




背景
我行自2018年开始从传统集中式应用架构向分布式微服务应用架构转型,2020年开始拥抱云原生体系,实现应用、平台上云。随着架构转型的不断深入,对监控体系的要求也不断提高,本文回顾我们基于Prometheus对微服务监控体系的一些探索和实践。
Prometheus是CNCF基金会管理的第二个毕业项目(第一个是Kubernetes),由于其良好的架构设计和完善的生态,迅速成为了监控领域的主流解决方案,尤其是在云原生领域。
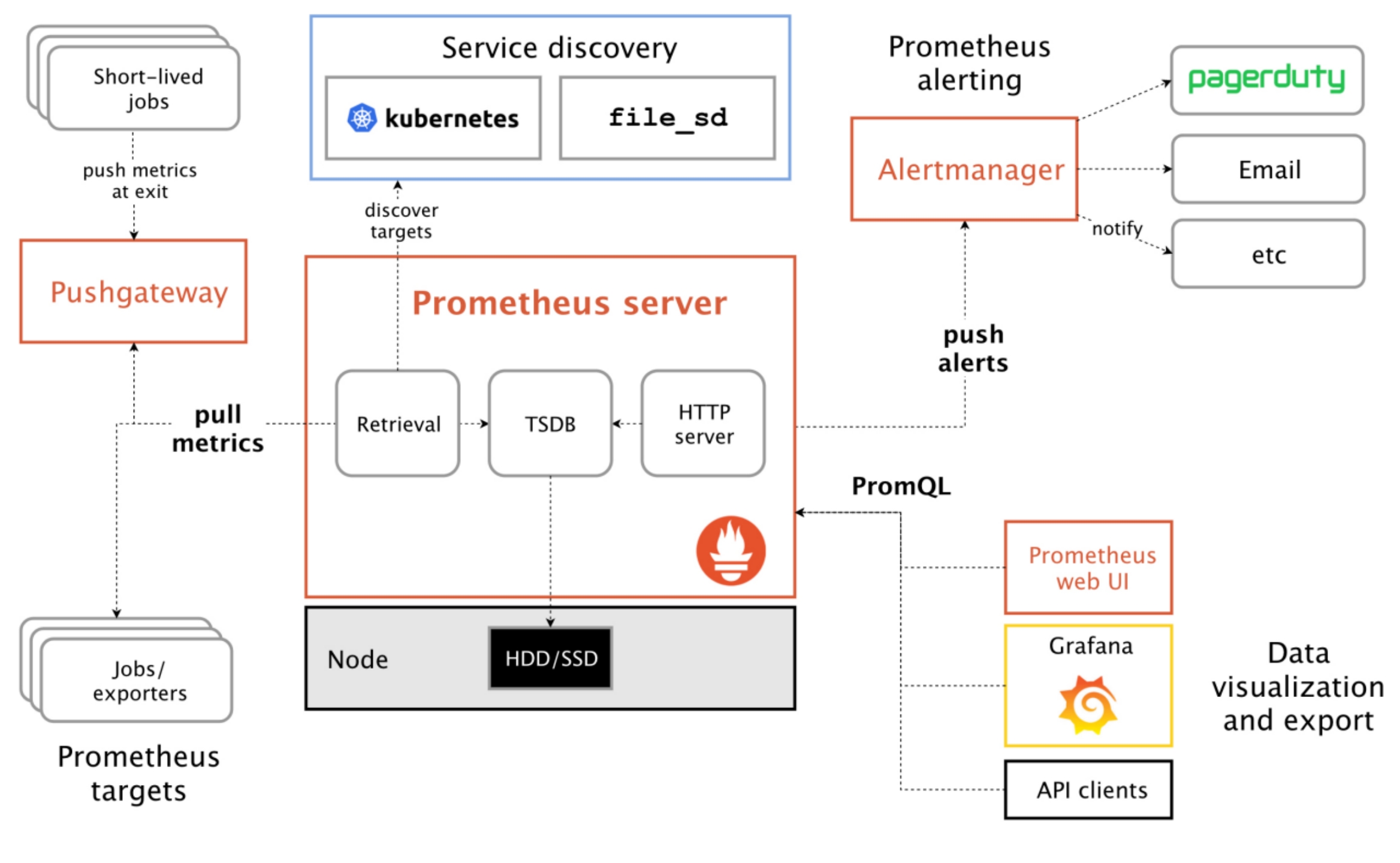
随着深入地了解Prometheus,会发现一些非常好的功能:
- 生态丰富,社区活跃,开源社区建立了数百个exporter,同时提供开箱即用的Grafana dashboard。基本上涵盖了所有基础设施和主流中间件
- 工具库可从您的应用程序获取自定义指标。基本上主流开发语言都有对应的工具库。
- 服务发现使配置更加容易。Prometheus支持consul,etcd,kubernetes以及各家公有云厂商自动发现。对于监控目标动态发现,这点特别契合Cloud时代,应用动态扩缩的特点。
- Pushgateway,Alermanager等组件,基本上涵盖了一个完整的监控生命周期;社区中Thanos、Cortex 等监控套件,完善其集群能力。
同样Prometheus同样存在一些问题:
- Prometheus性能不足:原生Prometheus并不支持高可用,也不能做横向扩缩容,当集群规模较大时,单一Prometheus会出现性能瓶颈,无法正常采集数据。
- 运维难度大:每一级Prometheus都是单独管理的,缺乏全局管理工具。
- 告警能力不足:缺乏oncall机制,告警信息持久化存储等能力。
通过服务发现简化运维
Prometheus提供多种客户端配置方式,包括服务发现,静态文件等。在目前云原生环境下,应用具备高度弹性,通过静态配置监控目标的行为是多么的低效。所以我们要尽可能的通过服务发现来管理客户端列表。
