




字节跳动内部有很多混合计算的需求,需要一套既支持 TP 计算,也支持 AP 计算的系统。下图是字节跳动 HTAP 系统的总体架构。系统使用内部自研的数据库作为 TP 计算引擎,使用 Flink 作为 AP 的计算引擎。
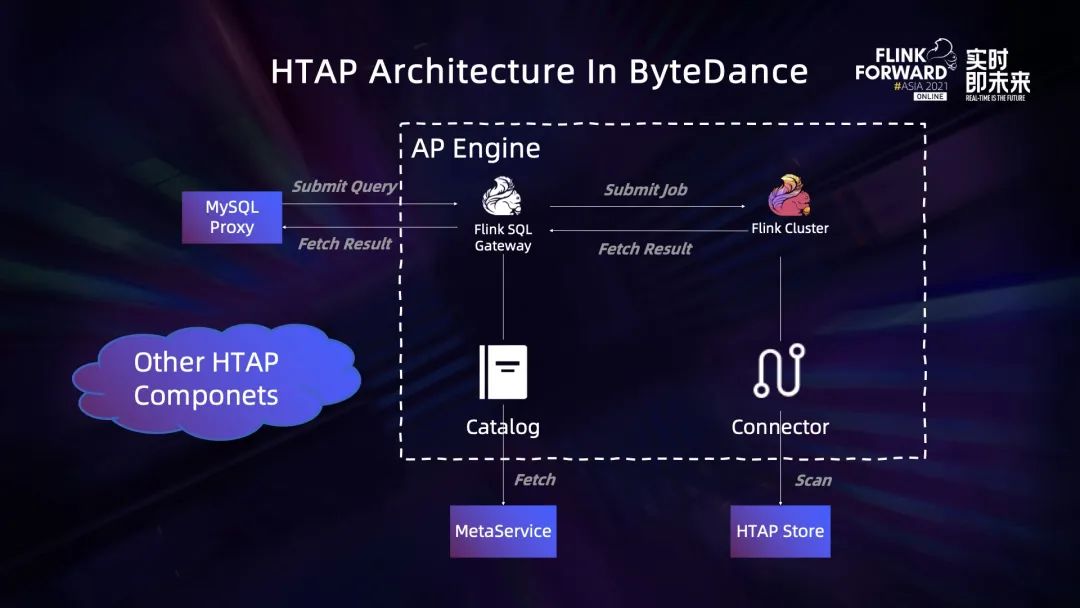
字节跳动 HTAP 系统的总体架构
HTAP 系统对外支持 MySQL 协议,MySQL Proxy 接收到查询后根据查询的复杂度和特点(是否使用索引等),将查询分发给 TP 或者 AP 计算引擎。Flink SQL Gateway 是 AP 计算引擎的查询入口,接收到 AP 查询后生成 Flink 作业执行计划,并提交到 Flink 集群调度和执行。AP 计算引擎有一个列式存储,Flink 集群通过 Catalog 和 Connector 的接口,分别与存储层的元信息和数据查询接口进行交互。AP 计算引擎完成计算后,Client 端会向 Flink Gateway 发起读取结果数据请求,Gateway 再向 Flink 集群读取结果数据,所有结果数据返回给 Client 后作业就完成了整个 AP 计算流程。
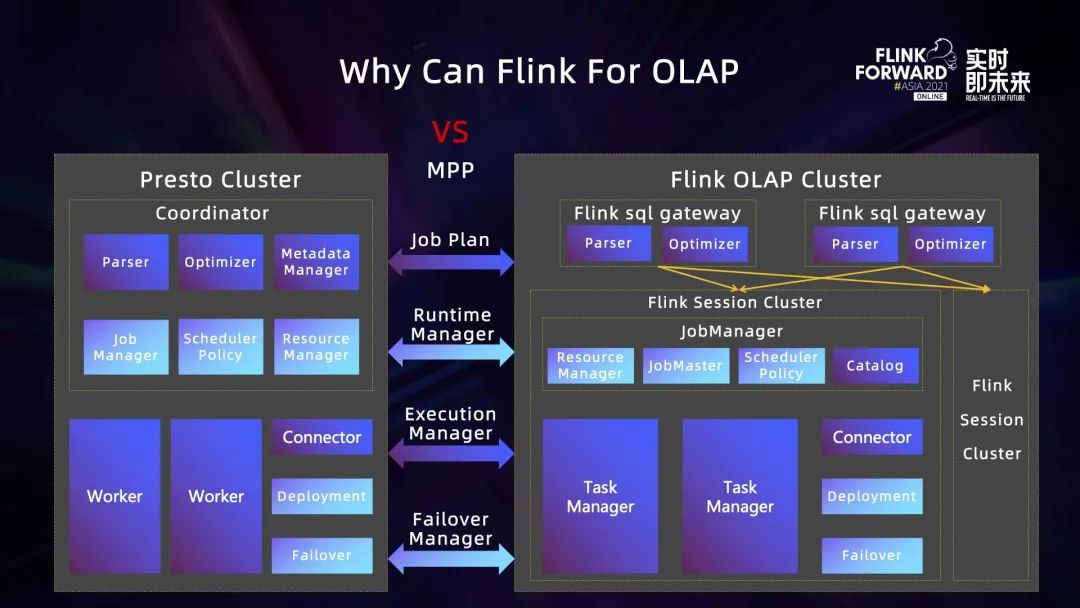
Flink 是流批一体的计算引擎,在业界通常作为流式计算引擎。在 OLAP 计算引擎的选型上,我们主要考虑和对比了 Flink 与 Presto。
首先从架构上看,Flink 支持多种不同的部署模式,Flink 的 Session 集群是一个非常典型的 MPP 架构,这是 Flink 可以支持 OLAP 计算的前提和基础。Flink对作业的计算执行总体上可以分为执行计划、作业 Runtime 管理、计算任务执行管理、集群部署和 Failover 管理 4 大部分。从上图 Presto 和 Flink OLAP 的总体架构以及功能模块图来看,两套系统在支持这些计算功能的具体实现上有很大的差异,但他们提供的系统能力和模块功能基本上是一致的。所以 Flink 引擎在架构及功能实现上,可以支持完整的 Flink OLAP 的计算需求。
