




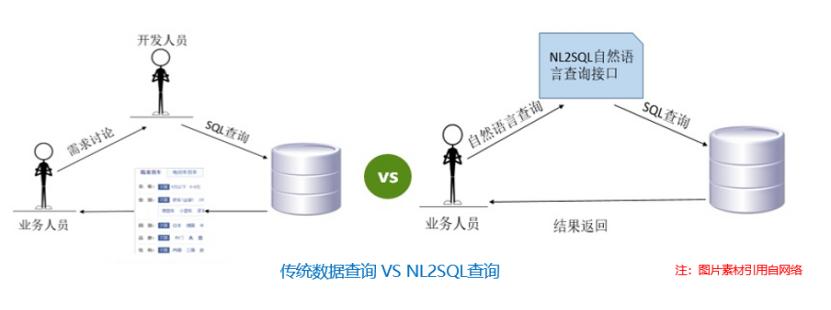
1、场景介绍
某银行业务人员想要查询某款理财产品中原财富1号9月销售额度,对于数据工程人员则会考虑写一个SQL语句:
Select sum(sale) from table_name where month= 9 and product_name =‘中原财富1号’
业务人员一般不具有SQL编程能力,而对于上述这些语句比较简单,但问题发散的场景,业务人员想要查询相应的结果需要找到数据工程人员完成相关流程。流程比较繁琐,而通过nl2sql技术,则可直接将问题转换成相对应的SQL语句用于相关表的查询并返回结果,因此nl2sql可被用于问答系统,通过配合相关规则及其他语义模型,能够对一些简单常见的用户问题转换成相应的SQL。
2、关于NL2SQL的介绍
2.1 什么是NL2SQL
NL2SQL(Natural Language to SQL), 顾名思义是将自然语言转为SQL语句。它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。
2.2 NL2SQL的目标与定位
从技术的角度来看,NL2SQL的本质是将用户的自然语言语句转化为计算机可读懂、可运行、符合计算机规则的语义表示,同时需要计算机理解人类的语言,生成准确表达语句语义的可执行程序式语言。其定位是语义分析领域的一个子任务。
2.3 NL2SQL的数据集
1. 英文nl2sql数据集
nl2sql的开源数据集,目前比较火的英文数据集有WikiSQL、Spider、WikiTableQuestions、ATIS等,各个数据集都有各自的特点,下面简单介绍下这几个数据集。
WikiSQL:该数据集是Salesforce在2017年提出的大型标注nl2sql数据集,也是目前规模最大的nl2sql数据集。它包含了 24,241张表,80,645条自然语言问句及相应的SQL语句。目前学术界的预测准确率可达91.8%。
Spider:Spider数据集是耶鲁大学于2018年新提出的一个较大规模的nl2sql数据集。该数据集包含了10,181条自然语言问句,分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。虽然在数据数量上不如WikiSQL,但Spider引入了更多的SQL用法,例如Group By、Order By、Having等高阶操作,甚至需要Join不同表,更贴近真实场景,所以难度也更大。目前准确率最高只有54.7%。
WikiTableQuestions:该数据集是斯坦福大学于2015年提出的一个针对维基百科中那些半结构化表格问答的数据集,内部包含22,033条真实问句以及2,108张表格。由于数据的来源是维基百科,因此表格中的数据是真实且没有经过归一化的,一个cell内可能包含多个实体或含义,比如「Beijing, China」或「200 km」;同时,为了很好地泛化到其它领域的数据,该数据集测试集中的表格主题和实体之间的关系都是在训练集中没有见到过的。
The Air Travel Information System (ATIS):ATIS是一个年代较为久远的经典数据集,由德克萨斯仪器公司在1990年提出。该数据集获取自关系型数据库Official Airline Guide (OAG, 1990),包含27张表以及不到2,000次的问询,每次问询平均7轮,93%的情况下需要联合3张以上的表才能得到答案,问询的内容涵盖了航班、费用、城市、地面服务等信息。
