




作者:任静思,火山引擎云原生工程师
本文整理自火山引擎开发者社区 Meetup 第八期演讲,主要介绍了字节跳动轻量级 Kubernetes 多租户方案 KubeZoo 的适用场景和实现原理。
Kubernetes 多租户模型
伴随着云原生技术的发展和推广,Kubernetes 已经成为了云计算时代的操作系统。在主机时代,操作系统有多个租户共享同一台物理机资源需求;在云计算时代,就出现了多个租户共享同一个 Kubernetes 集群的需求。在这方面,社区的 Kubernetes Multi-tenancy Working Group 定义了三种 Kubernetes 的多租户模型:
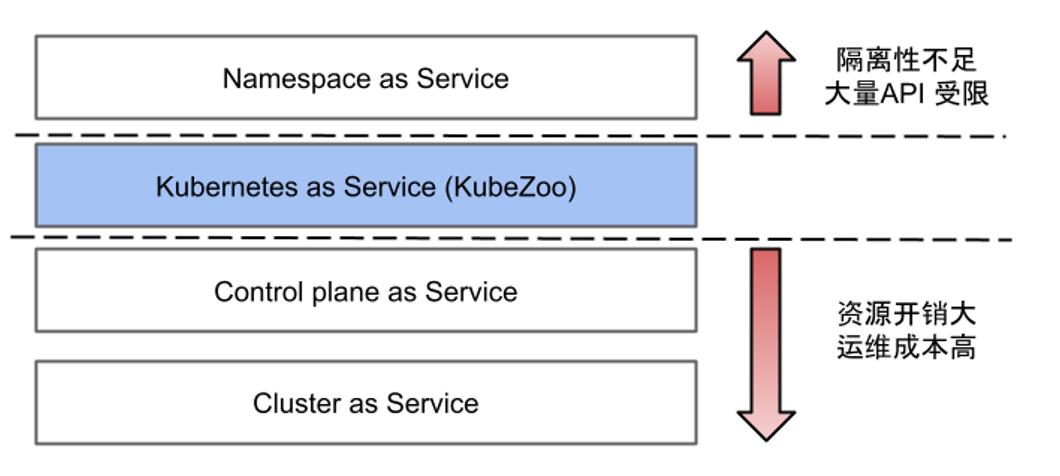
- 第一种是 Namespaces as a Service,这种模型是多个租户共享一个 Kubernetes 集群,每个租户被限定在自己的 Namespace 下,借用原生的 Namespace 的隔离性来实现租户负载的隔离租户一般只能使用 Namespace 级别的资源,不能使用集群级别的资源,它的 API 兼容性比较受限。

- 后两种模模型分别是 Clusters as a Service 以及 Control planes as a Service, 这两者都属于租户间做物理集群隔离的方案。每个租户都有独立的 Master,这个 Master 可能会通过 Cluster API 或 Virtual Cluster 等项目完成它的生命周期管理。Master 是独占的物理资源,因此每个租户都会有一套独立的控制面组件,包括 API Server、Controller Manager 以及自己的 Scheduler,每个组件还可能会有多个副本。在这种方案之下,租户之间是互相不影响的。
 为什么在现有的三种模型基础上,还需要提出一种新的多租户方案呢?
为什么在现有的三种模型基础上,还需要提出一种新的多租户方案呢?
