




“大数据“,近几年来最火的词之一。虽然大数据这个词的正式产生也就10年左右,但对大数据分析却早就有之。早在互联网初期,就有很多公司通过计算机技术对大量的分析处理,比如各个浏览引擎。 然而,大数据的真正提出却是源自2008.09.03 《Nature》专刊的一篇论文,紧接着,产业界也不断跟进,麦肯锡于2011.06 发布麦肯锡全球研究院报告,标志着大数据在产业界的真正兴起,随着白宫发布大数据研发法案,政府开始加入大数据的角逐。
大数据具有数据量大、数据多样化、数据价值稀疏等特点,因此导致处理大数据的大数据系统具有如下特点:
1)分布式:单机无法处理海量数据;
2)数据多样:需要支持各种数据源的各式各样的数据;
3)数据存储量大且数据稀疏:需要合理的存储方式与数据模型来进行数据存储;
由于大数据系统需要采集各式各样的数据源、并且需要存储海量低密度数据,并且是通过分布式的方式构建的,所以大数据系统面临了如下问题:
- 分布式协调与集群管理
- 多样化数据采集与存储
- 海量数据存储
3.1 M-S主从模式
分布式系统通过M-S主从模式,进行整个集群和系统的运行和管理。主节点主要的工作是注册应用、元数据管理、资源分配与再分配;从节点是实际进行数据存储与运算的节点,两者通过心跳模式链接,从而实现主节点对从节点的监听与管理。
3.2 CAP原则与节点容错
1)CAP原则
分布式系统相较于单机系统,就像足球与网球单打。足球是一个团体运动,需要团队成员之间的协调与调度、配合与补防,而网球单打则完全是自己能力的体现,在场上没有团队的概念。
分布式系统遵循CAP原则:
- C:Consistency,一致性
- A:Available,可用性
- P:Partition Tolerance,分区容错性
一致性是指由于在分布式系统中,存在一个数据的多个备份,因此当数据发生变化后,我们需要保证该数据在不同地方的一致性;可用性是指当用户请求系统后,系统能够有效的应答用户;分区容错性是指分布式系统要保证由于通信问题导致的分布式系统中各节点、机器的通信不通的问题。
分区容错性是分布式系统一定要保证的,但是一致性和可用性是彼此冲突的,分布式系统只能选择一个方向来保证。
2)节点容错
在宏观上,分布式系统需要尽量满足除了一致性、可用性与分区容错性。而在微观上,系统则要解决由于分布式节点出现宕机或者出现错误情况下的问题。在这种情况下,需要由主节点(资源管理器)将出现问题的节点的任务转交给其他节点或者重启当前节点重新运行来完成,并且这里还要保证数据没有出现重复计算的问题。
3.3 文件存储与列式存储
1)HDFS文件存储
HDFS是大数据系统的数据存储核心。
一般来说,我们都是通过数据库进行数据存储的,但HDFS实际上是一个分布式的文件系统,在它上面,数据都是以文件的形式存在。可以简单的把他理解为在我们的个人电脑上通过windows系统看到的一个个文件夹与文件。
HDFS的文件存储方式,适合大规模的数据存储,解决了大批量大规模数据的存储问题。
2)HBase列式存储
在HDFS基础上,采用了列式存储的HBase数据库,解决了数据稀疏性的问题。并且由于HBase中数据结构的优化,使得快速实时查询在HBase上成为可能。
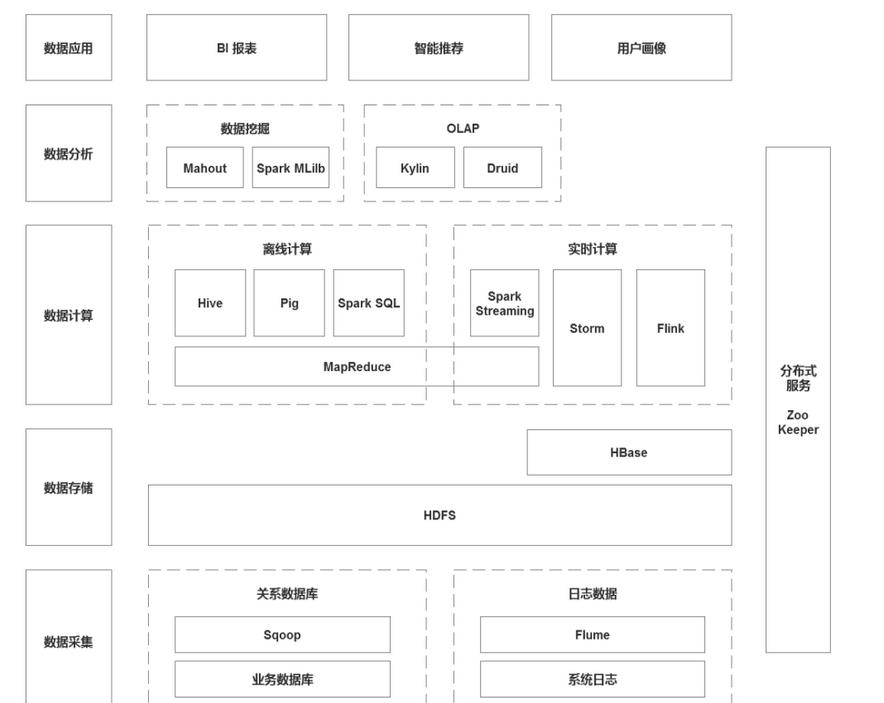
4.1 数据采集
1)Sqoop:Sqoop是关系型数据库和HDFS之间的一个桥梁,写的时候除了HDFS,还可以写Hive,甚至可以直接去建表。而且可以在源数据库设立是导整个数据库,还是导某一个表,或者导特定的列,这都是常见的在数据仓库中进行的ETL。
2)Flume:采集日志系统等非结构化数据;
4.2 数据存储
1)HDFS:分布式文件系统;
2)HBase:建立在HDFS之上的列式数据库,HBase的存储依旧是以HDFS文件的形式存在的。