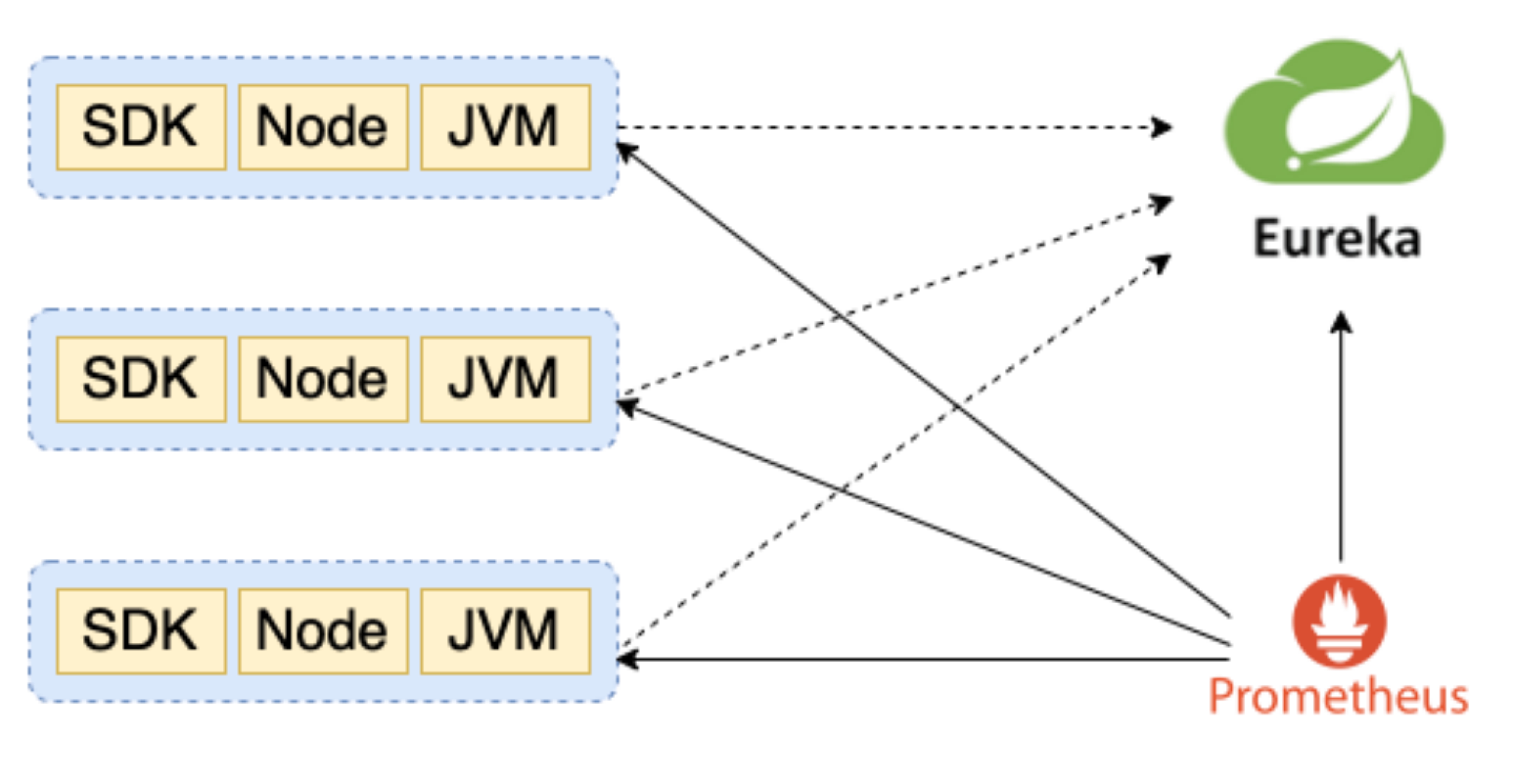
借助于架构转型,全行使用统一的springcloud技术栈,注册中心为Eureka,为了兼容Prometheus服务发现,我们对Eureka进行二次开发使其能够模拟Consul的服务注册发现API(2.21.0版本后以支持Eureka SD),简化server端配置。
我们监控主要分为资源监控和应用监控,资源监控为服务所在主机、虚机或容器的运行状态如cpu、内存、网络等,应用监控指标为应用的运行状态如接口响应时长,线程池情况,jvm运行情况等。
资源监控方面,我们对社区的NodeExporter进行定制化开发,使其可以通过Eureka进行服务发现。
应用监控方面,除了利用社区JmxExproter,我们提供了一套标准化的应用监控SDK,即插即用,提供了丰富的应用状态监控指标,包括节点运行情况,接口运行情况,线程池运行情况,JVM运行情况,队列监控,信号量监控和熔断监控。
在此基础上,我们提供标准的容器镜像,内置所需的各种agent或exporter,业务应用无需关注基础监控功能。
- job_name: jvm-exporter
relabel_configs:
- source_labels: [__meta_eureka_app_name]
separator: ;
regex: (.*)
target_label: service
replacement: $1
action: replace
- source_labels: [service]
separator: ;
regex: ^GATEWAY.*
replacement: $1
action: drop
- source_labels: [instance]
separator: ;
regex: ^gateway_.*
replacement: $1
action: drop
- source_labels: [__meta_eureka_app_instance_ip_addr]
