




作者:刘卯银|火山引擎日志系统架构师
本文整理自火山引擎开发者社区 Meetup 第八期演讲,主要介绍了火山引擎 TLS 日志服务的架构实现、设计优化以及实践案例。
谈到日志系统,首先要从日志说起,日志在 IT 系统里无处不在,也是 IT系统大数据的关键来源。日志的种类和样式非常多,以在线教育系统为例,日志包括客户端日志、服务端日志。服务端日志又包括业务的运行/运维日志以及业务使用的云产品产生的日志。要管理诸多类型的日志,就需要一套统一的日志系统,对日志进行采集、加工、存储、查询、分析、可视化、告警以及消费投递,将日志的生命周期进行闭环。
Kubernetes 下日志采集的开源自建方案
开源自建
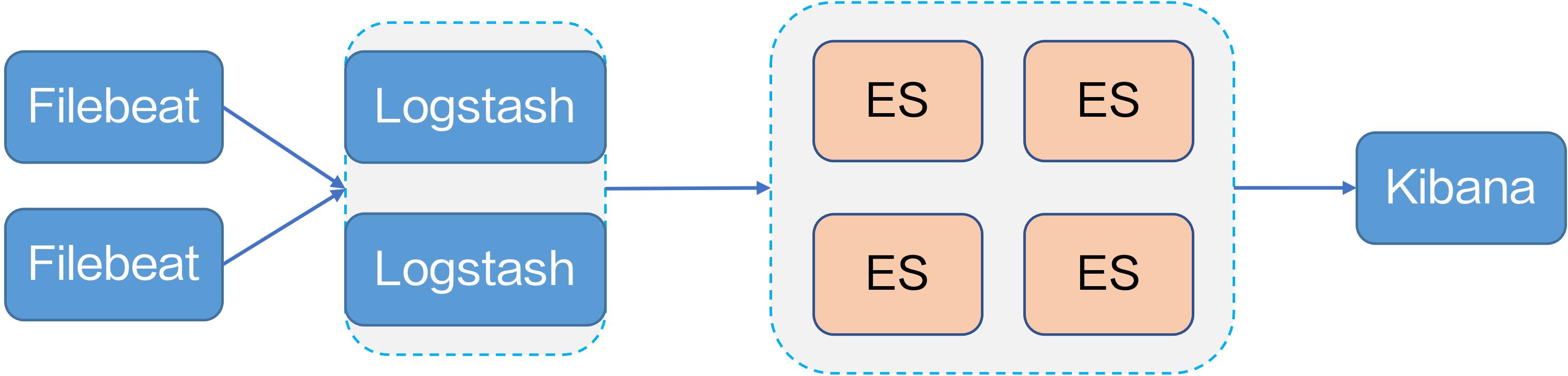
火山引擎早期为了快速上线业务,各团队基于开源项目搭建了自己的日志系统,以满足基本的日志查询需求,例如使用典型的开源日志平台 Filebeat+Logstash+ES+Kibana 的方案。
但是在使用过程中,我们发现了开源日志系统的不足:
- 各业务模块自己搭建日志系统,造成重复建设。
- 以 ES 为中心的日志架构可以利用 ES 查询便利的优势,但是资源开销大、成本高。而且 ES 与 Kibana 在界面上强绑定,不利于功能扩展。
- 开源方案一般采用单机 yaml 做采集配置,当节点数很多的时候,配置非常繁琐。
- 开源系统的采集配置难以管理,数据源也比较单一。
Kubernetes 下的日志采集
Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:
- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的文件。
