




前言
不管是线下办公,还是居家办公,摸鱼必不可少(当然不提倡摸鱼),可是摸鱼归摸鱼,工作总得完成,KPI 得好看,才能走向人生巅峰。不然月月 3.25,年年得吃土,你有多痛苦,老板不清楚,让你加入毕业队伍,你只会大骂人心不古。押韵吧,KPI 要好看,活得干的好,干的有效率,平时还想摸摸鱼,那摸鱼神器不得备一套,额。。。不,是高效办公神器必须得攒一套。这不,自动化办公的神器双手奉上,废话不多说,上才艺。
说到办公,每天都少不了要和各种文档打交道,csv,excel,word,ppt,pdf 甚至 txt 文本文件,需要对这些文档做各种操作,有很多还是比较机械化的重复工作,枯燥且无味,花时间勉强能够处理,就是有点废手,特别是作为开发人员,有时候需要给大量数据做分析,要对 excel 表格和 csv 中数据整理操作必不可少。所以,作为爱动手的程序猿怎么能放过炫技的时刻呢。能用代码批量解决的绝不操作两次,神器在手,天下我有,代码一粘,两手一摊,一劳永逸。
多亏找到了这些神器,最近可被各种文档表格,各种数据搞疯了,脑瓜子嗡嗡的。在这上面还闹过一些小乌龙,为了相互转各种文档还当冤大头买了 wps 的超级会员我知道 java 写点代码能搞,但是太费时间,还不太理想,没想到 python 有些就几行代码的事。之前领导丢给我十几个 excel 让我合到一起,几行代码的事我硬是手工搞了半天。有一次让我根据他发给我的一堆 PDF 准备 PPT,又搞了一天,因为 word 文档发给客户排版会变,让我转成 PDF,为了这些事真是没辙,开了 WPS 的会员。流下了没技术的眼泪,心疼我白花花的银子。自从使用过 python 的神器之后,犹如哥伦布发现新大陆,都是几行代码的事,多的也就大概 100 行左右。就这。。
说了半天,下面接着进入期待已久的实操阶段,毕竟实践才是检验真理的唯一标准,有请最简单易上手的且对新手友好的 python 选手出战,Python 在自动化方面有极大优势,其实不管大数据分析,人工智能,自动办公……都不在话下,特别能打
环境准备
工欲善其事必先利其器,不管任何编程语言在开发之前,必须搭建好支撑代码运行的环境以及开发环境,运行环境是程序跑起来的基础,相当于一个翻译,所以没有环境的支撑,相当于语言不通,只能是鸡同鸭讲。这里推荐安装 Anaconda,Anaconda 是包管理器和环境管理器,是一个集成的环境,Anaconda 已经自带安装好了 Python,不需要你再安装 Python,大大降低安装的难度,而且还自带了 Jupyter Notebook 代码编辑器,安装了 Anaconda 基本无需再安装其他工具就可以愉快地开发起来
不过还是建议安装 pyCharm 代码编辑器进行开发,而且这篇文章代码的编写也是基于 pycharm
工具
Anaconda https://anaconda.en.softonic.com/\
pyCharm https://www.jetbrains.com/pycharm/download/#section=windows\
这里不再赘述两者的安装步骤,可参考官网或网上者其他教程。
安装第三方库的命令
pip install xxx、pip3 install xxx或者conda install xxx
1.PPT-能造一切的神器
ppt 可谓是家喻户晓,不管各行各业都能用得上,会议必备,有一些公司的成功,完全就是因为 ppt 做得好,真的是只有你想不到,比如 PPT 造车,不仅如此,听说秀得好,还能用 ppt 做游戏,但是像我不想做 ppt,对 PPT 一脸抗拒的人,只想应付了事,会议上简单展示即可,我宁愿写代码,所以我在想,能不能这段代码,生成 PPT,一劳永逸,经过努力寻找,发现还真有这神奇的东西,上菜:
PPT 自动化能干什么?有什么优势?
- 它可以代替你自动制作 PPT
- 它可以减少你调整用于调整 PPT 格式的时间
- 它可以让数据报告风格一致
- 总之就是:它能提高你的工作效率!让你有更多时间去做其他事情!
a.pdf 转 ppt
这是快速制作会议 PPT 神技之一,值得收藏
# -*- coding: utf-8 -*-
from pptx import Presentation
from pdf2image import convert_from_path, convert_from_bytes
from pdf2image.exceptions import (
PDFInfoNotInstalledError,
PDFPageCountError,
PDFSyntaxError
)
from sys import argv
from PIL import Image
from pptx.enum.shapes import MSO_SHAPE
from pptx.util import Inches, Pt
from pptx.dml.color import RGBColor
from pathlib import Path
fff=argv[1]
pp=Path.cwd()
fn=fff+'.pdf'
filename=pp/fn
print("Creating %s" % fff)
prs = Presentation()
width,height=argv[3].split('x')
prs.slide_width = Inches(16)
prs.slide_height = Inches(10)
pages = convert_from_path(filename,dpi=int(argv[2]), size=(int(width)*100,int(height)*100))
jpgs=pp/'jpgs'
if not jpgs.exists():
jpgs.mkdir()
for index, page in enumerate(pages):
name=fff+"-(%d).png" % index
jpg_file =jpgs/name
# print(jpg_file)
page.save(jpg_file, 'PNG')
image = Image.open(jpg_file)
height = image.height
width = image.width
#
if height > width:
adjusted = image.rotate(270, expand=True)
adjusted.save(jpg_file)
#
#
title_slide_layout = prs.slide_layouts[6]
slide = prs.slides.add_slide(title_slide_layout)
left = top = 0
jpg_file=str(jpg_file)
print(jpg_file)
slide.shapes.add_picture(jpg_file, left,top,height = prs.slide_height)
pptname='%s.pptx' % fff
prs.save(pp/pptname)
print("Saved")
pdf 转图片,上面的代码的原理是先把 PDF 每一页转化为图片,然后写入 PPT 中
import os
import sys
import fitz
from reportlab.lib.pagesizes import portrait
from reportlab.pdfgen import canvas
from PIL import Image
def pdf2img(filename=r'./pw.pdf'):
# 打开PDF文件,生成一个对象
doc = fitz.open(filename)
print("共",doc.pageCount,"页")
for pg in range(doc.pageCount):
print("\r转换为图片",pg+1,"/",doc.pageCount,end="")
page = doc[pg]
rotate = int(0)