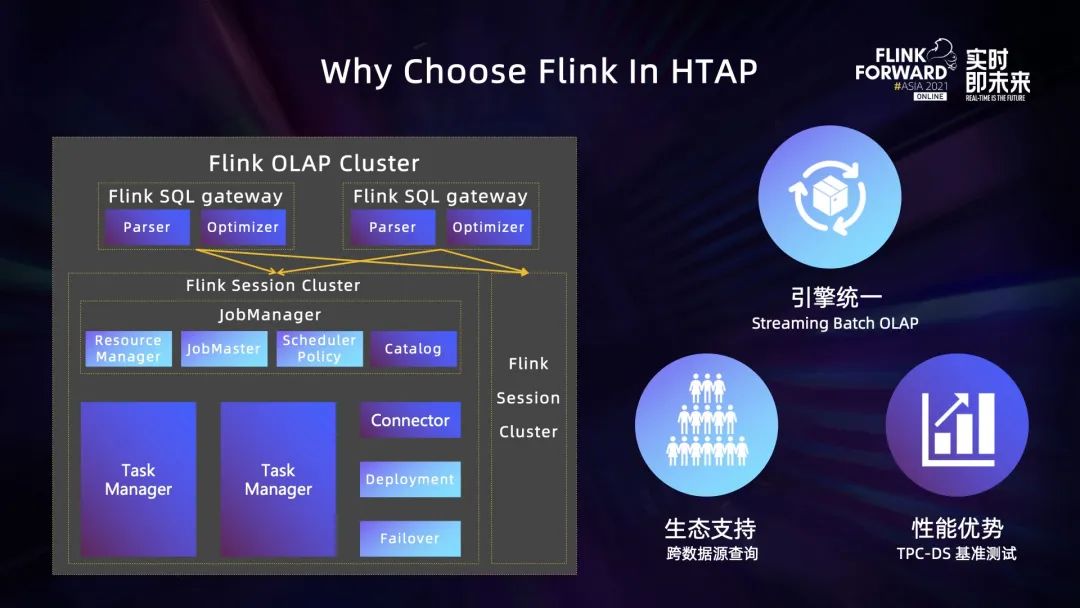
在字节跳动内部,Flink 最初被用作流式计算。后来由于 Flink 流批一体计算能力的发展,在一些实时数仓场景我们也使用 Flink 作为批式计算引擎。我们最终选用 Flink 作为 AP 计算引擎,主要基于三个方面的考虑:
-
统一引擎降低运维成本。 字节跳动流式计算团队对 Flink 有非常丰富的运维和优化开发经验,在流批一体的基础上,使用 Flink 作为 AP 计算引擎可以降低开发和运维成本;
-
生态支持。 字节内部有很多业务方使用 Flink SQL 来开发流式和批式作业,我们对 Flink 的 Connector 也进行了很多功能拓展,对接了很多字节内部的存储系统,所以用户使用 Flink 执行 OLAP 计算非常方便;
-
性能优势。 字节 Flink 团队曾进行过 TCP-DS 相关的基准测试 Benchmark,Flink 计算引擎相比 Presto 和 Spark SQL,在计算性能上并不逊色,在某些查询方面甚至是占优的。
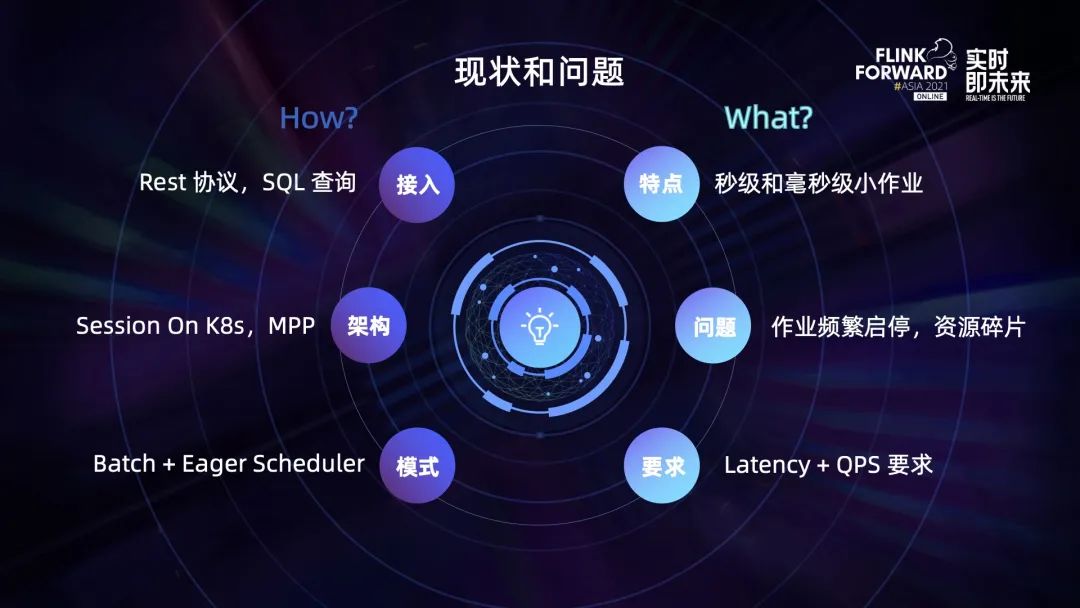
在具体应用中,Flink 引擎如何支持 OLAP 计算?
首先在接入层,我们使用 Flink SQL Gateway 作为接入层,提供 Rest 协议直接接收 SQL 语句查询;
架构上,在 K8s 上拉起 Flink 的 Session 集成,这是一个非常典型的 MPP 架构;
计算模式上,使用 Batch 模式以及计算全拉起的调度模式,减少了计算节点之间的数据落盘且能提升 OLAP 计算的性能。
在 Flink OLAP 计算过程中,主要存在以下几个问题:
- Flink OLAP 计算相比流式和批式计算,最大的特点是 Flink OLAP 计算是一个面向秒级和毫秒级的小作业,作业在启动过程中会频繁申请内存、网络以及磁盘资源,导致 Flink 集群内产生大量的资源碎片;
- OLAP 最大的特点是查询作业对 Latency 和 QPS 有要求的,需要保证作业在 Latency 的前提下提供比较高的并发调度和执行能力,这就对 Flink 引擎提出了一个新的要求。