首先我们来看 Namespaces as a Service,它的缺陷是租户没法使用集群级别的 API。比如租户内部再想细分 Namespace 或者租户想要创建 CRD 资源,这些都是 Cluster scope 的资源,需要系统管理员来协调,也就是说它的用户体验是有损的。
其次,Cluster 或 Control plane 的隔离方案引入了过多的额外开销,比如每个租户需要建立独立的控制面组件,这样就降低了资源利用率;同时大量租户集群的建立,也会带来运维方面的负担。
另外,无论是公有云还是私有云,都存在大量小租户并存的场景。在这些场景下,每个租户的资源需求量比较小,同时租户又希望在创建集群之后,能够立即使用集群。
轻量级多租户方案 KubeZoo
针对这种海量小租户并存的场景,我们就提出了一种轻量级的多租户方案——KubeZoo。
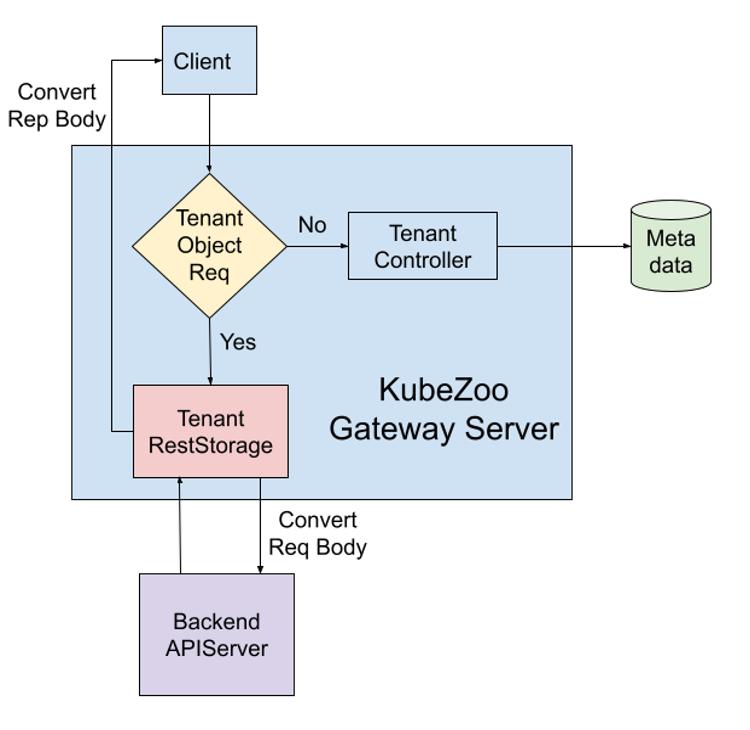
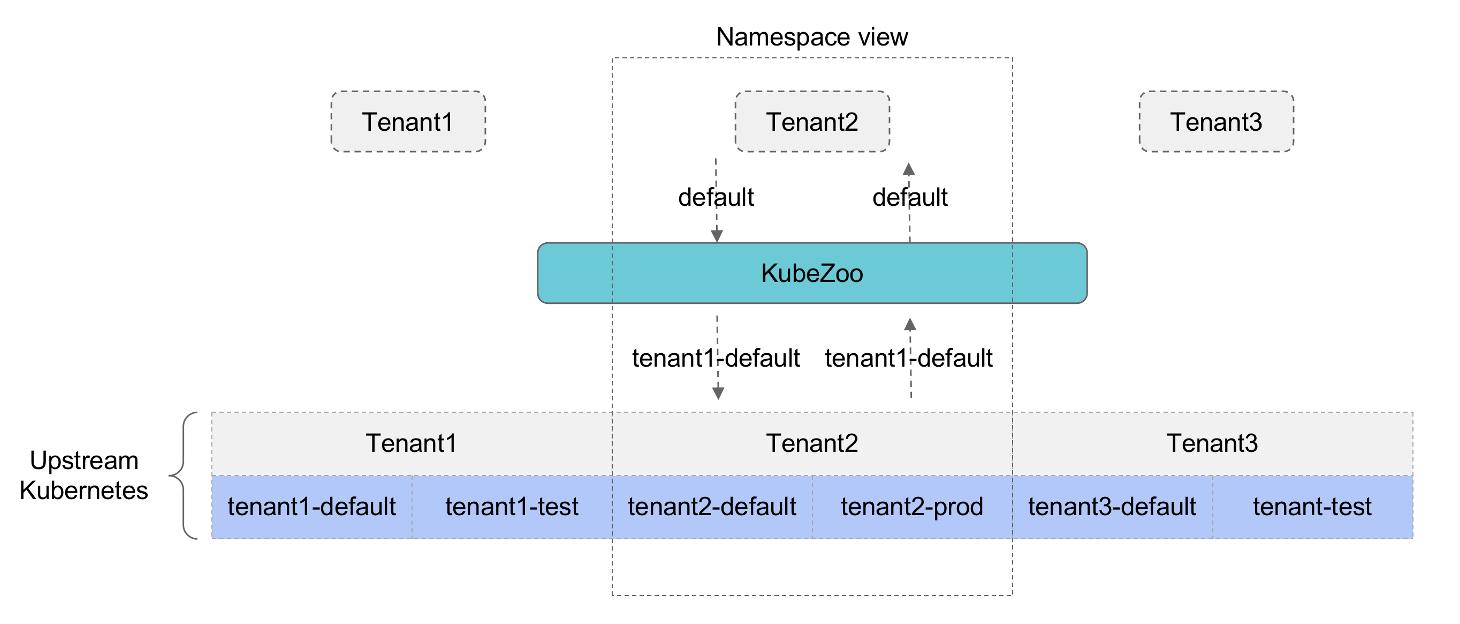 KubeZoo 作为一个网关服务,部署在 API Server 的前端。它会抓取所有来自租户的 API 请求,然后注入租户的相关信息,最后把请求转发给 API Server,同时也会处理 API Server 的响应,把响应再返回给租户。
KubeZoo 作为一个网关服务,部署在 API Server 的前端。它会抓取所有来自租户的 API 请求,然后注入租户的相关信息,最后把请求转发给 API Server,同时也会处理 API Server 的响应,把响应再返回给租户。