- Streaming Sidecar:有一些业务系统的日志不是标准输出,而是文件输出。Streaming Sidecar 的方式可以把这些文件输出通过 Sidecar 容器转换成容器的标准输出,然后采集。
- Sidecar Logging Agent:业务 Pod 内单独部署 Agent 的 Sidecar 容器。这种方式的资源隔离性强。
- API/SDK:直接在容器内使用 API 或 SDK 接口将日志采集到后端。
以上前三种采集方案都只支持采集容器的标准输出,第四种方案需要改造业务代码,这几种方式对采集容器文件都不友好。但用户对于日志文件有分类的需求,标准输出将所有日志混在一起,不利于用户进行分类。如果用户要把所有日志都转到标准输出上,还需要开发或者配置,难以推广。因此 Kubernetes 官方推荐的方案无法完全满足用户需求,给我们的实际使用带来了很多不便。
自建日志采集系统的困境与挑战
云原生场景下日志种类多、数量多、动态非永久,开源系统在采集云原生日志时面临诸多困难,主要包括以下问题:
一、 采集难
- 配置复杂 : 系统规模越来越大,节点数越来越多,每个节点的配置都不一样,手工配置很容易出错,系统的变更变得非常困难。
- 需求 不满足 : 开源系统无法完全满足实际场景的用户需求,例如不具备多行日志采集、完整正则匹配、过滤、时间解析等功能,容器文件的采集也比较困难。
- 运维难度高 : 大规模场景下大量 Agent 的升级是个挑战,系统无法实时监控 Agent 的状态,当Agent 状态异常时也没有故障告警。
二 、产品化能力不足
- 可用性低: 因为缺少流控,突发的业务容易使后端系统过载,业务之间容易相互影响。
