




在系统业务开发的过程中,都会面临这样一个问题:面对业务的快速扩展,很多版本在当时没有时间去全局考虑,导致很多业务数据存储和管理并不规范,例如常见的问题:
- 地址采取输入的方式,而非三级联动;
- 没有统一管理数据字典获取接口;
- 数据存储的位置和结构设计不合理;
- 不同服务的数据库之间存在同步通道;
而分析业务通常都是要面对全局数据,如果出现大量的上述情况,就会导致数据在使用的时候难度非常大,随之也会带来很多问题:数据分散不规范,导致响应性能差,稳定性低,同时提高管理成本。
当随着业务发展,数据的沉淀越来越多,使用的难度就会陡增,会导致在数据分析之前,需要大量时间去清洗数据。
1、基本方案
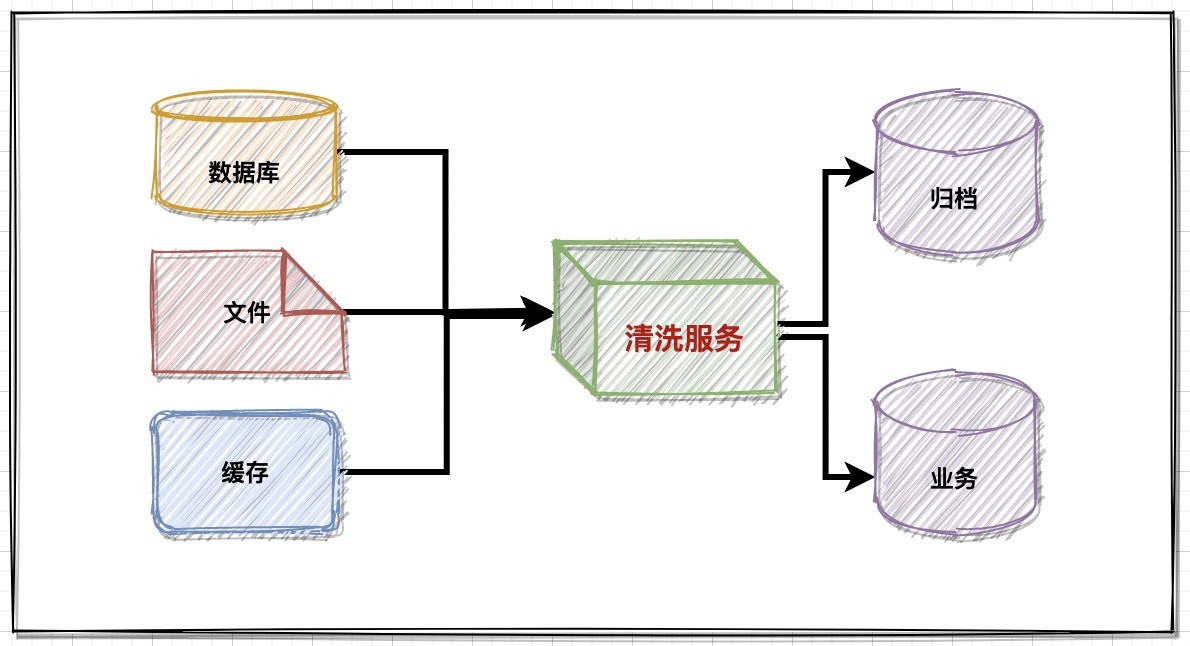
核心思想:
- 读-洗-写入业务库持续服务;
- 读-洗-写入档案数据资产库;
业务数据清洗本质上理解起来并不难,即读取待清洗的数据源,经过清洗服务规范化处理后,再把数据放到指定的数据源,但是实际操作起来绝对叫人眼花撩到。
2、容器迁移
数据存储的方式本身就是多种选择,清洗数据要面对的第一个问题就是:数据容器的迁移;
- 读数据源:文件、缓存、数据库等;
- 临时容器:清洗过程存储节点数据;
- 写数据源:清洗后数据注入的容器;
所以清洗数据的第一步就是明确整个流程下要适配多少数据源,做好服务的基础功能设计与架构,这是支撑清洗服务的基础;
3、结构化管理
读取的清洗数据可能并不是基于库表管理的结构化数据,或者在数据处理过程中在中间临时容器存储时,为了方便下次操作取到数据,都需要对数据做简单的结构管理;
例如:通常读取文件的服务性能是很差,当数据读取之后在清洗的过程中,一旦流程中断,可能需要对数据重新读取,此时如果再次读取文件是不合理的,文件中数据一旦读取出来,应该转换成简单的结构存储在临时容器中,方便再次获取,避免重温处理文件的IO流;
常见数据结构管理的几个业务场景:
- 数据容器更换,需要重组结构;
- 脏数据结构删除或者多字段合并;
- 文件数据(Json、Xml等)转结构;
注意:这里的结构管理可能不是单纯的库表结构,也可能是基于库表存储的JSON结构或者其他,主要为了方便清洗流程的使用,以至最终数据的写入。
4、标准化内容