KubeZoo 的核心功能是对租户的请求进行协议转换,使得每个租户看到的都是独占的 Kubernetes 集群。对于后端集群来说,多个租户实际上是利用了 Namespace 的原生隔离性机制而共享了同一个集群的资源。
通过上面的架构图可以看出,KubeZoo 作为一种多租户的方案,有一些独特的特性。
-
首先 KubeZoo 能提供足够的租户隔离性:
- 每个租户的请求都经过了 KubeZoo 的预处理。不同租户之间的请求被映射到了后端集群的不同 Namespace 或者不同的 Cluster scope 的对象上,租户之间相互不干扰。
- 同时它又能够提供比较完整的 Kubernetes API,租户既能使用 Namespace 级别的资源,又能使用集群级别的资源。每个租户的体验都可以认为是自己独占了完整的 Kubernetes 集群。
- 其次,KubeZoo 是高效率的:每次添加一个新的租户之后,不必再为该租户初始化新的集群控制面,只需要在 KubeZoo 这个网关层面建立一个 Tenant 对象即可。这样就能达到租户集群的秒级创建和即刻使用的效果。
- 最后,KubeZoo 是一种非常轻量级的多租户方案。因为所有的租户共享同一个后端集群的控制面,所以它拥有非常高的资源利用率,当然运营成本也非常低。
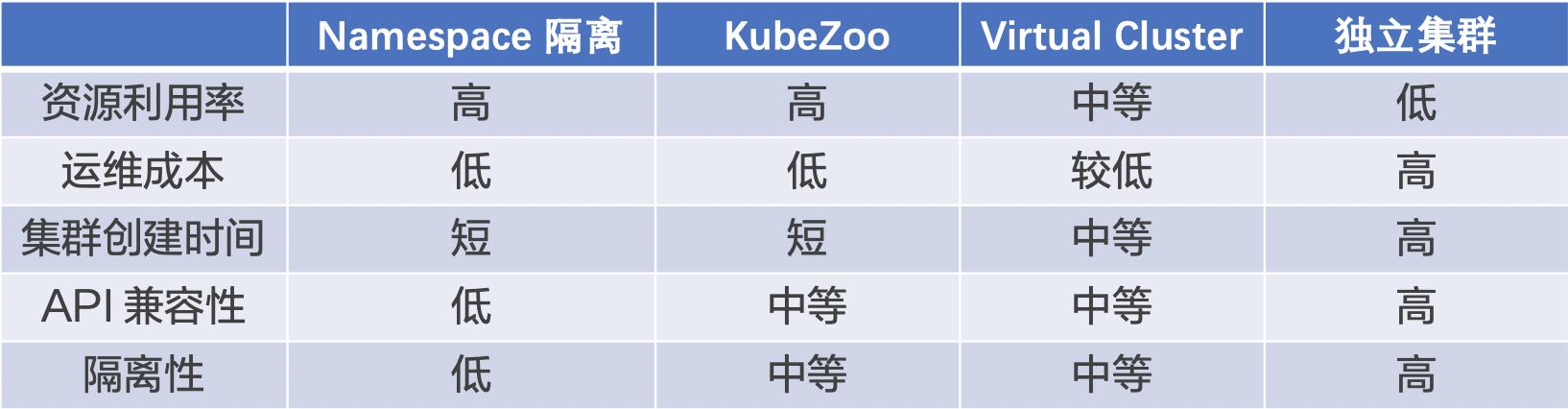 上面的表格展示了 KubeZoo 和一些现有方案的对比。
上面的表格展示了 KubeZoo 和一些现有方案的对比。
- 资源利用率:Namespace 隔离和 KubeZoo 都是共享后端集群,二者的资源利用率都是最高的; Virtual Cluster 方案需要为每个租户搭建独立的控制面,资源利用率中等;独立集群方案的资源利用率是最低的。
