




背景
新项目涉及大数据方面。之前接触微服务较多,趁公司没反应过来,赶紧查漏补缺。Kafka 是其中之一。
Apache Kafka 是一个开源的分布式事件流平台,可跨多台计算机读取、写入、存储和处理事件,并有发布和订阅事件流的特性。
本文将研究 Kafka 从生产、存储到消费消息的详细过程。
Producer
消息发送
所有的 Kafka 服务器节点任何时间都能响应是否可用、是否 topic 中的 partition leader,这样生产者就能发送它的请求到服务器上。
producer 只会将数据 push 给 partition 中的 leader,而 follower 需要自己去 leader 那里 pull 消息。
那么 producer 以什么形式发送数据,发送了一条/批消息之后,需要什么条件或者需要等待多久才能发送下一条消息呢,发送失败会重试吗?......
Kafka Documentation 中 Producer Configs 里有相关配置说明:
生产者生成的数据的压缩类型。通过使用压缩,可以节省网络带宽和Kafka存储成本。
type: string
default: none
valid values: [none, gzip, snappy, lz4, zstd]
importance: high
生产者发送消息失败或出现潜在暂时性错误时,会进行的重试次数。
type: int
default: 2147483647
valid values: [0, ..., 2147483647]
importance: high
当多条消息发送到一个分区时,producer 批量发送消息大小的上限 (以字节为单位)。即使没有达到这个大小,生产者也会定时发送消息,避免消息延迟过大。默认16K,值越小延迟越低,吞吐量和性能也会降低。
type: int
default: 16384
valid values: [0, ...]
importance: medium
producer 在确认一个请求发送完成之前需要收到的反馈信息。这个参数是为了保证发送请求的可靠性。
acks = 0:producer 把消息发送到 broker 即视为成功,不等待 broker 反馈。该情况吞吐量最高,消息最易丢失
acks = 1:producer 等待 leader 将记录写入本地日志后,在所有 follower 节点反馈之前就先确认成功。若 leader 在接收记录后,follower 复制数据完成前产生错误,则记录可能丢失
acks = all:leader 节点会等待所有同步中的副本确认之后,producer 才能再确认成功。只要至少有一个同步副本存在,记录就不会丢失。这种方式是对请求传递的最有效保证。acks = -1 与 acks = all 等效
type: string
default: all
valid values: [all, -1, 0, 1]
importance: low