separator: ;
regex: (.*)
target_label: __address__
replacement: ${1}:16666
action: replace
eureka_sd_configs:
- server: http://eureka-ip:8761/eureka
refresh_interval: 30s
- job_name: node_exporter
relabel_configs:
- source_labels: [__meta_eureka_app_name]
separator: ;
regex: (.*)
target_label: service
replacement: $1
action: replace
- source_labels: [service]
separator: ;
regex: (NODE_EXPORTER)
replacement: $1
action: keep
- source_labels: [__meta_eureka_app_instance_ip_addr]
separator: ':'
regex: (.*)
target_label: __address__
replacement: $1:9100
action: replace
eureka_sd_configs:
- server: http://eureka-ip:8761/eureka
refresh_interval: 30s
- job_name: msp-eureka
honor_timestamps: true
params:
module:
- tcp_connect
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /probe
scheme: http
relabel_configs:
- source_labels: [__meta_eureka_app_name]
separator: ;
regex: (.*)
target_label: service
replacement: $1
action: replace
- source_labels: [service]
separator: ;
regex: ^GATEWAY.*
replacement: $1
action: drop
- source_labels: [instance]
separator: ;
regex: ^gateway_.*
replacement: $1
action: drop
eureka_sd_configs:
- server: http://eureka-ip:8761/eureka
refresh_interval: 2m
统一告警管理
Prometheus官方提供了告警组件AlterManager进行告警管理,AlertManager用于处理客户端应用程序(如Prometheus)的警报。AlterManager支持分组,抑制,静默等特性,它还负责将其发送给下游处理(例如电子邮件,Slack,Pager Duty)。
Alertmanager虽然已经比较优秀了,但是在落地的过程中,存在以下问题:
-
缺失个性推送。做为企业级应用,我们不同应用的告警信息需要推送到对应的oncall人员。
-
警规则变更需要逐个修改Prometheus配置文件,告警配置繁琐,运维压力大。
-
Alertmanager 虽然支持许多通知方式,但企业会有自身的告警通知方式,对我们来说不支持行内的统一告警平台和员工APP。
-
此外,一个完善的报警系统,势必要支持报警分析,针对过去时间维度的报警,做一些比如topK的分析,有助于指导运维方向。目前Alertmanager没有将历史报警做持久化处理。
为了解决以上问题,我们要对Prometheus监控体系进行扩展。一种方案是fork源码,扩展功能,另一种是增加自有组件来扩展功能。考虑到社区的快速迭代,产品后续的持续更新,以及技术栈的差异,我们选择了增加自有组件来扩展功能。