- 运维成本:Namespace 隔离和 KubeZoo 方案都只需要维护一个后端集群,所以运维成本最低;Virtual Cluster 方案通过 controller 维护租户控制面,运维成本较低;独立集群方案运维成本最高。
- 集群创建时间:Namespace 隔离和 KubeZoo 的租户集群创建都只需要一次 API 调用,集群创建时间最短;Virtual Cluster 方案需要启动租户控制面组件,集群创建时间中等;独立集群方案集群创建时间最长。
- API 兼容性:Namespace 隔离方案下,租户无法任意创建和使用集群级别的资源,API 兼容性是最低的;KubeZoo 和 Virtual Cluster 方案中,除了 Node, Daemonset 等节点相关的资源外,租户可以使用任意的 Namespace 级别或集群级别的资源,API 兼容性中等;独立集群方案 API 兼容性最高。
- 隔离性:Namespace 方案下的租户隔离性最低;KubeZoo 和 Virtual Cluster 方案中,租户请求会经过网关或独立的 Apiserver,隔离性中等;独立集群方案的隔离性最高。
以上各维度综合对比来看,KubeZoo 能在租户体验、集群的资源效率和运维效率之间达到平衡,尤其是在大量小租户共享资源池的情况下,具有显著的优势。
KubeZoo 关键技术细节
下面我们来看下 KubeZoo 在实现过程中的一些关键技术细节。
租户管理
KubeZoo 本身可以理解成一种特殊的 API Server,也需要自己的元数据存储服务,比如典型的我们会使用 Etcd 来存储租户相关的信息。对租户对象的管理方式和 Kubernetes 管理原生资源对象的方式是一致的。