# 每个尺寸的缩放系数为8,这将为我们生成分辨率提高64倍的图像。
zoom_x = 8.0
zoom_y = 8.0
trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate)
pm = page.getPixmap(matrix=trans, alpha=False)
pm.writePNG(r'./tu'+'{:02}.png' .format(pg))
print()
b.ppt 转 pdf
其实这里包含了合并多张图片到 pdf 文档中
import comtypes.client
import os
def init_powerpoint():
powerpoint = comtypes.client.CreateObject("Powerpoint.Application")
powerpoint.Visible = 1
return powerpoint
def ppt_to_pdf(powerpoint, inputFileName, outputFileName, formatType = 32):
if outputFileName[-3:] != 'pdf':
outputFileName = outputFileName[0:-4] + ".pdf"
deck = powerpoint.Presentations.Open(inputFileName)
deck.SaveAs(outputFileName, formatType) # formatType = 32 for ppt to pdf
deck.SaveAs(inputFileName.rsplit('.')[0] + '.jpg', 17)
deck.Close()
def convert_files_in_folder(powerpoint, folder):
files = os.listdir(folder)
pptfiles = [f for f in files if f.endswith((".ppt", ".pptx"))]
for pptfile in pptfiles:
fullpath = os.path.join(cwd, pptfile)
ppt_to_pdf(powerpoint, fullpath, fullpath)
if __name__ == "__main__":
powerpoint = init_powerpoint()
cwd = os.getcwd()
convert_files_in_folder(powerpoint, cwd)
powerpoint.Quit()
运行之后,会循环所有的 PPT 文件,进行转化,如下图,PPT 一共 3 页,转出 3 张图片,然年写入 pdf

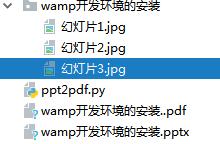
这是转化后的 pdf:

c.word 转 ppt
有时候我们只拿到一些文字表述或者别人整理的 word 文档资料,这时候我们可以使用 word 转 PPT 的功能快速制作会议需要的 PPT
word 转 ppt 的原理是先把 word 转 PDF 然后把 PDF 转 PPT, 第一节(PPT-能打造一切的神器)和第二节(PDF 与 Word-办公文档常客) 结合即可以实现.而且为控制文章篇幅这里不再重复展示代码.
d.ppt 转 word
会议之后,我们拿到别人分享的 PPT,觉得很多很好的地方想写成一篇 word,整理成自己会议心得以及归档,这时候这个功能就能起到很好的辅助作用
方法 1.ppt 转 word 的原理是先把 PPT 转 PDF 然后把 PDF 转 word, 第一节(PPT-能打造一切的神器)和第二节(PDF 与 Word-办公文档常客) 结合即可以实现.而且为控制文章篇幅这里不再重复展示代码.
方法 2
pip install python-pptx
pip install python-docx
代码如下:
from pptx import Presentation
from docx import Document
wordfile = Document()
# 给定ppt文件所在的路径
filepath = r'**.pptx'
pptx = Presentation(filepath)
# 遍历ppt文件的所有幻灯片页
for slide in pptx.slides:
# 遍历幻灯片页的所有形状
for shape in slide.shapes:
# 判断形状是否含有文本框,如果含有则顺序运行代码
if shape.has_text_frame:
# 获取文本框
text_frame = shape.text_frame
# 遍历文本框中的所有段落
for paragraph in text_frame.paragraphs:
# 将文本框中的段落文字写入word中
wordfile.add_paragraph(paragraph.text)
if shape.has_table:
# 获取表格
myTable = shape.table
for row in myTable.rows:
for i in range(0, len(myTable.columns)):
tx = row.cells[i].text_frame.text.strip()
# 将文本框中的段落文字写入word中
wordfile.add_paragraph(tx)
save_path = r'***.docx'
wordfile.save(save_path)
e.使用 win32com 操作 ppt
安装 pypiwin32
pip3 install pypiwin32
win32com 复制 ppt 模板
有时候我们需要对 ppt 的模板进行复制,然后再添加相应内容,由于 python-pptx 对复制模板也没有很好的支持,所以我们用 win32com 对模板页进行复制,然后再用 python-pptx 增加 ppt 内容。
参考文档:https://docs.microsoft.com/zh-cn/office/vba/api/powerpoint.slide.copy
先准备好一张模板 ppt
import win32com
from win32com.client import Dispatch
import os
ppt = Dispatch('PowerPoint.Application')
# 或者使用下面的方法,使用启动独立的进程:
# ppt = DispatchEx('PowerPoint.Application')
# 如果不声明以下属性,运行的时候会显示的打开word
ppt.Visible = 1 # 后台运行
ppt.DisplayAlerts = 0 # 不显示,不警告
# 创建新的PowerPoint文档
# pptSel = ppt.Presentations.Add()
# 打开一个已有的PowerPoint文档
pptSel = ppt.Presentations.Open(os.getcwd() + "\" + "wamp开发环境的安装.pptx")
# 复制模板页
pptSel.Slides(1).Copy()
#设置需要复制的模板页数
pageNums = 10
# 粘贴模板页
for i in range(pageNums):
pptSel.Slides.Paste()
# pptSel.Save() # 保存
pptSel.SaveAs(os.getcwd() + "\" + "wamp开发环境的安装copy.pptx") # 另存为
pptSel.Close() # 关闭 PowerPoint 文档
ppt.Quit() # 关闭 office
效果图

python-pptx 创建 PPT、编辑页面
安装 pptx
pip install python-pptx
新建页面
from pptx import Presentation