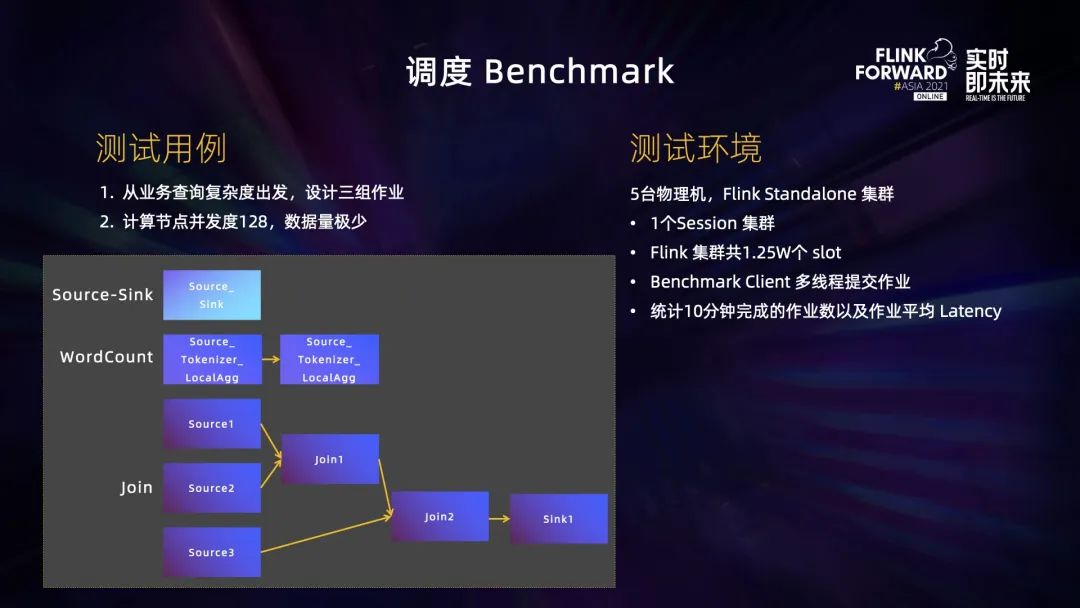
为了测试 Flink 执行 OLAP 计算的能力,我们对 Flink 作业调度进行 Benchmark 测试:
- 测试作业:设计了三组不同复杂度的作业,分别是单节点作业、两个节点的 Wordcount 作业以及 6 个节点的 Join 作业。每组作业的计算节点并发度均为 128;
- 测试环境:选取了 5 台物理机启动一个 Flink Session 集群,集群内有 1 万多个 Slot;
- 测试步骤:开发了一个作业提交的Client,Client 多线程并发提交作业,统计 10 分钟之内完成的作业数量及完成作业的平均 Latency。
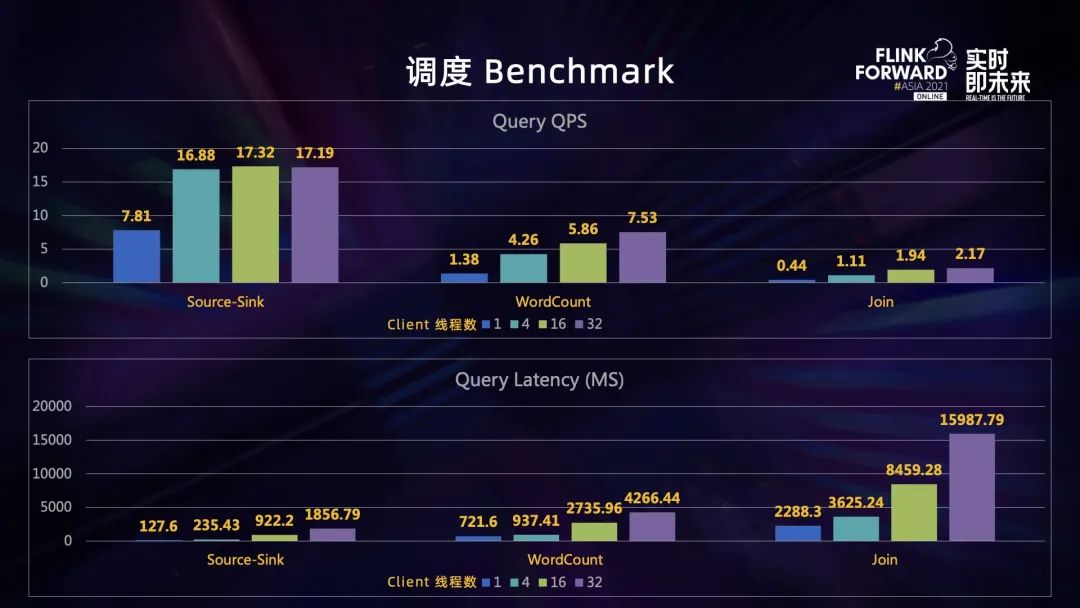
调度 Benchmark 测试结果
测试结果如上图所示,分为两方面:QPS 和 Latency 。
QPS 测试结果分析:作业 QPS 随着 Client 线程数增加而小幅增加,并很快达到瓶颈。
- 单节点作业,Client 单线程提交作业时 QPS 为 7.81;Client 线程数为 4 时,达到 QPS 极限,接近 17 ;
- Wordcount 两节点作业,Client 单线程提交作业时 QPS 为 1.38;Client 线程数为 32 时, QPS 为 7.53;
- Join 的作业表现最差,Client 单线程提交作业时 QPS 只有 0.44;Client 线程数增加到 32 时,QPS 也只有 2.17。
Latency测试结果分析:作业 Latency 随着 Client 线程数增加而大幅度增加。
- 单作业的 Latency 从 100 多毫秒增加到 2 秒;
- Wordcount 作业的从 700 多毫秒增加到 4 秒;
- Join 的作业从 2 秒增加到了 15 秒多,有数倍的增长。
Flink 引擎这样的作业调度性能在线上业务使用过程中是不可接受的。
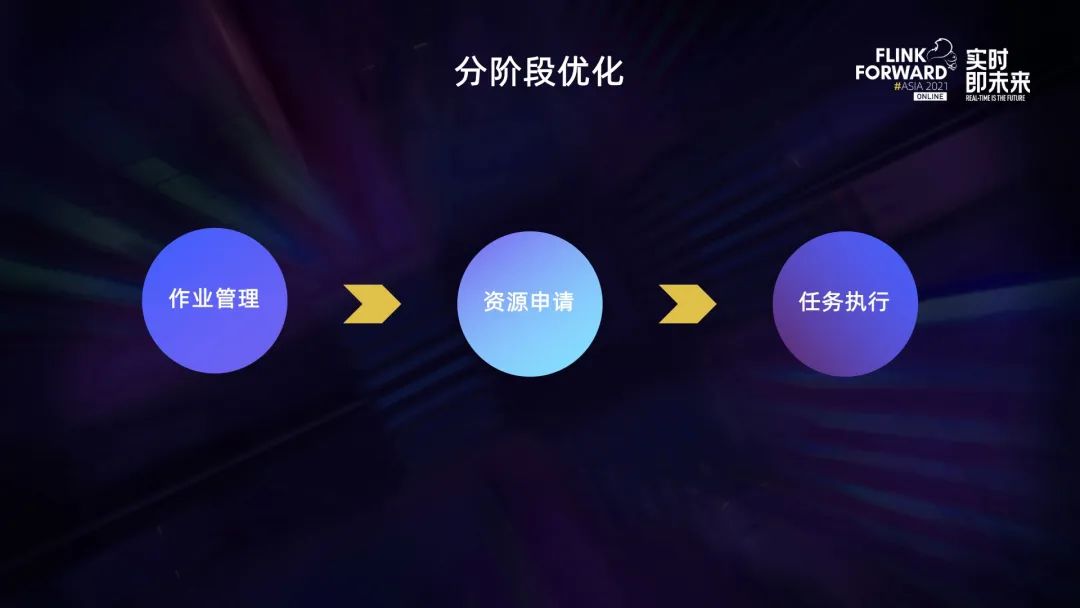