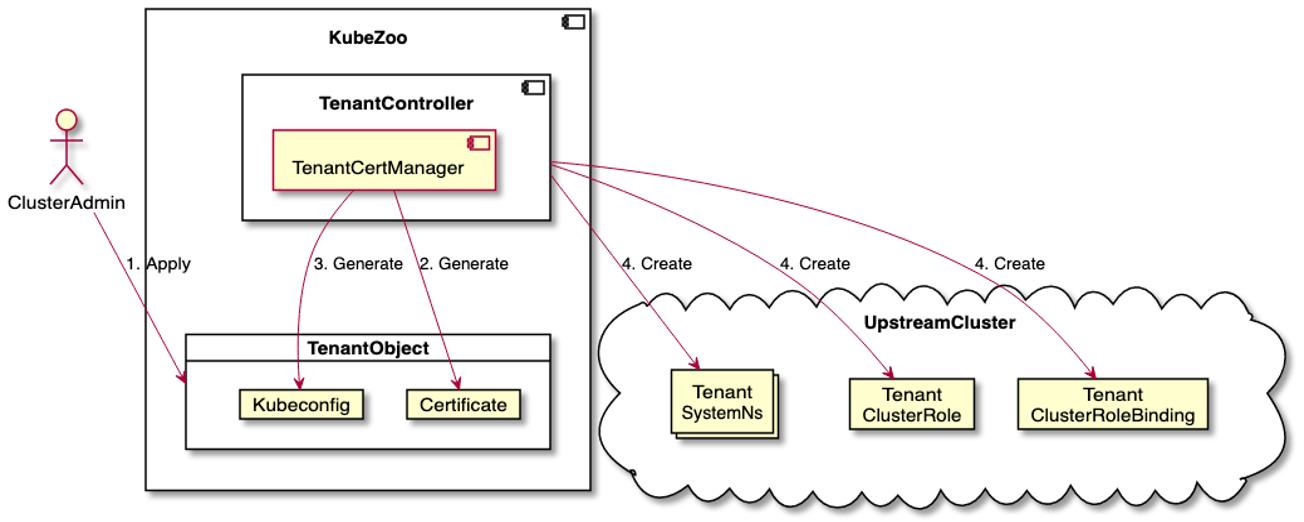
- 当管理员创建一个租户对象之后,该 TenantController 会为租户签发一个证书,证书里携带了该租户的 ID,同时也会为该租户生成对应的 Kubeconfig,写入这个 Tenant 对象的 annotation 字段中。
- 下一步,这个 TenantController 会在后端集群中为租户初始化一些相关资源,包括租户的 Namespace,管理该租户权限相关的 Role 和 Rolebinding 对象。
租户请求转换
KubeZoo 本身会同时处理两种请求:一种是来自管理员的请求,另一种是来自租户的请求。所以当一个请求到来之后,KubeZoo 会首先判断该请求是否为租户相关对象:
- 如果是处理 Tenant 对象,就直接交给 TenantController 处理,最终会存储到 KubeZoo 的 metadata server 中,即 Etcd 。
-
否则则说明是租户相关的请求,
- 这时会首先通过证书验证租户的身份,然后从证书中提取该 Tenant 的 ID,最后会通过 Tenant RestStorage 的接口转换租户请求,并发送给后端的 API Server。
- 后端 API Server 返回的响应也在经过处理之后也返回给租户。
API 对象转换
Kubernetes 的资源可以分为两类:Namespace 级别和 Cluster 级别。这两种资源对象的协议转换方式也是有所区别的:
- Namespace 级别对象:需要对资源对象的 Namespace 做转换,保证不同租户的资源在后端集群中映射到不同的 Namespace, 巧妙利用了 Kubernetes 原生的 Namespace 隔离机制,实现不同租户的 API 视图隔离。
- Cluster 级别对象:需要对资源的对象的 name 做转换,保证不同租户的 Cluster 级别对象在后端集群没有命名冲突。
除了原生对象之外,KubeZoo 还支持用户自定义的 CRD 资源。CRD 资源都是运行在租户自定义的 API group 下,经过 KubeZoo 协议转换后,多个租户自定义的资源对象可以在后端集群并存而不发生冲突;同时 KubeZoo 还提供完善的过滤机制,使得租户定义的资源对象只对租户自己可见。
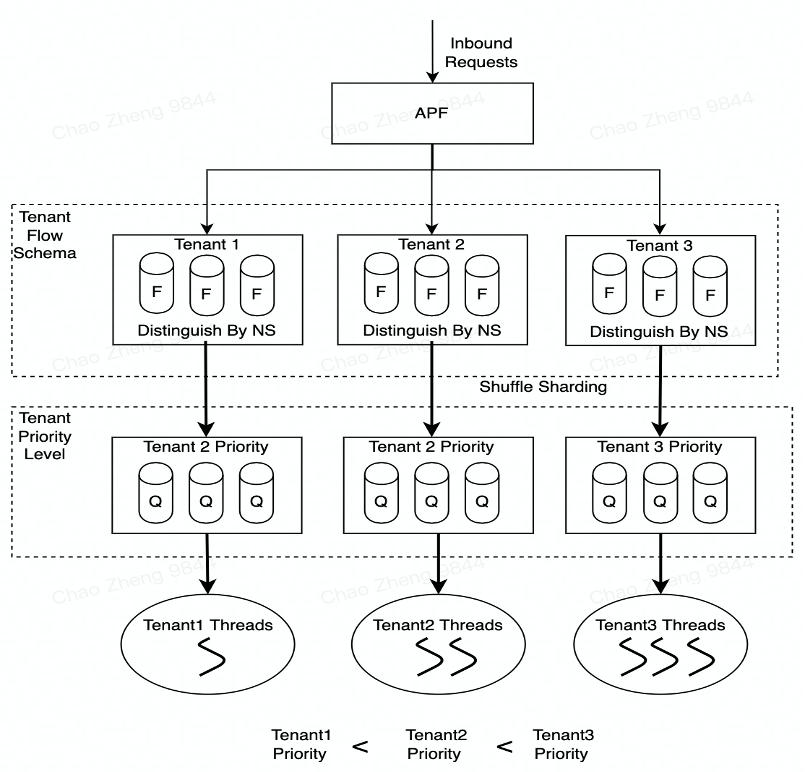
租户请求公平性
由于所有的租户请求都会经过 KubeZoo 的统一网关,所以要避免某个租户发送的大量请求把网关或者集群资源占满,进而影响其他租户请求的发送。这种情况下我们沿用了 API Server 的 priority and fairness 机制,具体来说会为每一个租户创建 Flow Schema(用来匹配租户的流量),另一方面会为每一个 Flow Schema 对象创建 Priority Level(用来代表租户的权重)。最后通过配置流量策略来保证不同租户之间请求的公平性。
租户网络隔离(VPC)
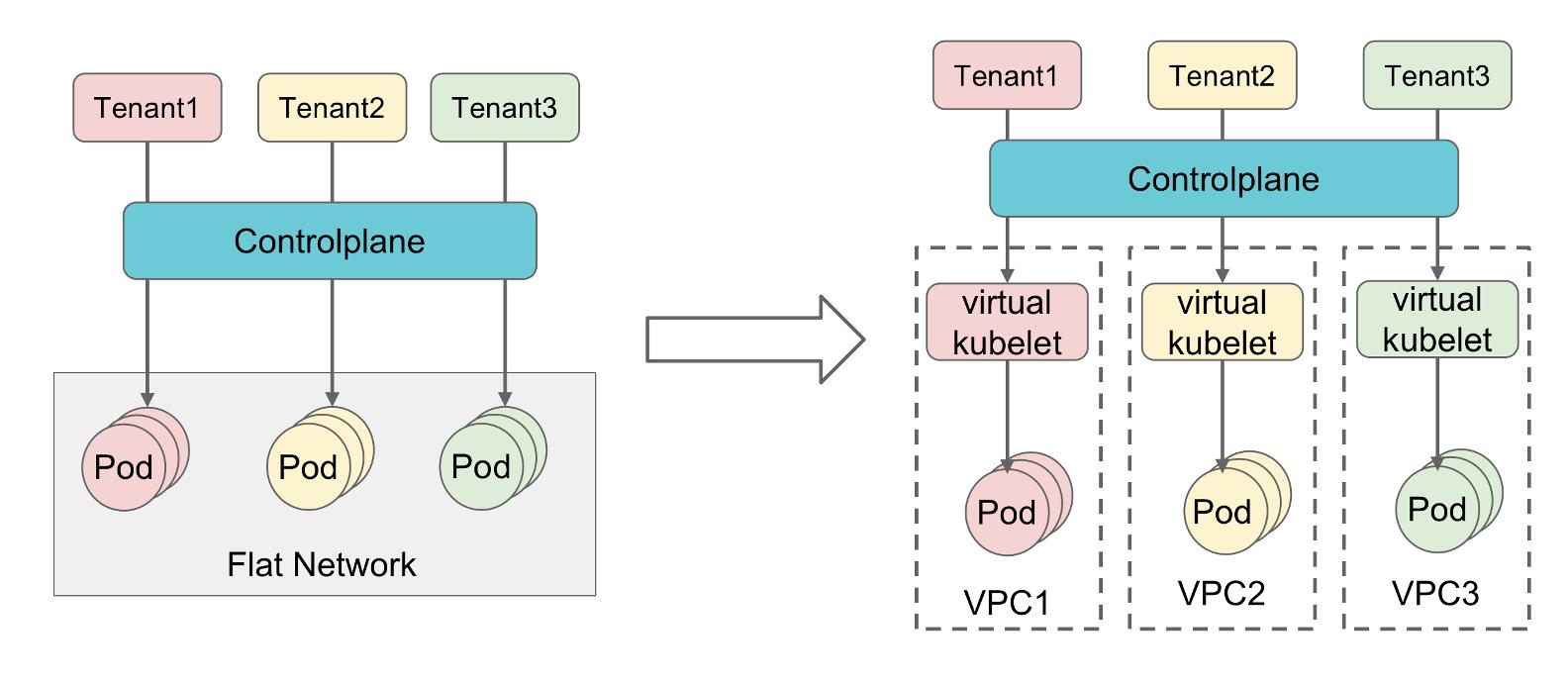
在网络隔离方面可以细分为两个场景:
- 第一种场景是所有的租户都来自同一个公司的内部。在这种场景下信任度比较高,安全和审计也比较完善。这时后端集群通常可以采用一种扁平的网络,即不同租户的 Pod 之间的网络是可以互通的。
