




本文是字节跳动数据平台开发套件团队在1月9日Flink Forward Asia 2021: Flink Forward 峰会上的演讲,着重分享了Flink在字节跳动数据流的实践。

文|Richard 字节跳动数据平台开发套件团队高级研发工程师
字节跳动数据流的业务背景
数据流处理的主要是埋点日志。埋点,也叫Event Tracking,是数据和业务之间的桥梁,是数据分析、推荐、运营的基石.
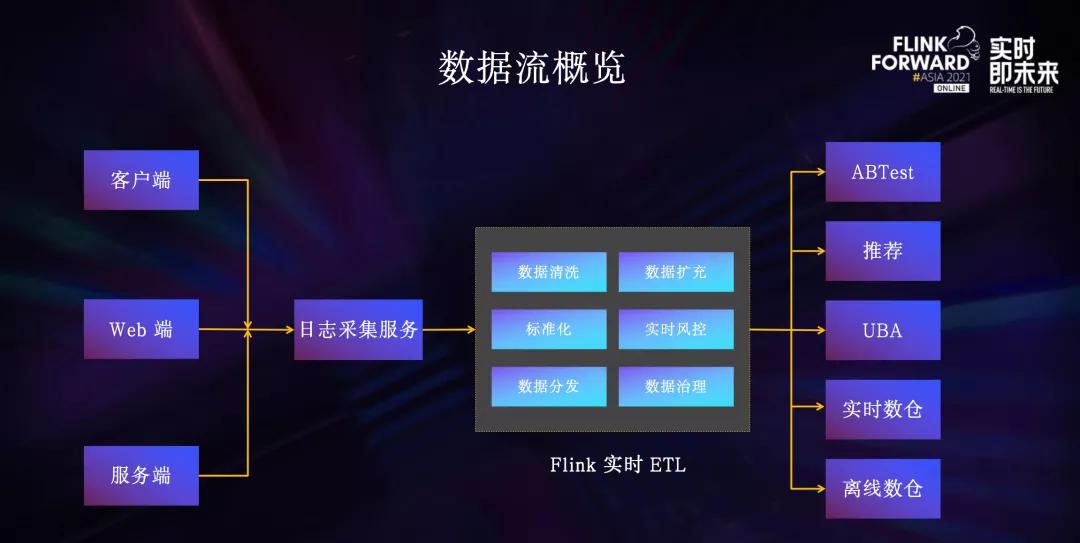
用户在使用App、小程序、Web等各种线上应用时产生的行为,主要通过埋点的形式进行采集上报,按不同的来源分为客户端埋点、Web端埋点、服务端埋点。
不同来源的埋点都通过数据流的日志采集服务接收到MQ,然后经过一系列的Flink实时ETL对埋点进行数据标准化、数据清洗、实时风控反作弊等处理,最终分发到下游,主要的下游包括ABTest、推荐、行为分析系统、实时数仓、离线数仓。
所以,如果用一句话来概括数据流主要业务,其实就是埋点的收集、清洗、分发。
目前在字节跳动,清洗和分发环节是基于Flink搭建的。
01 - 数据流业务规模
- 业务数量: 在 字节跳动,包括抖音、今日头条、西瓜视频、番茄小说在内的3000多个大大小小的APP和服务都接入了数据流。
- 数据流峰值流量: 当前,字节跳动埋点数据流峰值流量超过1亿每秒,每天处理超过万亿量级埋点,PB级数据存储增量。
- ETL任务规模: 目前,字节跳动数据流在多个机房部署超过1000个Flink任务和超过1000个MQ Topic,使用超过50W Core CPU,单任务最大12W**** Core CPU ,Topic最大10000 Partition 。
02 - 数据流业务挑战
字节跳动数据流ETL遇到的挑战主要有四点:
- 第一点,流量大,任务规模大。
- 第二点,处在所有产品数据链路最上游,下游业务多,ETL需求变化频繁。
- 第三点,高SLA要求,下游推荐、实时数仓等业务对稳定性和时效性有比较高的要求。
- 最后一点,在流量大、业务多、SLA要求高的情况下,针对流量、成本、SLA保障等多维度的综合治理也面临挑战。
下面从两个数据流业务场景中介绍一下我们遇到的业务挑战。
1、UserAction ETL场景
在UserAction ETL场景中,我们遇到的核心需求是:种类繁多且流量巨大的客户端埋点需求和ETL规则动态更新的需求。