针对 Flink 并发作业调度的性能问题,我们也曾尝试针对一些性能的瓶颈点进行简单的优化,但效果并不理想。所以我们针对 Flink 作业的调度执行全链路进行了分析,将 Flink 作业的执行分为作业管理、资源申请、计算任务三个主要阶段,随后针对每个阶段进行了相应的性能优化和改进。
作业管理优化
Flink 通过 Dispatcher 模块接收和管理作业,整个作业的执行过程可以分为 4 个步骤:初始化、作业执行准备、启动作业执行、结束作业执行。
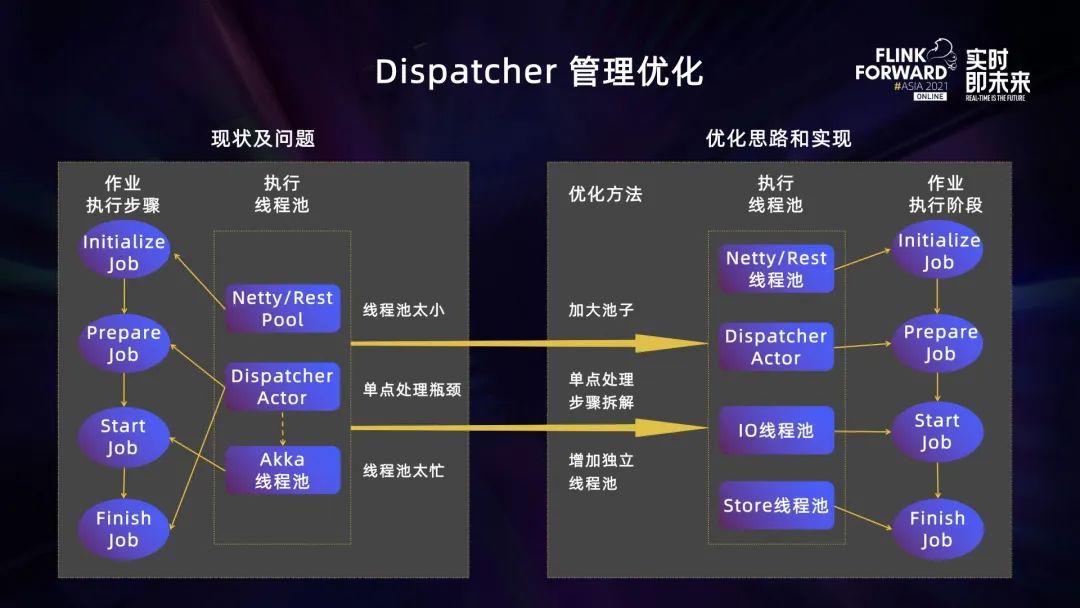
Dispatcher 内部有 3 个线程池负责执行作业的 4 个步骤,分别是 Netty/Rest、Dispatcher Actor 以及 Akka 线程池。根据测试和分析:
- Netty/Rest 线程池默认线程数量太少;
- Dispatcher Actor 单点处理且执行了一些非常重量级的作业操作;
- Akka 线程池过于繁忙,不仅要负责 Dispatcher 内的作业管理,还负责了很多 每个作业 JobMaster 的具体执行。
针对上述问题,我们分别进行了相应的优化。
- 加大了 Netty/Rest 线程池的大小;
- 对作业管理流程进行拆解,创建了两个独立的线程池:IO 线程池和 Store 线程池,分别负责执行作业管理过程中比较重量级的操作,减轻 Dispatcher Actor 和 Akka 线程池的工作压力。
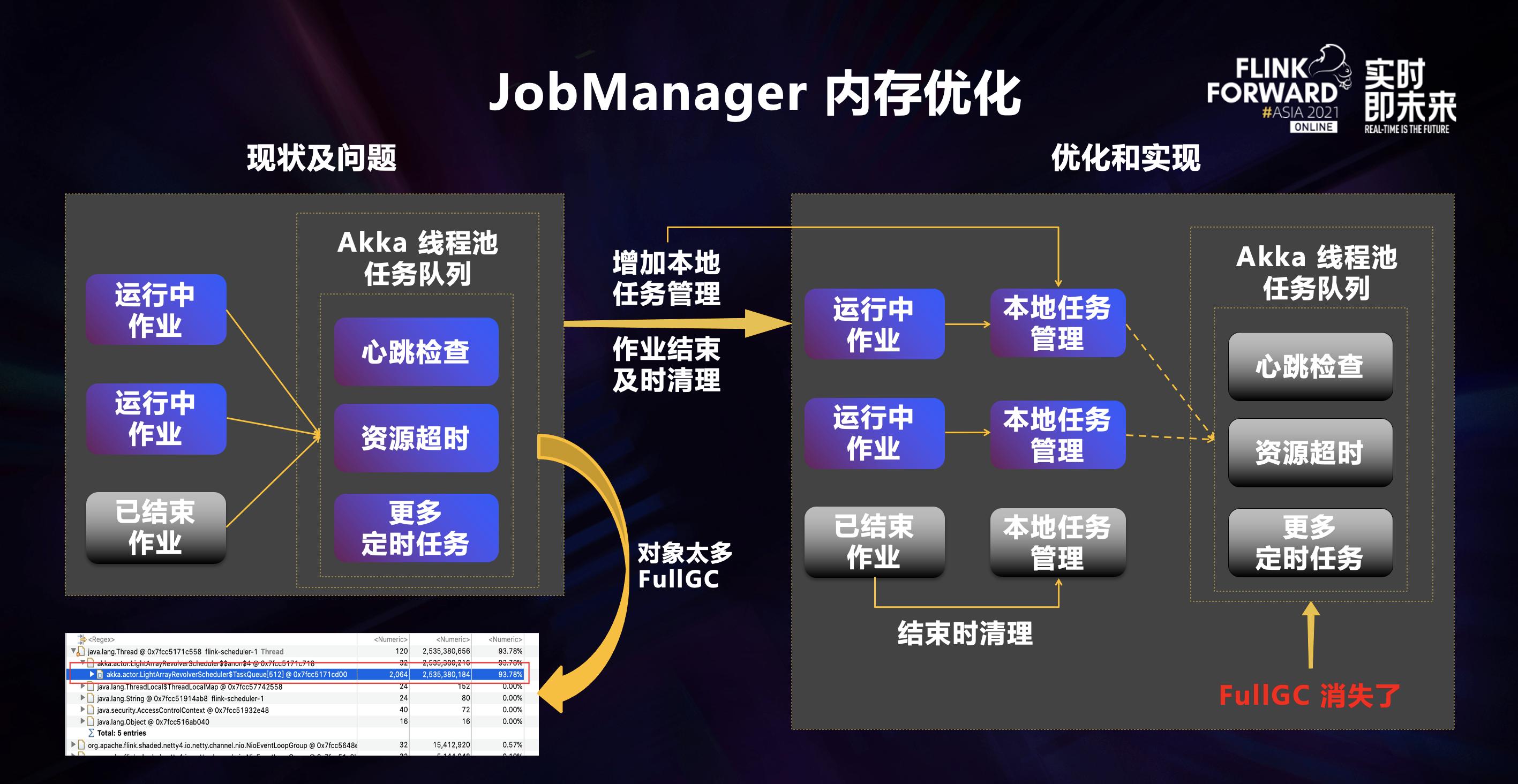
在 Flink 执行作业计算过程中,会有很多定时任务,包括 Flink 各个模块和组件间的心跳检查、作业资源申请过程中的超时检查等。Flink 会将这些定时任务放到 Akka 线程池里定时调度执行,当一个作业已经结束时,这个作业相关的定时任务无法被及时回收和释放。这会使 Akka 线程池里缓存的定时任务过多,导致 JobManager 节点产生大量的 FullGC,根据我们的测试分析,在高 QPS 场景下,JobManager 进程有 90% 左右的内存被这些定时任务占用。