Github地址:
WikiSQL:https://github.com/salesforce/WikiSQL
Spider:https://yale-lily.github.io/spider
ATIS:https://www.kaggle.com/siddhadev/ms-cntk-atis
WikiTableQuestions:https://github.com/ppasupat/WikiTableQuestions
2. 中文nl2sql数据集
中文数据集目前只有追一科技在天池发布的比赛数据集,包括4万条有标签数据作为训练集,1万条无标签数据作为测试集。目前比赛第一名的成绩,准确率达到了92%。
3、 基于深度学习的nl2sql数据格式
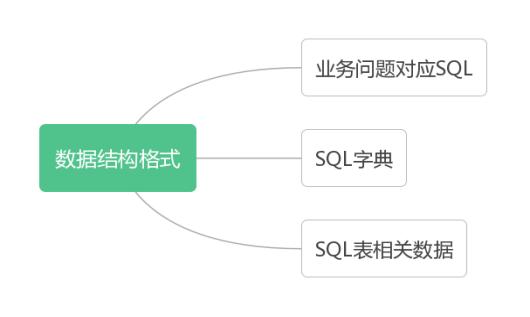 如上图所示,构建基于深度学习的nl2sql训练数据,主要包括三部分:业务问题对应的SQL信息,SQL字典,SQL表数据。下面分别介绍相应的数据格式
如上图所示,构建基于深度学习的nl2sql训练数据,主要包括三部分:业务问题对应的SQL信息,SQL字典,SQL表数据。下面分别介绍相应的数据格式
3.1 业务问题对应的的SQL
首先来看一下SQL相关的符号字典
op_sql_dict = {0:">", 1:"<", 2:"==", 3:"!=", 4:"不被select"} #判断符号 agg_sql_dict = {0:"", 1:"AVG", 2:"MAX", 3:"MIN", 4:"COUNT", 5:"SUM", 6:"不被select"} #聚合函数符号
conn_sql_dict = {0:"", 1:"and", 2:"or"} #条件逻辑关系
基于符号字典的描述格式为
{
"table_id": "a1b2c3d4", # 相应表格的id
"question": "", # 自然语言问句
"sql":{ # 真实SQL
"sel": [1], # SQL选择的列
"agg": [4], # 选择的列相应的聚合函数, '0'代表无
"cond_conn_op": 1, # 条件之间的关系
"conds": [[6,2,'2016'],[7,2,'融资收购其他资产']]
#其中[6,2,2016]分别表示[条件列,条件符号类型,条件值]
} }
下面看一个实际案例:
(1)业务问题为
净资产收益率达到25以上或者季度每股盈余达到2以上的有哪些证券?
(2)对应的SQL为
select col_1 from Table_43b0a2f31d7111e9b86df40f24344a08 where col_3 > "25" or col_4 >"2"
(3)描述格式
{ "table_id": "43b0a2f31d7111e9b86df40f24344a08",
"question": "净资产收益率达到25以上或者季度每股盈余达到2以上的有哪些证券?",
"sql": {
"agg": [0], #不做聚合
"cond_conn_op": 2, #选择条件是或
"sel": [1], #选择第1列
"conds": [
[3, 0, "25"], #第3列大于25