- 另外一种是公有云或者对租户的网络隔离性有较强要求的场景,我们可以在创建租户对象的时候分配对应的 VPC 和子网。当通过 Virtual Kubelet 共享资源池的时候,会同步 Pod 到后端集群,该同步过程中也会同步这个 VPC 和子网的网络配置。这样每一个租户就运行在一个独立的 VPC 内部,能够保证租户内部之间的网络互通,而租户之间的网络是相互隔离的。
总结
KubeZoo 是一种基于协议转换的 Kubernetes 的多租户网关方案。与现有的多租户方案对比,它有三方面的特点:
- 轻量级:主要体现在跟 Cluster as a Service 和 Control planes as a Service 对比,它的资源率利用率是非常高的,因为它只需要一个网关,无需为每一个租户起一个独立的控制面集群。相对应的,因为控制面集群的数量只有一个,其运维成本非常低。
- 高效率:主要体现在租户的集群创建方面。租户的集群创建相当于创建一个 Tenant 对象,一次 API 调用,所以租户的集群其实是秒级拉起,拉起之后可即刻使用。
- 租户隔离:KubeZoo 在租户隔离性方面也做得非常优秀。因为每个租户可以拥有独立且完整的 Kubernetes 集群视图,它既可以使用这个 namespace scope 的资源,又可以使用集群级别的资源。
KubeZoo 方案有几种典型的适用场景:
- 第一种是对集群的资源利用率和租户体验有极致要求。
- 第二种是海量的小租户共享一个大的资源池,每一个租户要求的资源量不多,但租户的总体数量比较多,KubeZoo 可以使其达到非常高效的共享资源池的效果。
Q&A
Q:除了 DS 还有一些其他的限制吗?