标准化内容则是数据清洗服务中的一些基本准则,或者一些业务中的规范,这块完全根据需求来确定,也涉及到清洗数据的一些基本方法;
于业务本身的需求而言,可能常见几个清洗策略如下:
- 基于字典统一管理:例如常见的地址输入,如果值
浦东新区XX路XX区,这样要清洗为上海市-浦东新区-XX路XX区,省市区这种地域肯定是要基于字典方式管理的表,事实上在系统中很多字段属性都是要基于字典去管理值的边界和规范,这样处理之后有利于数据的使用、搜索、分析等; - 数据分析档案化:例如在某个业务模块需要用户实名认证,如果认证成功,基于手机号+身份证所读取到的用户信息则是变动极小,特别是基于身份证号分解出来的相关数据,这些数据则可以作为用户档案数据,做数据资产化管理;
- 业务数据结构重组:通常分析都会基于全局数据来处理,这就涉及到数据分分合合的管理,这样可能需要对部分数据结构做搬运,或者不同业务场景下的数据结构做合并,这样整体分析,更容易捕获有价值的信息数据;
然对于数据清洗本身来说,也是有一些基本策略:
- 数据基础结构的增、删、合并等;
- 数据类型的转变,或者长度处理;
- 数据分析中数值转换、缺失数据弥补或丢弃;
- 数据值本身的规范化处理,修复等;
- 统一字符串、日期、时间戳等格式;
在数据清洗的策略中并没有一个标准化的规范,这完全取决数据清洗后的业务需求,例如数据质量差,严重缺失的话可能直接丢弃,也可能基于多种策略做弥补,这完全取决于结果数据的应用场景。
1、基础设计

通常在数据清洗的服务中,会围绕数据的读-洗-写基本链路来做架构,各个场景本身并没有过于复杂的逻辑:
数据源读取
数据源读取两面对两个关键问题之一:适配,不同的存储方式,要开发不同的读取机制;
- 数据库:MySQL、Oracle等;
- 文件型:XML、CSV、Excel等;
- 中间件:Redis、ES索引等;
另一个关键问题就是数据读取规则:涉及读取速度,大小,先后等;
- 如果数据文件过大可能要做切割;
- 数据间如果存在时序性,要分先后读取;
- 根据清洗服务处理能力,测评读取大小;
2、服务间交互
事实上服务间如何交互,如何管理数据在整个清洗链路上的流动规则,需要根据不同服务角色的吞吐量去考量,基本交互逻辑为两个:直调、异步;
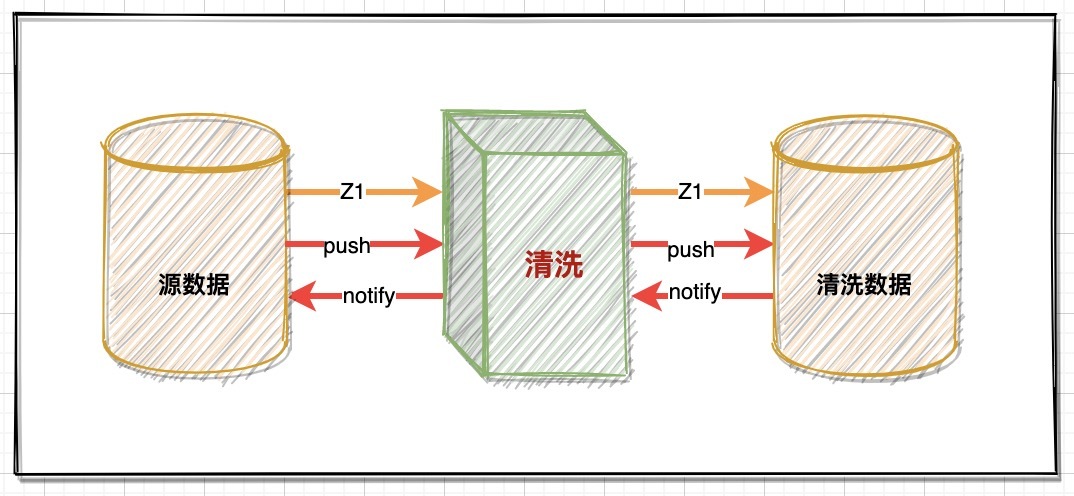
