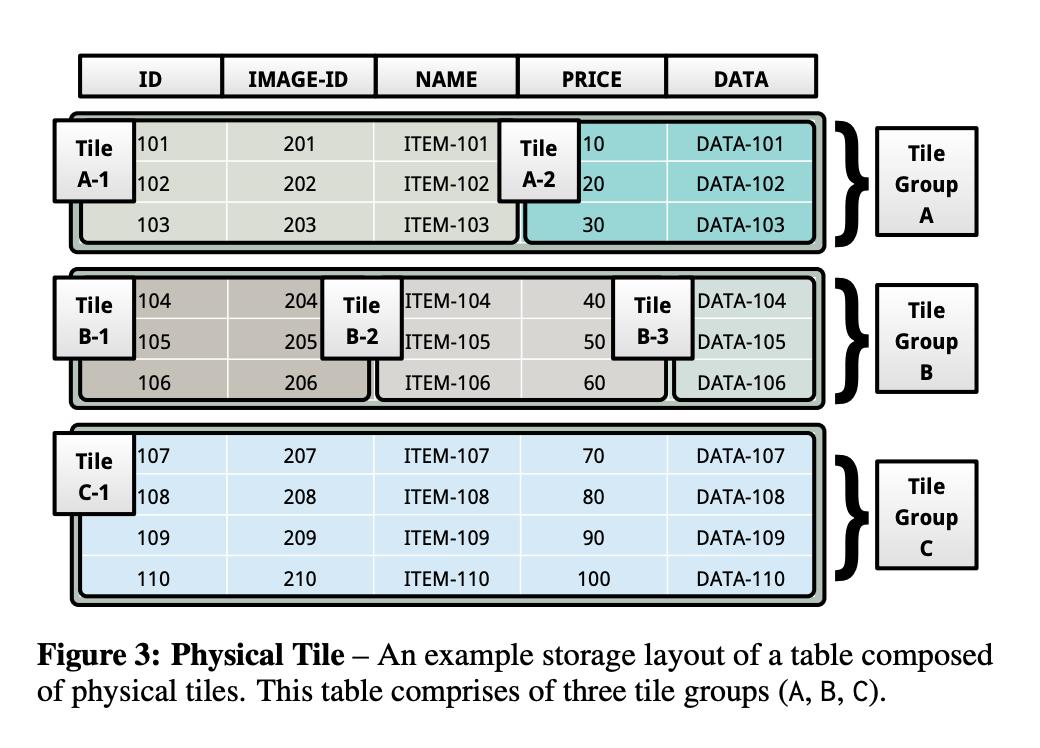
这里的逻辑层指的就是逻辑Tile + 逻辑代数(Logical Tile Algebra) 。首先来看看逻辑Tile的结构:
- 逻辑Tile:可以理解为一张特殊的二维表,共有N行 * M列,每一行是一个逻辑Tuple,每一列是一个指针(offset)列,指向原物理Tile的一列或多列。同时逻辑Tile里还维护了一个bitmap,记录哪些数据是存在的,哪些是不存在的。
- Materialization(物化):把逻辑Tile存储的“指针(offset)”转化为具体数据的操作
*NOTE:
- 一个逻辑Tile对应一个物理的Tile Group
- 逻辑Tile里的不同列可以指向物理Tile里的同一列,如上图逻辑Tile的第二列指向了Tile A-2的第一列,逻辑Tile的第三列也指向了Tile A-2的第一列
- 当逻辑Tile要转化为物理Tile的时候,就生成一个只有1列的逻辑Tile即可,称为passthrough logical tile(passthrough理解为透明转发)
看完了逻辑Tile,来看看与之配套的逻辑代数(Logical Tile Algebra):
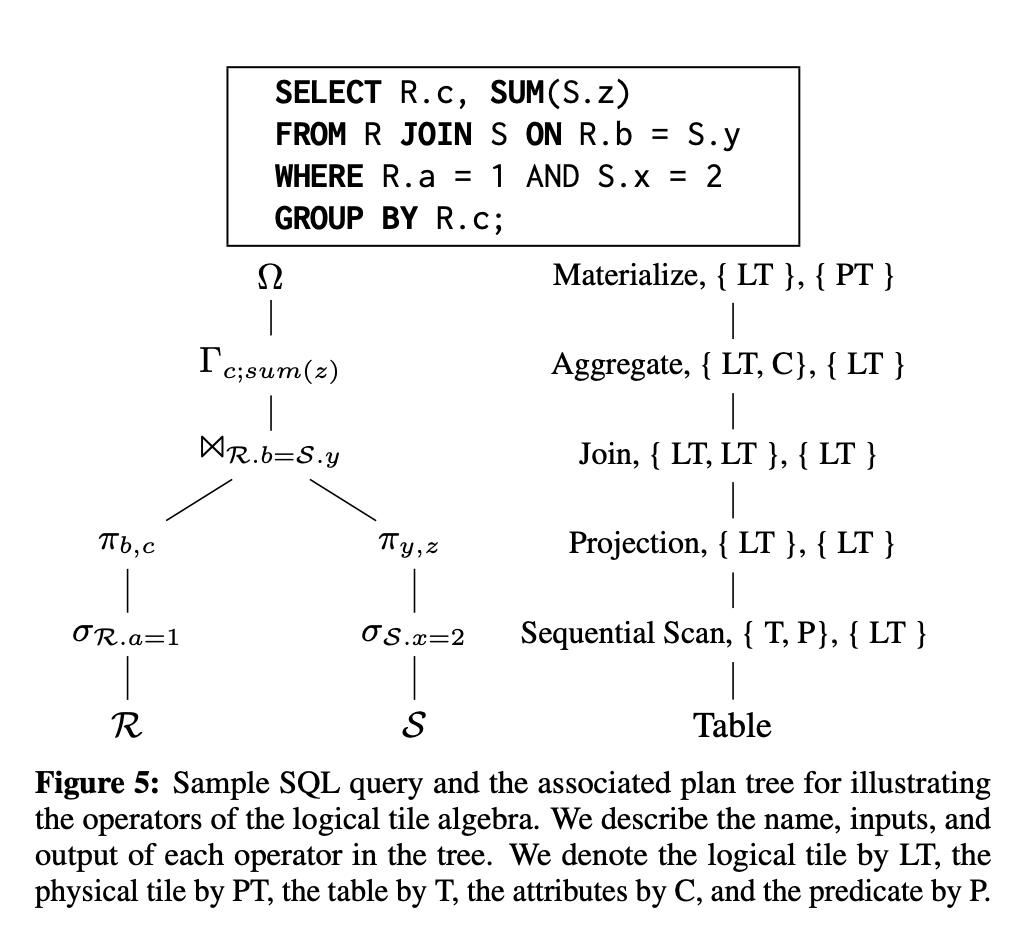
以上述SQL为例,我们可以总结出以下几种逻辑代数的算子:
- Bridge Operator(笔者译:桥接算子):该算子是用来做物理Tile和逻辑Tile的转换的。 如上图最底层的操作,从Table(物理Tile)读出数据转为逻辑Tile;又如上图最顶层的操作,从最终的聚合结果返回给客户端时,要将逻辑Tile转化为物理Tile。
- Metadata Operator(笔者译:元数据算子):该算子是用来修改逻辑Tile里记录的元数据的,对应一些不需要修改物理数据的代数操作。 如上图的projection和selection操作,无非就是筛掉一些不必要的行(R.a = 1和S.x = 2)和不必要的列(R.a和S.x),这样的操作并不需要修改物理数据,只需要在逻辑Tile的bitmap里改一下metadata即可。
- Mutators(笔者译:修改算子):对于insert/delete/update而言,不仅要修改逻辑Tile里的元数据,还必须修改底层物理Tile的实际数据。
- Pipeline Breakers(笔者译:阻塞点):如上图的Join操作,Aggregate操作,还有上图没有的Set,Union等操作,都是要集成多个child node的结果才能继续执行,例如Join就要等待所有子路径执行完毕,然后把各个子路径的逻辑Tile拼到一起,再根据Join条件做筛选,才能得到一个新的逻辑Tile,这样的点就被称为pipeline breakers。