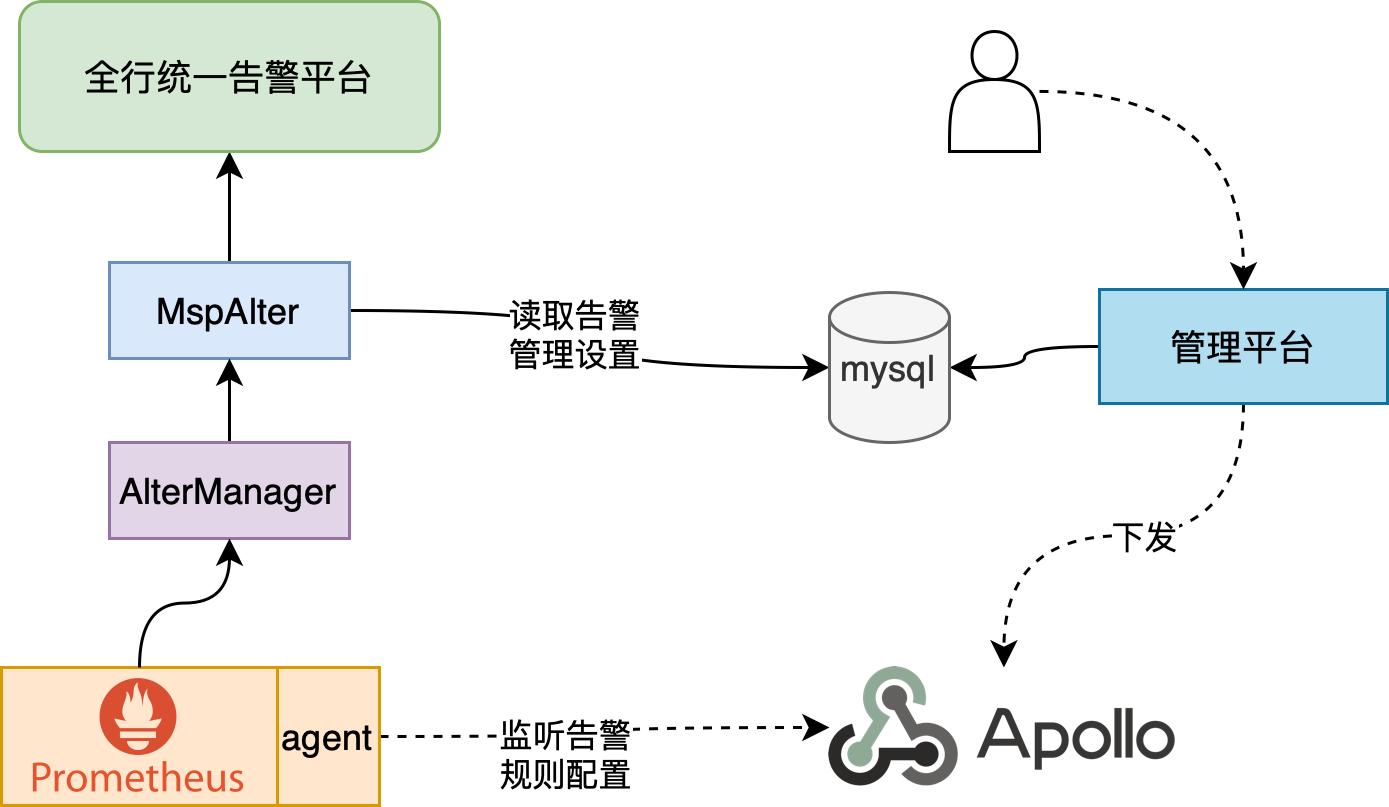
我们微服务平台提供了功能完善的服务治理体系,构建了注册中心、配置中心、认证中心等基础组件,借助这些组件我们可以方便的对Prometheus告警体系进行增强。我们开发了Prometheus-agent和MspAlter来增强告警功能,达到企业级要求,架构如下如所示。
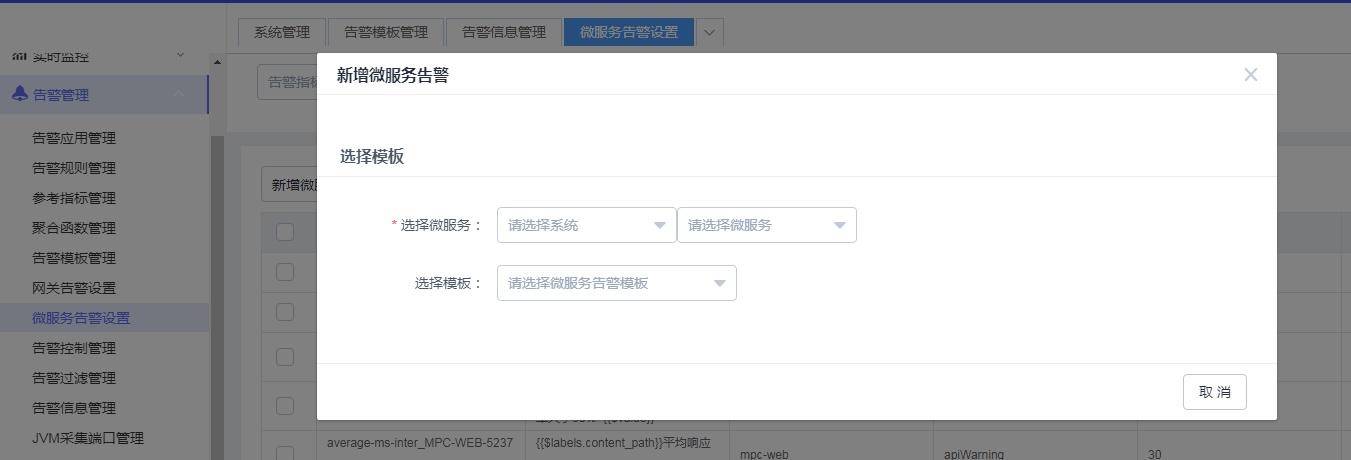
我们在管理平台抽象出了告警应用、告警模板、告警函数、告警规则等概念,屏蔽了Prometheus的rule表达式,实现了告警规则的可视化流程化设置。如下图所示,选择一个微服务和模板即可生成告警规则。
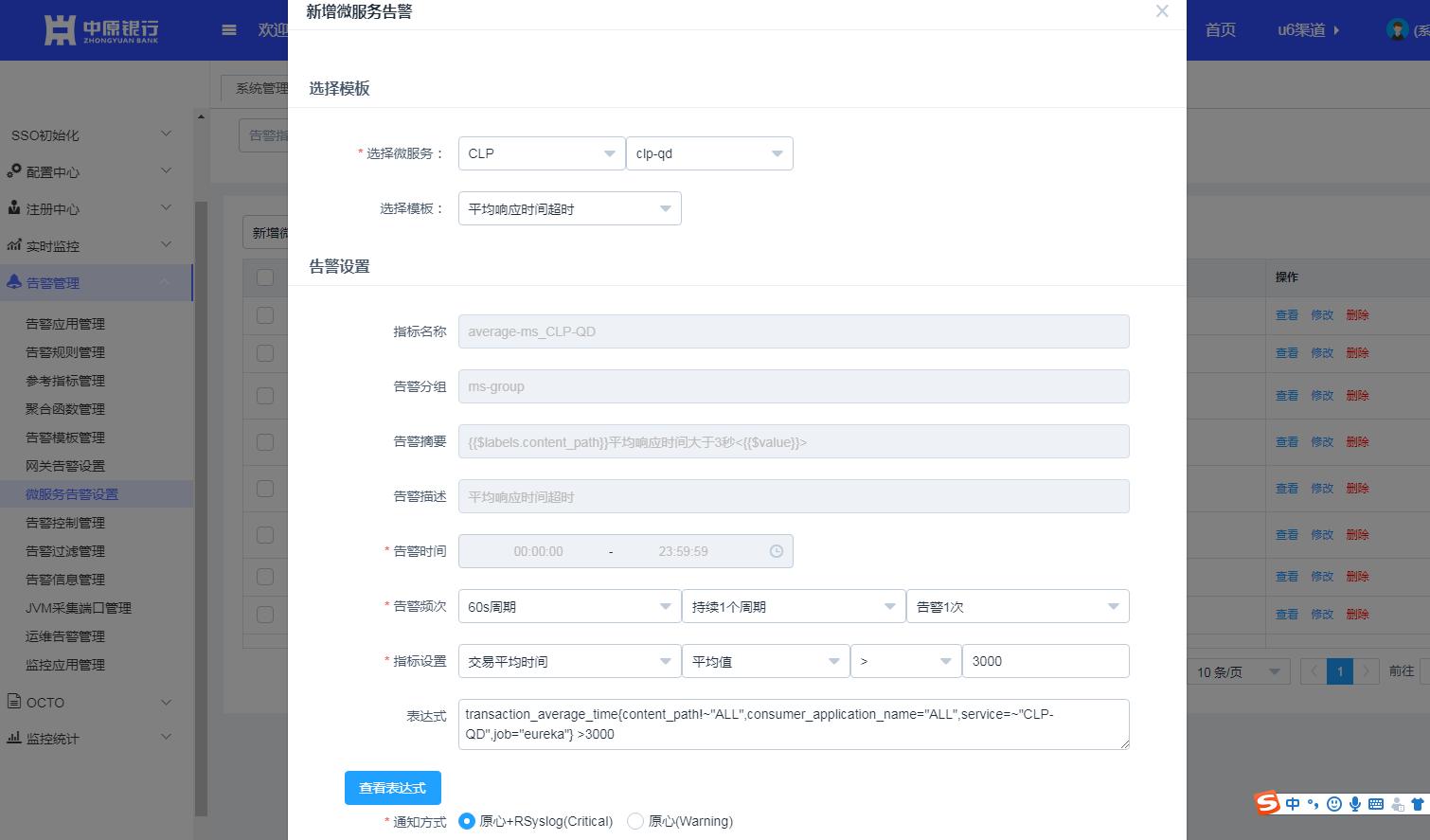
管理平台进一步将翻译后的告警规则下发至apollo配置中心,Prometheus-agent监听配置变化,实时修改Prometheus配置文件。
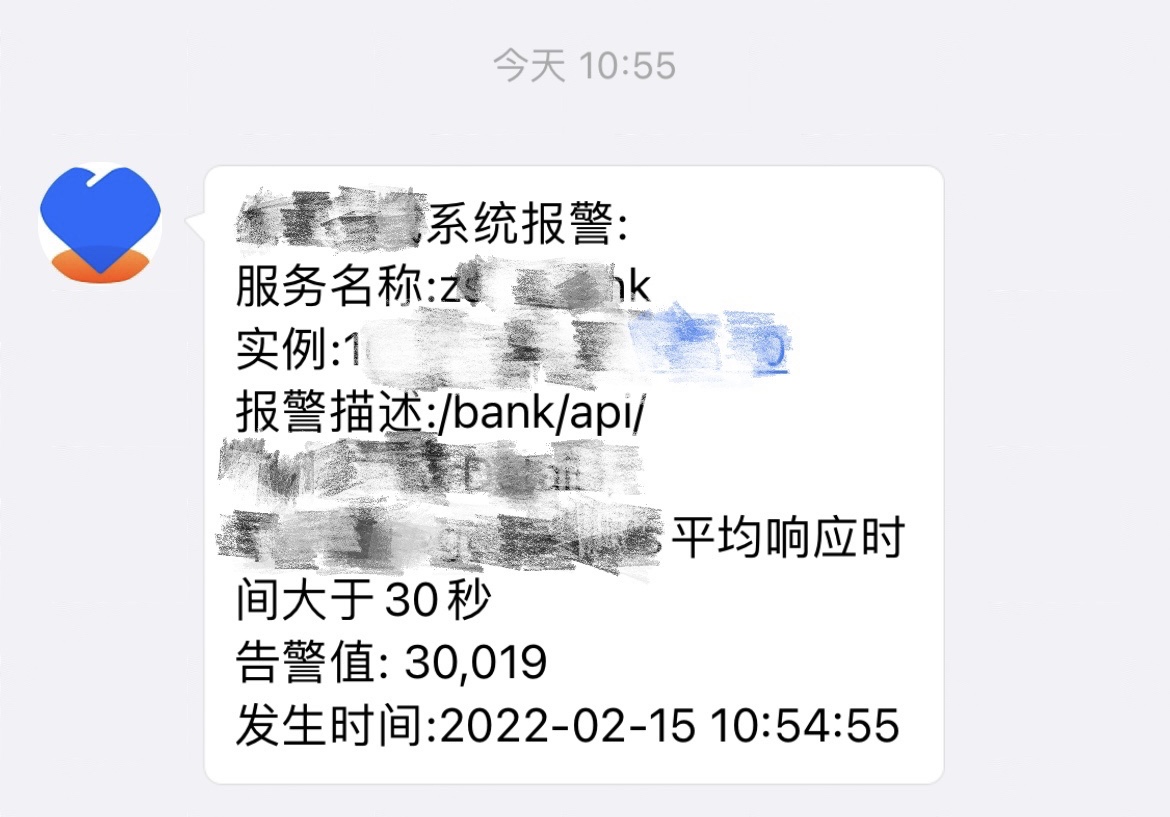
MspAlter组件对AlterManager推送的告警做进一步的处理,包括告警过滤,定时开启告警,告警持久化存储,告警信息格式转换以适配统一告警平台和员工APP,以及根据告警来源推送至对应人员等功能。下图为员工APP中收到的告警信息。
Prometheus自身的时序数据库TSDB是一个单机的数据库,不支持分布式是其天生的劣势。当你的metrics 数量足够多的时候,单机Prometheus就显得捉襟见肘。Prometheus中的内存使用量与存储的时间序列数量成正比,并且随着时间序列数量的增加,Prometheus会OOM。具有数百万个指标的Prometheus可以使用超过100GB的RAM,很多时候我们受限制于一些主机本身的大小,我们无法不断的通过纵向调整机器大小来解决这个问题。因此解决Prometheus的扩展性,是打造企业分布式监控平台的关键。