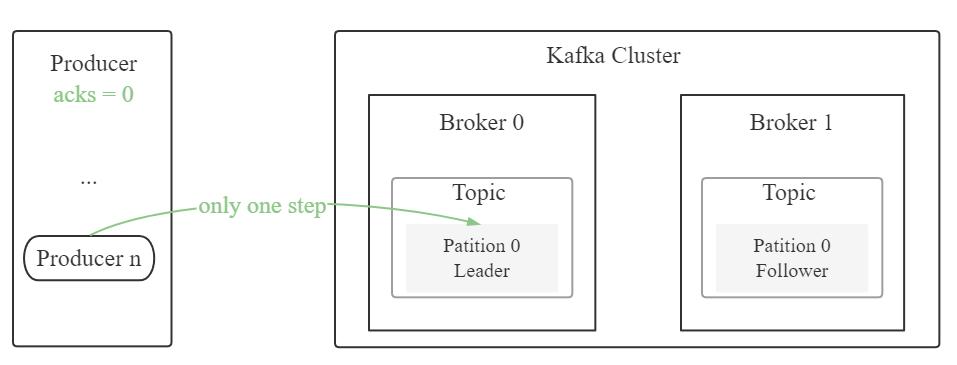
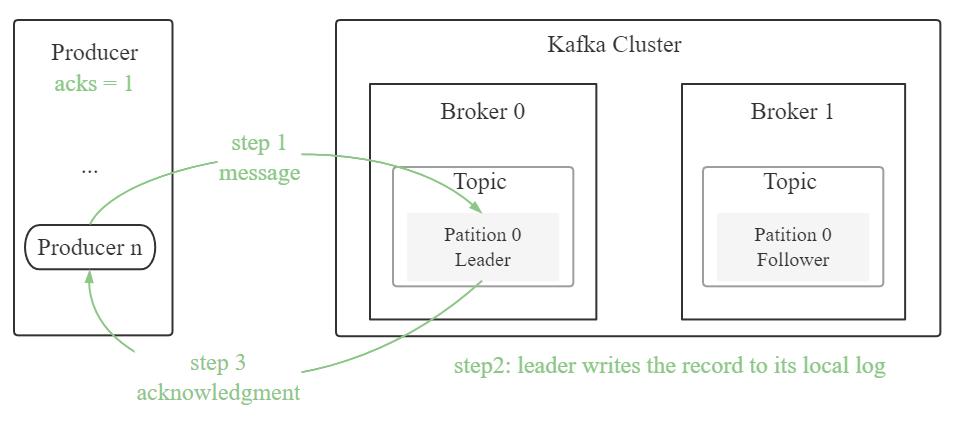
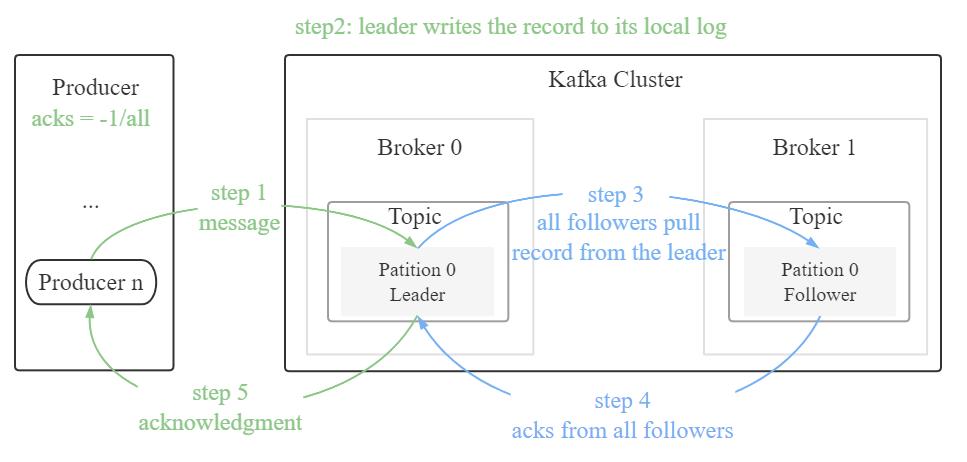
Java 实现 Kafka 消息发送分为直接、同步、异步发送。其中直接发送无回调,同步发送有阻塞,故生产环境多用异步发送。
Properties properties = new Properties();
// 建立与 Kafka 群集的初始连接的主机/端口对的列表 多个以逗号隔开
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka1:9092, kafka2:9092, kafka3:9092");
// 消息不成功重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 0);
// 请求的最大大小 以字节为单位
properties.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 2147483640);
// 超时限制 ms
properties.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 60000);
// 缓冲区大小
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// key/value 的序列化类
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
Producer<String,String> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>("Topic", "Key", "Value");
try {
// 直接发送
producer.send(record);
// 同步
RecordMetadata recordMetadata = producer.send(record).get();
System.out.println("part: " + recordMetadata.partition() + " " + "topic: " + recordMetadata.topic()+ " " + "offset: " + recordMetadata.offset());
// 异步
producer.send(record, (metadata, exception) -> {
if (exception == null){
System.out.println("part: " + metadata.partition() + " " + "topic: " + metadata.topic()+ " " + "offset: " + metadata.offset());