采用Tile-Based结构的好处:
- 由于加入了统一的抽象层——逻辑Tile层,所以底层存储结构的细节对计算层透明,开发比较友好
- 可向量化,原本很多系统采用的是Volcano模型(open-next-close语义,参考Volcano),传统Volcano模型是典型的tuple-at-a-time的处理方式,CPI比较高,且无法做loop pipelining和vectorization。但是Tile-Based结构,就可以以Tile为单位处理,可向量化,提高了处理效率。
- 逻辑Tile和物理Tile的转换非常灵活,甚至只有在一颗AST的最顶层和最底层才需要进行逻辑Tile和物理Tile的转换,中间全程用逻辑指针来运算。
- Tile和Tile Group可以根据业务需求灵活变更,例如一个表切分多少个Tile Group,每个Tile Group里纵向切分多少个Tile等等。
一般我们在支持事务的数据库中提到并发控制,首先会想到MVCC,而提到MVCC后最常见的词无非就是“版本号”、“时间戳”、“历史版本链”、“事务ID”。没错,作者在这篇论文里提出的MVCC机制也跟大多RDBMS类似。
事务元数据
- Last Commited Timestamp,本事务开始时能看到的最后一个commited事务的commited timestamp,意味着当前事务能看到该timestamp前的所有修改
- References to a set of tuple versions,当前事务要记录自己修改过哪些tuple,以及修改时那些tuple的version,用于回滚
Tile元数据
对于每一个Tile Tuple而言要保存:
- Txn ID:哪个事务拿着当前Tuple的锁(正在操作该Tuple)
- BeginCTS:可见性timestamp,从哪个时间戳开始当前Tuple变得全局可见(意味着在该时间戳,insert/update当前Tuple的事务commit了)
- EndCTS:不可见性timestamp,从哪个时间戳开始当前Tuple变得全局不可见(意味着在该时间戳,delete/update当前Tuple的事务commit了)
- Prev:历史版本指针,指向前一个历史版本
MVCC机制简单描述
*NOTE:论文里提到的默认隔离级别是Snapshot Isolation