在字节内部,客户端的埋点种类繁多且流量巨大,而推荐关注的只是部分埋点,因此为了提升下游推荐系统处理效率,会在数据流配置一些ETL规则,对埋点进行过滤,并对字段进行删减、映射、标准化之类的清洗处理,将埋点打上不同的动作类型标识。
处理之后的埋点一般称之为UserAction,UserAction数据会和服务端展现等数据在推荐Joiner任务的分钟级窗口中进行拼接Join,产出Instance训练样本。
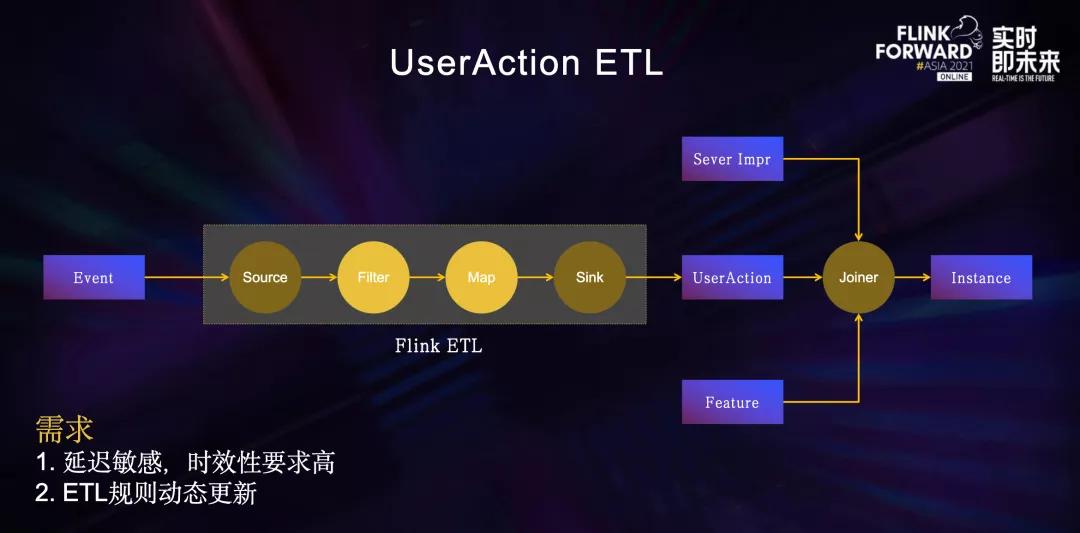
举个例子:一个客户端的文章点赞埋点描述了用户在一个时间点对某一篇文章进行了点赞操作,埋点经过数据流日志采集服务进入数据流ETL链路,通过UserAction ETL处理后实时地进入到推荐Joiner任务中拼接生成样本更新推荐模型,从而提升用户体验。
如果产出UserAction数据的ETL链路出现比较大的延迟,那么就不能在窗口内及时完成拼接,可能导致用户体验下降。
因此对于推荐来说,数据流的时效性是一个强需求。
而推荐模型的迭代、产品埋点的变动都可能导致UserAction的ETL规则的变动。如果ETL规则硬编码在代码中,每次修改都需要升级代码并重启Flink Job,会影响数据流稳定性和数据的时效性。因此,这个场景的另一个需求就是ETL规则的动态更新。
2、数据分流场景
目前,抖音业务的埋点Topic晚高峰流量超过1亿/秒,而下游电商、直播、短视频等不同业务的实时数仓关注的埋点范围实际上都只是其中的一小部分。
如果各业务分别使用一个Flink任务,消费抖音埋点Topic,过滤消费各自关注的埋点,需要消耗大量Yarn资源,同时会造成MQ集群带宽扇出严重,影响MQ集群的稳定性。
因此,数据流提供了数据分流服务,使用一个Flink任务消费上游埋点Topic,然后通过配置规则的方式,将各业务关注的埋点分流到下游小Topic中,再提供给各个业务消费。这样就减少了不必要的反序列化开销,同时降低了MQ集群带宽扇出比例。
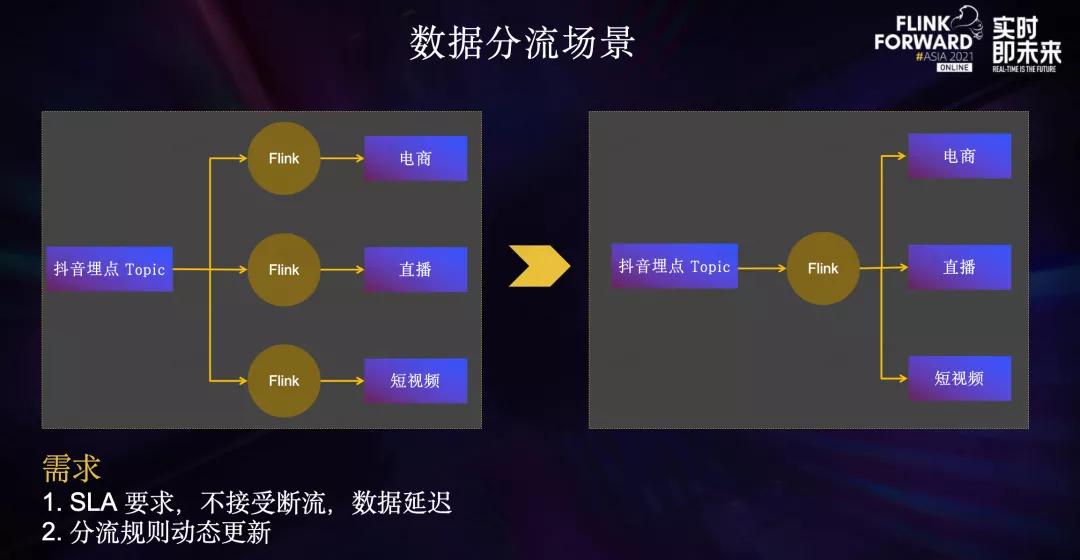
在数据分流场景中,核心需要解决的是高稳定的SLA。因为断流、数据延迟可能会影响推荐效果、广告收入、实时数据报表。
同时随着业务发展,实时数据需求日益增加,分流规则新增和修改也会日益频繁。如果每次规则变动都需要修改代码并重启Flink Job,会影响很多下游,因此分流规则的动态更新也是这一场景中的强需求。