[4, 0, "2"] #第4列大于2 ]}}
3.2 SQL相关表信息
(1)如表二所示,为上述SQL业务问题对应的表
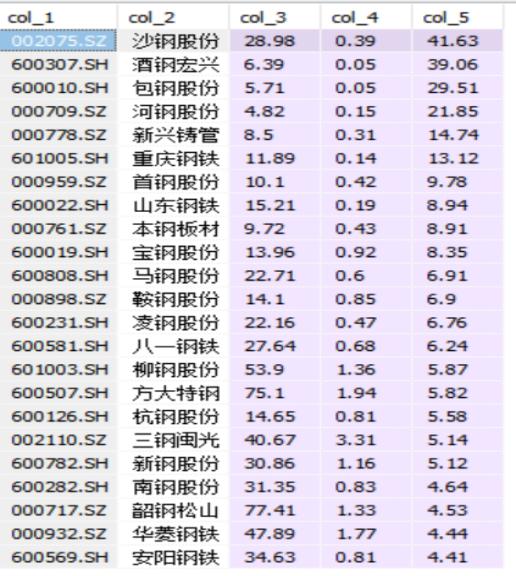
表二
(2)SQL相关表的格式
{ "rows": [
["002075.SZ", "沙钢股份", 28.98, 0.39, 41.63],
["600307.SH", "酒钢宏兴", 6.39, 0.05, 39.06],
["600010.SH", "包钢股份", 5.71, 0.05, 29.51],
["000709.SZ", "河钢股份", 4.82, 0.15, 21.85],
["000778.SZ", "新兴铸管", 8.5, 0.31, 14.74],
["601005.SH", "重庆钢铁", 11.89, 0.14, 13.12],
["000959.SZ", "首钢股份", 10.1, 0.42, 9.78],
["600022.SH", "山东钢铁", 15.21, 0.19, 8.94],
],
"header": ["证券代码", "证券简称", "ROE(TTM)", "EPS(TTM)", "PE(对应2018.10.31收盘价)"],
"id": "43b0a2f31d7111e9b86df40f24344a08", }
对应的SQL格式为:
`SELECT agg COLUMN_NAME1****
FROM TABLE_NAME****
WHERE COLUMN_NAME2 op VALUE1 conn COLUMN_NAME3 op VALUE2`
其中agg为agg_sql_dict中字典中的值,op为op_sql_dict字典中的值,conn为conn_sql_dict中的值
4、基于bert的nl2sql模型
4.1 NL2SQL实现简述
对于nl2sql的各个系统,在内部实现上,整体结构都大同小异,只是技术不同罢了。图二描述了从Question到SQL生成的核心细节,简单来说,整个系统将nl2sql分成了SQL几个子句的识别,包括SELECT clause、WHERE clause,当然可能还有group by、limit等等。每个部分又会牵扯很多的细节,比如table识别,属性识别,适当的添加索引等等。图二是采用深度学习方法,通过encoder-decoder的方式进行nl2sql的实现。Google的Analyza采用的则是语义解析和规则的方式构建的,paper中解释主要还是因为数据的问题。
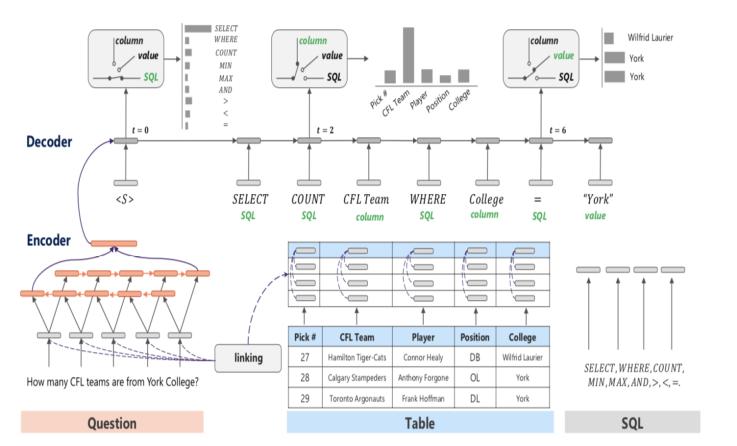
图二
4.2 NL2SQL深度模型简述
本文介绍基于bert的nl2sql模型,bert模型是GOOGLE公司的AI团队于2018年10月11日发布,在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩:全部两个衡量指标上全面超越人类,并且还在11种不同NLP测试中创出最佳成绩,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进率5.6%)等。bert是一个深层的基于Transformer结构模型,其结构只包含了Transformer结构的encode部分,是一个预先经过大量语料训练的预训练模型,主要包括掩码损失函数与用于预测上下句之间是否有逻辑关系的损失函数。在基于预训练bert模型的基础上,我们可以针对特定场景fine-tune模型,比如文本分类,自然语言推理,文本序列标注,其模型结构如图三所示。