- 资源使用效率低 : 如果配置的资源是固定的,在突发场景下容易造成性能不足的问题;但如果配置的资源过多,普通场景下资源利用率就会很低;不同的组件配置不均衡还会导致性能瓶颈浪费资源。ES 的原始数据和索引使用相同的资源配置,也会导致高成本。
- 功能不足 : 比如 ES 的投递和消费能力弱、分析能力固化、没有告警能力、可视化能力有限。
火山引擎统一日志平台 TLS
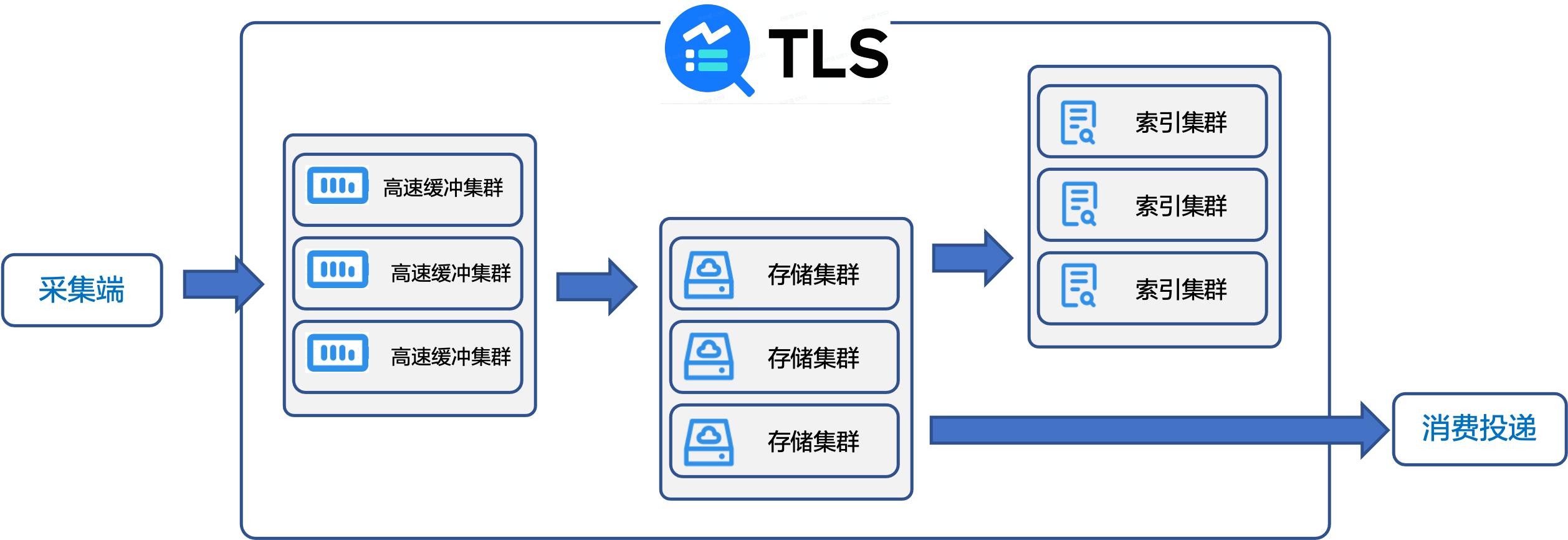
在遇到这些问题以后,我们研发了一套统一的日志管理平台——火山引擎日志服务(Tinder Log Service,简称为 TLS)。TLS 的整体架构如下:
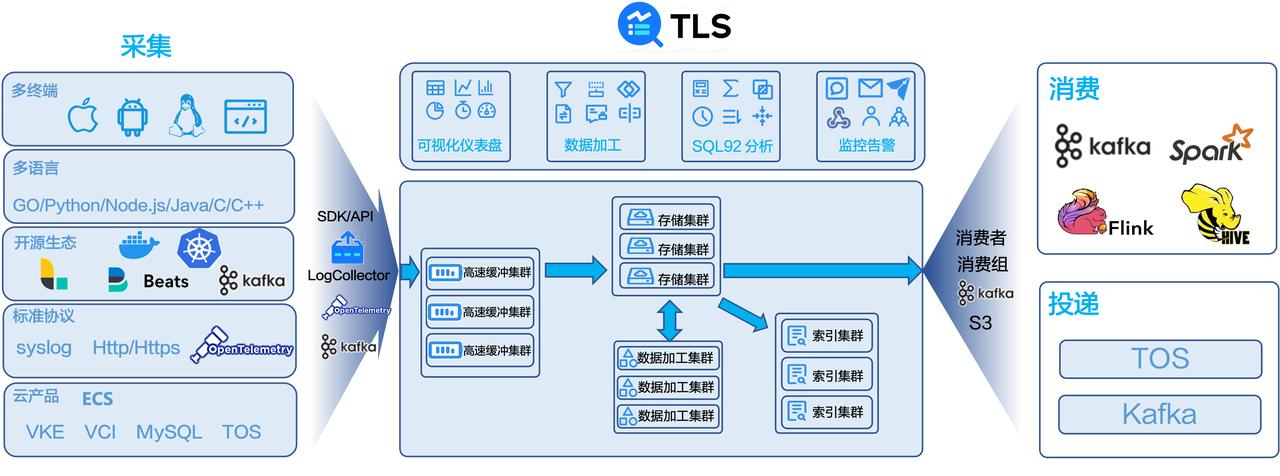
面对各种日志源,TLS 通过自研的 LogCollector/SDK/API,可支持专有协议、 OpenTelemetry 和 Kafka 协议上传日志。支持多种类型的终端、多种开发语言以及开源生态标准协议。
采集到的日志首先会存入高速缓冲集群,削峰填谷,随后日志会匀速流入存储集群,根据用户配置再流转到数据加工集群进行日志加工,或者到索引集群建立索引。 建立索引后用户可以进行实时查询和分析。TLS 提供标准的 Lucene 查询语法、SQL 92 分析语法、可视化仪表盘以及丰富的监控告警能力。
当日志存储达到一定周期,不再需要实时分析之后,用户可以把日志投递到成本更低的火山引擎对象存储服务中,或者通过 Kafka 协议投递到其他云产品。如果用户有更高阶的分析需求,TLS 也支持把日志消费到实时计算、流式计算或离线计算进行更深入的分析。
TLS 的系统设计遵循高可用、高性能、分层设计的原则。
- 高可用:通过存算分离,所有服务都是无状态的,故障快速恢复。
- 高性能:所有集群都可横向扩展,没有热点。