字节跳动数据流实践
01 - 数据流ETL链路建设
字节跳动数据流ETL链路建设主要经历了三个阶段:

- 第一阶段是2018年以前——业务需求快速迭代的早期阶段
主要使用PyJStorm和基于Python的规则引擎构建主要的流式数据处理链路。其特点是比较灵活,可以快速支持业务需求。
但随着埋点流量快速上涨,PyJStorm暴露出很多稳定性和运维上的问题,性能也不足以支撑业务的增长。
2018年,公司内部开始大力推广Flink,并且针对大量旧任务使用PyJStorm的情况,提供了PyJStorm到PyFlink的兼容适配。 流式任务托管平台的建设一定程度上解决了流式任务运维管理的问题。数据流ETL链路也在2018年全面迁移到了PyFlink,进入了流式计算的新时代。
- 第二个阶段是2018至2020年
随着流量的进一步上涨,PyFlink和Kafka的性能瓶颈、以及JSON数据格式带来的性能和数据质量问题都一一显现出来,与此同时下游业务对延迟、数据质量的敏感程度却是与日俱增。
于是,我们一方面对一些痛点进行了针对性的优化。另一方面,花费1年多的时间将整个ETL链路从PyFlink切换到了Java Flink,使用基于Groovy的规则引擎替换了基于Python的规则引擎,使用ProtoBuf替换了JSON。
数据流ETL新链路,相比旧链路性能提升了1倍。
与此同时,一站式大数据开发平台和流量平台的建设提升了数据流在任务开发运维、ETL规则管理、埋点元数据管理、多机房容灾降级等多方面的能力。
- 第三个阶段是从2021年开始
在全球资源供应紧张的背景下,进一步提升数据流ETL性能和稳定性,满足流量增长和需求增长的同时,降低资源成本和运维成本,是这一阶段的主要目标。我们主要从三个方面进行了优化:
- 优化引擎性能。随着流量和ETL规则的不断增加,基于Groovy的规则引擎使用的资源也不断增加,于是我们基于Janino进行了重构,引擎性能得到数倍提升。
- 优化埋点治理体系。我们基于流量平台建设了一套比较完善的埋点治理体系,通过无用埋点下线、埋点采样等手段降低埋点成本。
- 优化链路。我们进行了链路分级,不同等级的链路保障不同的SLA,在资源不足的情况下优先保障高优埋点链路。
从2018年到2020年,我们持续在数据流Flink ETL Job应对需求挑战上取得了一些实践效果。
下图展示了数据流Flink ETL Job是如何支持动态更新的,在不重启任务的情况下,实时更新上下游Schema、规则处理逻辑、修改路由拓扑。