针对这个问题我们也进行相应的优化,在每一个作业启动时会为它创建一个作业级别的本地线程池,作业相关的定时任务会先提交到本地线程池,当这些任务需要被真正执行时,本地线程池会将它们发送到 Akka 线程池直接执行。作业结束后会直接关闭本地线程池,快速释放定时任务资源。
资源申请优化
字节跳动内部目前使用的是 Flink 1.11 版本,Flink 资源申请主要是基于 Slot 维度,我们使用全拉起的作业调度模式,所以作业会等待 Slot 资源全部申请完成之后才会进行计算任务调度。比如,Resource Manager 有 4 个 Slot ,现有两个作业并发申请资源,每个作业都需要三个 Slot,如果它们都只申请到两个 Slot ,就会导致两个作业相互等待 Slot 资源而产生死锁。
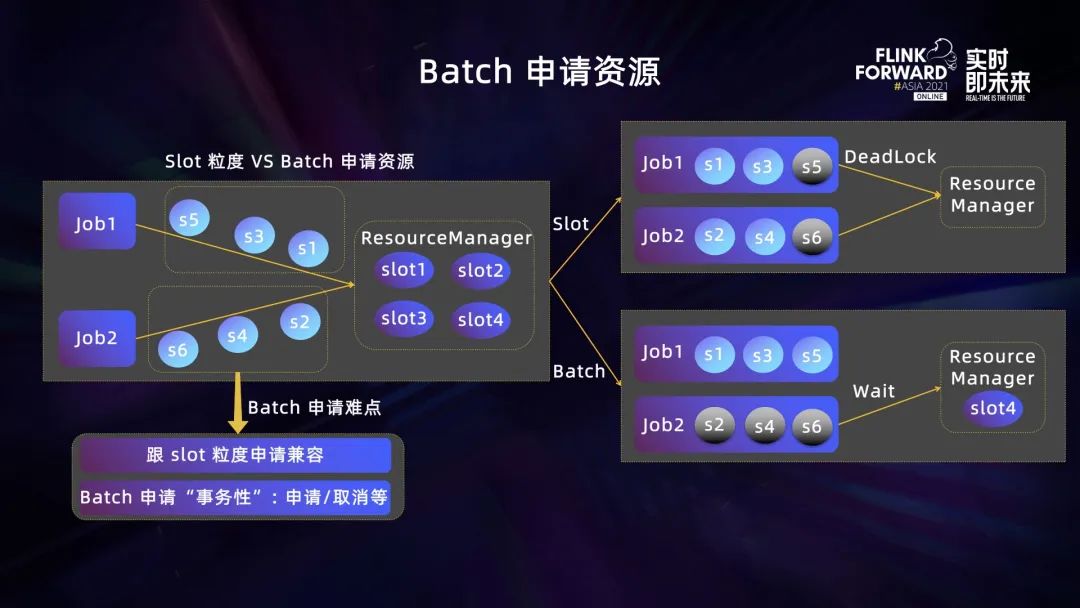
针对这个问题,我们选择将资源申请从 Slot 粒度优化为作业 Batch 粒度,每个作业会将它的资源申请打成 Batch 一次性申请。作业 Batch 粒度的资源申请主要需要解决两个难点:
- 和原先 Slot 粒度的资源申请如何兼容的问题。因为许多机制是基于 Slot 粒度,如资源申请超时处理等,我们实现了两个机制的无缝融合;
- Batch 资源申请的事务性。我们需要保证一个 Batch 内的资源能够同时申请成功或申请失败时同时释放,如果有异常情况,这些资源申请会同时取消。
任务执行优化
■ 作业间连接复用
Flink 上下游计算任务通过 Channel 传输数据,在一个 Flink 作业内部,相同计算节点的网络连接是可以复用的,但是不同作业间的网络连接无法复用。一个作业所有的计算任务结束之后,它在 TaskManager 之间的网络连接会被关闭并且释放。当另外一个作业执行计算时,TaskManager 需要创建新的网络连接,这样就会出现在Flink引擎支持 OLAP 计算时,频繁创建和关闭网络连接,最终影响计算任务的执行性能和作业的 Latency 与 QPS。同时这个过程也会导致资源使用的不稳定,增加 CPU 的使用率和 CPU 的波峰波谷抖动。