# 新建ppt
ppt = Presentation()
# 新建页面
slide = ppt.slides.add_slide(ppt.slide_layouts[0])
# 保存ppt
ppt.save('测试ppt.pptx')
效果图
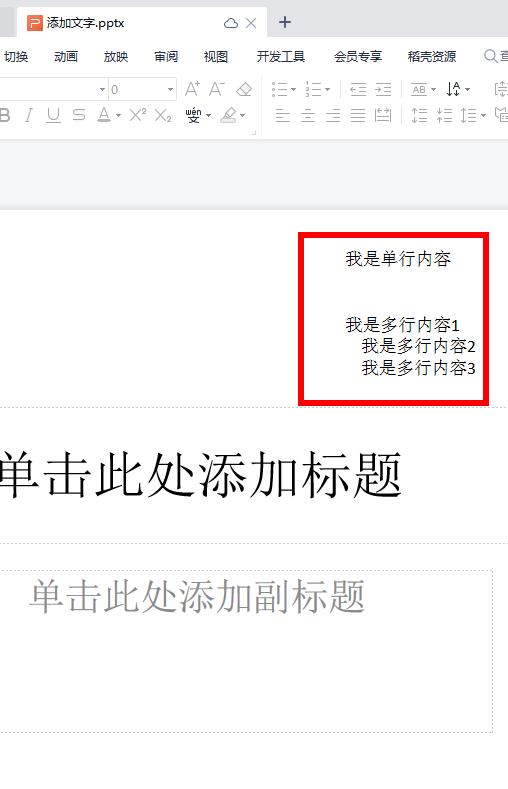
编辑页面
from pptx import Presentation
from pptx.util import Pt, Cm
# 打开已存在ppt
ppt = Presentation('测试ppt.pptx')
# 设置添加到当前ppt哪一页
n_page = 0
singleLineContent = "我是单行内容"
multiLineContent = \
"""我是多行内容1
我是多行内容2
我是多行内容3
"""
# 获取需要添加文字的页面对象
slide = ppt.slides[n_page]
# 添加单行内容
# 设置添加文字框的位置以及大小
left, top, width, height = Cm(16.9), Cm(1), Cm(12), Cm(1.2)
# 添加文字段落
new_paragraph1 = slide.shapes.add_textbox(left=left, top=top, width=width, height=height).text_frame
# 设置段落内容
new_paragraph1.paragraphs[0].text = singleLineContent
# 设置文字大小
new_paragraph1.paragraphs[0].font.size = Pt(15)
# 添加多行
# 设置添加文字框的位置以及大小
left, top, width, height = Cm(16.9), Cm(3), Cm(12), Cm(3.6)
# 添加文字段落
new_paragraph2 = slide.shapes.add_textbox(left=left, top=top, width=width, height=height).text_frame
# 设置段落内容
new_paragraph2.paragraphs[0].text = multiLineContent
# 设置文字大小
new_paragraph2.paragraphs[0].font.size = Pt(15)
# 保存ppt
ppt.save('添加文字.pptx')
效果图
这里仅仅是抛砖引玉,还有更多关于 PPT 的高级操作等你发现!
2.PDF 与 Word-办公文档常客
不管任何岗位几乎都会接触到这两种文档,特别是行政类岗位和管理类岗位,平时发布公告消息或者文档手册都会使用到。pdf 和 word 文档之间的转换也是我们最常用到的操作,而且 PDF 相对于 word 来说,打印的布局更稳定,且不易变形,但是 word 的优点在于可自由编辑,接下来我们来了解他们之间的转换以及其他办公场景的应用
a.PDF 转 word
由于 PDF 不方便修改,所以当我们需要增加或者修改文档内容时,就需要把 PDF 转换为 word 进行修改,使用 wps 转换功能需要开通会员才可以转换多页。这时候 Python 这个转换功能就能派上用场。
代码如下:
使用到的模块:pdf2docx
将某个目录下的全部 pdf 转化成 word
import os
from pdf2docx import Converter
def pdf_docx():
# 获取当前工作目录
file_path = os.getcwd()
# 遍历所有文件
for file in os.listdir(file_path):
# 获取文件后缀
suff_name = os.path.splitext(file)[1]
# 过滤非pdf格式文件
if suff_name != '.pdf':
continue
# 获取文件名称
file_name = os.path.splitext(file)[0]
# pdf文件名称
pdf_name = os.getcwd() + '\' + file
# 要转换的docx文件名称
docx_name = os.getcwd() + '\' + file_name + '.docx'
# 加载pdf文档
cv = Converter(pdf_name)
cv.convert(docx_name)
cv.close()
if __name__=='__main__':
pdf_docx()
b.word 转 PDF
很多时候因为我们需要把自己整理的文档资料进行分享,但是 word 文档可能会因为版本的不同以及平台或者环境的不同导致文档排版错乱,变形,这时候就需要转为 PDF 再分享,
转化代码如下:
使用到的模块:docx2pdf
将某个目录下的全部 word 转化成 pdf
from docx2pdf import convert
import os
director = r'E:\prokect\AI\word'
FileList = map(lambda x:director+ '\'+x, os.listdir(director))
for file in FileList:
convert(file,f"{file.split('.')[0]}.pdf")
c.提取 PDF 文字
当我们需要对 PDF 文件上的文字进行复用时,由于 PDF 不方便编辑,而如果 PDF 又有很多页的时候,直接使用 Python 对 PDF 进行文字提取,解放双手,一劳永逸
import PyPDF2
pdfFile = open('example.pdf','rb')
pdfReader = PyPDF2.PdfFileReader(pdfFile)
print(pdfReader.numPages)
page = pdfReader.getPage(0)
print(page.extractText())
pdfFile.close()
还可以把提取到文字存入 txt
import pdfplumber
with pdfplumber.open("example.pdf") as p:
for i in range(75):
page = p.pages[i]
textdata = page.extract_text()
#print(textdata)
data = open("text.text", "a")
data.write(textdata)
d.提取 PDF 表格
当我们拿到的数据都存放在 PDF 的表格上,我们需要对数据做分析,就可以使用 pdfplumber 提取 PDF 上的表格数据
import pdfplumber
with pdfplumber.open("example.pdf") as pdf:
page01 = pdf.pages[0] #指定页码
table1 = page01.extract_table()#提取单个表格
# table2 = page01.extract_tables()#提取多个表格
print(table1)
我们还可以把提取到的表格数据存入 Excel
import pdfplumber
from openpyxl import Workbook
with pdfplumber.open("example.pdf") as p:
workbook = Workbook() #新建空白Excel工作簿
sheet = workbook.active #激活sheet
for i in range(68,75): #遍历69页-75页
page = p.pages[i]
table = page.extract_table() #提取表格数据
#print(table)
for row in table: #遍历所有行
#print(row)
sheet.append(row) #按行追加写入数据
workbook.save("Excel.xlsx") #保存文件,命名为Excel