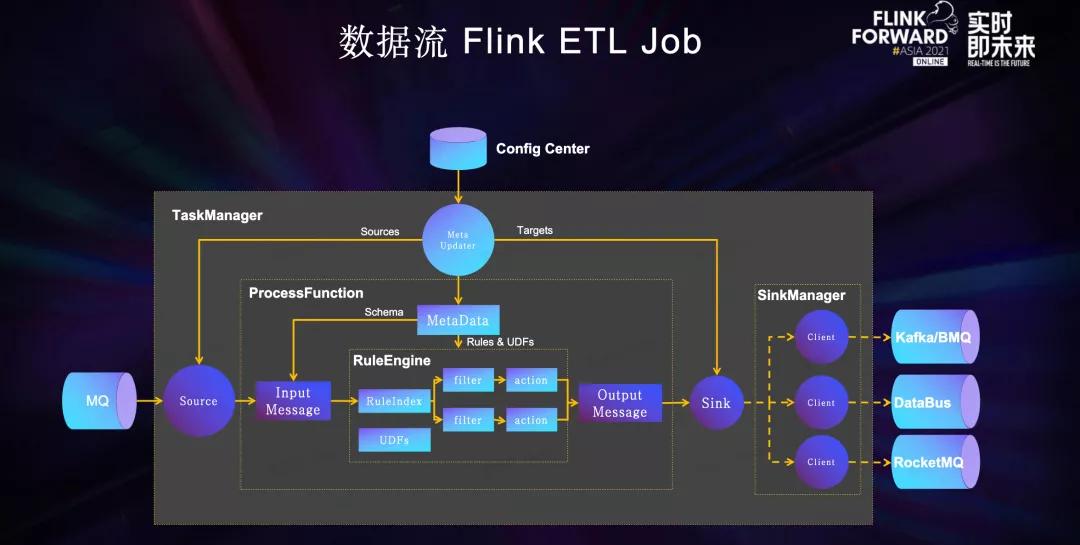
流量平台Config Center为数据流Flink ETL Job提供上下游数据集拓扑关系、Schema、ETL规则和UDF等元数据。
数据流Flink ETL Job中的每个TaskManager中会有一个Meta Updater更新线程,更新线程每分钟通过RPC请求从流量平台拉取并更新相关元数据。
Source将从MQ中消费到的数据传入ProcessFunction,根据MQ对应的Schema反序列化为InputMessage,然后进入规则引擎中,通过规则索引匹配出需要运行的规则,每条规则抽象为一个Filter模块和一个action模块,Filter和action都支持UDF ,Filter筛选命中后,通过action模块对输入数据进行字段映射和清洗,然后写出到OutputMessage中。
每条规则也指定了对应的下游数据集,路由信息也会一并写出到OutputMessage。OutputMessage输出到Sink后,Sink根据OutputMessage中的路由信息将数据发送到SinkManager管理的Client,由对应的Client发送到下游MQ。
这里解释一下我们为什么让每个TaskManager通过一个MetaData updater定时去更新元数据,而不是通过增加一条元数据流来更新。这么做的原因主要是因为使用元数据流更新的方式需要开启Checkpoint以保存元数据的状态,而在字节跳动数据流这样的大流量场景下,开启Checkpoint会导致在Failover时产生大量重复数据,下游无法接受。
1、规则引擎的解决方案
数据流Flink ETL Job使用的规则引擎经历了从Python到Groovy再到Janino的迭代。规则引擎对于数据流来说最主要的就是提供动态更新ETL规则的能力。
Python由于脚本语言本身的灵活性,动态加载规则实现起来比较简单,通过Compile函数可以将一段规则代码片段编译成字节代码,再通过eval函数进行调用即可。但存在性能较低,规则缺乏管理的问题。
迁移到Java Flink后,我们在流量平台上统一管理ETL规则、Schema、数据集等元数据。用户在流量平台编辑ETL规则,规则从前端视图发送到后端,经过一系列校验后保存为逻辑规则,引擎将逻辑规则编译为物理规则运行。Groovy本身兼容Java,所以我们可以通过GroovyClassLoader动态的加载规则、UDF。