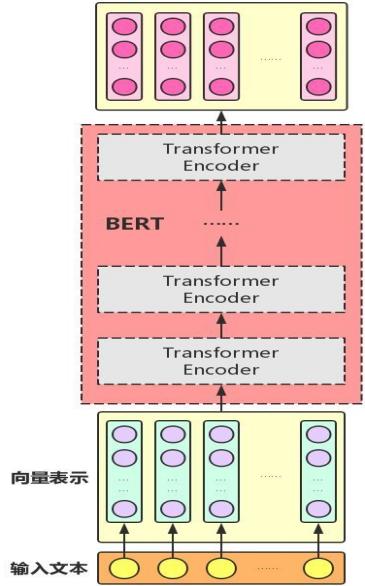
图三
本文实践基于追一科技在天池发布的开源中文比赛数据集,并应用科学空间博主苏剑林发表的《基于Bert的nl2sql模型》,并借鉴参考了nl2sql比赛第一名与第三名的相关技术方案及思路,以及tong guo等于2019年发表的论文《Content Enhanced BERT-based Text-to-SQL Generation》。其整体技术方案为在bert模型的基础上进行fine-tune,使用四个子模型,主要包括select部分的预测,where部分的连接条件,where部分的运算符号,where部分的条件列与条件值,如图四所示。
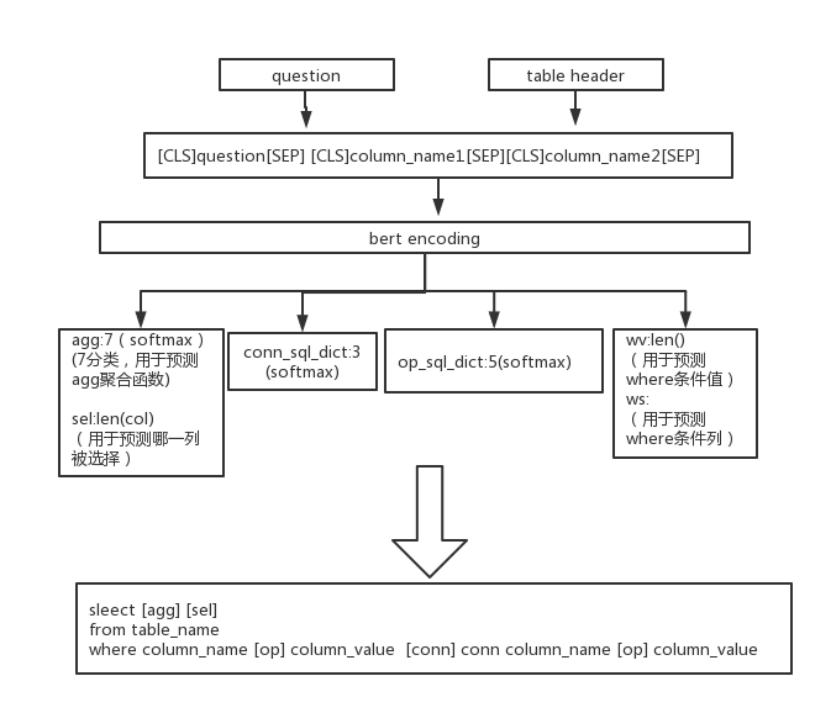
图四
在预训练bert作为整个结构的深层网络,将输入问题与相关表列的信息结构作为输入部分,本文将问题与表的结构分别用Q于H表示。
下面对各个模块进行详细介绍。
(1)bert embedding层
对于输入问题信息与表结构信息需要转换成bert的tokens,对于输入的问题信息我们用w1,w2,...,wn来表示。对于输入的表的列信息用h1,h2,...,hn来表示,然后将两部分进行concat作为bert的输入,用bert的编码格式表示如下:
[CLS]w1,w2,...,wn[SEP][CLS]h1[SEP].......,输入bert后经过bert的embedding层转换成相应的embedding层编码作为bert的多头自注意力机制与feed forward等的输入,然后进入下游子任务进行fine-tune。
(2)where部分的con操作
对于where部分的con子任务,目标是预测where部分的条件连接符操作(and,or等),用Q表示输入问题,即是第一个[CLS]对应的向量可以认为是整个问题的句向量,用H表示表的列名,通过上述特征可以用来预测conds的连接符(3分类问题)。则输入部分可以用如下表示
使用交叉熵损失函数
loss_wc = crossentropy(wc_in, wc)
(3)where部分中的运算符
对于where部分的运算符部分的任务,目标是预测条件值对应的运算符有4个,新增一类代表当前字不被选中,其它类别则是选中且对应某个运算符。QV表示问题的外的其他输入特征,其形式为:
使用交叉熵损失函数
loss_wo = crossentropy(wo_in, wo)
此外需要对输入问题特征进行mask处理,xm为列的mask,其shape为 shape=mask.shape=(None, x_len):
loss_wo = sum(loss_wo * xm) / sum(xm)
(4)where部分中的条件列选择
用Q表示输入问题,用H表示表的列名,QV表示如问题的外的其他输入特征,HV表示除了列名外的其他特征,其输入形式如下表示:
P(ws,wv|Q,H,QV,HV)
使用交叉熵损失函数:
loss_ws = crossentropy(WS_in, WS)
并同时对输入模型的问题特征向量与表列名称向量做mask处理:loss_ws = sum(loss_ws * xm * cm) / sum(xm * cm)
