




sonic 是字节跳动开源的一款 Golang JSON 库,基于即时编译(Just-In-Time Compilation)与向量化编程(Single Instruction Multiple Data)技术,大幅提升了 Go 程序的 JSON 编解码性能。同时结合 lazy-load 设计思想,它也为不同业务场景打造了一套全面高效的 API。
自 2021 年 7 月份发布以来, sonic 已被抖音、今日头条等业务采用,累计为字节跳动节省了数十万 CPU 核。
为什么要自研 JSON 库
JSON(JavaScript Object Notation) 以其简洁的语法和灵活的自描述能力,被广泛应用于各互联网业务。但是 JSON 由于本质是一种文本协议,且没有类似 Protobuf 的强制模型约束(schema),编解码效率往往十分低下。再加上有些业务开发者对 JSON 库的不恰当选型与使用,最终导致服务性能急剧劣化。
在字节跳动,我们也遇到了上述问题。根据此前统计的公司 CPU 占比 TOP 50 服务的性能分析数据,JSON 编解码开销总体接近 10%,单个业务占比甚至超过 40%,提升 JSON 库的性能至关重要。因此我们对业界现有 Go JSON 库进行了一番评估测试。
首先,根据主流 JSON 库 API,我们将它们的使用方式分为三种:
-
泛型(generic)编解码:JSON 没有对应的 schema,只能依据自描述语义将读取到的 value 解释为对应语言的运行时对象,例如:JSON object 转化为 Go map[string]interface{};
-
定型(binding)编解码:JSON 有对应的 schema,可以同时结合模型定义(Go struct)与 JSON 语法,将读取到的 value 绑定到对应的模型字段上去,同时完成数据解析与校验;
-
查找(get)& 修改(set) :指定某种规则的查找路径(一般是 key 与 index 的集合),获取需要的那部分 JSON value 并处理。
其次,我们根据样本 JSON 的 key 数量和深度分为三个量级:
- 小(small):400B,11 key,深度 3 层;