但使用Groovy,虽然性能比Python提高了很多倍,但额外的开销仍比较大,因此我们又借助Janino可以高效动态编译Java类并加载到JVM直接执行的能力,将Groovy替换为Janino。
除了规则引擎的迭代,我们在平台侧的测试、发布、监控和报警方面也做了很多建设。
测试发布环节支持了规则的线下测试、线上调试、灰度发布等功能,监控环节则是支持字段、规则、任务等不同粒度的异常监控,并支持了规则流量的波动报警、任务的资源报警等功能。
规则引擎的应用解决了数据流ETL链路如何快速响应业务需求的问题,实现了动态调整ETL规则不需要修改代码、重启任务。
但规则引擎本身的迭代、流量增长导致的资源扩容等场景还是需要升级重启Flink任务,引发断流。除了重启断流外,大任务还可能遇到启动慢、队列资源不足或资源碎片导致起不来等问题。

2、Flink拆分任务的实践
针对这些痛点,我们上线了Flink拆分任务。Flink拆分任务本质上就是将一个大任务拆分为一组子任务,每个子任务按比例消费上游Topic一部分Partition,处理后再分别写出到下游Topic。
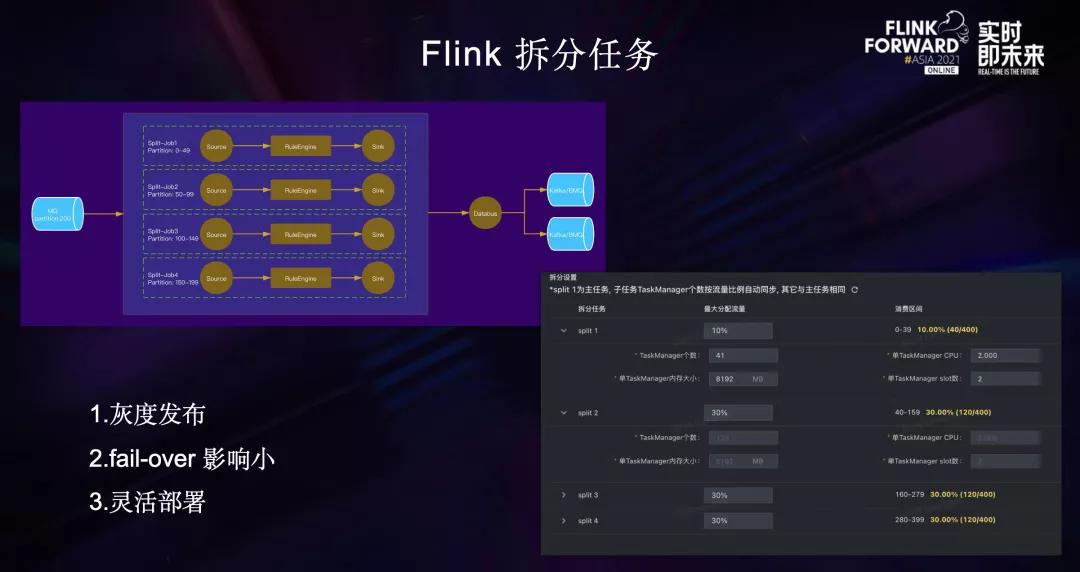
举个例子,上游Topic有200个Partition,我们在大数据研发治理套件DataLeap的数据开发上配置一个Flink拆分任务只需要指定每个子任务的流量比例,其余参数都可以按比例自动同步。
拆分任务的应用使得数据流Flink ETL Job除了规则粒度的灰度发布能力,还具备了Job粒度的灰度发布能力,从此升级、扩容不断流,上线风险更可控。同时,由于拆分任务各子任务是独立的,因此单个子任务出现反压、fail-over不会影响其他子任务,对下游的影响更小。另外一个优点是单个子任务资源使用量更小,子任务可以同时在多个队列灵活部署。
在流量迅速增长的阶段,数据流最开始是通过Kafka Connector直接写Kafka。但是由于数据流Flink ETL Job任务处理的流量大,Sink比较多,批量发送的效率不高,Kafka集群写入请求量很大,另外由于每个Sink一个Client,Client与Kafka集群间建立的连接数很多,而Kafka集群由于Controller性能瓶颈也无法继续扩容。
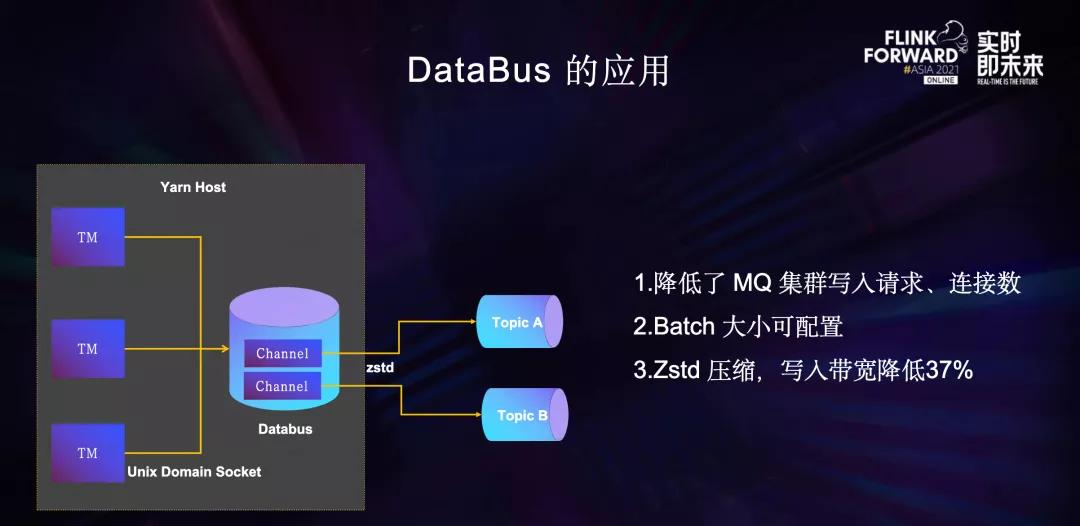