4.3 数据计算
4.3.1 离线计算
1)Hive:Hadoop平台上的数据仓库工具,可以用来做ETL与数据分析。可以用SQL语句操作。Hive会把SQL语句转换成MapReduce作业。
2)Pig:处理非结构化数据的Hive;
3)Spark SQL:类似Hive SQL;
4.3.2 实时计算
1)Spark Streaming:微批处理计算框架,通过小微批处理实现实时计算。
2)Storm:流式计算框架,有了Flink,基本不用Storm了。
3)Flink:高吞吐、低延迟、高性能的流式计算框架。
4.4 数据分析
4.4.1 数据挖掘
1)Spark MLilb:Spark上一个包含通用机器学习功能的包,Machine Learing lib。包含分类,聚类,回归等,还包含模型评估和数据导入。MLilb 提供的这些方法,都支持集群上的横向扩展。
2)Mahout:是一个建立于Hadoop之上的算法库,集成了很多算法。
4.4.2 OLAP
1)Durid:实时OLAP分析工具。它既支持高速的数据实时摄入处理,也支持实时且灵活的多维数据分析查询。因此 Druid 最常用的场景就是大数据背景下、灵活快速的多维 OLAP 分析。另外,Druid 还有一个关键的特点:它支持根据时间戳对数据进行预聚合摄入和聚合分析,因此也有用户经常在有时序数据处理分析的场景中用到它。
2)Kylin:它采用多维立方体(Cube)预计算技术,可以将某些场景下的大数据 SQL 查询速度提升到亚秒级别。相对于之前的分钟乃至小时级别的查询速度。
4.5 数据应用
1)BI:商务智能,用来将企业中现有的数据进行有效的整合,快速准确地提供报表并提出决策依据,帮助企业做出明智的业务经营决策。简单来说,就是用BI工具,来代替Excel处理海量数据。
2)用户画像
3)智能推荐
4.6 其他组件
1)分布式服务ZooKeeper
2)消息队列Kafka
3)内存数据库Redis:基于内存的数据结构存储器,可以用作数据库、缓存和消息中间件。
大数据给我们带来了机遇和挑战,我们是否能从中受益则需要看我们怎么对待这些机遇和挑战。 大数据的机遇是明显的,各种大平台的数据采集与公开,MapReduce等数据分析平台的开放,以及各领域数据挖掘服务的提供,使我们获得数据变得更加容易。而这些丰富的数据更是带来了众多的创新机会,任何领域的数据都可能对这个领域造成巨大的影响。
当然大数据也给我们带来了很多挑战。
一、数据共享与数据私有的矛盾。
大数据的价值是稀疏的,而大量的数据往往被大公司垄断,因此对于一般人来说,数据的共享变得十分重要,而其中一个解决方法就是建立一个共享的数据中心。
二、数据洪流与技术滞后的矛盾。
首先是数据存储能力与处理不匹配,对此我们可以采用对数据流进行实时处理、就近原则存储和处理原始数据、购买数据存储和分析服务等方法进行解决。再者,是分析手段与性能需求不匹配,主要原因是因为传统数据仓库不再使用于大数据分析,对于此我们可以采用大规模并发、Map-Reduce分布式计算、NoSQL管理并发存取等方法进行处理。
三是社会需求与人才匮乏的矛盾。
对此,培养优秀大数据人才已是当务之急。
四、开放数据与保护隐私的矛盾。
其中包含用户隐私成为牺牲品、有可能危害国家安全等问题,我们的解决思路就是发展隐私保护数据挖掘方法和完善立法。

1.移动大数据分析将逐步成为云计算和物联网的研究聚焦点。
2.移动互联网UGC和MGC数据的深度融合将催生新的产业。
3.专注于局部领域的数据分析服务将成为近期产业创新主流。
4.Map-Reduce将仍保持活力,分布式流数据分析方法将成为机器学习理论研究和应用研究热点。
5.数据共享是大势所趋,但需要特别重视国家信息安全,开放数据需要立法支持,信息安全需要自主技术保障。