- 中(medium):110KB,300+ key,深度 4 层(实际业务数据,其中有大量的嵌套 JSON string);
- 大(large):550KB,10000+ key,深度 6 层。
测试结果如下:
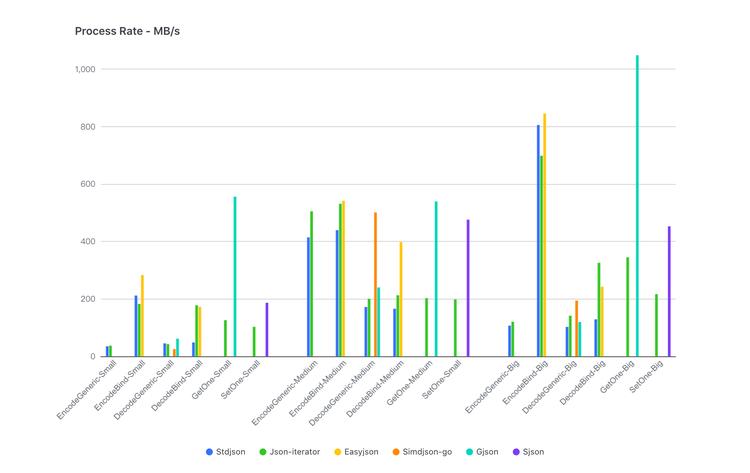
不同数据量级下 JSON 库性能表现
结果显示:目前这些 JSON 库 均无法在各场景下都保持最优性能 , 即使是 当前 使用最广泛的第三方库 json-iterator,在泛型编解码、 大数据 量级场景下 的性能也 满足不了我们的需要。
JSON 库的基准编解码性能固然重要,但是对不同场景的最优匹配更关键 —— 于是我们走上了自研 JSON 库的道路。
开源库 sonic 技术原理
由于 JSON 业务场景复杂,指望通过单一算法来优化并不现实。于是在设计 sonic 的过程中,我们借鉴了其他领域/语言的优化思想(不仅限于 JSON),将其融合到各个处理环节中。其中较为核心的技术有三块:JIT、lazy-load 与 SIMD 。
JIT
对于有 schema 的定型编解码场景而言,很多运算其实不需要在“运行时”执行。这里的“运行时”是指程序真正开始解析 JSON 数据的时间段。
举个例子,如果业务模型中确定了某个JSON key 的值一定是布尔类型,那么我们就可以在序列化阶段直接输出这个对象对应的 JSON 值(‘true’或‘false’),并不需要再检查这个对象的具体类型。
sonic-JIT 的核心思想就是:将模型解释与数据处理逻辑分离,让前者在“编译期”固定下来。
这种思想也存在于标准库和某些第三方 JSON 库,如 json-iterator 的函数组装模式:把 Go struct 拆分解释成一个个字段类型的编解码函数,然后组装并缓存为整个对象对应的编解码器(codec),运行时再加载出来处理 JSON。但是这种实现难以避免转化成大量 interface 和 function 调用栈,随着 JSON 数据量级的增长,function-call 开销也成倍放大。只有将模型解释逻辑真正编译出来,实现 stack-less 的执行体,才能最大化 schema 带来的性能收益。