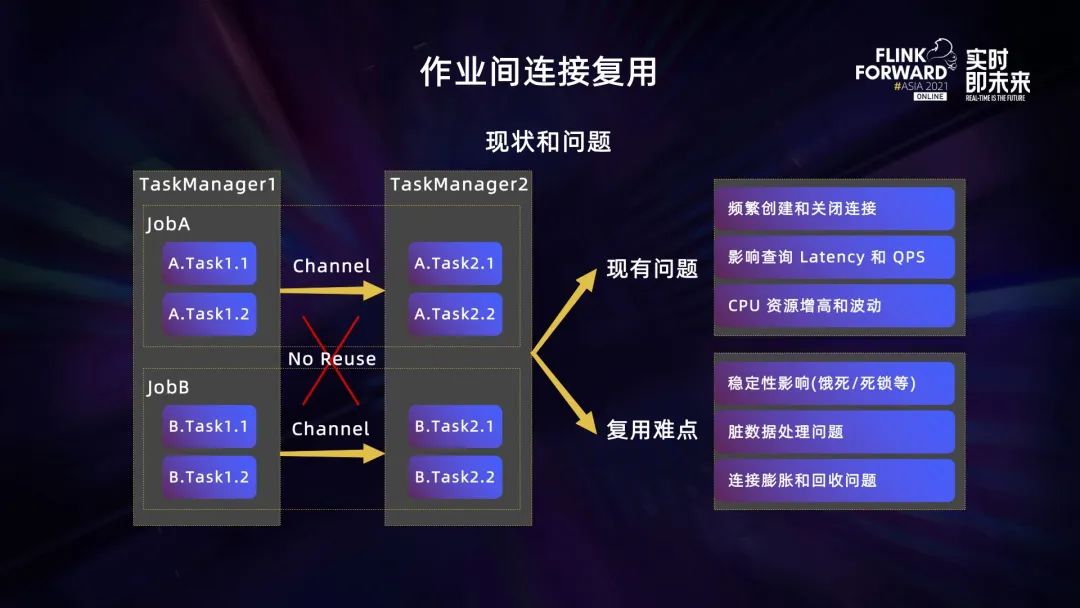
TaskManager 的多作业网络连接复用,主要存在以下几个难点:
- 稳定性问题。Channel 不仅用来做数据传输,而且还与计算任务的反压相关,所以直接复用网络连接可能会导致计算任务饿死以及死锁等问题;
- 脏数据问题。不同的作业复用网络连接有可能引起计算任务在执行过程中产生脏数据;
- 网络连接膨胀和回收问题。对于不再使用的网络连接,我们需要及时探测并且关闭,释放资源。
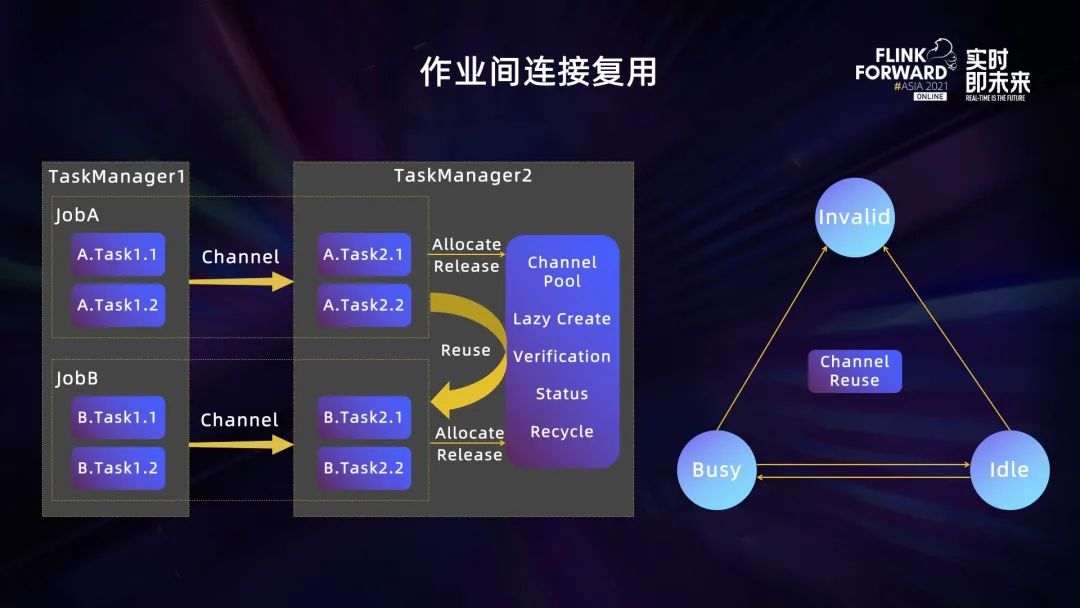
我们实现的 Flink 作业间网络连接复用,主要方案是在 TaskManager 内增加一个 Netty 连接池,计算任务需要创建网络连接时,先向连接池发起请求,连接池根据需要创建或复用已经存在的连接;计算任务完成计算后,会向连接池释放连接。
为了保证系统的稳定性,Flink 现有作业内的网络连接使用机制保持不变,上下游计算任务交互时增加发送连接校验。每个 Netty 连接有三个状态,分别是 Idle、Busy 以及 Invalid。网络连接池会管理网络连接的三个状态,后台有定时任务会检查连接状态,同时根据需要创建和回收网络连接。
■ PartitionRequest 优化
Partition Request 优化主要分为两个方面:Batch 优化和通知机制优化。
一个作业内上下游计算任务创建连接后,下游的计算任务会向上游发送一个 Partition Request 消息,告诉上游任务需要接收哪些 Partition 数据的信息。Partition Request 消息最大的问题是消息量太大,是上下游计算节点并发度的平方量级。
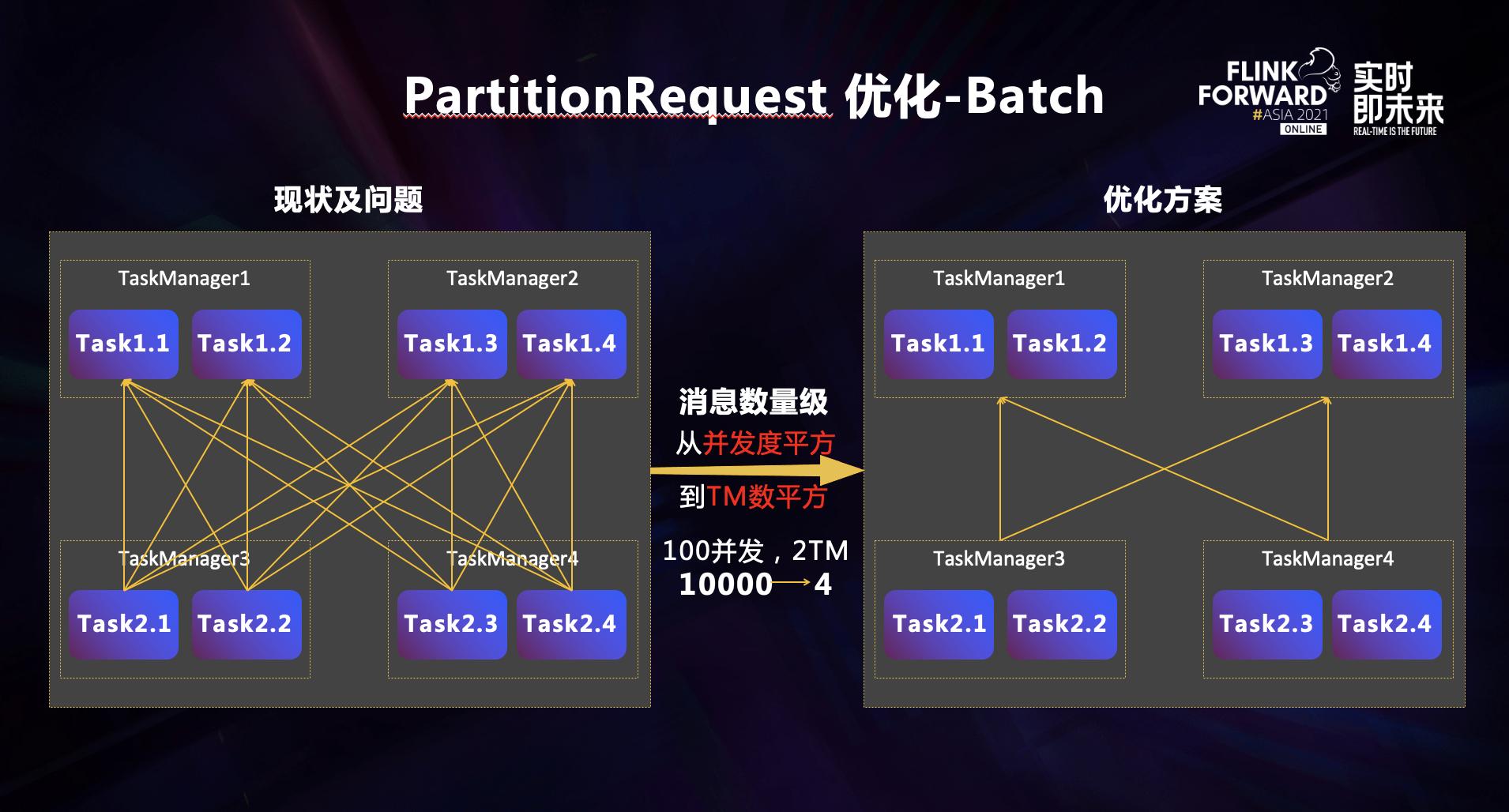
Batch 优化的主要目的是将相同 TaskManager 内上下游计算任务间的 Partition Request 消息数量进行打包处理,降低 Partition Request 的量级。优化过后,在一个计算节点 100 并发的情况下,两个 TaskManager Partition Request 数量可以从原先的 100100 降低到现在的 22,由并发的平方降为 TaskManager 数量的平方,改善非常明显。