- 直调:如果各服务节点处理能力相同,采用直调方式即可,这种方式流程比较简单,并且可以第一时间捕获异常,做相应的补偿处理,但实际上清洗服务要处理的规则非常多,自然要耗时很多;
- 异步:每个服务间做解耦,通过异步的方式推动各个节点服务执行,例如数据读取之后,异步调用清洗服务,当数据清洗完成后,在异步调用数据写入服务,同时通知数据读服务再次读取数据,这样各个服务的资源有释放的空隙,降低服务压力,为了提高效率可以在不同服务做一些预处理,这样的流程设计虽然更合理,但是复杂度偏高。
数据的清洗是一个细致且耗费精力的活,要根据不同需求,对服务做持续优化和通用功能的沉淀。
3、流程化管理
对数据清洗链路做一个流程管理十分有必要,通常要从两个方面考虑:节点状态、节点数据;
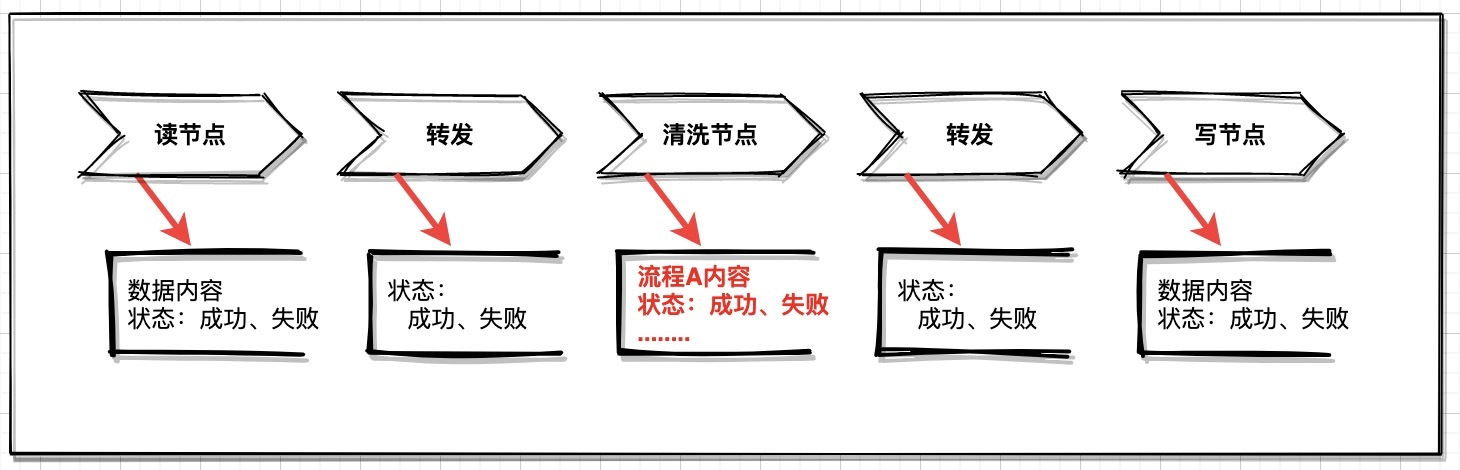
清洗节点:这是重点记录的节点,如果清洗规则过多,分批处理的话,对于每个关键流程处理成功后的数据和状态做记录尤其重要;
读写节点:根据数据源类型选择性存储,例如文件类型;
转发节点:记录转发状态,常见成功或者失败状态;
对于关键节点结果记录,可以在清洗链路失败的时候快速执行重试机制,哪个节点出现异常,可以快速构建重新执行的数据,例如读取文件A的数据,但是清洗过程失败,那么可以基于读节点的数据记录快速重试;
如果数据量过大,可以对处理成功的数据进行周期性删除,或者直接在数据写成功之后直接通知删除,降低维护清洗链路本身对资源的过度占用。
4、工具化沉淀
在数据清洗的链路中,可以对一些工具型代码做持续沉淀和扩展:
- 数据源适配,常用库和文件类型;
- 文件切割,对大文件的处理;
- 非结构化数据转结构化表数据;
- 数据类型转换和校验机制;
- 并发模式设计,多线程处理;
- 清洗规则策略配置,字典数据管理;
数据清洗的业务和规则很难一概而论,但是对清洗服务的架构设计,和链路中工具的封装沉淀是很有必要的,从而可以集中时间和精力处理业务本身,这样面对不同的业务场景,可以更加的快速和高效。
5、链路测试
数据清洗的链路是比较长的,所以对链路的测试很有必要,基本上从两个极端情况测试即可:
- 缺失:非必要数据之外全部缺失;
- 完整:所有数据属性的值全存在;
这两个场景为了验证清洗链路的可用性和准确性,降低异常发生的可能性。