A:本质上来说 KubeZoo 的方案和 Virtual Cluster 有点类似,是一种 Serverless 的 Kubernetes 方案。KubeZoo 针对 Pod、Deployment、Statefulset 等租户层面的对象都是不受限制的。但是针对 Daemonset 和 Node 等集群共享资源对象是受限制,简单来说就是,如果多个租户共享一个集群的话,我们不希望任何一个租户对集群中的节点做任何操作,所以它不能用 Daemonset 也不能操作集群中的 Node。
Q:租户的 RBAC 支持吗?
A:支持。前面提到我们会为租户初始化三种资源,其中就包括租户自己的 Role 和 RoleBinding 对象,然后 KubeZoo 通过 impersonate 机制模拟租户身份。所以 RBAC 的体验跟原生集群的体验是一致的。
Q:不同租户创建的 CRD 能共用吗?
A:关于 CRD 可以介绍一下细节。我们在方案设计上是把 CRD 分为两类:
- 一种是租户级别的 CRD,每个租户都可以创建,相互之间是完全隔离的。
- 另一种是在公有云场景下提供系统级别的 CRD,在后端集群上会由同一个 Controller 进行处理。
系统级别的 CRD 可以配置为一种特殊的策略,保证它对于某一个或某一些租户是开放的,这些租户可以创建系统级别的 CRD 的对象。
Q:不同租户的 Pod 部署到相同的 Node 上,性能互相影响怎么办?
A:一般来说,在公有云场景下,Pod 可能会通过一些隔离性更高的方式(比如 Kata 这种轻量级虚拟机)进行部署。在单节点的隔离性和性能优化上肯定会有一些对应的措施,保证每一个租户的资源占用不会超过它的最大申请量,性能互不影响。
Q:CTL 命令上有什么区别吗?
A:没有区别。KubeZoo 可以支持完整的 Kubernetes 的 API 视图,所以每一个租户用 Kubectl 跟单集群的方式完全一样,没有任何区别。唯一的不同是 KubeZoo 会为租户单独签发证书,发送 Kubeconfig,用户只需要指定正确的 Kubeconfig 即可。
Q:KubeZoo 和 Kubernetes 自己的多租户方案 HNC 比较有哪些优势和不足呢?
A:HNC 方案实现了一种层级化的 Namespace 的结构,目前还在演进当中的,尚未成为 Kubernetes 的标准 API 。KubeZoo 的优势在于它能跟现有标准的 Kubernetes API 打平。换句话说,假如以后标准 Kubernetes API 也支持 HNC, 那 KubeZoo 的每个租户也能使用 HNC,相当于 KubeZoo 是 HNC能力的一个超集。
Q:KubeZoo 的实际应用场景能举几个例子吗?
A:举例来说,在字节跳动内部,有一些比较小的业务在接入的时候需要的资源量不多,但是如果为这些业务独立维护一个集群,其运维和资源成本又比较高。在这种内场景下,其实是有一定的业务接入量。在公有云场景下,未必所有的租户都是大客户,可能会有一些小用户,他们的需求量不大。但是有点类似于 Kubernetes 的 Sandbox,他们需要体验一下 API 或者是他们做原型验证,这种场景也是非常适用的。
【活动推荐】
4月14日,火山引擎开发者社区技术大讲堂第一期将为大家揭秘字节跳动基于 HPC 的大规模机器学习技术,字节跳动经过业务实践打磨的机器学习技术将首次亮相开发者社区,由技术负责人项亮公开深度分享;同时,承载机器学习平台的超大规模 HPC 基础设施也将首度在社区分享。扫描下方二维码即可报名!