业界实现方式目前主要有两种:代码生成 code-gen(或模版 template) 和 即时编译 JIT。前者的优点是库开发者实现起来相对简单,缺点是增加业务代码的维护成本和局限性,无法做到秒级热更新——这也是代码生成方式的 JSON 库受众并不广泛的原因之一。JIT 则将编译过程移到了程序的加载(或首次解析)阶段,只需要提供 JSON schema 对应的结构体类型信息,就可以一次性编译生成对应的 codec 并高效执行。
sonic-JIT 大致过程如下:
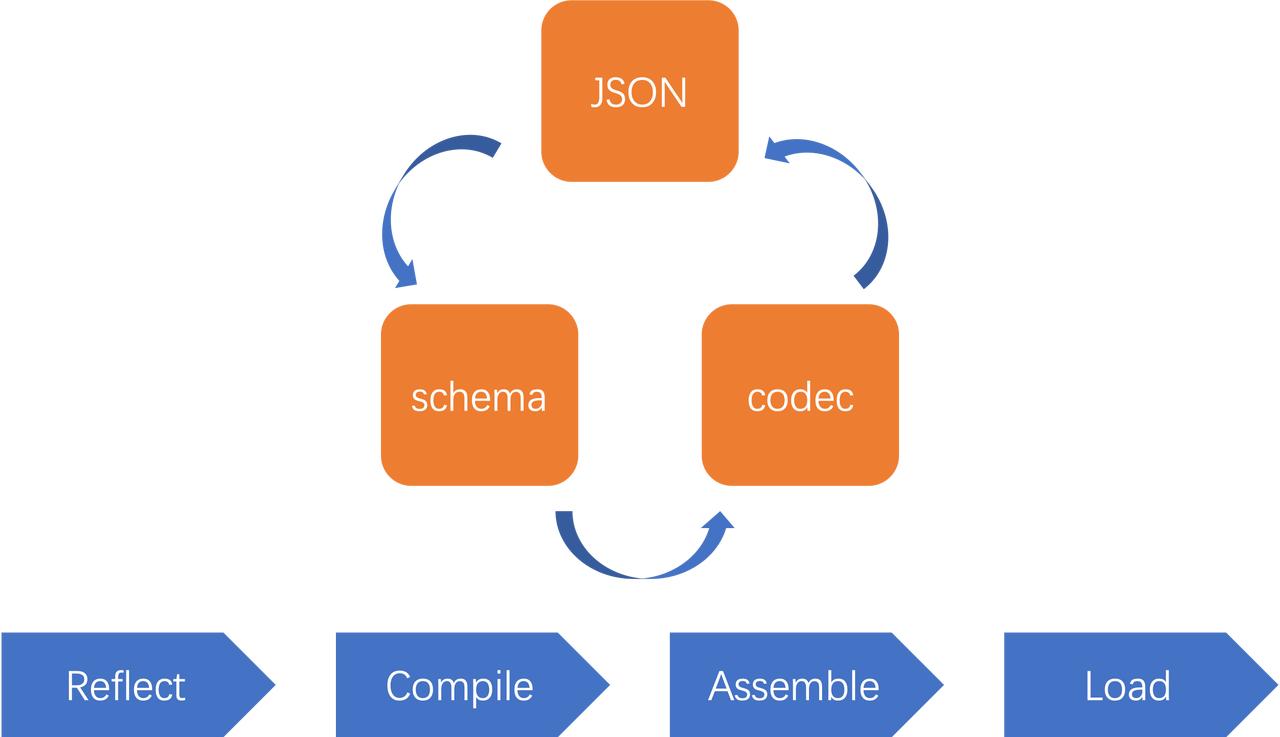
sonic-JIT 体系
- 初次运行时,基于 Go 反射来获取需要编译的 schema 信息 (AST)
- 结合 JSON 编解码算法生成一套自定义的中间代码 OP codes(SSA)
- 将 OP codes 翻译为 Plan9 汇编 (LL)
- 使用第三方库 golang-asm 将 Plan 9 转为机器码 (ASM)
- 将生成的二进制码注入到内存 cache 中并封装为 go function (DL)
- 后续解析,直接根据 type ID (rtype.hash)从 cache 中加载对应的 codec 处理 JSON。
从最终实现的结果来看,sonic-JIT 生成的 codec 性能不仅好于 json-iterator,甚至超过了代码生成方式的 easyjson(见后文“性能测试”章节)。这一方面跟底层文本处理算子的优化有关(见后文“SIMD & asm2asm”章节),另一方面来自于 sonic-JIT 能控制底层 CPU 指令,在运行时建立了一套独立高效的 ABI(Application Binary Interface)体系:
- 将使用频繁的变量放到固定的寄存器上(如 JSON buffer、结构体指针),尽量避免 memory load & store;
- 自己维护变量栈(内存池),避免 Go 函数栈扩展;
- 自动生成跳转表,加速 generic decoding 的分支跳转;
- 使用寄存器传递参数(当前 Go Assembly 并未支持,见“SIMD & asm2asm”章节)。