i += 1
print("第%d页PDF提取完成"%i) #提示提取进度
e.提取 Word 文字
可以通过提取 word 的文字进行重新整理,然后通过其他自动化操作加工利用,比如通过 word 生成 PPT,取 word 的文字和数据整理到 Excel 归档
from docx import Document
doc = Document(r"E:\python办公自动化\getword\test.docx")
print(doc.paragraphs)
for paragraph in doc.paragraphs:
print(paragraph.text)
f.Python 生成合同
在我们经济交往中,有时会涉及到销售合同的批量制作。比如我们需要根据如下合同数据(Excel),进行批量生成销售合同(Word)。
安装相关库
pip install openpyxl
pip install docxtpl
读取合同数据
我们可以通过 load_workbook 方法打开合同数据(Excel 表),然后读取每一个合同数据并存入到 data 字典,再将每个字典放入到列表 datas 中。PS:由于读取的签约日期是一个时间戳,需要通过 strftime 方法转为标准的年月日格式
from docxtpl import DocxTemplate
from openpyxl import load_workbook
wb = load_workbook("数据.xlsx")
ws = wb['Sheet1']
datas = []
for row in range(2, ws.max_row):
name1 = ws[f"A{row}"].value
name2 = ws[f"B{row}"].value
price = ws[f"C{row}"].value
product = ws[f"D{row}"].value
count = ws[f"E{row}"].value
deadline = ws[f"F{row}"].value
time = ws[f"G{row}"].value
time = time.strftime("%Y-%m-%d")
data = {"甲方": name1,
"乙方": name2,
"合同价款": price,
"产品名称": product,
"产品数量": count,
"付款期限": deadline,
"签约时间": time}
datas.append(data)
datas
批量生成合同
for data in datas:
tpl = DocxTemplate('销售合同.docx')
tpl.render(data)
tpl.save(f'合同生成/{data["甲方"]}的销售合同{data["签约时间"]}.docx')
print(f'{data["甲方"]}的销售合同已生成')
效果图如下:




3.Excel-数据分析/数据收集神器
相对于其他办公工具,excel 更加常用且更加重要。他是财会人员或者数据分析师手上分析的神兵利器。管理层可以通过 Excel 上的数据已经可视化图表,了解到整个企业的运营情况,从而制定公司下一步发展策略,不但是汇报工作的必备神器还是公司开疆扩土的利剑
a.Python 处理 Excel 数据
可以使用 pandas、xlwings、openpyxl 等包来对 Excel 进行增删改查、格式调整等操作,甚至可以使用 Python 函数来对 excel 数据进行分析
import xlwings as xw
wb = xw.Book() # this will create a new workbook
wb = xw.Book('FileName.xlsx') # connect to a file that is open or in the current working directory
wb = xw.Book(r'C:\path\to\file.xlsx') # on Windows: use raw strings to escape backslashes
表格将 matplotlib 绘制 excel
import matplotlib.pyplot as plt
import xlwings as xw
fig = plt.figure()
plt.plot([1, 2, 3])
sheet = xw.Book().sheets[0]
sheet.pictures.add(fig, name='MyPlot', update=True)
b.合并 Excel
批量合并现在是我最常用的功能,特别是做数据分析的时候,数据一般存储在一个或者多个 excel 表格中
# -*- coding: utf-8 -*-
import os
import pandas as pd
import numpy as np
dir = "E:\prokect\AI\office\data"#设置工作路径
#新建列表,存放文件名(可以忽略,但是为了做的过程能心里有数,先放上)
filename_excel = []
#新建列表,存放每个文件数据框(每一个excel读取后存放在数据框)
frames = []
for root, dirs, files in os.walk(dir):
for file in files:
#print(os.path.join(root,file))
filename_excel.append(os.path.join(root,file))
df = pd.read_excel(os.path.join(root,file)) #excel转换成DataFrame
frames.append(df)
#打印文件名
print(filename_excel)
#合并所有数据
result = pd.concat(frames)
#查看合并后的数据
result.head()
result.shape
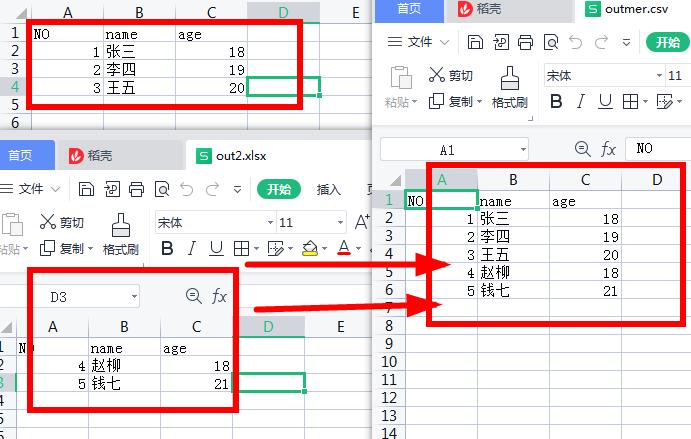
result.to_csv('E:\prokect\AI\office\data\outmer.csv',sep=',',index = False)#保存合并的数据到电脑D盘的merge文件夹中,并把合并后的文件命名为outmer.csv
合并效果图:
4.python 自动控制
对鼠标的自动控制,执行一些流水线的工作,解放双手.比如软件测试。
Python 的 pyautogui 库可以任意地去控制你的鼠标。
鼠标左击/右击/控制左键以及测试脚本
# 获取鼠标位置
import pyautogui as pg
try:
while True:
x, y = pg.position()
print(str(x) + " " + str(y)) #输出鼠标位置
if 1746 < x < 1800 and 2 < y < 33:
pg.click()#左键单击
if 1200 < x < 1270 and 600 < y < 620:
pg.click(button='right')#右键单击
if 1646 < x < 1700 and 2 < y < 33:
pg.doubleClick()#左键双击
except KeyboardInterrupt:
print("\n")
Python 也可以通过 pyautogui 控制键盘。
写键盘
import pyautogui
#typewrite()无法输入中文内容,中英文混合的只能输入英文
#interval设置文本输入速度,默认值为0
pyautogui.typewrite('你好,world!',interval=0.5)
5.python 文字提取
别人分享的资料或者自己找到的资料可能是截图或者是张图片,你觉得内容很好,想借鉴一下,但是又不太想打字,就可以使用 Python 提取文字,特别是当你有多张图片的时候可以批量快速提取然后保存到 Excel 或者 txt,以便使用.