- 分层设计:各模块之间低耦合,模块之间定义标准接口,组件可替换。
以上就是火山引擎自研的日志存储平台 TLS 的系统架构,下面将详细介绍 TLS 相较于开源系统做的优化。
系统优化
中心化白屏化的配置管理
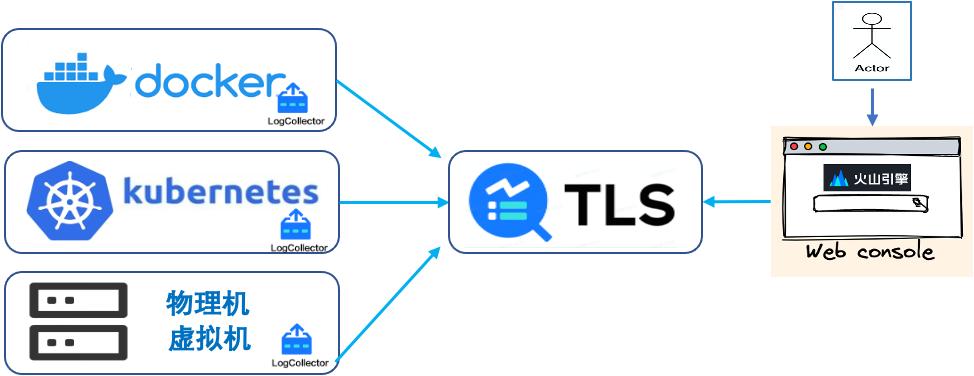
当日志系统中采集 Agent 数量较多时,不再适合在每台机器上手工配置,因此我们开发了中心化、白屏化的配置管理功能,支持动态下发采集配置,并支持查看 Agent 运行状态监控、支持客户端自动升级。
中心化配置的实现流程如下:
- 客户端主动向服务端发起心跳,携带自身版本信息;
- 服务端收到心跳,检查版本;
- 服务端判断是否需要下发配置信息给客户端;
- 客户端收到配置信息,热加载到本地配置,以新的配置进行采集。
中心化配置管理的优势在于:
- 可靠:中心化管理,配置不丢失,白屏化配置不容易出错。
- 高效:各种环境下所有的配置都是统一处理,无论 LogCollector 部署在移动端、容器还是物理机上,用户都可以在服务端相同的界面上配置,配置以机器组为单位批量下发,快速高效。
- 轻松运维:用户可以在服务端查看客户端的运行状态,对客户端的异常发出告警。通过中心化配置,TLS 可以向客户端推送最新版本,自动升级。
CRD 云原生 配置方式
中心化、白屏化的配置方式是适合运维人员的配置方式。在开发测试自动化的场景下,最优的方式是 CRD。传统的方式通过 API 接口去做采集配置,用户通常需要写数千行代码来实现。TLS 提供了云原生 CRD 的方式来进行配置,用户只需要在 yaml 文件里配置要采集的容器、容器内的日志路径以及采集规则即可完成采集配置。因为不再需要编写代码,CRD 方式大幅提高了日志接入效率。