Lazy-load
对于大部分 Go JSON 库,泛型编解码是它们性能表现最差的场景之一,然而由于业务本身需要或业务开发者的选型不当,它往往也是被应用得最频繁的场景。
泛型编解码性能差仅仅是因为没有 schema 吗?其实不然。我们可以对比一下 C++ 的 JSON 库,如 rappidjson、simdjson,它们的解析方式都是泛型的,但性能仍然很好(simdjson 可达 2GB/s 以上)。标准库泛型解析性能差的根本原因在于它采用了 Go 原生泛 型 ——interface(map[string]interface{})作 为 JSON 的编解码对象。
这其实是一种糟糕的选择:首先是数据反序列化的过程中,map 插入的开销很高;其次在数据序列化过程中,map 遍历也远不如数组高效。
回过头来看,JSON 本身就具有完整的自描述能力,如果我们用一种与 JSON AST 更贴近的数据结构来描述,不但可以让转换过程更加简单,甚至可以实现按需加载(lazy-load)——这便是 sonic-ast 的核心逻辑:它是一种 JSON 在 Go 中的编解码对象,用 node {type, length, pointer} 表示任意一个 JSON 数据节点,并结合树与数组结构描述节点之间的层级关系。

sonic-ast 结构示意
sonic-ast 实现了一种有状态、可伸缩的 JSON 解析过程:当使用者 get 某个 key 时,sonic 采用 skip 计算来轻量化跳过要获取的 key 之前的 json 文本;对于该 key 之后的 JSON 节点,直接不做任何的解析处理;仅使用者真正需要的 key 才完全解析(转为某种 Go 原始类型)。由于节点转换相比解析 JSON 代价小得多,在并不需要完整数据的业务场景下收益相当可观。
虽然 skip 是一种轻量的文本解析(处理 JSON 控制字符“[”、“{”等),但是使用类似 gjson 这种纯粹的 JSON 查找库时,往往会有相同路径查找导致的重复开销(见 benchmark)。