Prometheus官方的解决方案是联邦,主要提供了分层联邦和跨服务联邦(联邦官方文档)。本质上就是采集级联,说白了就是 a 从 b,c,d那里再采集数据过来,其实有很大的问题,本质上Prometheus的单机能力依旧没有得到解决。
我们最初的方案是利用remote_read功能,将Prometheus分为查询节点和采集节点,来解决高可用和全局查询的问题。采集节点按模采集监控指标并触发告警,查询节点从各个采集节点查询并merge数据,不存储数据。
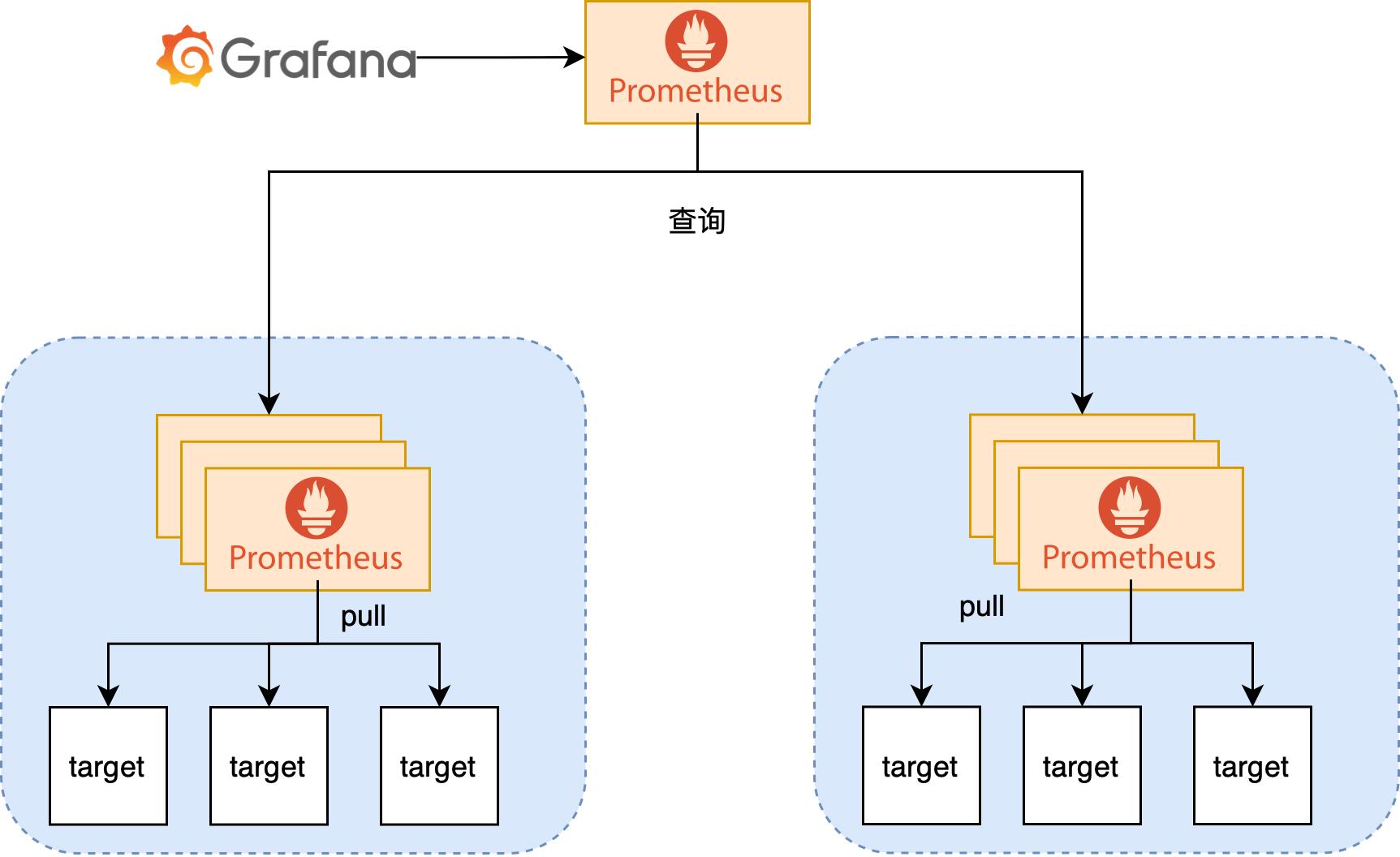
这种架构同样有一些不可避免的缺点:
-
并发查询必须要等最慢的那个返回才返回,所以如果有个慢的节点会导致查询速度下降。
-
应对重查询时可能会把query打挂,但也正是这个特点,会很好的保护后端存储分片,重查询的基数分散给多个采集器了。
-
由于是无差别的并发query,也就是说所有的query都会打向所有的采集器,会导致一些采集器总是查询不存在他这里的数据。
随着监控节点的不断增加,我们遇到了性能瓶颈,在做一些重查询,比如api网关接口耗时topN时,查询速度缓慢,甚至qurey节点OOM。所以我们继续进行架构调整以适应不断提升的监控需求。
针对Prometheus的集群扩展问题,业内主要有远端存储和开源监控套件两类解决方案:
-
远端存储:借助prometheus remote_write API将监控数据写入远端存储(通常是分布式时序数据库如influxDB、M3DB、VictoraMetrics等),prometheus负责采集和告警,存储和查询使用远端存储。
-
监控套件:业内为了解决prometheus集群功能欠缺的问题,开发了Thanos 、Cortex 等监控套件(依赖于对象存储),与原生 Prometheus 结合,满足了长期存储 + 无限拓展 + 全局视图 + 无侵入性的需求。
我们重点调研测试了VictoriaMetrics和Thanos两个解决方案。
Thanos
Thanos 也是一个CNCF基金会下管理的项目。Thanos利用Prometheus 2.0存储格式以经济高效的方式将历史指标数据存储在任何对象存储中,Thanos 整体架构图如下:
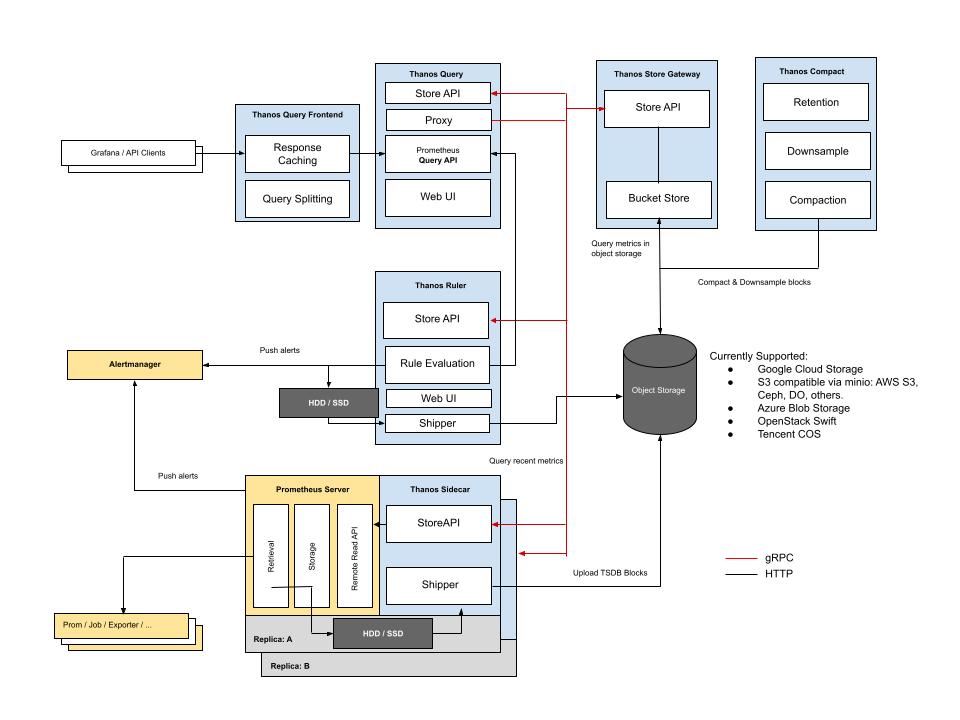
从架构图就可看出其组件比较复杂,这里就不在一一赘述,有兴趣的同学可以到其官网了解。Thanos 解决了Prometheus的集群缺失问题,与原生 Prometheus 结合,满足了长期存储 + 无限拓展 + 全局视图 + 无侵入性的需求,但维护成本比较高,如果你在一些非云的环境中,需要自己提供一套对象存储。
VictoriaMetrics
VictoriaMetrics是一种快速,经济高效且可扩展的时间序列数据库,可用作Prometheus的长期远程存储。
VictoriaMetrics 包括了如下的组件:
-
vmstorage -- 存储数据。
-
vminsert -- 通过remote_write API接收来自Prometheus的数据并将其分布在可用的vmstorage节点上。
-
vmselect -- 通过从vmstorage节点获取并合并所需数据,通过Prometheus查询API执行传入查询。
他是一种无共享架构(Shared-nothing_architecture),每个组件可以使用最合适的硬件配置独立扩展到多个节点。
整体架构图如下:
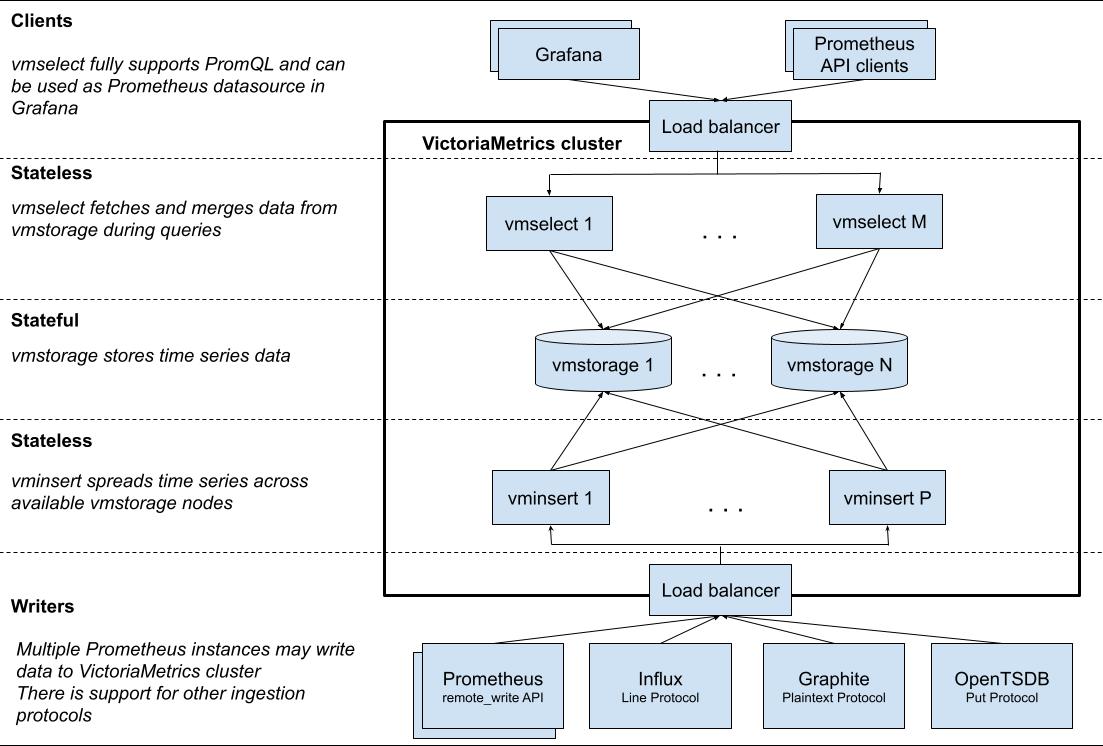
该系统的优势是架构简单,提供单节点和集群两种部署模式,无需额外组件,启动二进制文件即可完成部署。扩展性好,集群模式下,各个组件可独立扩容。性能优异,借鉴clickhouse的思想的列式存储,官方测试相较Prometheus和Thanos数据压测7倍,在写入和查询性能上相比InfluxDB和TimescaleDB有20倍的性能优势;在处理百万级别时间序列时,内存使用比 InfluxDB小十倍,比 Prometheus、 Thanos小七倍。