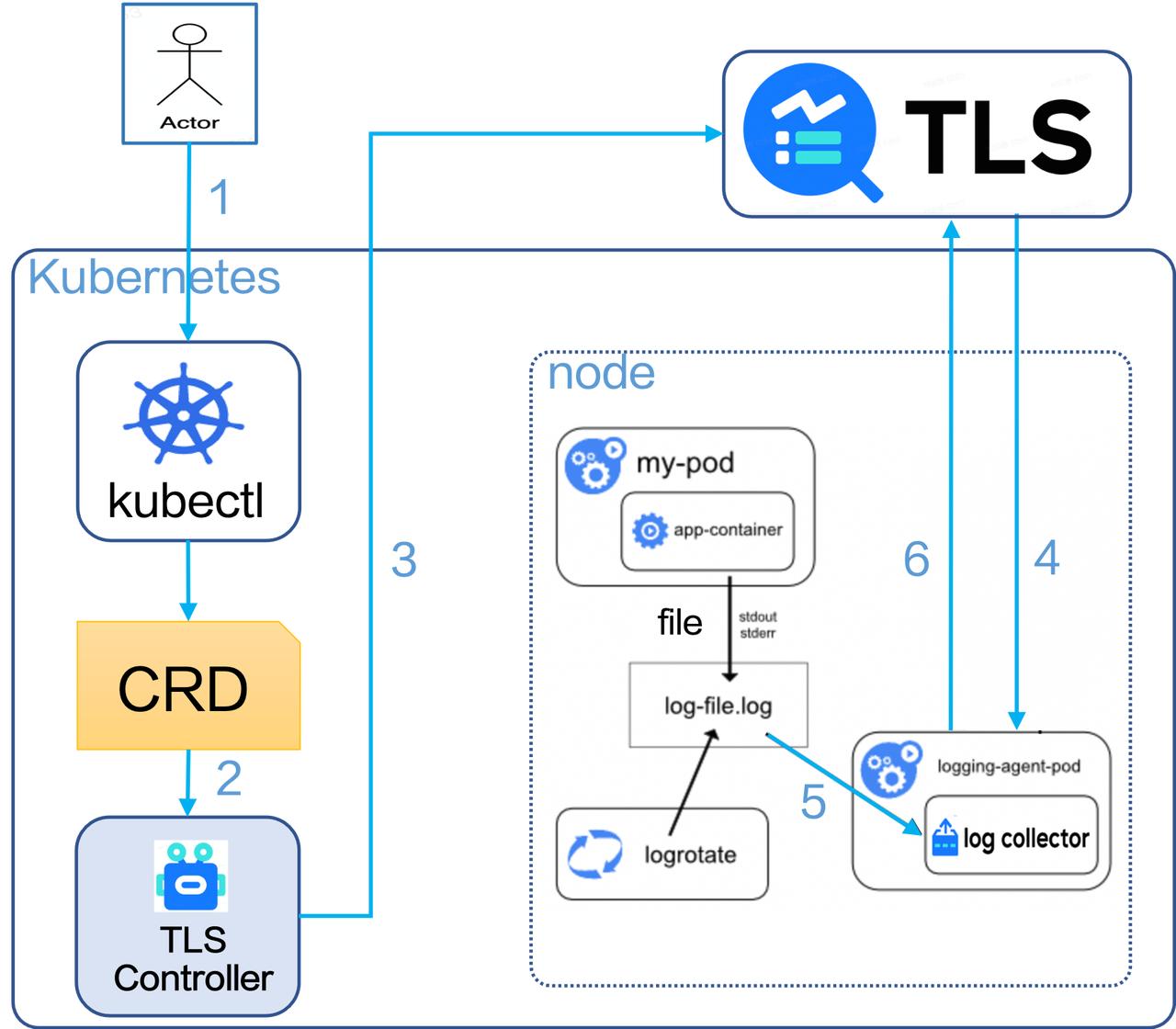
CRD 的配置流程如下:
- 使用 Kubectl 命令创建 TLS LogConfig CRD;
- TLS Controller 监听到 CRD 配置更新;
- TLS Controller 根据 CRD 配置向 TLS Server 发送命令,创建 topic、创建机器组,创建日志采集配置;
- LogCollector 定期请求 TLS Server,获取新的采集配置并进行热加载;
- LogCollector 根据采集配置采集各个容器上的标准输出或文本日志;
- LogCollector 将采集到的日志发送给 TLS Server。
适合大规模、多租户场景的客户端
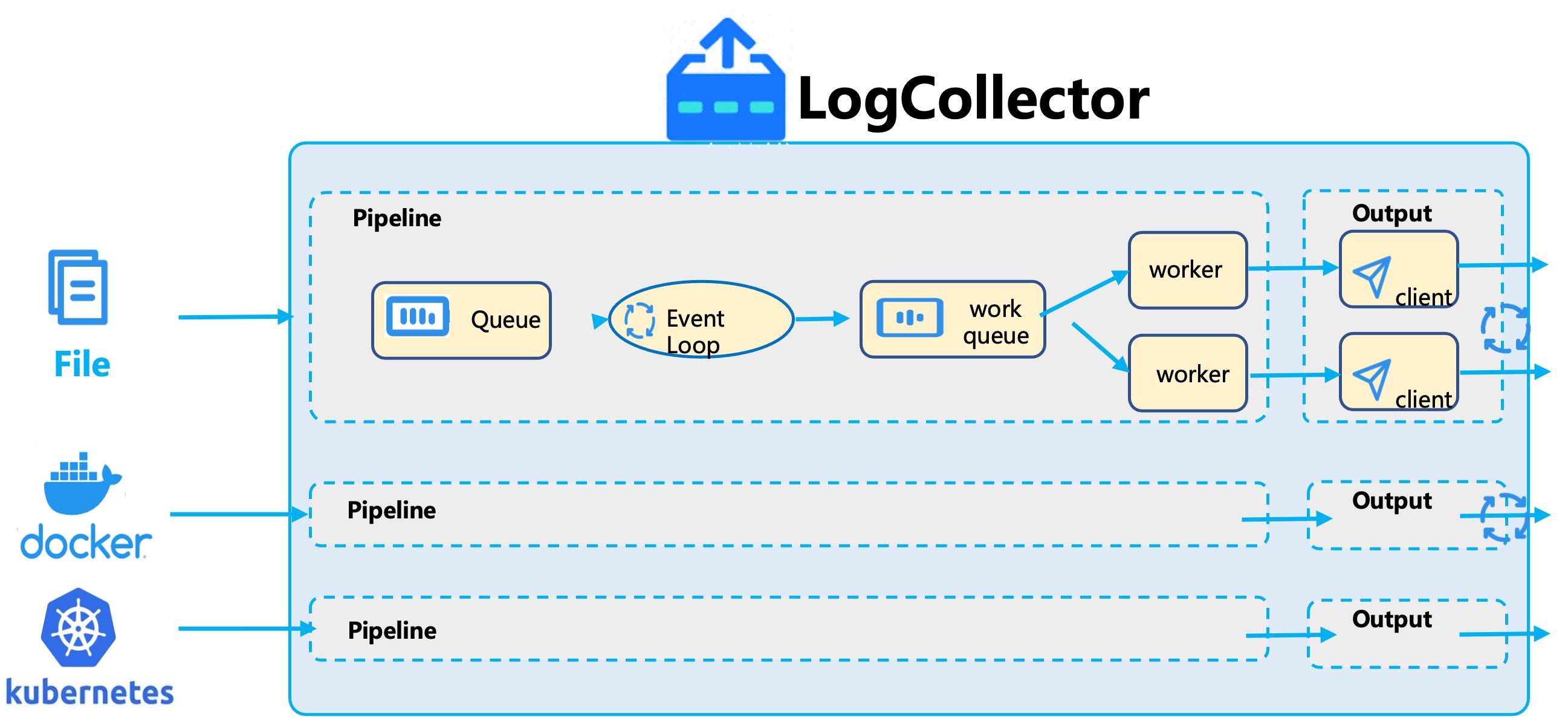
开源日志采集客户端一般只支持一个 Output,多个 Input 采用相同的 Pipeline,相互影响。为了适应大规模、多租户场景,火山引擎自研了日志采集的客户端 LogCollector。LogCollector 对不同的 Input 采用不同的 Pipeline 做资源隔离,减少多租户之间的相互影响。一个 LogCollector 支持多个 Output,可以根据不同的 Output 单独做租户鉴权。同时我们还在 LogCollector 内实现了自适应反压机制,如果服务端忙碌,LogCollector 会自动延迟退避,服务端空闲时再发送,减少算力负担。
产品优化
可用性提升
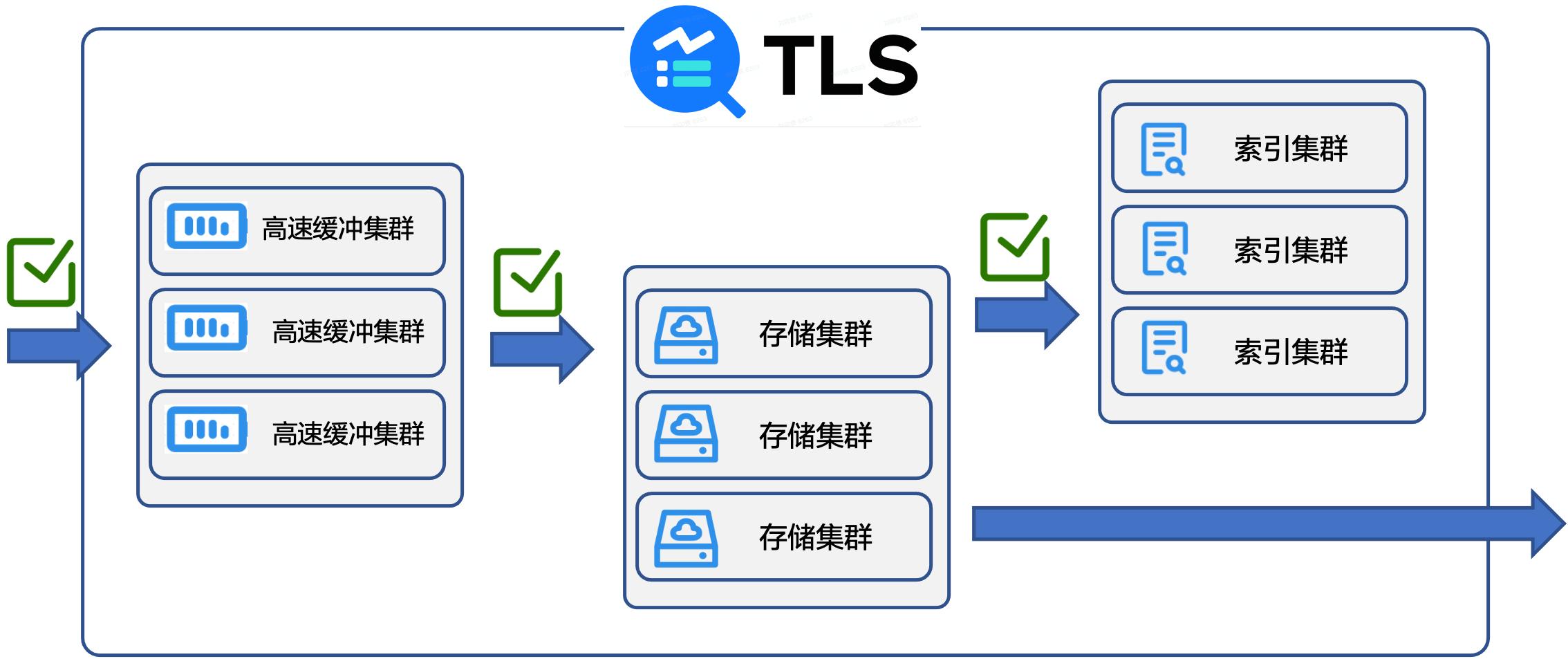
在可用性方面,TLS 支持多级全局流控,能杜绝因业务突发导致的故障扩散问题。
