




问题背景
我们周围存在大量的文字、语音、视频等信息,比如网络购物玲琅满目的商品信息,浏览抖音各种类型的信息,一个互联网产品是否具有吸引力,是看其有多智能,能够让用户发较小的时间能够获取他感兴趣的内容,这里面少不了推荐系统的作用了,它已经渗透到我们生活中的方方面面,他们解决的问题的本质都是一一样的,就是为了解决:“信息”过载的情况下,用户如何高效获取感兴趣的信息。在浩如烟海的互联网信息中和用户兴趣点之间,搭建起一座桥梁。
逻辑结构
推荐系统主要处理的是人和物的关系,描述一个人 可以从性别、年龄、兴趣爱好来进行描述,每个人都有不同的喜好,而这个喜好会随着时间的变化、年龄的变化、场地的变化、场景的变化、身份的转变呈现出不一样的喜好,从技术的角度来说如何竟可能的勾勒出这个人的准确特征,选择符合当前情境下的物品、内容展现给用户这就是推荐系统要解决的问题。总结如下:
对于某个用户 U(User),在特定场景下C(Context),针对海量的“物品”信息构建一个函数,预测用户对特定候选物品I(Item)的喜好程度,在根据喜好程度进行排序,生成推荐列表的问题。如下图呈现:
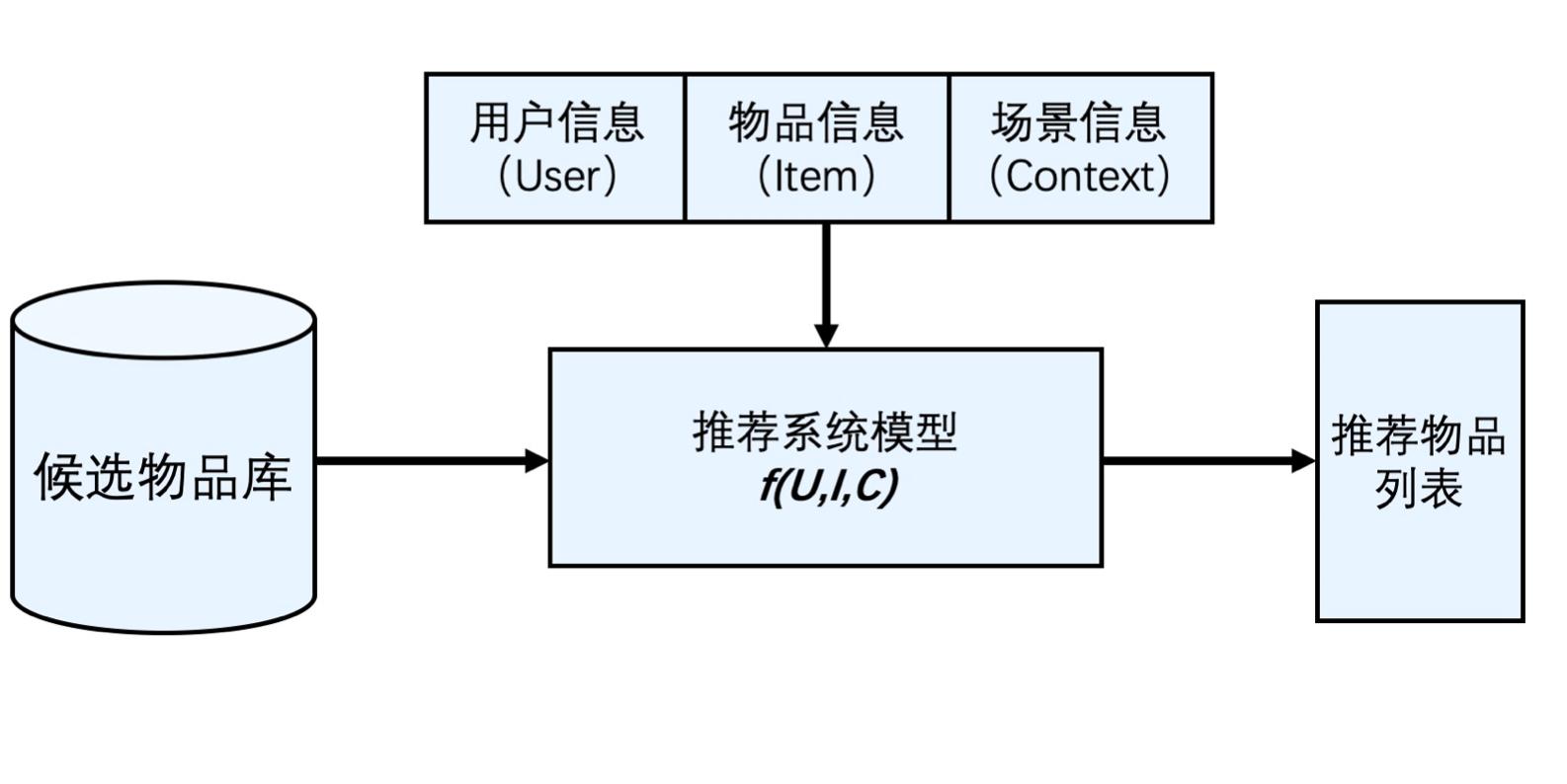
具体用技术去实现,就是在各个模块上面进行细化和扩展,因此而形成推荐系统的整个技术体系。
复杂的系统通常由简单的规则而组合而来。
技术架构
实际在推荐系统的开发过程中,推荐系统工程师需要着重解决的问题有两类。
一类问题与数据和信息相关,即“用户信息”、“物品信息”、“场景信息”分别是什么?如何存储、更新和处理数据?