我们在测试环境8C32G虚拟机搭建VictoriaMetrics单节点应用,秒增5万数据点,CPU平均使用率5%,峰值15%,内存平均6.75G,峰值8.5G;预铺30天数据,查询耗时99%峰值3s。
总的来说,两者均对Prometheus生态有较好的兼容性,支持promtheus查询api,支持全局查询视图,支持prometheus HA去重。Thanos组件比较复杂,维护成本比较高,如果公司已有对象存储,或在公有云部署可以省去对象存储的运维工作。VictoriaMetrics架构简单,性能优异,也有较好的可扩展性和高可用性。
我们最终选择VictoriaMetrics作为Prometheus数据的持久化存储和查询数据库。 逻辑架构如下图所示:
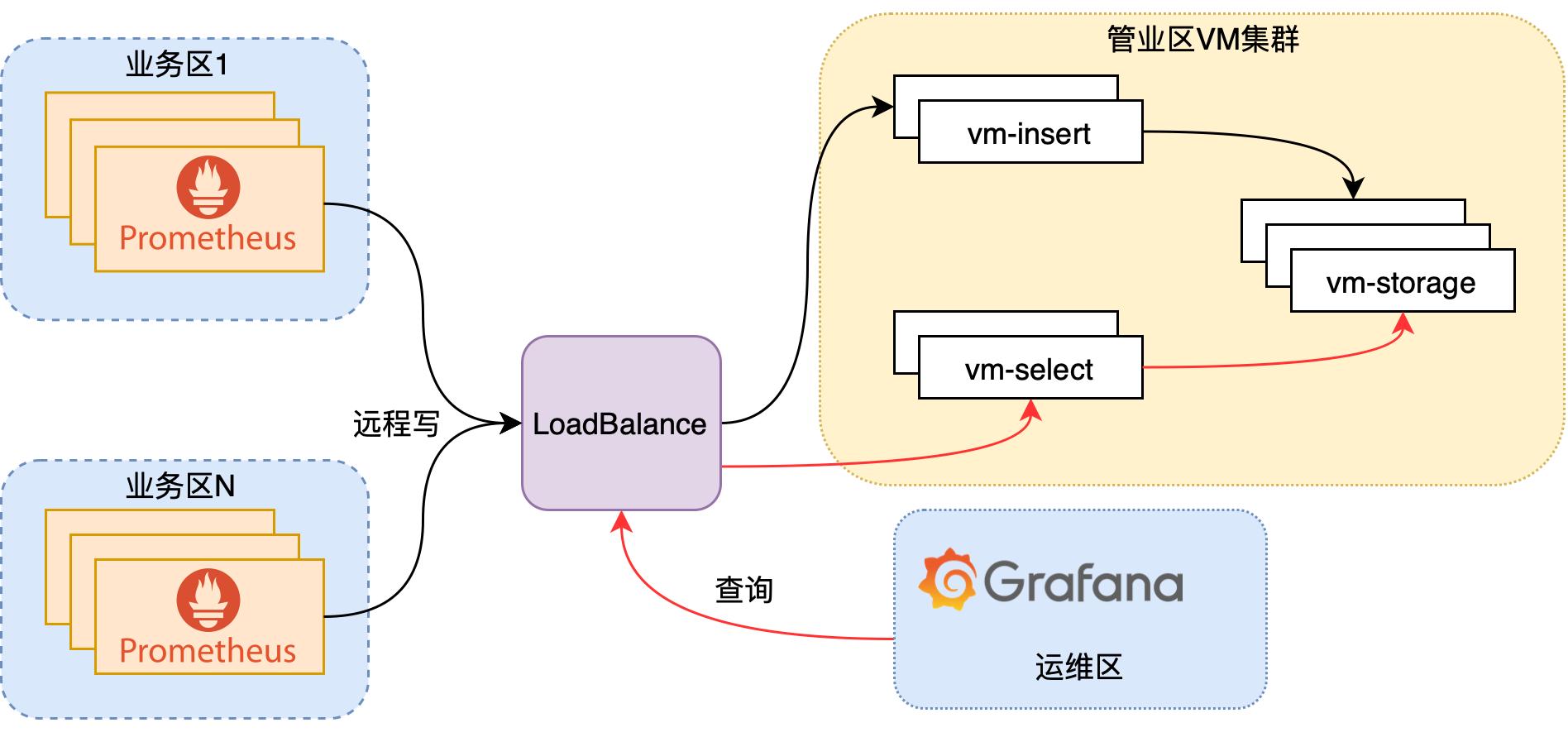 我们在生产环境使用四台中配虚机(4C16G)部署insert和select节点,三台高配虚机(8C32G)部署storage节点,单副本存储。除了搭建VM集群,仅需在Prometheus配置中增加远程写,Grafana中修改数据源。在秒增10万数据点压力下,长期运行稳定无异常。以较小的代价,实现了业务目标。
我们在生产环境使用四台中配虚机(4C16G)部署insert和select节点,三台高配虚机(8C32G)部署storage节点,单副本存储。除了搭建VM集群,仅需在Prometheus配置中增加远程写,Grafana中修改数据源。在秒增10万数据点压力下,长期运行稳定无异常。以较小的代价,实现了业务目标。
总结与展望
未来Prometheus生态体系仍将是云原生监控的主流解决方案,企业级的落地要根据自身场景,做出适当的扩展和选型。 架构的演进不是一蹴而就的,随着业务的增长,当时合理的一些决策,在当前的场景下会变得不再适用。未来随着target数量的增长以及种类的增多,Prometheus节点的动态扩容和target的动态调度是我们面临的一个痛点,也是后续需要重点解决的问题。
参考
https://github.com/tkestack/kvass/blob/master/README_CN.md