使用 Tesseract-OCR 简单图片识别
安装所需的库
pip3 install pytesseract
pip3 install pillow
具体代码如下:
import pytesseract
from PIL import Image
#如果报错可能是没把tesseract设置到环境变量中,可以设置系统环境变量或者添加如下代码:在代码中指定识别程序
pytesseract.pytesseract.tesseract_cmd = 'E:/Program Files/Tesseract-OCR/tesseract.exe'
tessdata_dir_config = '--tessdata-dir "E:/Program Files/Tesseract-OCR/tessdata"'
image = Image.open("my.png")
result = pytesseract.image_to_string(image, config=tessdata_dir_config)
print(result)#打印识别的图片内容
批量识别图片(以识别证件为例)
批量文字识别(OCR)是
Python办公自动化的基本操作,应用在我们工作生活中的方方面面,比如车牌识别、证件识别、银行卡识别、票据识别等等。Python 中
OCR第三方库非常多,比如easyocr、PaddleOCR、cnocr等等。当然,直接调用百度API也是可以的,不过超过一定限额后要收费,因此本文主要以开源免费的easyocr来进行介绍。
运用easyocr进行识别并保存为Excel,效果如下:(详细代码)

安装 easyocr
pip install easyocr
1.easyocr识别图片代码非常简洁,只需要创建一个easyocr.Reader类对象,指定以下两个常用参数:
- 需要识别的文字属于哪几种语言
- 是否启用 GPU 显卡加速
2.调用Reader对象的readtext方法,将图片中所有文字读入一个列表并返回。
代码如下:
import easyocr
import os
# 指明所有图片所在的文件夹
images = './id_card'
# 创建ocr的reader对象,识别中英文
ocr = easyocr.Reader(['ch_sim', 'en'])
# 识别图片文字
content = ocr.readtext(images,detail=0)
# 遍历所有图片并识别文字,切片提取有效信息
data = []
for image in os.listdir(images):
content = ocr.readtext(f'{images}/{image}', detail=0)
print(f"正在识别:{image}")
name = content[0][4:]
gender = content[1][-1]
nation = content[2][-1]
birth = content[-5]
if "月" not in birth:
birth = content[-6] + "月" + content[-5]
if "日" not in birth:
birth = birth[:-1] + "日"
address = content[-4][4:] + content[-3]
number = content[-1]
print(f"完成识别:{image}")
print("-" * 50)
data.append([name, gender, nation, birth, address, number])
图片文字识别之后,建议通过pandas输出为Excel,方便简洁。
#保存数据到Excel
import pandas as pd
# 保存识别结果至Excel
df = pd.DataFrame(data, columns=["姓名", "性别", "民族", "出生", "住址", "身份证号"])
print(f"识别结果如下:")
print(df)
df.to_excel("识别结果.xlsx", index=False)
还有更简单的方式,使用百度的文字识别接口
import requests
import base64
def ocr(img_path: str) -> list:
'''
根据图片路径,将图片转为文字,返回识别到的字符串列表
'''
# 请求头
headers = {
'Host': 'cloud.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.76',
'Accept': '*/*',
'Origin': 'https://cloud.baidu.com',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://cloud.baidu.com/product/ocr/general',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
# 打开图片并对其使用 base64 编码
with open(img_path, 'rb') as f:
img = base64.b64encode(f.read())
data = {
'image': 'data:image/jpeg;base64,'+str(img)[2:-1],
'image_url': '',
'type': 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic',
'detect_direction': 'false'
}
# 开始调用 ocr 的 api
response = requests.post(
'https://cloud.baidu.com/aidemo', headers=headers, data=data)
# 设置一个空的列表,后面用来存储识别到的字符串
ocr_text = []
result = response.json()['data']
if not result.get('words_result'):
return []
# 将识别的字符串添加到列表里面
for r in result['words_result']:
text = r['words'].strip()
ocr_text.append(text)
# 返回字符串列表
return ocr_text
'''
img_path 里面填图片路径,这里分两种情况讨论:
第一种:假设你的代码跟图片是在同一个文件夹,那么只需要填文件名,例如 test1.jpg (test1.jpg 是图片文件名)
第二种:假设你的图片全路径是 D:/img/test1.jpg ,那么你需要填 D:/img/test1.jpg
'''
img_path = 'test1.jpg'
# content 是识别后得到的结果
content = "".join(ocr(img_path))
# 输出结果
print(content)
6.提取 word/PDF 的图片
有时候我们需要用到的图片是存在 word 或者 PDF 中,手动一张张另存太费事了,批量保存图片你值得拥有
a.提取 word 图片
代码如下:
import zipfile
import os
import shutil
def word2pic(path, zip_path, tmp_path, store_path):
'''
:param path:源文件
:param zip_path:docx重命名为zip
:param tmp_path:中转图片文件夹
:param store_path:最后保存结果的文件夹(需要手动创建)
:return:
'''
# 将docx文件重命名为zip文件
os.rename(path, zip_path)
# 进行解压
f = zipfile.ZipFile(zip_path, 'r')
# 将图片提取并保存
for file in f.namelist():
f.extract(file, tmp_path)
# 释放该zip文件
f.close()
# 将docx文件从zip还原为docx
os.rename(zip_path, path)
# 得到缓存文件夹中图片列表
pic = os.listdir(os.path.join(tmp_path, 'word/media'))
# 将图片复制到最终的文件夹中
for i in pic:
# 根据word的路径生成图片的名称
new_name = path.replace('\', '_')
new_name = new_name.replace(':', '') + '_' + i
shutil.copy(os.path.join(tmp_path + '/word/media', i), os.path.join(store_path, new_name))
# 删除缓冲文件夹中的文件,用以存储下一次的文件
for i in os.listdir(tmp_path):
# 如果是文件夹则删除
if os.path.isdir(os.path.join(tmp_path, i)):
shutil.rmtree(os.path.join(tmp_path, i))
if __name__ == '__main__':
# 源文件
path = r'E:\word2pdf\提取图片\log.docx'
# docx重命名为zip
zip_path = r'E:\word2pdf\提取图片\log.zip'
# 中转图片文件夹
tmp_path = r'E:\word2pdf\提取图片\tmp'
# 最后保存结果的文件夹
store_path = r'E:\word2pdf\提取图片\测试'
m = word2pic(path, zip_path, tmp_path, store_path)
b.提取 PDF 图片
代码如下:
#安装pip install pymupdf
import fitz
import time
import re
import os
def pdf2pic(path, pic_path):
'''
# 从pdf中提取图片
:param path: pdf的路径
:param pic_path: 图片保存的路径
:return:
'''
t0 = time.clock()
# 使用正则表达式来查找图片
checkXO = r"/Type(?= */XObject)"
checkIM = r"/Subtype(?= */Image)"
# 打开pdf
doc = fitz.open(path)
# 图片计数
imgcount = 0
lenXREF = doc._getXrefLength()
# 打印PDF的信息
print("文件名:{}, 页数: {}, 对象: {}".format(path, len(doc), lenXREF - 1))
# 遍历每一个对象
for i in range(1, lenXREF):
# 定义对象字符串
text = doc.getObjectString(i)
isXObject = re.search(checkXO, text)
# 使用正则表达式查看是否是图片
isImage = re.search(checkIM, text)
# 如果不是对象也不是图片,则continue
if not isXObject or not isImage:
continue
imgcount += 1
# 根据索引生成图像
pix = fitz.Pixmap(doc, i)
# 根据pdf的路径生成图片的名称
new_name = path.replace('\', '_') + "_img{}.png".format(imgcount)
new_name = new_name.replace(':', '')
# 如果pix.n<5,可以直接存为PNG
if pix.n < 5:
pix.writePNG(os.path.join(pic_path, new_name))
# 否则先转换CMYK
else:
pix0 = fitz.Pixmap(fitz.csRGB, pix)
pix0.writePNG(os.path.join(pic_path, new_name))
pix0 = None
# 释放资源
pix = None
t1 = time.clock()
print("运行时间:{}s".format(t1 - t0))
print("提取了{}张图片".format(imgcount))
if __name__=='__main__':
# pdf路径
path = r'E:\word2pdf\提取图片\课件.pdf'
pic_path = r'E:\word2pdf\提取图片\测试'
# 创建保存图片的文件夹
if os.path.exists(pic_path):
print("文件夹已存在,请重新创建新文件夹!")
raise SystemExit
else:
os.mkdir(pic_path)
m = pdf2pic(path, pic_path)
7.Python 生成图文并茂的 PDF 报告
reportlab 简直是工作报告神器,写完代码一劳永逸,毕竟我是宁愿写代码也不愿做文档的人,而且代码是可以复用的~
reportlab 是 Python 的一个标准库,可以画图、画表格、编辑文字,最后可以输出 PDF 格式。它的逻辑和编辑一个 word 文档或者 PPT 很像。有两种方法:
1)建立一个空白文档,然后在上面写文字、画图等;
2)建立一个空白 list,以填充表格的形式插入各种文本框、图片等,最后生成 PDF 文档。
因为需要产生一份给用户看的报告,里面需要插入图片、表格等,所以采用的是第二种方法。
安装第三方库
reportlab 输入 Python 的第三方库,使用前需要先安装:pip install reportlab
提前导入相关内容,并且注册字体。(注册字体前需要先准备好字体文件)
from reportlab.pdfbase import pdfmetrics # 注册字体
from reportlab.pdfbase.ttfonts import TTFont # 字体类
from reportlab.platypus import Table, SimpleDocTemplate, Paragraph, Image # 报告内容相关类