- 在日志采集到高速缓冲集群时,按照用户的 Shard 数控制写入高速缓冲区的流量。
- 当数据从高速缓冲区流向存储集群时,按存储集群控制单个存储集群的流量。
- 从存储集群到索引集群,按索引集群控制单个索引集群的写入流控以及查询分析并发数。
效率提升
索引 和 原始数据分离
ES 的索引和数据存在一起,我们在设计过程发现索引和原始数据分离会更优,主要表现在:
- 提升数据流动性:存储集群支持批量消费接口,消费数据不经过索引集群。相对于从索引集群先查询后消费的模式,直接从存储集群消费性能更高,有效提升数据流动性。
- 降低成本:索引和存储可以采用不同成本的存储,整体的存储成本就会降低。用户可以随时按需创建索引,进一步降低索引成本。
- 提升可用性:索引可以异步创建,流量突发时创建索引慢不会影响存储写入速率。
索引管理和调度
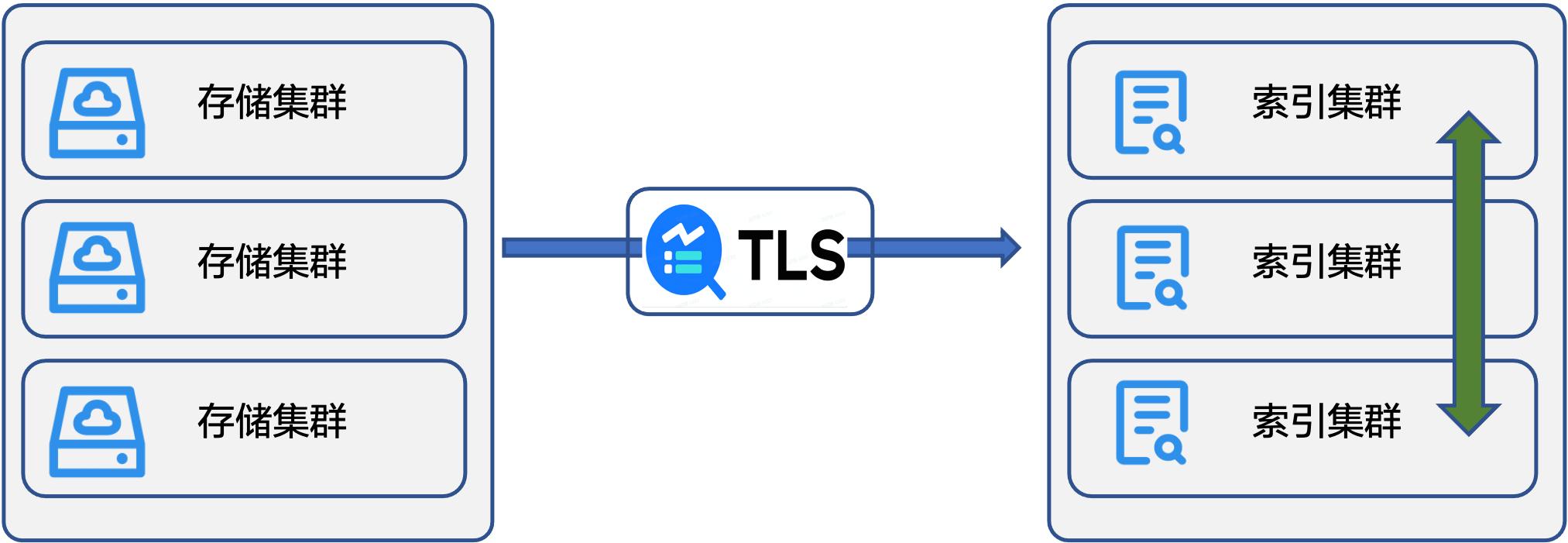
索引的流量是不可预测的,因此我们在效率方面的另一个优化是支持索引的管理和调度,实现弹性伸缩,从而提升可用性,解决规模问题。我们的解决方案是在多个索引集群之间做数据流动,基于负载、资源、容量自动迁移索引,支持动态跨集群在线迁移索引,平衡索引集群负载。
功能优化
-
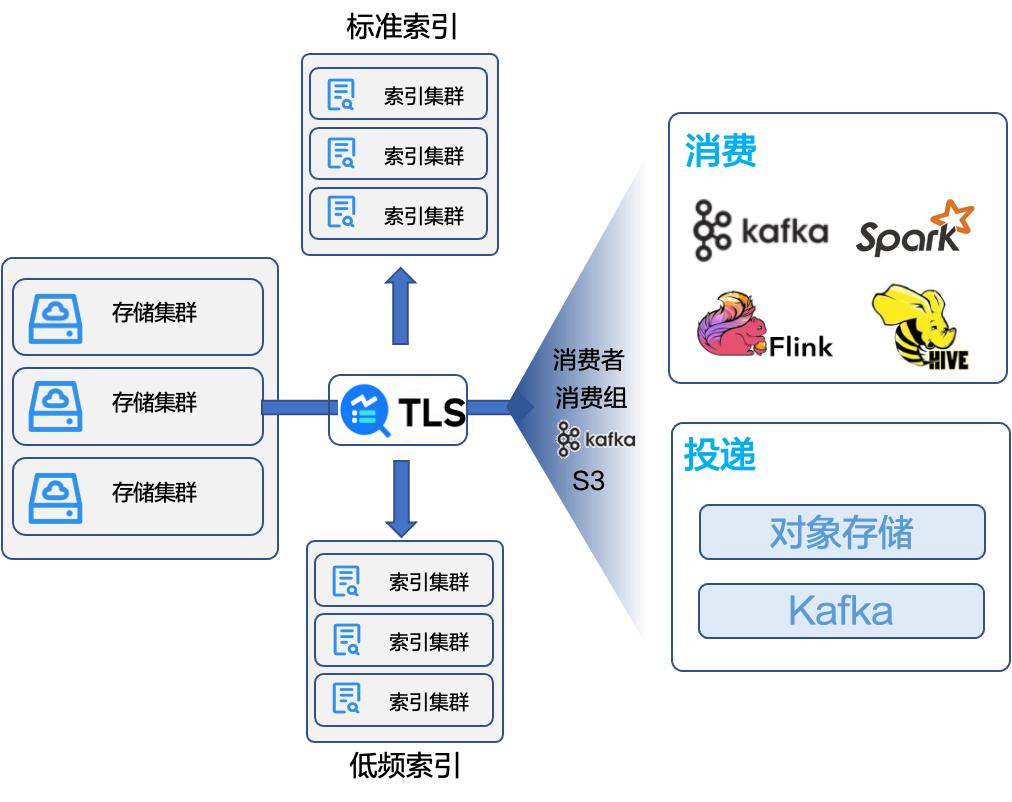
消费投递:在消费投递方面我们支持了丰富的消费投递接口,包括:
- 消费者
- 消费组
- Kafka 协议:通过 Kafka 协议进行标准协议的消费;
- S3 协议:支持通过 S3 对象存储的协议把日志投递到对象存储。
- 查询分析:支持先查询过滤后分析,减少分析数据量提高性能。分析支持标准的 SQL 92,分析结果支持图表可视化。