回忆一下我们上面提到的逻辑代数算子:Bridge Operators、Mutators、Metadata Operators、Pipeline Breakers,其实只有Bridge Operators和Mutators会修改底层的物理Tile,所以只有Bridge Operators和Mutators“在乎”每个Tuple的版本,其余的算子都只会操作逻辑Tile,它们只关心逻辑Tile。
所以下面我们来看看Bridge Operator和Mutators执行时是怎么做MVCC的。
Bridge Operators
上面提过Bridge Operators就是做逻辑Tile和物理Tile的转换的,那么肯定少不了table scan和index scan。在table/index scan过程中,所谓的MVCC就是过滤出Tuple的正确版本,如果事务自身的Last Commited Timestamp介于Tuple的BeginCTS和EndCTS之间,说明该Tuple对当前事务可见,反之不可见。
Mutators
- insert,先在物理Tile里申请一个空行(Empty Tuple Slot),填入自己的Txn ID表示当前事务锁住了该行,待当前事务commit时填入BeginCTS,表示事务完成并且该行变得全局可见。如果要回滚,不会对该行做原地删除,只会把Txn ID置成特殊值,之后由后台gc线程做gc和compaction。
- update,先把原Tuple的EndCTS置为当前timestamp,表示原Tuple从此变为不可见,然后申请一个空行(Empty Tuple Slot),克隆原Tuple到空行,置其Txn ID为当前事务ID(锁行),在克隆Tuple上执行update,将克隆Tuple的Prev置为原Tuple的offset,待事务commit时填入BeginCTS。
- delete,先填入Txn ID(锁行),然后将其EndCTS置为当前timestamp,表示该Tuple从此变为不可见。
*NOTE:以上操作的前提是抢到行锁,且该行对当前事务可见(BeginCTS<= Last Commited Timestamp <= EndCTS)
底层采用Tile-Based结构,并不影响索引的数据结构,仍然可以使用B+树实现clustered index和secondary index,只不过跟MySQL相比,这里的B+树的叶子节点不再存行指针,而是存了行最新版本的“逻辑位置”(笔者注:终究还是要有一个逻辑位置<->物理位置的转换)。为什么不直接存一个行指针?因为会随着时间推移或者业务压力变化,后台会对Tile和Tile Group做reorg,reorg后行位置有变,如果存了行指针的话reorg后又要更新B+树,比较麻烦。