from reportlab.lib.pagesizes import letter # 页面的标志尺寸(8.5*inch, 11*inch)
from reportlab.lib.styles import getSampleStyleSheet # 文本样式
from reportlab.lib import colors # 颜色模块
from reportlab.graphics.charts.barcharts import VerticalBarChart # 图表类
from reportlab.graphics.charts.legends import Legend # 图例类
from reportlab.graphics.shapes import Drawing # 绘图工具
from reportlab.lib.units import cm # 单位:cm
# 注册字体(提前准备好字体文件, 如果同一个文件需要多种字体可以注册多个)
pdfmetrics.registerFont(TTFont('SimSun', 'SimSun.ttf'))
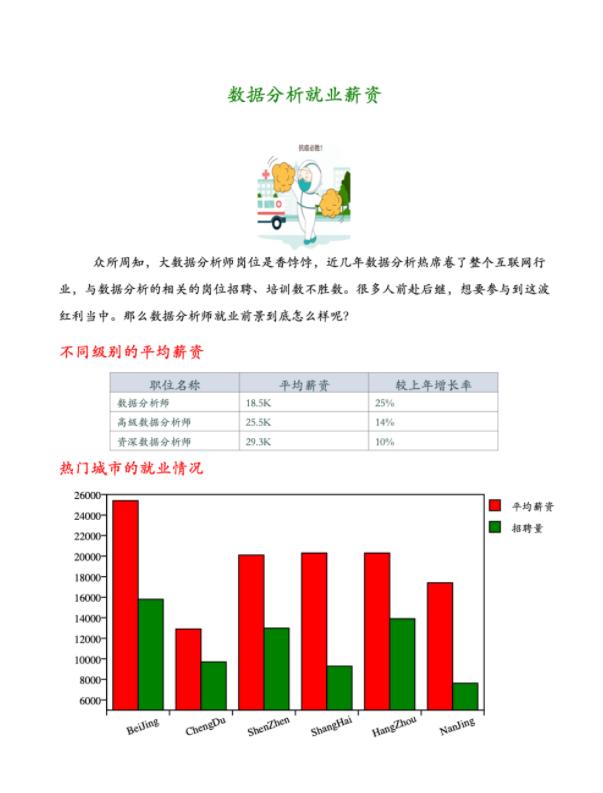
这里就不贴代码了.这个链接写的很详细(生成图文并茂的PDF报告代码)
效果图:
8.Python 处理邮件
在 Python 中可以使用 smtplib 配合电子邮件库,来实现邮件的自动化传输,非常方便。
import smtplib
import email
# 负责将多个对象集合起来
from email.mime.multipart import MIMEMultipart
from email.header import Header
# SMTP服务器,这里使用163邮箱
mail_host = "smtp.163.com"
# 发件人邮箱
mail_sender = "******@163.com"
# 邮箱授权码,注意这里不是邮箱密码,如何获取邮箱授权码,请看本文最后教程
mail_license = "********"
# 收件人邮箱,可以为多个收件人
mail_receivers = ["******@qq.com","******@outlook.com"]
mm = MIMEMultipart('related')
# 邮件正文内容
body_content = """你好,这是一个测试邮件!"""
# 构造文本,参数1:正文内容,参数2:文本格式,参数3:编码方式
message_text = MIMEText(body_content,"plain","utf-8")
# 向MIMEMultipart对象中添加文本对象
mm.attach(message_text)
# 创建SMTP对象
stp = smtplib.SMTP()
# 设置发件人邮箱的域名和端口,端口地址为25
stp.connect(mail_host, 25)
# set_debuglevel(1)可以打印出和SMTP服务器交互的所有信息
stp.set_debuglevel(1)
# 登录邮箱,传递参数1:邮箱地址,参数2:邮箱授权码
stp.login(mail_sender,mail_license)
# 发送邮件,传递参数1:发件人邮箱地址,参数2:收件人邮箱地址,参数3:把邮件内容格式改为str
stp.sendmail(mail_sender, mail_receivers, mm.as_string())
print("邮件发送成功")
# 关闭SMTP对象
stp.quit()
9.Python 处理文件
处理文件一直是个脏活累活,而且特别机械,枯燥,Python 可以帮你脱离苦海。Python 中有很多文件,sys、os、shutil、glob、path.py 等等。
修改文件后缀名
日常工作中,除了查找文件就是修改文件后缀了,批量操作一劳永逸
import os
def file_rename():
path = input("请输入你需要修改的目录(格式如'E:\test'):")
old_suffix = input('请输入你需要修改的后缀(需要加点.):')
new_suffix = input('请输入你要改成的后缀(需要加点.):')
file_list = os.listdir(path)
for file in file_list:
old_dir = os.path.join(path, file)
print('当前文件:', file)
if os.path.isdir(old_dir):
continue
if old_suffix != os.path.splitext(file)[1]:
continue
filename = os.path.splitext(file)[0]
new_dir = os.path.join(path, filename + new_suffix)
os.rename(old_dir, new_dir)
if __name__ == '__main__':
file_rename()
10.生成统计图表
在 Python 中处理图像的包有 scikit Image、PIL、OpenCV 等,处理图表的包有 matplotlib、plotly、seaborn 等。数据可视化让数据更加直观,更容易通过数据做出正确的决策
import numpy as np
import matplotlib.pyplot as plt
N = 5
menMeans = (20, 35, 30, 35, 27)
womenMeans = (25, 32, 34, 20, 25)
menStd = (2, 3, 4, 1, 2)
womenStd = (3, 5, 2, 3, 3)
ind = np.arange(N) # the x locations for the groups
width = 0.35 # the width of the bars: can also be len(x) sequence
p1 = plt.bar(ind, menMeans, width, yerr=menStd)
p2 = plt.bar(ind, womenMeans, width,
bottom=menMeans, yerr=womenStd)
plt.ylabel('Scores')
plt.title('Scores by group and gender')
plt.xticks(ind, ('G1', 'G2', 'G3', 'G4', 'G5'))
plt.yticks(np.arange(0, 81, 10))
plt.legend((p1[0], p2[0]), ('Men', 'Women'))
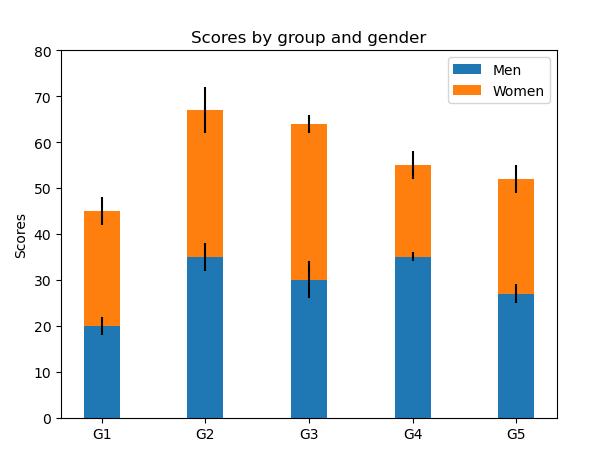
plt.show()
效果图:
11.Python 处理 txt
txt 文件是我们日常打交道最多的文件,甚至我们第一个认识的文档类型就是 txt,除了存放文字,还可以按照一定格式存放我们所需的数据,所以在日常的数据处理中,除了 xlsx 和 csv,我们还会接触到 txt 作为数据处理的文件对象
a.读取 txt 内容
#第一种方法
f = open("data.txt","r") #设置文件对象
line = f.readline()