}else {
exception.printStackTrace();
}
});
} catch (Exception e) {
e.printStackTrace();
}
producer.close();
Kafka producer 消息发送的另一种实现方式:
@Slf4j
public class KafkaTemplateProducer {
public void sendTemplate(String topic, Object data){
Map<String, Object> properties = new HashMap<>();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka1:9092");
properties.put(ProducerConfig.RETRIES_CONFIG, 0);
properties.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 2147483640);
properties.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 60000);
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// key/value 的序列化类
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
DefaultKafkaProducerFactory<String, Object> defaultKafkaProducerFactory = new DefaultKafkaProducerFactory<>(properties);
KafkaTemplate<String, Object> kafkaTemplate = new KafkaTemplate<>(defaultKafkaProducerFactory);
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, data);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onSuccess(SendResult<String, Object> sendResult) {
log.debug("topic: " + topic + " " + "value: " + data + " " + "success result: " + sendResult.toString());
}
@Override
public void onFailure(Throwable throwable) {
log.error("topic: " + topic + " " + "value: " + data + " " + "failure result:" + throwable.getMessage());
}
});
}
}
Partition 中文件存储
Topic 包含若干 partition,partition 中存储若干 segment,segment 包含 .index (存储元数据)、 .log文件 (存储 message) 和 .timeindex 文件 (记录时间信息) 等。
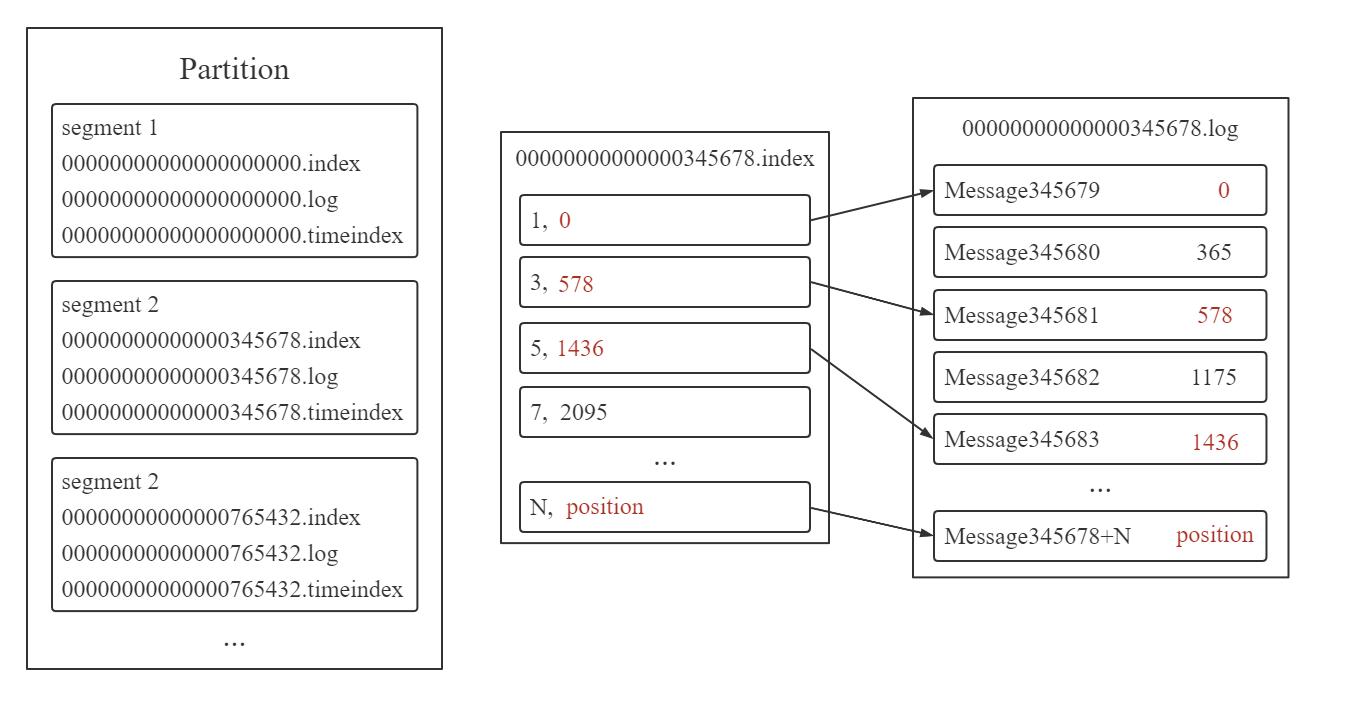
.log 文件中的 message 物理结构包括 offset, message size 等。偏移 (offset) 是每条消息的有序编号,它可以确定每条消息在 partition 内的唯一位置。
如上图所示, .index 文件中的 N 为索引,position 为元数据物理位置。 .log 文件中的 345678 + N 为 offset,position 为物理偏移地址。 .index 文件元数据物理位置指向 .log 文件中 message 的物理偏移地址。
.index 文件采用稀疏索引存储方式,只为每个存储块建立索引项,而非稠密索引的每个单元都建立。存储块意味着块内连续存储单元。稀疏索引比稠密索引节省了存储空间,但查找起来需要消耗更多时间。稠密索引与稀疏索引_Jeaforea的博客-CSDN博客_稠密索引和稀疏索引
注:稀疏索引不宜太过稀疏或密集,以免增大查找成本或导致存储块太小。
Consumer
消息查找
consumer 通过向 broker 发出一个 “fetch” 请求来获取它想要消费的 partition。consumer 的每个请求都在 log 中指定了对应的 offset,并接收从该位置开始的一块数据。
若现在 consumer 想查找 offset 为 345682 的数据,整个查询过程基于二分法,顺序为:
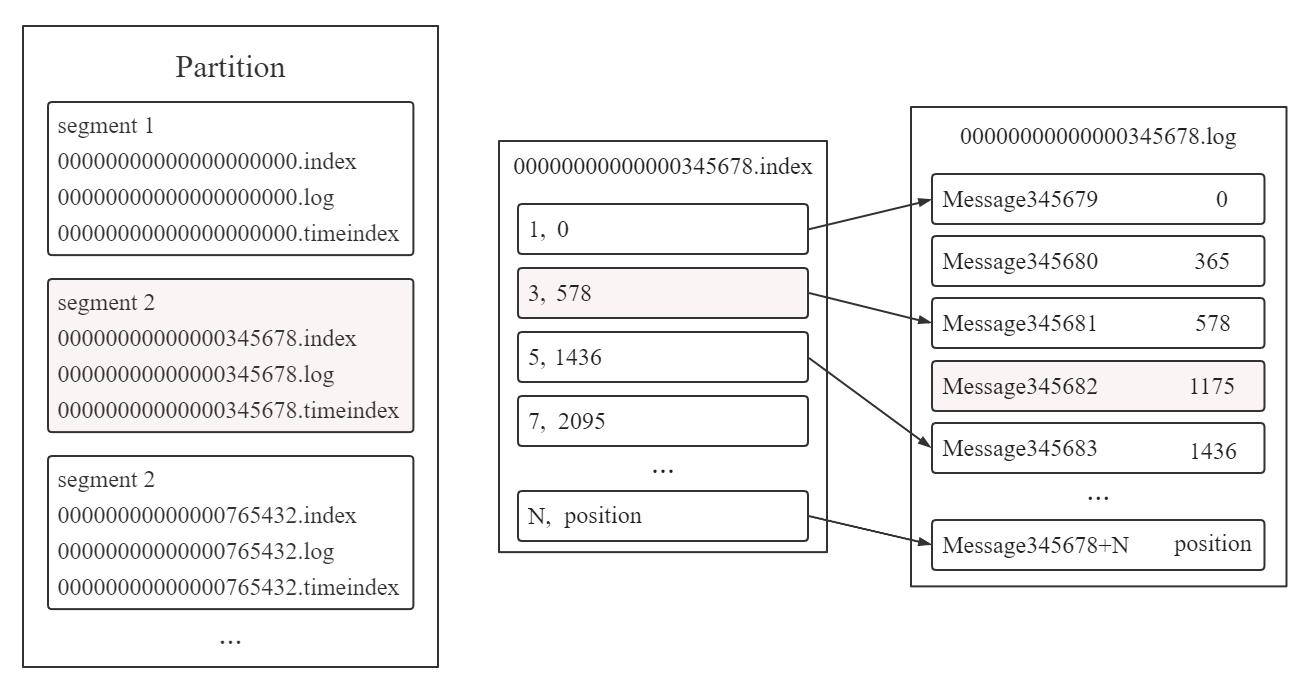
(1) 利用二分法找到小于 345682 且离其最近的 segment 2 文件
(2) 345682 = 345678 + 4,故在对应 .index文件中利用二分法找到小于4且离其最近的3索引
(3) 因为 .index 文件元数据物理位置指向 .log 文件中 message 的物理偏移地址。找到 3 索引 578 元数据物理位置指向 .log文件中 578 位置的 Message3456781
(4) 从 Message3456781 开始扫描,直到找到 offset 为 345682 的数据
接收消息
Kafka consumer 从 broker 中 pull 数据。具体代码实现调用 poll() 方法。
// poll() 调用间隔时间
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