跟MySQL的redo log和checkpoint类似,论文里提到的recovery机制是通过WAL + snapshot来实现的,recovery时先恢复snapshot,然后逐条replay WAL,生成index。但是没有提到snapshot具体怎么生成,所以这一块没啥好说的。
本文提出的data layout叫FSM,Flexibility除了体现在静态属性:行存和列存混合,可自定义Tile和Tile Group外,还体现在其“动态”属性上:可根据时间推移 or query pattern的变化来reorganize data layout。
论文里提出的reorg机制是一种后台机制,通过全局的monitor不断采样以下数据:
- query pattern(取random set,避免热数据偏差)
- SELECT子句和WHERE子句里的列信息(可以把经常一起出现的列reorg到同一个Tile里)
- query optimizer对每个query plan计算出来的cost(因为取query pattern是随机取的,但是HTAP系统要同时兼顾TP和AP,要保证不能一直只取到TP或者AP的query,所以还得从query optimizer处取样)
Reorg算法——KMeans
有了以上数据,要按照什么规则去reorg现有的data layout呢,简单来说就是一种非常朴素的数据挖掘算法——KMeans。对于每一张表T,我们能够采集到近期访问表T的query集合Q,然后给定一个参数K,算法如下:

一言以蔽之,就是对近期访问过表T的query集合作聚类,聚类输出为多个聚簇(cluster),每个聚簇(cluster)会有一个中心点(mean),取其中心点的query包含的列,把这些列reorg到同一个Tile中。
*NOTE:
- 对于每张表T而言,近期的query集合Q怎么取,是不是直接取最近N条即可?不是,要按照上面提到的,兼顾TP和AP,所以要按I/O cost来排序取前N条作为近期query集合。
- KMeans中计算对象是向量,我们怎么将query向量化?很简单,就是把表T的所有列当作一个向量,类似于NLP中常见的bag-of-words模型,然后把query里访问的列对应的位置置为1,其余置0。例如表T = {a, b, c, d, e},向量化得到向量V = {0, 0, 0, 0, 0},某个query为
select a, d from T,那么该query对应的向量为{1, 0, 0, 1, 0}。 - KMeans中怎么计算query向量间的距离?有很多经典距离公式可以用,例如欧式距离、曼哈顿距离等。但这里用的是作者自定义的距离公式,原话是