另一类问题与推荐系统算法和模型相关,即推荐系统模型如何训练、预测、以及如何达成更好的推荐效果?
一个工业级推荐系统技术架构其实也是按照这两部分展开的,其中“数据和信息”部分逐渐发展为推荐系统中融合了数据离线批处理、实时流处理的数据流框架;
“算法和模型”部分则进一步细化为推荐系统中,集训练、评估、部署、线上推断为一体的模型框架。
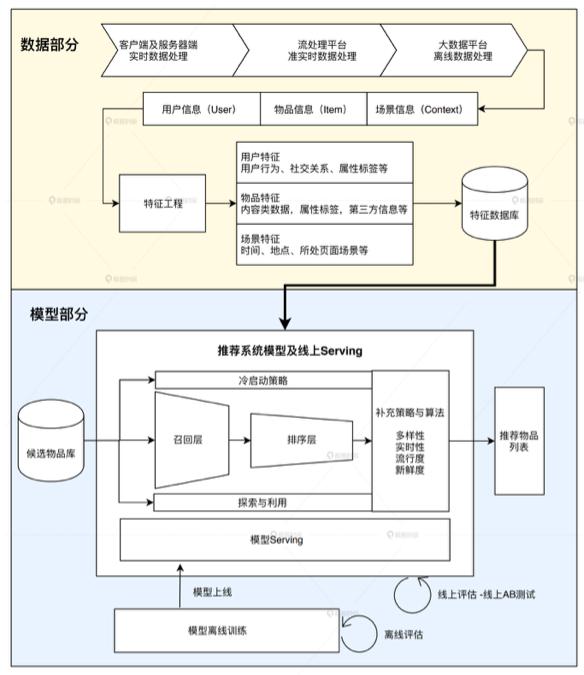
推荐系统数据工程
主要负责的是“用户”、“场景”、“物品”信息的收集与处理。根据处理数据量和处理实时性的不同,会用到三种不同的数据处理方式,按照实时性排序,一次是客户端与服务端实时数据处理、流处理平台准实时数据处理(Flink准实时数据处理)、大数据平台离线数据处理(Spark离线数据批处理)。这其中会用到常见的大数据计算和存储技术对数据进行特征工程预处理和特征的存储,比如Spark MLlib、Flink、HDFS等 。
大数据平台加工后的数据出口主要有3个:
数据用于训练
生成推荐系统模型所需要的样本数据,用于算法模型的训练和评估。
这部分用来训练的样本特征数据,一般是以文件的形式存储在分布式文件系统或者对象存储中,比如HDFS、S3、Ceph中。
进一步的算法在建模的时候,会把数据分为训练集、测试集、验证集等。
数据用于线上推理
生成推荐系统模型服务所需要的“用户特征”,“物品特征”,和一部分“场景特征”,用于推荐系统的线上推断。线上推断的特征需要访问速度比较快,不能够有太大的延迟,通常会采用redis、Cassandra、RocksDB 之类的KV存储进行特征的存储。
数据用于报表等可视化展示
生成系统监控、商业智能(business intelligence BI)系统所需要的统计型数据。这类统计型的数据通常是存在关系型数据库中,比如Mysql。这块统计出结构后,通过报表等可视化的形式供给相关数据分析、产品运行、公司领导做出业务调整和决策。
数据部分是整个推荐系统的水源,深度学习对水源要求是水量要大(模型尽快收敛)、水流要快(让数据能够更快的流到模型更新训练的模块,这样才能让模型实时抓住用户兴趣变化的趋势)。其中数据部分还包括大量的特征工程,毕竟在推荐系统领域算法模型都是比较公开的,特征工程、数据工程处理的好坏对推荐系统的效果起着很重要的作用了。
推荐系统模型部分
推荐系统模型的结构一般由“召回层”、“排序层”以及“补充策略与算法层”组成。
其中召回层一般由高效的召回规则、算法或简单的模型组成,这让推荐系统能快速从海量的候选集中召回用户可能感兴趣的物品。“排序层”则是利用排序模型对初筛的候选集进行精排序。补充策略与算法层也被称为再排序层,是在返回给用户推荐列表之前,为兼顾结果的“多样性”、“流行度”、“新鲜度”等指标,结合一些补充策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。这块会涉及到算法选型、数据特征处理方法等。