- 日志告警:通过实时监控日志,基于用户配置的监控规则组合以及告警触发条件,满足条件就可以通过短信、邮件、飞书等方式发送告警给用户或用户组。
- 可视化仪表盘:TLS 提供多种可视化仪表盘,实现实时监测,且仪表盘可以关联告警。
TLS 实践案例
接下来为大家介绍两个 TLS 的典型案例。
火山引擎内部业务及运维日志采集
TLS 目前支撑了火山引擎全国多个 Region 运维日志的采集分析。日志类型包括业务的文件日志、容器标准输出。业务分别部署在内网、外网以及混合云,日志都通过 TLS 平台统一做采集和分析。
相较于前期各业务模块自己搭建日志系统,采用 TLS 获得了如下收益:
- 经济高效:资源利用率由之前的 20% 提升到现在的 80%,大幅降低资源成本;
- 可用性较高:多级流控加缓存,抗突发能力强,即使在索引系统故障的时候也不会影响原始数据的流量;
- 轻松运维:TLS 的统一运维提升了运维人员的能力,少量运维人员即可完成整个系统的运维。
- 快速接入:TLS 可以在一小时内完成一个新业务的采集、查询、分析、消费的快速接入。
某教育行业头部客户日志采集
该客户的系统业务主要采集的日志包括:
- 文件日志
- App 日志
- Kubernetes 集群后端业务的日志
- 用户行为日志
TLS 把这几个平台的日志统一采集到云端,进行实时查询分析以及进行告警。客户自建有大数据分析平台,TLS 可将日志数据通过消费的方式流转到该平台进行在线、离线等更高阶的大数据分析。对于时间长的历史数据,则投递到对象存储进行归档,从而降低整个系统的成本。
用户的管理员可在 TLS 上统一查看所有平台的各种日志,整个系统的建设和运维成本也降低了。TLS 使用标准接口,可以兼容云上自建的分析平台,用户在快速上线的同时也能保证系统的高度兼容。