line = line[:-1]
while line: #直到读取完文件
line = f.readline() #读取一行文件,包括换行符
line = line[:-1] #去掉换行符,也可以不去
f.close() #关闭文件
#第二种方法
data = []
for line in open("data.txt","r"): #设置文件对象并读取每一行文件
data.append(line) #将每一行文件加入到list中
#第三种方法
f = open("data.txt","r") #设置文件对象
data = f.readlines() #直接将文件中按行读到list里,效果与方法2一样20 f.close() #关闭文件
#或者
for line in f:
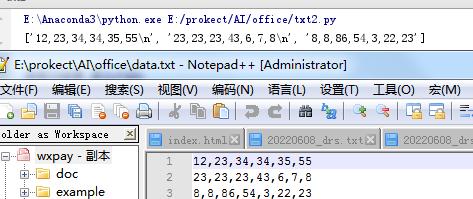
print(line)
效果图:
b.写入 txt
使用 open()函数和 write()函数
但是有两种写法,分别是'a'和'w'
原文件图

'a'
表示写入文件
若无该文件会直接创建一个
如果存在这个文件,会接着已有的内容的后面写入
with open('D:\test.txt','a',encoding='utf-8') as f:
text = '\n奔涌吧,后浪'
f.write(text)
效果图

'w'
表示写入文件
若无该文件会直接创建一个
如果存在这个文件,里面的内容会被后面写入的内容替换掉
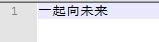
with open('D:\test.txt','w',encoding='utf-8') as f:
text = '一起向未来'
f.write(text)
效果图
c.将读取到的数据转化为插入 sql 语句
这是我工作中常用的数据入库操作,当我需要把线下收集到的数据或者其他的系统数据导入我们的数据库时,我会将 TXT 数据通过以下代码转换为 sql 语句,然后分批执行入库
代码如下:
#生成sql
f = open("data2.txt","r") #设置文件对象
for line in f:
print(line)
line = line[:-1]
with open('test2.txt','a+',encoding='utf-8') as wf:
text = 'insert into table (code) value ("'+ line +'"); \n'
wf.write(text)
效果图:

12.给图片添加水印
近年来,人们对知识产权保护的意识越来越强,为了防止别人抄袭或者盗图,怎么少得了给图片加水印的技能呢
给图片加水印首选 pillow,pillow 简单易用,非常适合初学者学习
Python 处理图像的库还有OpenCV、Scikit-image,这里选择相对简单的 pillow
安装库
pip install pillow
代码如下:
from PIL import Image, ImageDraw, ImageFont
im = Image.open('./img1.jpg')
draw = ImageDraw.Draw(im)
font=ImageFont.truetype(r'C:\Windows\Fonts\simhei.ttf',70)
draw.text((400,280),"HELLO~你好",font=font,fill="gray")
im.save('result.png')
原图

效果图

安装库
pip3 install filestools
代码如下:
from watermarker.marker import add_mark
import os
add_mark(file = "./img1.jpg", #待添加水印的照片
out =r'.\out', #添加水印后保存的位置
mark = "HELLO~你好", #水印文字
opacity= 0.5, #文字透明度
size = 80, #字体大小
angle=30, #水印字体的旋转角度
space=30, #水印字体之间的间隔
color="gray") #水印字体的颜色
#批量加水印
for img in os.listdir("./imgs"):
add_mark(file = f"{os.path.join(imgs,img)}", #待添加水印的照片
out =r'.\out', #添加水印后保存的位置
mark = "HELLO~你好", #水印文字
opacity= 0.5, #文字透明度
size = 80, #字体大小
angle=30, #水印字体的旋转角度
space=30, #水印字体之间的间隔
color="gray") #水印字体的颜色
效果图:

13.抠图
对图片的操作怎么能少得了抠图呢,对于不会PS的童鞋简直就是一大福利!
a.准备好自己需要抠图的相片
b.安装 removebg 库(这一步至关重要,不然后面无法实现抠图)
打开命令行输入如下命令:
pip install removebg或pip3 install removebg
选择文件使用的是 UI 可视化对话界面的方式,所以还需要安装 UI 相关的库:win32ui 模块是简单的封装了 Windows 中 ui 类
打开命令行输入如下命令:
pip install pypiwin32 或 pip3 install pypiwin32
#使用安装的插件的方式
#管理员身份运行命令提示行,然后执行命令
#pip3 install removebg
from removebg import RemoveBg
import win32ui
dlg = win32ui.CreateFileDialog(1) # 1表示打开文件对话框
dlg.SetOFNInitialDir('E:/') # 设置打开文件对话框中的初始显示目录
dlg.DoModal()
filename = dlg.GetPathName() # 获取选择的文件名称
rmbg = RemoveBg("你的API KEY", "error.log") # 引号内是你获取的API
rmbg.remove_background_from_img_file(filename) # 图片地址
总结
生活不止眼前的苟且,还有诗和远方,解放双手,尽情享受居家办公美好与自由的时光,好好感受这个季节带来的小欢喜和惬意······
Python 简直就是一个百宝箱,就像哆啦 A 梦的口袋,随时都能从时光之门变出一个自动化办公的神器,上面只是 Python 自动化办公中的冰山一角,得益于 Python 拥有各种各样丰富的第三方库,仅需少量的代码,即可实现你任何自动化办公的需求,且对新手同样友好。这里只是抛砖引玉,还有更多助力自动化办公的神器等你发现
除了自动化办公以外,Python 还可以进行远程控制电脑,居家办公怎么能少得了远程呢,不过涉及到远程这块目前用的主要使用是 teamview 和向日葵等工具。Python 在爬虫,自动化测试,大数据,AI 等领域同样表现优秀,有一些天然的优势,这些方面的使用有待你的探索。。。学习就是在不断的探索中,不断地积累中成长的过程,总有一天你会羽翼丰满,飞上自由的蓝天--人生万事须自为,跬步江山即寥廓