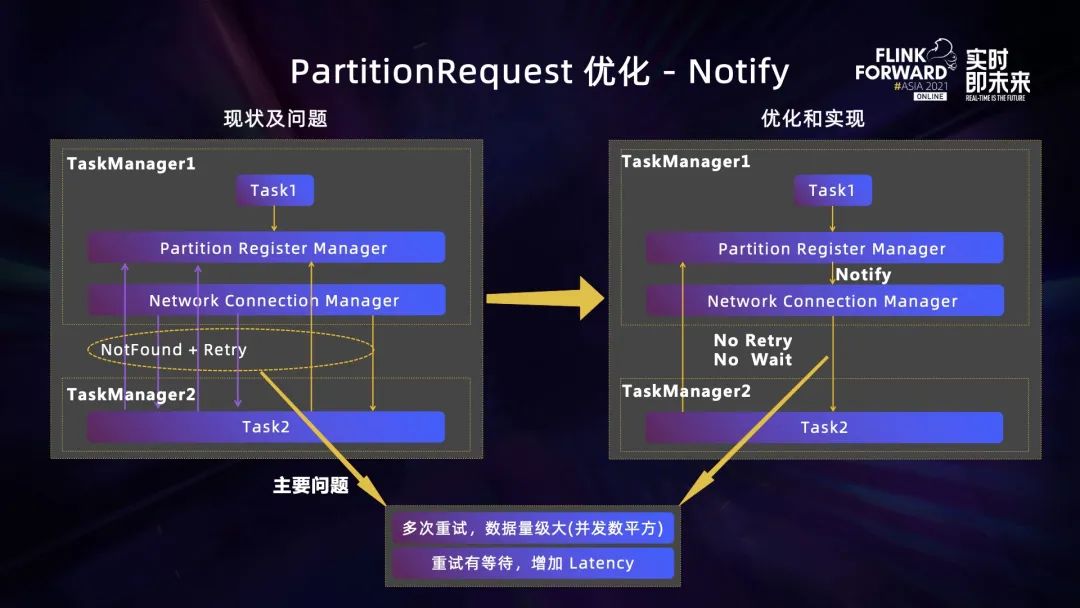
由于上下游的计算任务是并行部署的,所以会存在下游计算任务部署完成之后,上游的计算任务还没有开始部署的情况。当下游的计算任务向上游发送一个 Partition Request 时,上游的 TaskManager 会返回一个 Partition Not Found 的异常,下游的计算任务根据这个异常会不断重试和轮询,直到请求完成。
这个过程存在两个问题,一个是 Partition Request 数量过多,另外一个是下游的计算任务在轮询重试的过程中有时间差,导致计算任务的 Latency 加大。所以我们为上下游计算任务交互实现了一个 Listen+Notify 机制。上游的 TaskManager 接受到下游计算任务发送的 Partition Request 时,如果上游的计算任务还未部署,则会将 Partition Request 放入到一个 Listen 列表里,计算任务部署完成再从计算队列里面获取 Partition Request ,并且回调执行完成整个交互。
■ 网络内存池优化
TaskManager 启动后,会预先分配一块内存作为网络内存池,计算任务在 TaskManager 部署时会从网络内存池里分配一个本地内存池,并加入到网络内存池列表。计算任务创建本地内存池后,申请内存分片以及释放本地内存池等所有操作时,网络内存池会遍历本地内存池列表,TaskManager 中并行执行的计算任务很多时,这个遍历的次数会非常大,是 Slot 的数量乘以上游并发度的数量,甚至会达到千万量级。
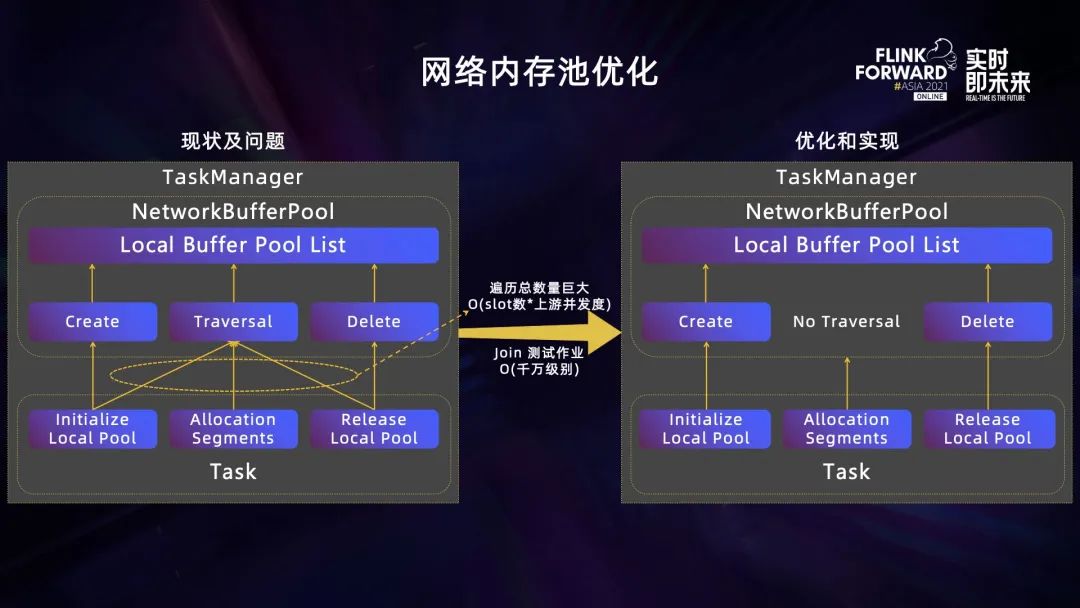
遍历的主要目的是提前释放其他本地内存池中空闲的内存分片,提升内存的使用率。我们的主要优化是将遍历操作删去,虽然这会造成一部分的内存浪费,但能够极大地提升计算任务的执行性。