从推荐系统模型接收到所有候选物品集,到最后产生推荐列表,这一过程叫做“模型服务过程”。模型服务的过程是把模型从一个静态的结果,上线到线上进行服务,这里面涉及到一些的后端技术,如果提供高可用、高性能的服务是很重要的。
模型训练方法根据环境的不同,可以分为离线训练和在线更新两部分。另外推荐系统还包括,离线评估和线上A/B测试等多种评估模块。
下面分模型训练、线上服务两部分来简单介绍下所采用的技术
模型训练
模型训练就是主要是算法的选择及训练,其中会涉及到计算框架的选择,当前模型越来越复杂,所需要的算力要求也越高,通常会采用分布式计算框架比如Spark、tensorflow、pytorch等。现在各大公司普通采用的深度学习模型,能够应对复杂的模型结构、具有比较强的数据拟合能力 和算法表达能力,能让推荐模型更好的跟踪用户的兴趣变迁过程,同时也能够更快、更强的处理推荐系统相关数据。模型训练涉及到相关算法的使用,这里不做过多介绍。
线上服务
通常一个工业级推荐系统中,大量的工作都发生在搭建并维护推荐服务器、模型服务模块,以及特征和模型参数数据库等线上服务部分。训练和实现推荐模型的工作量不到一半。
推荐系统服务需要满足高并发、高可用、高可靠的机制,通常一线互联网为了应对大量的推荐请求都为采用分布式的服务部署,一个推荐服务部署到多台机器上,通过Nginx之类的负债均衡进行分流,另外就是为了减少服务器数据重复访问和计算会使用内存缓冲机制,同时为了应对流量波峰都会有类似的服务降级策略,抛弃原本复杂的计算逻辑和数据访问逻辑,采用最简单、最保险、最不消耗资源的降级服务来度过特殊时期。
线上服务方法
推荐系统主流模型服务方法:
模型服务有多种部署部署模式,比如预存结果、复杂模型预训练及轻量级模型线上服务、基于模型PMML模型转换及上线、Tensorflow Serving服务。其中前两种并不是端到端的训练和模型部署,PMML的话对于复杂的深度学习模型服务来说,表达能力比较有限,还不足以支持复杂的深度学习模型,所以深度学习模型就需要借助Tesorflow Serving来完成了。
- 预存推荐结果或 Embedding 结果
离线生成每个用户的推荐结果,存储在如redis之类的线上数据库中,在线上环境中直接取出预存数据推荐给用户即可。
- 预训练 Embedding+ 轻量级线上模型
- 利用PMML转换和部署模型
PMML(预测模型标记语言)
JPMML作为序列化xml和解析PMML文件的Library库
- TensorFlow Serving
Tesorflow 模型上线流程主要是,先离线把模型序列化存储到文件系统,Tensorflow Serving把模型文件载入到模型服务器,还原模型推断过程,对外以HTTP接口或gRPC接口的方式提供模型服务。
总结
这里真是从大的方向上总结了推荐系统的主要架构和内容,整个个推荐系统不仅仅是算法,还需要有大量的后台工程能力,包括大数据技术数据工程、推荐系统后端技术开能力,同时还会涉及到逻辑能力,程序员算法数据结构工程能力,另外还有一个就是业务能力,比较推荐系统需要与特定的业务场景结合起来,只有算法、工程、业务三者结合起来,才能够取得大的突破,因此作为推荐系统学习者,这里面涉及到大量的技术,