(5)select部分
对于select部分的子任务,目标是预测select部分的列值与select部分的agg值。用sc表示用来预测select部分的列值,用sa表示select部分的agg对应值。用Q表示输入问题,用H表示表的列名,即后面的每个[CLS]对应的向量,每个表头的编码向量,用来预测该表头表示的列是否应该被select和agg(7分类问题),HV表示除了列名外的其他特征,则输入部分可以用如下表示:
P(sa,sel|Q,H,HV)
使用交叉熵损失函数:loss_sel = crossentropy(sel_in, sel)
此外需要进行列名的mask处理,hm为列的mask,其shape为mask.shape=(None, h_len)loss_sel = sum(psel_loss * hm) / sum(hm)
最终的损失函数为loss_wc+loss_wo+loss_ws+loss_sel。模型的优化器可使用Adam优化器,是目前深度模型常用的优化器,包含两阶动量对梯度进行处理,其算法流程图如图五。

图五
相比较于Adadelta和RMSprop优化器,除了存储了过去梯度的平方vt的指数衰减平均值,也像momentum一样保持了过去的梯度mt的指数衰减平均值。因此对于稀疏数据来说,使用Adam是比较好的选择。
5、模型部署测试
本文部署nl2sql使用了微服务架构,采用kubernetes+docker+gunicorn+flask的架构,将模型发布成为restful Api接口的形式用以给工程端进行调用。其Kubernetes常用的架构如图六所示
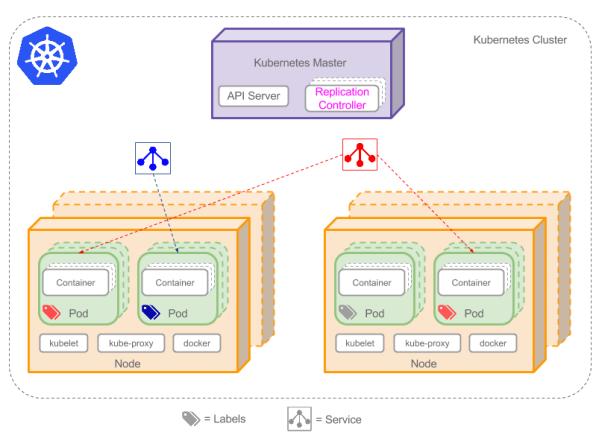
图六
本项目采用的部署方案具体流程如图七
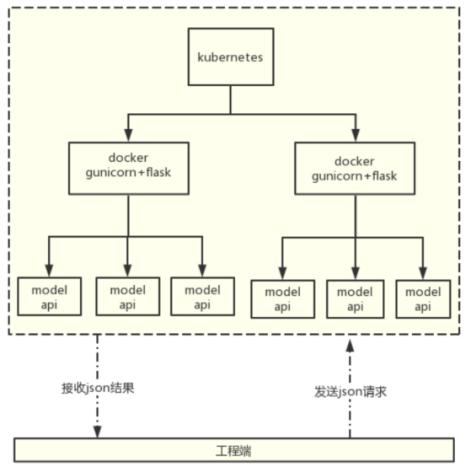
图七
其中工程端发送的json数据格式如图八所示

图八
通过模型计算返回的json结果如图九所示,其中sql_pred字段即为模型预测返回结果。
(注:文本实践中为了验证模型,对数据进行了随机抽取,因此是基于小样本学习,没有进行系统性调参,预测结果会出现偏差。在服务器上使用GPU进行全样本大规模多轮迭代会大幅提升准确率)

图九
6、应用现状与未来展望
nl2sql技术当前由于数据的问题暂时没有应用到业务当中,对于未来业务应用的规划其相关技术可作为智能问答系统的一项辅助技术。当用户提出的问题在问答知识库中找不到相关答案,且通过语义相似模型找不到相似问题,则可再通过nl2sql模型再进行预测如图十。此外基于上文提到的论文及优化方案,可对模型进行大幅优化。
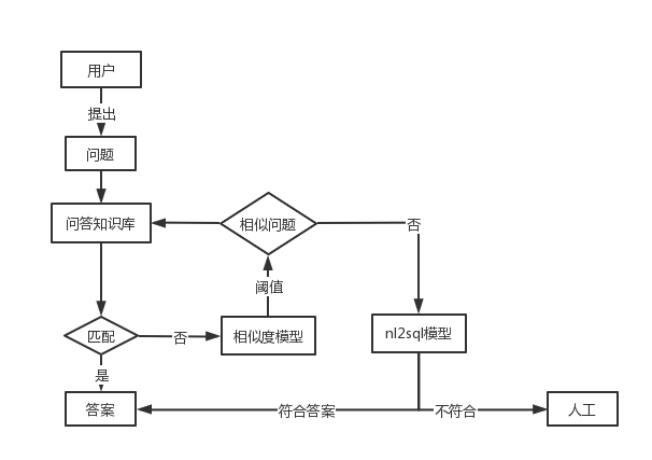
图十
本文主要介绍了nl2sql的背景,发展历程,相关数据集。详细介绍了构建nl2sql模型的特征工程过程,基于bert构建nl2sql模型的原理,及采用微服务架构部署模型的相关技术方案,并针对nl2sql对于未来业务问答系统的架构做了一个规划。
目前尽管有着各色的数据库,但访问和操作数据库的SQL是通用的。人性化的编程语言SQL为开发者在工作中访问数据库提供了便利,但同时也限定了非专业用户按需查询数据库的场景。随着人工智能在机器视觉领域取得突破进展,结合了人工智能与NLP的NL2SQL为非专业用户查询数据库提供了新的思路。