除了上述优化,我们还做了很多其他的优化和改造。
- 在计算调度方面,我们支持实现全拉起和 Block 结合的调度模式;
- 在执行计划方面,我们优化和实现了很多计算下推,将计算下推到存储去执行;
- 在任务执行方面,我们针对任务的拉起和初始化都做了很多相关的优化和实现。
调度 Benchmark 优化
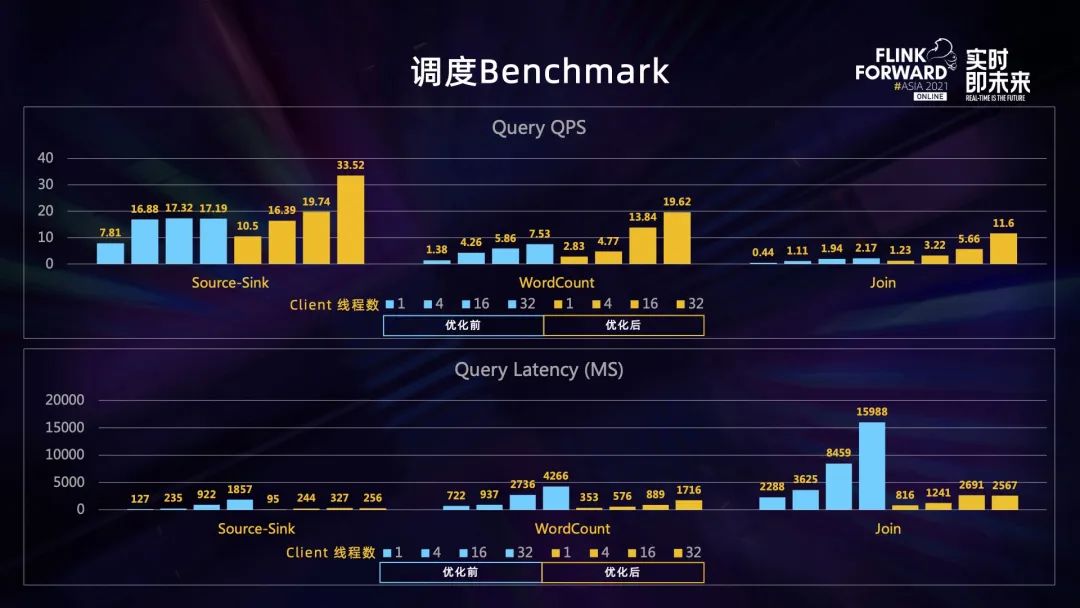
调度 Benchmark 的优化效果
完成作业调度和执行优化后,我们对优化后的 Flink 集群进行 Benchmark 测试。
QPS 测试结果:最大 QPS 提升显著
- 单节点作业 QPS 从原先的 17 提升到现在的 33;
- Wordcount 两节点作业最高 QPS 从 7.5 提升到 20 左右;
- Join 作业从原先最高的 2 左右提升到现在 11 左右。
Latency 测试结果:32 个 线程 下 Latency 下降明显
- 单节点作业的 Latency 从原先的 1.8 秒降低到 200 毫秒左右;
- Wordcount 两节点作业从 4 秒降低到 2 秒不到;
- Join 作业从原先的 15 秒降为 2.5 秒左右。
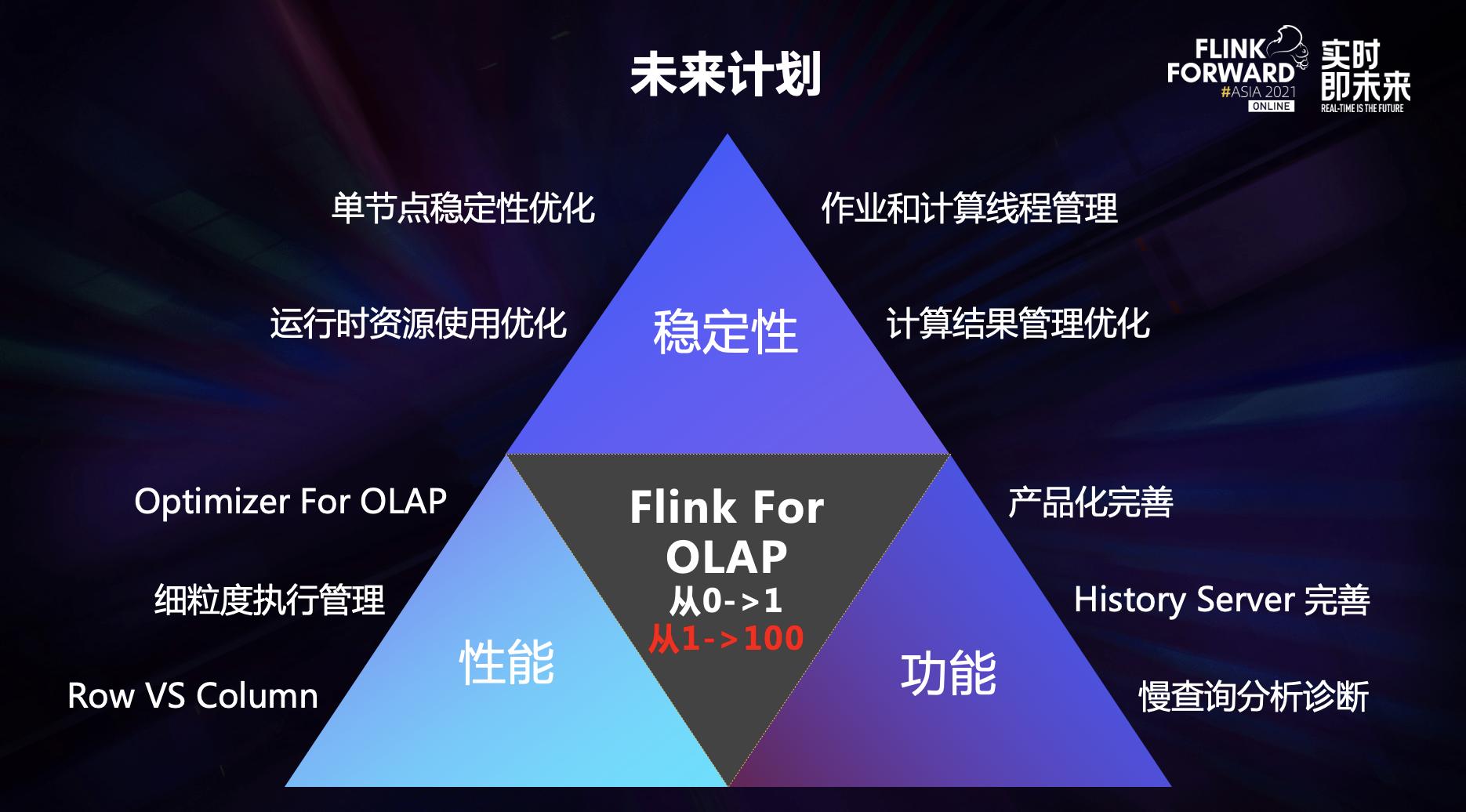
现在 Flink OLAP 虽然在实际业务场景中已经投入使用,但在很多方面还需要继续打磨和优化,我们将这块主要分为三大部分:稳定性、性能和功能。
稳定性方面
- 提升单点的稳定性,包括资源管理单点以及作业管理单点;
- 优化运行时的资源使用及计算线程等管理,优化 OLAP 计算结果管理;
- 其他更多稳定性相关优化。
性能方面
- 包括计划优化、细粒度计算任务执行和管理优化等;
- 面向行和列的计算优化,包括向量化计算等。
功能方面
- 持续完善产品化建设,包括 History Server 的持续完善和建设;
- 完善 Web 分析工具,帮助业务方更好地定位在查询过程中发现的问题。
火山引擎流式计算 Flink 版现已上线。
添加小助手微信,了解更多 Flink OLAP 相关信息👇