The distance metric between two queries is defined as the number of attributes which are accessed by one and exactly one of the two queries divided by the number of attributes in T
这里举三个例子:
表T = {a, b, c, d, e}
Query0 = select a, b, c from T = {1, 1, 1, 0, 0}
Query1 = select a, c, e from T = {1, 0, 1, 0, 1}
Distance(Query0, Query1) = (1 + 1) / 5 = 0.4
表T = {a, b, c, d, e}
Query0 = select d, e from T = {0, 0, 0, 1, 1}
Query1 = select d, e from T = {0, 0, 0, 1, 1}
Distance(Query0, Query1) = 0 / 5 = 0(距离最近)
表T = {a, b, c, d, e}
Query0 = select a, b from T = {1, 1, 0, 0, 0}
Query1 = select c, d, e from T = {0, 0, 1, 1, 1}
Distance(Query0, Query1) = 5 / 5 = 1(距离最远)
- KMeans结束后,得到的每个cluster包含什么?包含一堆属于该cluster的点,每个点代表一个归属该cluster的query,还有一个cluster的中心点(mean),也是一个query,实际上就是一个均值向量。
Reorg的简单例子
笔者在这里举个例子(非论文中的例子):
- 表T = {a, b, c, d, e}
- Query集合Q = {Q0, Q1, ... Q9}
- K = 3
KMeans结束得到3个cluster,假设每个cluster的中心向量(mean)如下:
- {0.2, 0, 0.7, 0, 0.9}
- {0, 0.5, 0.8, 0, 0}
- {0.4, 0, 0, 0.9, 0.9}