push 和 pull 比较:
两者区别是,push 是发送方定义发送速率,而不管接收方接收速率,而 pull 是接收方在能承受的范围内自己定义接收速率。
push 容易造成 consumer 超载、无法进行消费、吞吐量很低、延迟高等问题。而 pull 出现这些问题的概率更小,即使 message 很多,也能根据自身服务器的速率消化数据,一直能进行消费。pull 更支持批处理,吞吐量高且有效利用了缓冲区。
但 pull 也存在缺陷:如果 broker 中没有数据,consumer 可能会 busy-waiting 直到数据到来 (busy-waiting 会一直循环检测是否有数据,占用线程和 CPU)。为了避免 busy-waiting ,Kafka 在 pull 请求中加入参数,使得 consumer 在一个 “long pull” 中阻塞等待,直到数据到来 (还可以选择等待给定字节长度的数据来确保传输长度)。
在此配置指定的毫秒数后关闭空闲连接。
type: long
default: 540000 (9 min)
valid values: [0, ...]
importance: medium
服务器读取请求返回的最小数据量。如果可用的数据不足,请求将等待累积指定数据,然后再响应请求。可以用一些额外的延迟为代价来提高服务器吞吐量。
type: int
default: 1
valid values: [0, ...]
importance: high
消费
Kafka 是多订阅模式,一个 topic 可以有一个或者多个消费者来订阅它的数据。
Kafka 的 topic 被分割成了一组完全有序的 partition,其中每一个 partition 在任意给定的时间内只能被每个订阅了这个 topic 的 consumer group 中的一个 consumer 消费。
消息传向消费者消费的过程中,可能会丢失、重复消费或者一直无响应。如何让 broker 和 consumer 被消费的数据保持一致性?
Kafka 提供了 consumer 的消费确认机制来解决这些问题:若当前消息已被正确消费,则 consumer 存储下一条要消费的消息的 offset。
该机制的优点:
(1) 占用存储少
(2) 可以进行周期性的检查
(3) consumer 可以回退到之前的offset来再次消费数据
当 Kafka 中没有初始偏移量或当前偏移量在服务器上不再存在时 (如该数据已被删除) 的策略:
earliest: 自动将偏移量重置为最早偏移量
latest: 自动将偏移量重置为最新偏移量
none: 如果找不到消费者组的先前偏移量,则向消费者抛出异常
其他: 向消费者抛出异常
type: string
default: latest
valid values: [latest, earliest, none]
importance: medium
如果为 true,则将在后台定期提交 offset。