为了缓解Kafka集群压力,数据流Flink ETL Job引入了DataBus组件。
DataBus以Agent的方式 B部署Yarn节点上,Agent中每个Channel对应一个Kafka Topic。数据流FlinkETL Job每个TM中的SinkManager使用Databus Client 通过 Unix Domain Socket的方式将数据发送到Databus Agent 的Channel中,再由Channel将数据批量发送到对应的Kafka Topic。
由于每个Yarn节点上所有的TM都先把数据发送到本机的DataBus Agent,每个DataBus channel聚合了机器上所有TM Sink写同一个Topic的数据,因此批量发送的效率非常高,极大的降低了Kafka集群的写入请求量,与Kafka集群之间需要建立的连接也更少。
同时,单个请求中数据条数的增加带来更高的压缩效率,在DataBus Agent 上开启了ZSTD压缩后,Kafka集群写入带宽降低了37%,极大的缓解了Kafka集群的压力。
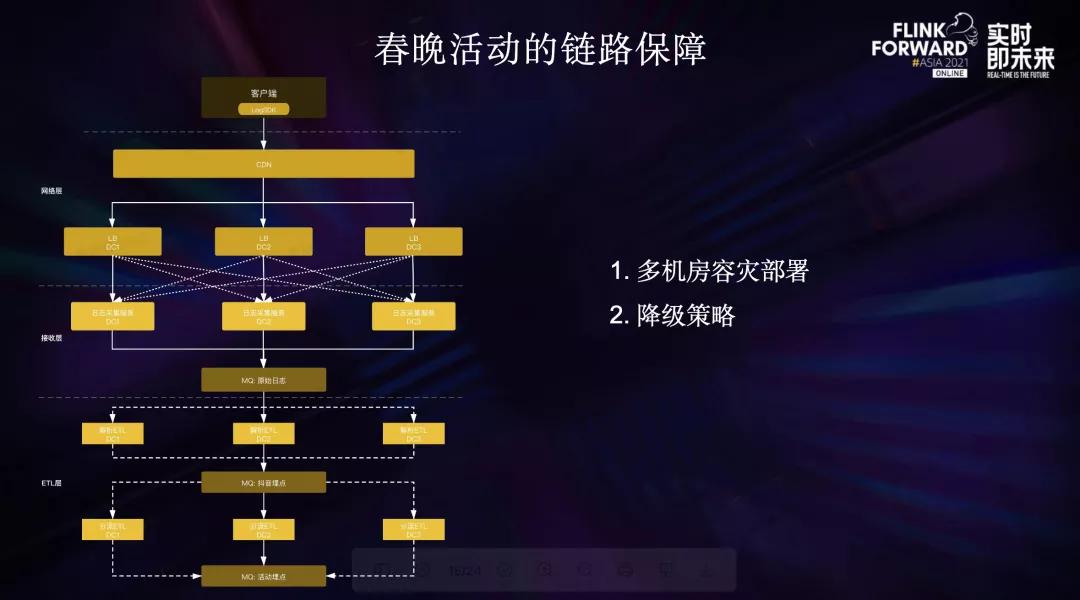
春晚活动是万众瞩目的一大盛事,2021年春晚活动期间数据流对相关的埋点链路进行了重点保障。
首先是完成了多机房的容灾部署并准备了多种切流预案,正常情况下流量会均匀的打到多个机房,MQ多机房同步,Flink ETL Job都从本地消费。如果某个机房出现网络或其他大规模故障,可以从客户端将流量调度到其他机房,也可以在CDN侧将流量调度到不同的机房,数据流Flink ETL 链路可以分钟级进入容灾模式,切换到可用机房。
为了应对口播期间的流量洪峰,我们还准备了客户端降级策略与服务端降级策略。其中客户端降级策略可以动态的降低一定百分比用户的埋点上报频率,口播期间不上报,口播结束后逐步恢复。
在降级场景下,下游指标计算可以通过消费未降级的活动埋点分流估算整体指标。春节活动链路的顺利保障标志着数据流基于Flink搭建的ETL链路已经能提供较好的稳定性和可用性。
02 - 数据流治理实践
数据流比较常见的治理问题包括但不限于以下几个:
- 第一个是数据流稳定性治理中最常见的一个问题——Yarn单机问题导致Flink任务fail-over、反压、消费能力下降。Yarn单机问题的类型有很多,比如:队列负载不均、单机load高、其他进程导致CPU负载高、硬件故障等等。