然后根据以上的向量来reorg,先处理向量一,a = 0.2, c = 0.7,e = 0.9,所以先把a, c, e三列放到同一个物理Tile;然后处理向量二,b = 0.5,c = 0.8,所以把b,c放到一个Tile,但是b已经和a一起了,所以只能把c单独放到一个Tile里;最后处理向量三,a = 0.4,d = 0.9,e = 0.9,只能单独把d放到一个物理Tile里。
(笔者注:在reorg期间,如果有Bridge Operators或者Mutators在飞,要同步阻塞?其他的算子可以不阻塞,因为只是操作逻辑Tile。)
reorg完成后,会生成新的Tile,修改全局metadata,然后后台线程会定期把原来的Tile回收掉。
随着时间的推移,对于每一张表T而言,近期的query集合Q会持续变化,搞不好过了几分钟后会“丢失”之前的一些关键query pattern,那我们就要通过调整参数来让它“丢失”得更慢,即使有新的query pattern进来也尽可能地保留之前的关键query pattern,所以要加入参数w(类似于遗忘率)。
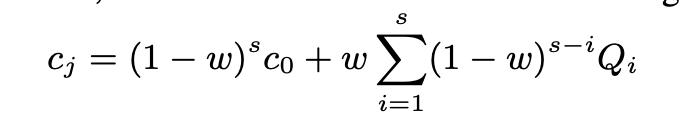
*NOTE:不会对正在频繁处理OLTP请求的Tile做reorg,那样性能损失会很大,而是reorg一些“温”的Tile,将其从NSM(第一次插入表时都存成NSM)往DSM方向转换,适应OLAP请求。
Query Pattern
实验数据
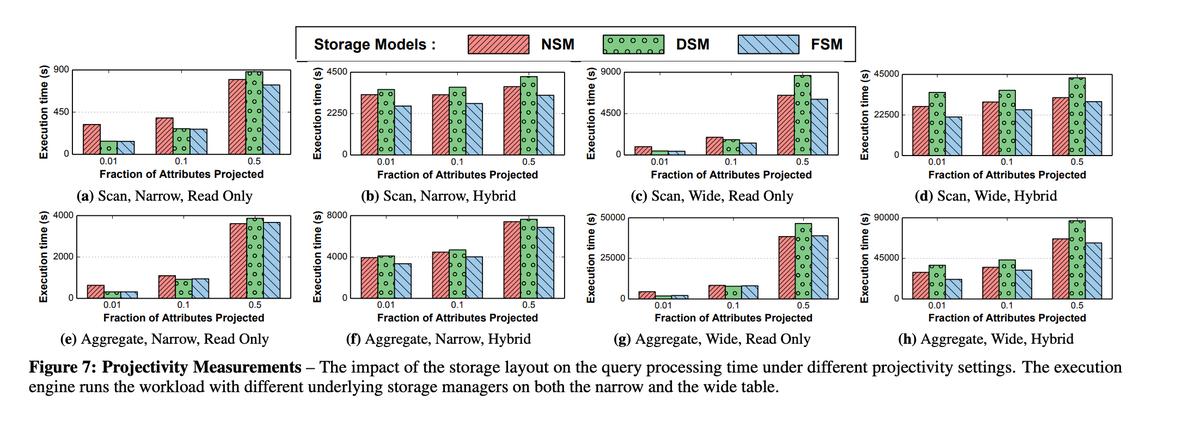
控制projectivity
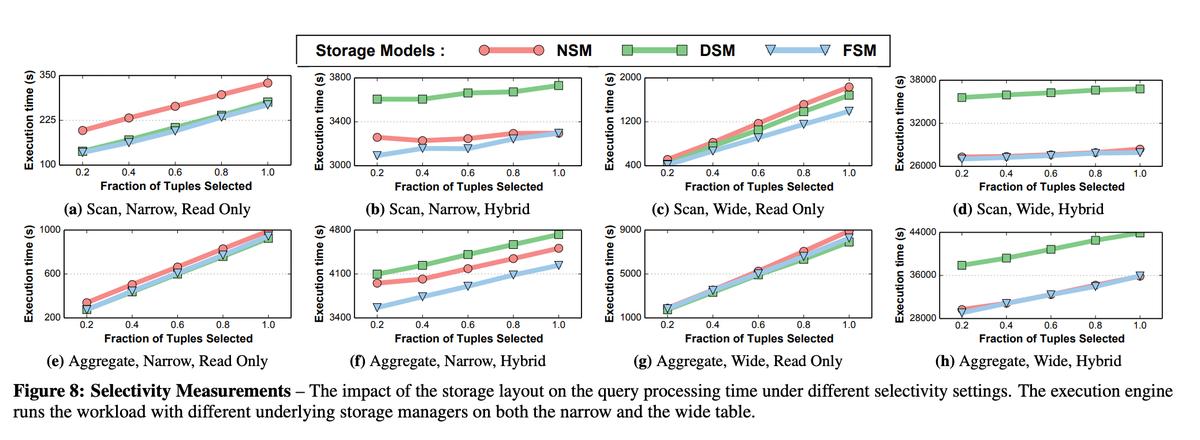
控制selectivity
*NOTE:实验控制的变量如下
- 窄表(50列) & 宽表(500列)
- Read Only Workload & Hybrid Workload
- 控制projectivity分为别1%、10%、50%
- 控制selectivity分别为20%、40%、60%、80%、100%
- 对于FSM来说,先不断插入Tuple,让其自适应reorg后再测benchmark,那样才能看出FSM的真实效果
然而,不是每个现实应用场景都允许你先去预热 + reorg,有可能一启动就要接大流量,所以上述基于reorg后的实验数据还不是很有说服力。之后作者做了另外一个benchmark,是在无预热的情况下,连续分组执行不同query,观察FSM、DSM、NSM的执行时延。具体操作如下:
- 以segment为单位组织query,每个segment包含25条query,每个segment中的query都是同一pattern但是不同参数
- 调整FSM的参数,提高其reorg的频率