频率可用 auto.commit.interval.ms 进行设置,ms。
type: boolean
default: true
valid values:
importance: medium
consumer 消费示例:
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka1:9092, kafka2:9092, kafka3:9092");
// 所属消费者组的id
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");
// 消费者的偏移量提交频率 ms
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 客户端超时时间限制
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
// key/value的反序列化类
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
// 订阅 topic
consumer.subscribe(Collections.singletonList("Topic"));
try {
// noinspection InfiniteLoopStatement
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.println("offset: "+ record.offset() + " " + "key: " + record.key() + " " + "value: " + record.value());
}
} catch (Exception e){
e.printStackTrace();
}
consumer.close();
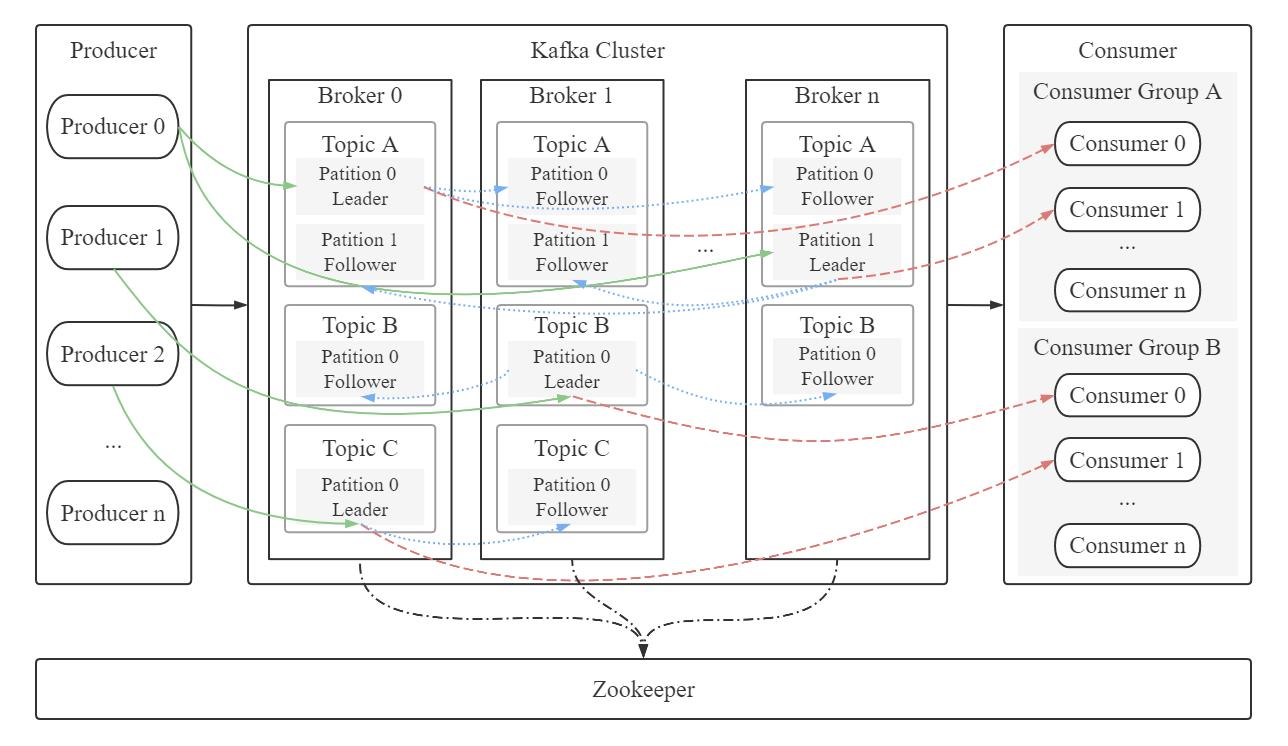
Kafka 完整的消息传递过程如上图所示。其中还有一些问题可以继续深入讨论,比如负载均衡、Partition Leader 选举、Consumer group 重平衡等,这些因素会影响到消息传递的准确性和性能。
展望
大数据涉及范围很广,Yarn、MapReduce、Spark、Hive、Sqoop ...... 明年慢慢学习。还有Linux,说来惭愧,用的并不是很习惯,属于命令行需要上网搜的那种。仔细想想,我对不熟悉的事务有一种天然的恐惧感,这一点也需要克服。
最近的政策发生了改变,一时竟无法判断是否良性。不管怎样,希望身心俱疲的打工人们能寻到生活当中的那些光亮。最后衷心的祝福大家平安喜乐、年年有余、万事胜意。
参考:
学习 Kafka 入门知识看这一篇就够了!(万字长文) - 腾讯云开发者社区-腾讯云 (tencent.com)
【Kafka】消息的同步发送和异步发送_云川之下的博客-CSDN博客_kafkatemplate异步发送