- 第二个问题是Kafka集群负载不均导致Flink任务生产消费受到影响
- 第三个问题是埋点治理场景中无用埋点、异常埋点消耗大量计算存储资源
针对单机问题,我们从Flink和Yarn两个层面分别进行了优化,将单机load高导致的延迟减少了80%以上。
- 首先,Flink层面的优化。
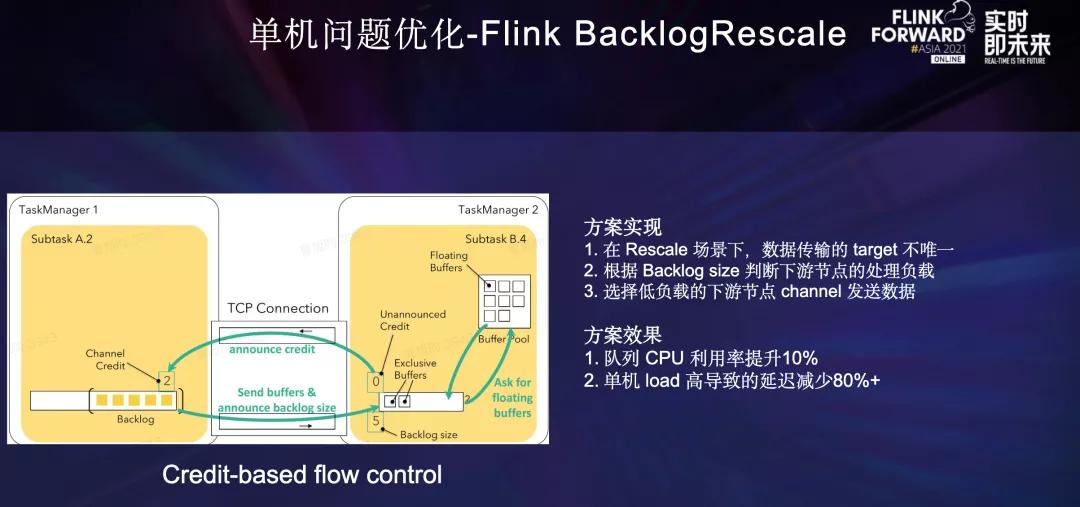
在数据流ETL场景中,为了减少不必要的网络传输,Partitioner主要采用Rescale Partitioner。而Rescale Partitioner会使用Round-robin的方式发送数据到下游部分Channel中,由于单机问题可能出现个别任务处理能力不足的情况,导致反压,任务出现lag。
实际上数据发到下游任何一个任务都是可以的,最合理的策略应该根据下游任务的处理能力去发送数据。
另一方面,我们注意到Flink Credit-based Flow Control反压机制中,可以通过Backlog Size判断下游任务的处理负载,那么我们就可以将Round-robin发送的方式修改为根据Channel的Backlog Size信息选择负载更低的下游Channel发送的方式。
方案上线后队列的负载更加均衡,CPU利用率提升10%。
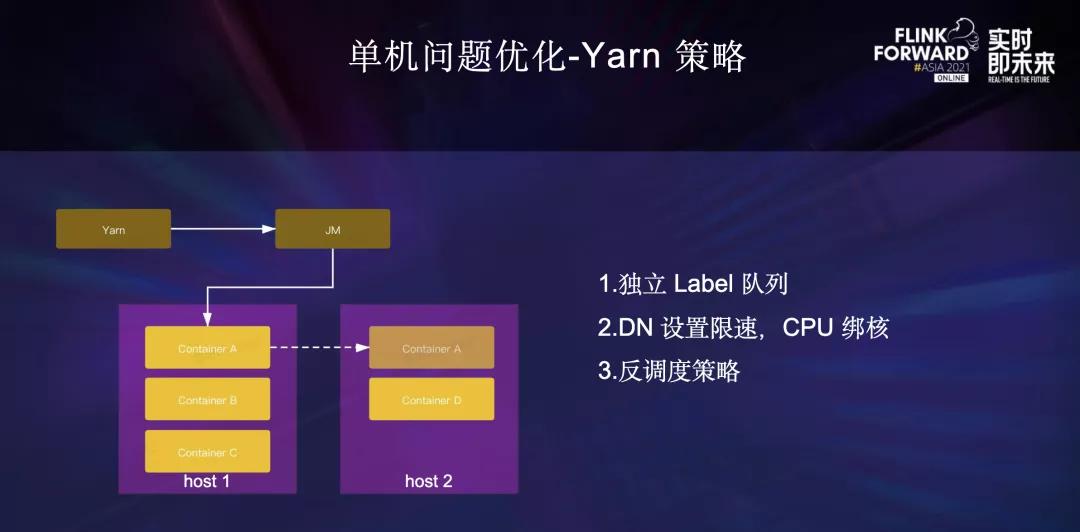
- 其次,Yarn层面的优化。
第一、队列资源使用独立Label队列,避免高峰期和其他低优任务互相影响;
第二、Yarn节点上的DataNode偶发有带宽打满、CPU使用高的情况,影响节点上数据流Flink ETL 任务的稳定性,通过给DataNode设置网络限速并进行CPU绑核以避免DataNode对Flink进程的影响;
第三、Yarn反调度策略。目前字节跳动Flink使用的Yarn GangScheduler调度策略会根据约束条件选择性的获取分配到的Yarn资源,在任务启动时做到比较均衡的放置Container,但由于时间的推移,流量的变化等诸多因素,队列还是可能会出现负载不均衡的情况。
反调度策略则是为了解决负载不均衡而生的二次调度机制。 Yarn会定期检查集群中不再满足原有约束的Container,并在这些Container所在的节点上筛选出需要重新调度的Container返回给Flink JobManager,Flink会重新调度这些Container。