- 连续交替执行不同的segment,例如先执行insert segment(25条insert),再执行scan segment(25条scan)、再执行aggregate segment(25条agg),一直交替,观察系统时延

交替执行不同query segment
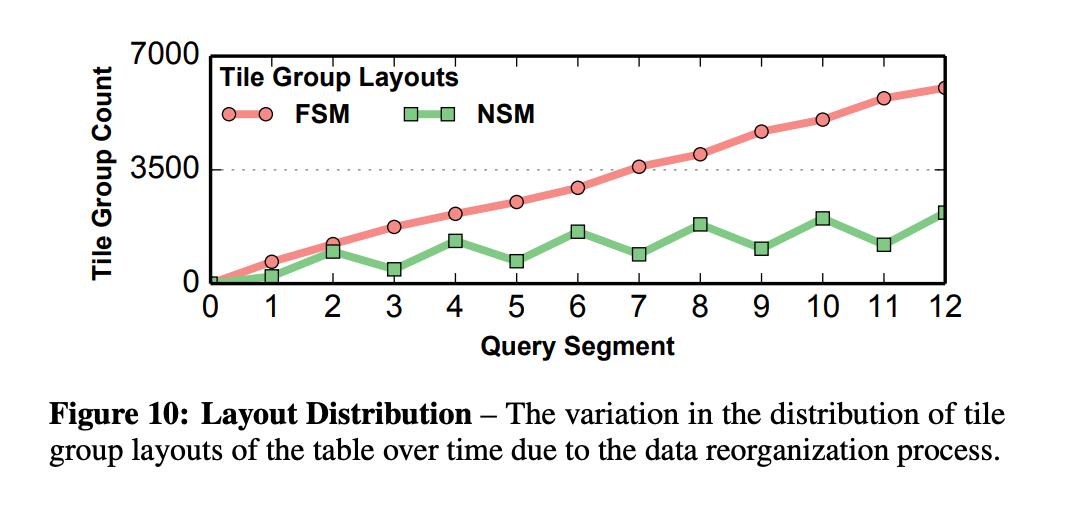
可以看到,随着时间推移,FSM结构的Tile Group越来越多,而NSM结构的Tile Group在每次刚执行完insert segment后会增加,但是之后也会后台被reorg成FSM。
之后,作者还研究了Tile Group的大小对系统性能的影响:
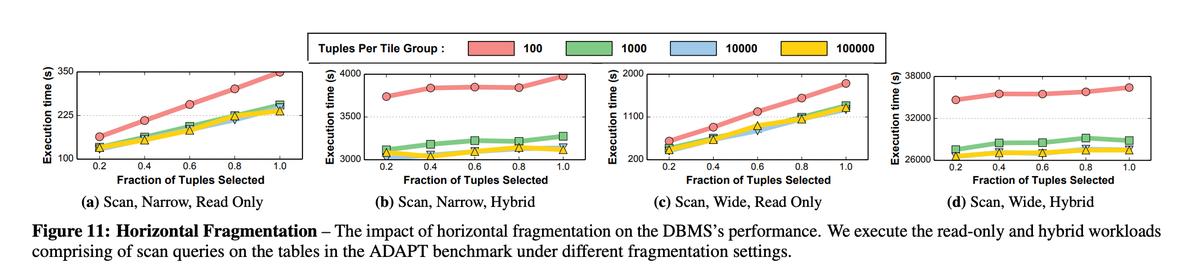
从上图可以看出,跟tuple-at-a-time的Volcano模型相比,当Tile Group的行数越多,性能越好。因为本身以Tile Group为单位就能利用上loop pipelining和vectorized processing,当一个Tile Group内的行数越多,在多核CPU上运行的性能自然也更好。
*NOTE:原论文后面还有一些KMeans相关的benchmark,这里就不赘述了,有兴趣的同学可自行查阅原文。
- FSM布局肯定是有正面作用的。从布局的角度而言,它在某些局部布局成了NSM,另一些局部布局成了DSM,这样就能很好地适应部分NSM/DSM友好的query。仔细一想其实FSM布局很依赖query pattern,如果系统的query pattern相对杂乱,事务时延很容易出现极端毛刺。
- 从CPU的角度来看,FSM布局对于现在的多核环境也更友好,打破了tuple-at-at-time(Volcano模型)的瓶颈,更好地利用CPU能力。
- 不再通过hard-code的经验规则,而是利用KMeans来做Tile Group的reorg,这是一个非常好的思路,特别是基于I/O cost排序 + 随机取样后再做KMeans。笔者转念一想,貌似用分类算法好像也可以,但需要一个query pattern相对稳定的业务场景,先用过去X天的数据构造出一个离线的分类器,然后reorg的时候for each column用分类器判断一下应该reorg到什么Tile Group,好像也可以?
- 本论文不只是纸上谈兵,还有具体的工程代码,他们团队自行实现了一个内存数据库叫Peloton,但是2019/03就被archive了,github链接:Peloton。现在CMU-DB实验室正在筹备一个新的内存数据库,github链接:Terrier,可以保持关注。