针对该问题,sonic 在对于子节点 skip 处理过程增加了一个步骤,将跳过 JSON 的 key、起始位、结束位记录下来,分配一个 Raw-JSON 类型的节点保存下来,这样二次 skip 就可以直接基于节点的 offset 进行。同时 sonic-ast 支持了节点的更新、插入和序列化,甚至支持将任意 Go types 转为节点并保存下来。
换言之,sonic-ast 可以作为一种通用的泛型数据容器替代 Go interface,在协议转换、动态代理等服务场景有巨大潜力。
SIMD & asm2asm
无论是定型编解码场景还是泛型编解码场景,核心都离不开 JSON 文本的处理与计算。其中一些问题在业界已经有比较成熟高效的解决方案,如浮点数转字符串算法 Ryu,整数转字符串的查表法等,这些都被实现到 sonic 的底层文本算子中。
还有一些问题逻辑相对简单,但是可能会面对较大数量级的文本,如 JSON string 的 unquote\quote 处理、空白字符的跳过等。此时我们就需要某种技术手段来提升处理能力。SIMD 就是这样一种用于并行处理大规模数据的技术,目前大部分 CPU 已具备 SIMD 指令集(例如 Intel AVX),并且在 simdjson 中有比较成功的实践。
下面是一段 sonic 中 skip 空白字符的算法代码:
#if USE_AVX2
// 一次比较比较32个字符
while (likely(nb >= 32)) {
// vmovd 将单个字符转成YMM
__m256i x = _mm256_load_si256 ((const void *)sp);
// vpcmpeqb 比较字符,同时为了充分利用CPU 超标量特性使用4 倍循环
__m256i a = _mm256_cmpeq_epi8 (x, _mm256_set1_epi8(' '));
__m256i b = _mm256_cmpeq_epi8 (x, _mm256_set1_epi8('\t'));
__m256i c = _mm256_cmpeq_epi8 (x, _mm256_set1_epi8('\n'));
__m256i d = _mm256_cmpeq_epi8 (x, _mm256_set1_epi8('\r'));
// vpor 融合4次结果