重新调度会按照原有约束尝试申请等量的可用资源,申请成功后进行迁移,申请不成功不做操作。
针对Kafka集群优化问题,我们自研来了存储计算分离的MQ——BMQ,单GB流量成本下降50%。
在数据流这种大流量场景下使用Kafka,经常会遇到broker或者磁盘负载不均衡、磁盘坏掉等情况,进行扩容、机器替换时的运维操作会引起集群Under Replica, 影响读写性能。除此之外,Kafka还有集群规模瓶颈、多机房容灾部署成本高等缺点。
为了优化这些问题,BMQ这款字节跳动自研的存储计算分离的MQ应运而生。
BMQ数据使用HDFS分布式存储,每个partition被切分为多个segment,每个segment对应一个HDFS文件,元数据使用kv存储,Proxy和Broker都是无状态的,因此可以支持快速扩缩容,且没有数据拷贝不会影响读写性能。受益于HDFS多机房容灾部署能力,BMQ多机房容灾部署变得比较简单,数据同时写入所有容灾机房成功后才会向client返回成功,数据消费则是在每个机房本地消费,减少了跨机房带宽,除此之外,由于基于HDFS存储所需的副本数更少,单GB流量成本下降50% 。

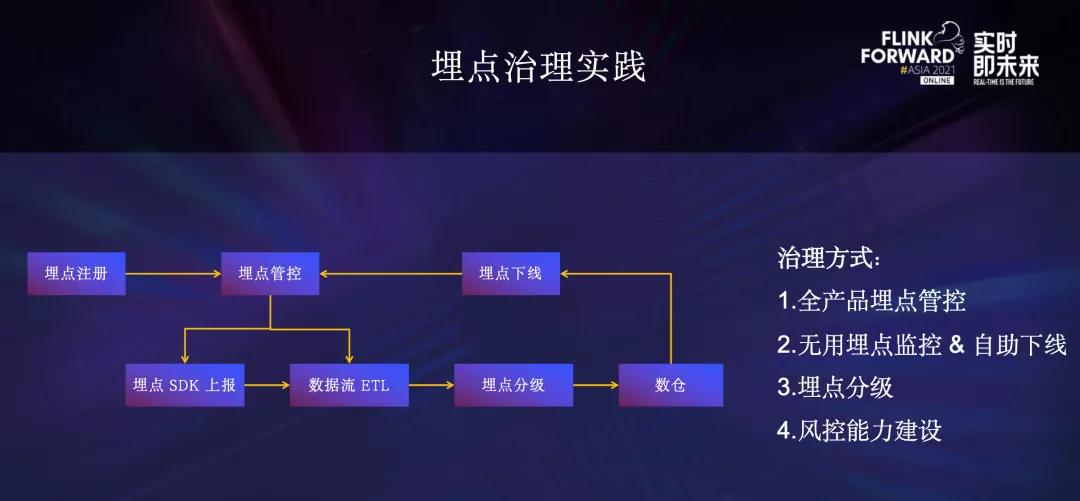
针对埋点治理,我们从全产品开启埋点管控、无用埋点监控&自助下线、埋点分级、风控能力建设四个点入手。
- 全产品开启埋点管控。 所有产品都需要先在流量平台注册埋点元数据才能上报,这是从埋点接入流程进行的治理。
- 对已上报的埋点,通过埋点血缘,统计出已经没有在使用的埋点,自动通知埋点负责人在平台进行自助下线。 埋点注册和埋点下线完成后,都会通过埋点管控服务动态下发相关的配置信息到埋点SDK和数据流Flink ETL任务中,从而保障未注册埋点和无用埋点在上报或ETL环节被丢弃掉。
- 根据不同用途对埋点进行分级,从而Dump到HDFS和数仓的时候可以按不同等级进行分区,不同等级的分区提供不同的TTL和就绪时间的保障。
- 针对异常流量,数据流ETL链路接入了风控系统,对埋点进行实时打标或过滤,防止异常流量造成数据倾斜、数据延迟、统计指标异常等问题。
结语
目前,Flink在字节跳动数据流实践中,已经可以做到计算层面的流批一体。接下来,还将计划探索计算和存储的流批一体,同时也会探索云原生架构,实现资源的动态Rescale,提升资源利用率。此外,在一些高优链路保障上探索追求更高的SLA,比如保障端到端Exactly-once语义。