未来展望
未来,TLS 平台会不断进行更深层次的优化:
- 云产品的一键日志采集
- 搜索引擎的深度优化
- 数据清洗和加工的函数式接口
- 集成更多第三方平台,火山引擎云产品深度融合
火山引擎 TLS 日志服务将在5月初正式 GA,感兴趣的小伙伴可以在火山引擎开发者社区公众号后台回复关键字【TLS】关注试用。
Q&A:
Q:中心化配置,各个业务的日志采集配置是 OP 负责还是 RD 负责?
A:日志采集的中心化配置是 Web 方式,配置非常简单,无论是 RD 或是 OP 负责都可以。火山引擎上 Web 配置由 OP 来负责,容器自动化采集是用 CRD 的方式,一般是 RD 负责。
Q:采集端 Agent 的使用资源可以限制吗?是否会影响业务的资源使用?
A:CPU 占用量、内存占用量这些是可以配置的,不会影响业务的资源使用。
Q:CRD 和中心化配置不会冲突吗?
A:通常情况下不会冲突。CRD 有特定的命名规则,只要 Web 配置和 CRD 配置的名字不冲突就不会报错。如果名字冲突,配置会失败,改名字后重试即可。
Q:Node 节点宕机是否会丢日志?
A:不会。LogCollector 有 Checkpoint,Checkpoint 会定期更新。如果节点宕机没有更新 Checkpoint,日志会从上次 Checkpoint 点重新采集,所以是不会丢的。
Q:日志采集的延迟情况如何?
A:一般在秒级延迟,后端业务忙的时候可能是几秒到十几秒的延迟。
Q:Kafka 协议是如何暴露的?通过实现 Kafka Server 吗?
A:我们是在服务端实现的 Kafka 协议。用户以 Kafka 的协议方式接入,鉴权也是以 Kafka 的鉴权协议来做的。用户看到的其实就是一个 Kafka。这样可以对用户做到透明。