__m256i u = _mm256_or_si256 (a, b);
__m256i v = _mm256_or_si256 (c, d);
__m256i w = _mm256_or_si256 (u, v);
// vpmovmskb 将比较结果按位展示
if ((ms = _mm256_movemask_epi8(w)) != -1) {
_mm256_zeroupper();
// tzcnt 计算末尾零的个数N
return sp - ss + __builtin_ctzll(~(uint64_t)ms);
}
/* move to next block */
sp += 32;
nb -= 32;
}
/* clear upper half to avoid AVX-SSE transition penalty */
_mm256_zeroupper();
#endif
sonic 中 strnchr() 实现(SIMD 部分)
开发者们会发现这段代码其实是用 C 语言编写的 —— 其实 sonic 中绝大多数文本处理函数都是用 C 实现的:一方面 SIMD 指令集在 C 语言下有较好的封装,实现起来较为容易;另一方面这些 C 代码通过 clang 编译能充分享受其编译优化带来的提升。为此我们开发了一套 x86 汇编转 Plan9 汇编的工具 asm2asm,将 clang 输出的汇编通过 Go Assembly 机制静态嵌入到 sonic 中。同时在 JIT 生成的 codec 中我们利用 asm2asm 工具计算好的 C 函数 PC 值,直接调用 CALL 指令跳转,从而绕过 Go Assembly 不能寄存器传参的限制,压榨最后一丝 CPU 性能。
其它
除了上述提到的技术外,sonic 内部还有很多的细节优化,比如使用 RCU 替换 sync.Map 提升 codec cache 的加载速度,使用内存池减少 encode buffer 的内存分配,等等。这里限于篇幅便不详细展开介绍了,感兴趣的同学可以自行搜索阅读 sonic 源码进行了解。
性能测试
我们以前文中的不同测试场景进行测试(测试代码见 benchmark),得到结果如下:
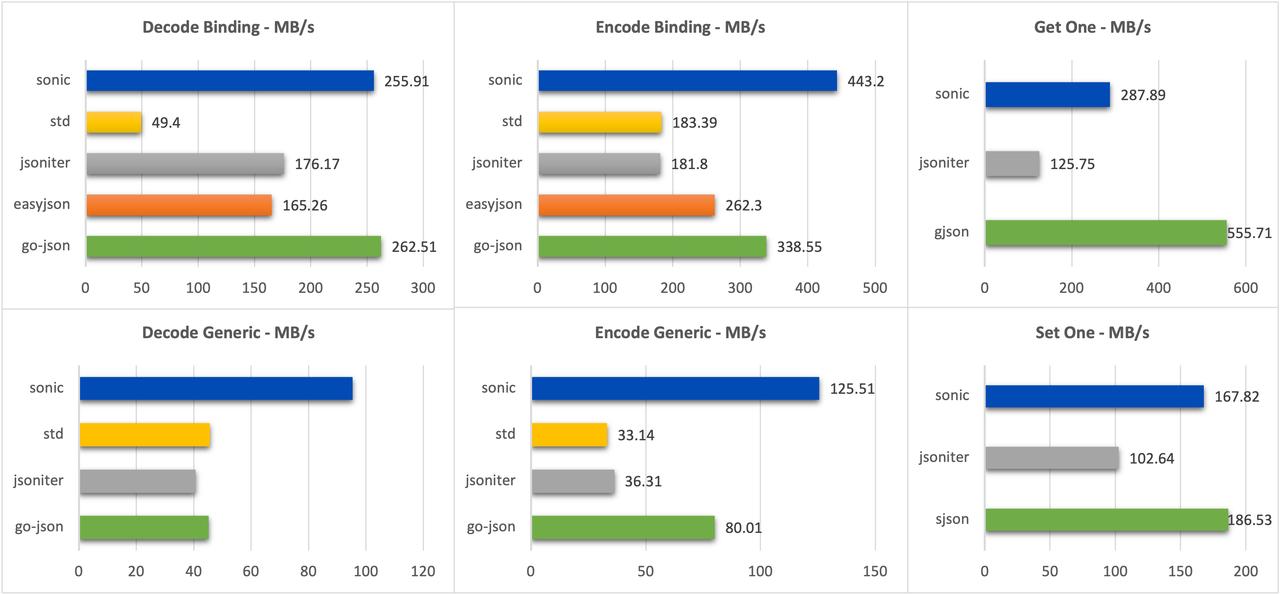
小数据(400B,11 个 key,深度 3 层)
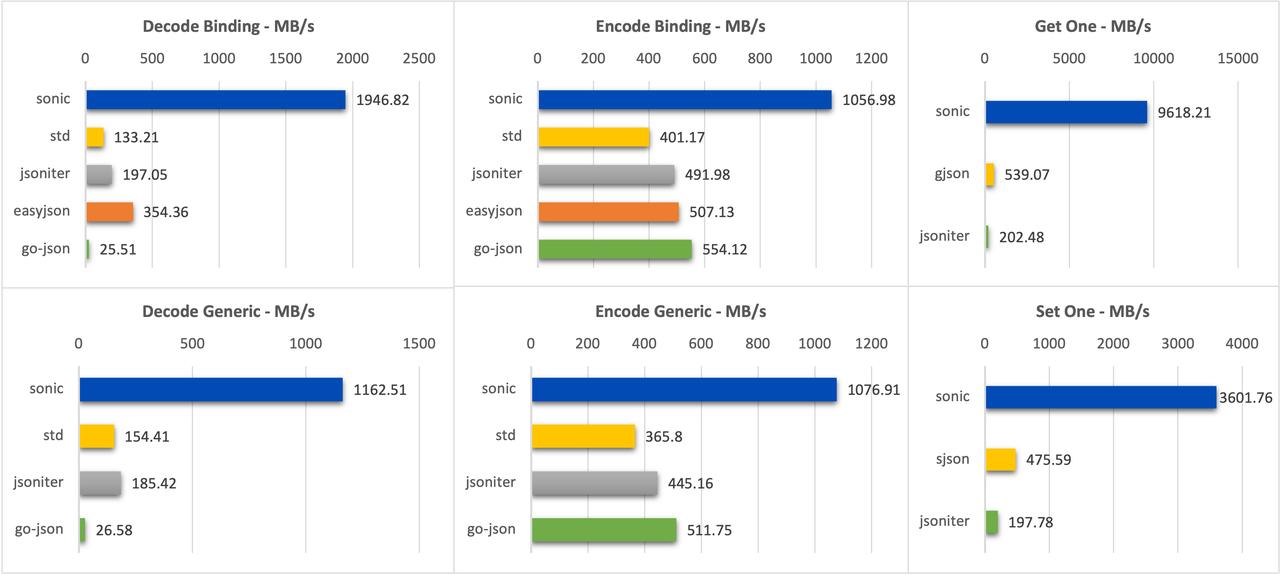
中数据(110KB,300+ key,深度 4 层)
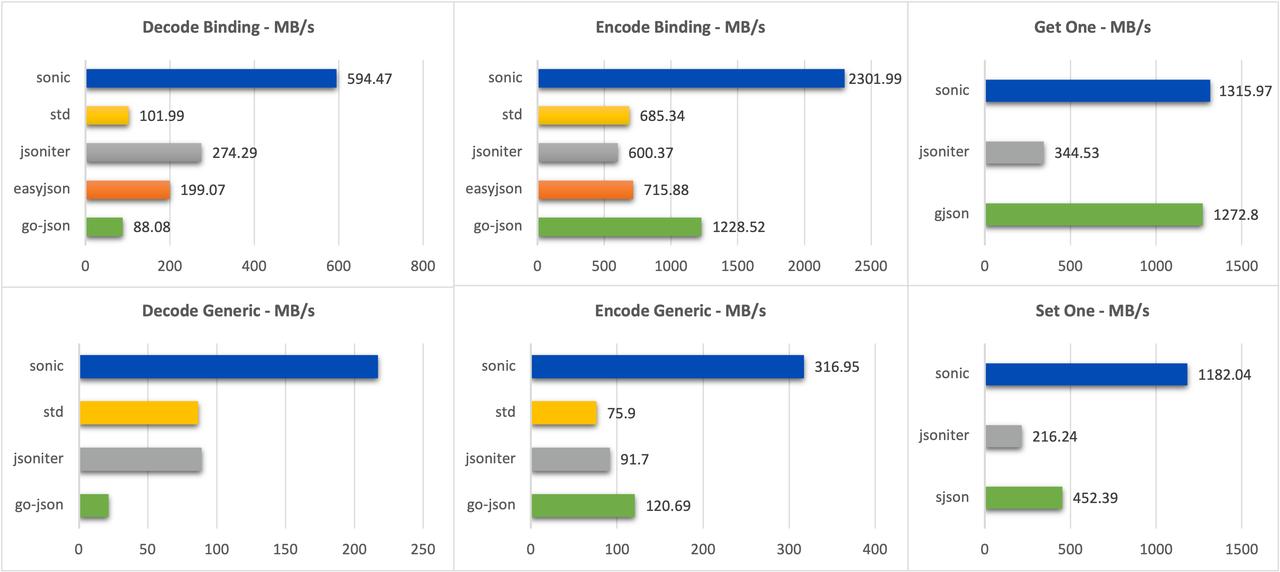
大数据(550KB,10000+ key,深度 6 层)
可以看到 sonic 在几乎所有场景下都处于领先(sonic-ast 由于直接使用了 Go Assembly 导入的 C 函数导致小数据集下有一定性能折损)
- 平均编码性能较 json-iterator 提升 240%,平均解码性能较 json-iterator 提升 110%;
- 单 key 修改能力较 sjson 提升 75% 。
并且在生产环境中,sonic 中也验证了良好的收益,服务高峰期占用核数减少将近三分之一:
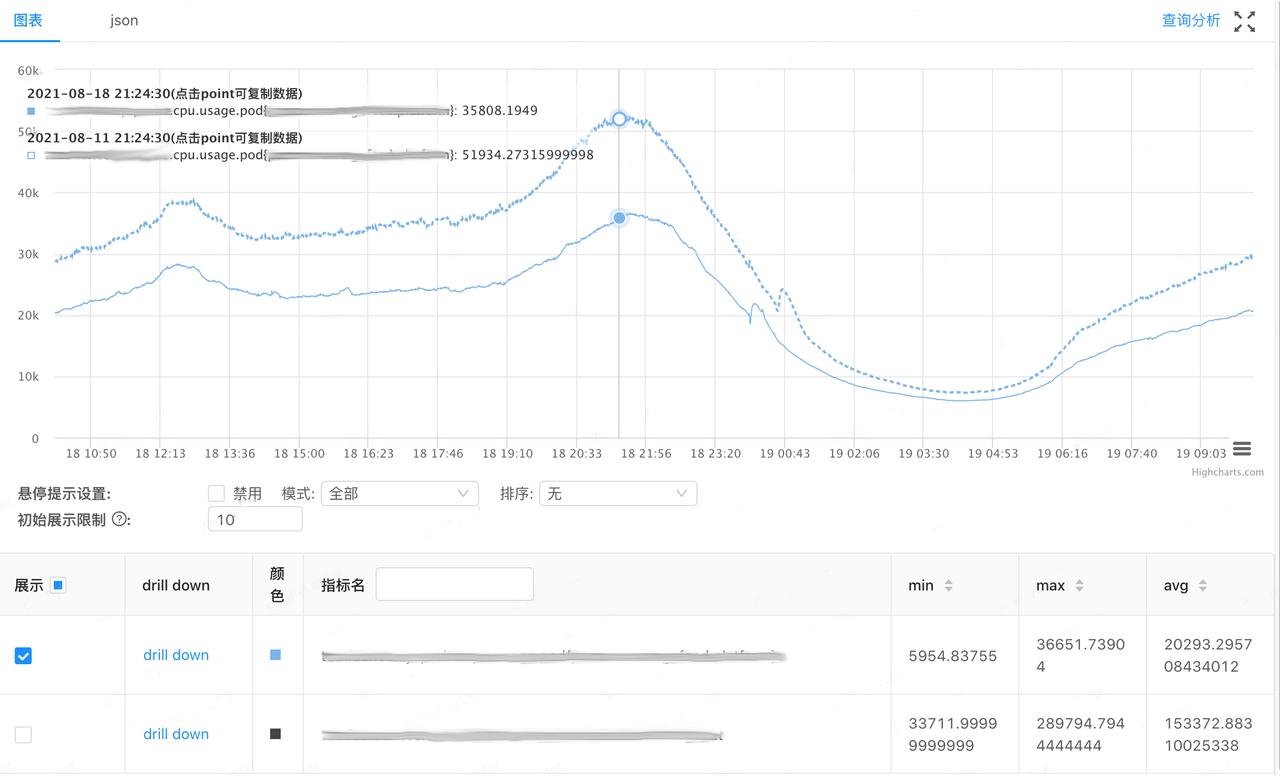
字节某服务在 sonic 上线前后的 CPU 占用(核数)对比
结语
由于底层基于汇编进行开发,sonic 当前仅支持 amd64 架构下的 darwin/linux 平台 ,后续会逐步扩展到其它操作系统及架构。除此之外,我们也考虑将 sonic 在 Go 语言上的成功经验移植到不同语言及序列化协议中。目前 sonic 的 C++ 版本正在开发中,其定位是基于 sonic 核心思想及底层算子实现一套通用的高性能 JSON 编解码接口。
近日,sonic 发布了第一个大版本 v1.0.0,标志着其除了可被企业灵活用于生产环境,也正在积极响应社区需求、拥抱开源生态。我们期待 sonic 未来在使用场景和性能方面可以有更多突破,欢迎开发者们加入进来贡献 PR,一起打造业界最佳的 JSON 库!
相关链接
项目地址:https://github.com/bytedance/sonic
BenchMark:https://github.com/bytedance/sonic/blob/main/bench.sh