




由于公司近一年开始朝向在云原生方向开始发展,已经将部分业务应用迁移至Kubernetes上运行,并且形成了一套一站式应用研发全生命周期管理体系,提供了如项目管理、代码托管、CI/CD等功能。因此数据平台也面临着从Hadoop到云原生的探索。我们做了一些尝试:首先是存储,使用OSS等对象存储替代了HDFS。其次就是计算,也是本篇文章将要介绍的,将Spark计算任务从Yarn迁移至K8S上运行。
考虑到我们服务的客户数据量都不是很大,并且在数据相关的场景中都是基于SQL来实现。上半年我们在离线业务中首先选择了spark-thrift-server。 spark-thrift-server的本质其实就是一个Spark Application,和我们单独提交Spark Jar包任务到集群是一样的,也会启动一个Driver和多个Executor。 因此这一步要做的其实就是将其提交到K8S集群上,并启动Driver对应的pod和Executor对应的pod。具体实现过程如下:
基于deployment部署spark-thrift-server到K8S
首先需要准备好spark镜像,如果没有则需要自己去构建一个。因为我们使用了hive的元数据信息,所有镜像中打入了mysql的jar包。
apiVersion: apps/v1
kind: Deployment
metadata:
name: spark-thrift-server-test
namespace: default
labels:
app.kubernetes.io/name: spark-thrift-server-test
app.kubernetes.io/version: v3.1.1
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: spark-thrift-server-test
app.kubernetes.io/version: v3.1.1
template:
metadata:
labels:
app.kubernetes.io/name: spark-thrift-server-test
app.kubernetes.io/version: v3.1.1
spec:
serviceAccountName: thrift-server
hostname: spark-thrift-server-test
containers:
- name: spark-thrift-server-test
image: registry.cn-hangzhou.aliyuncs.com/lz18xz/lizu:v3.1.1-thrift
env:
- name: "SPARK_DRIVER_URL"
value: "spark-thrift-server-test"
imagePullPolicy: Always
ports:
- containerPort: 9000
args:
- /opt/spark/bin/spark-submit
- --class
- org.apache.spark.sql.hive.thriftserver.HiveThriftServer2
- --name
- Thrift JDBC/ODBC Server
- --master
- k8s://https://kubernetes.docker.internal:6443
- --name
- spark-thriftserver
- --conf
- spark.executor.instances=1
- --conf
- spark.executor.memory=1g
- --conf
- spark.executor.cores=1
- --conf
- spark.driver.cores=1
- --conf
- spark.driver.memory=1g
- --conf
- spark.kubernetes.namespace=default
- --conf
- spark.driver.port=45984
- --conf
- spark.blockManager.port=38141
- --conf
- spark.kubernetes.container.image=registry.cn-hangzhou.aliyuncs.com/lz18xz/lizu:v3.1.1-thrift
- --conf
- spark.kubernetes.container.image.pullPolicy=Always
- --conf
- spark.default.parallelism=1000
- --conf
- spark.driver.extraJavaOptions=-Duser.timezone=GMT+08:00
- --conf
- spark.executor.extraJavaOptions=-Duser.timezone=GMT+08:00
- --conf
- spark.kubernetes.driver.limit.cores=2
- --conf
- spark.kubernetes.executor.limit.cores=2
- --conf
- spark.driver.memoryOverhead=0
- --conf
- spark.executor.memoryOverhead=0
- --conf
- spark.network.timeout=300s
- --conf
- spark.rpc.lookupTimeout=300s
- --conf
- spark.executor.heartbeatInterval=30s
- --hiveconf
- javax.jdo.option.ConnectionURL=jdbc:mysql://ip:4306/metastore?createDatabaseIfNotExist=true&useSSL=false
- --hiveconf
- javax.jdo.option.ConnectionDriverName=com.mysql.jdbc.Driver
- --hiveconf
- javax.jdo.option.ConnectionUserName=root
- --hiveconf
- javax.jdo.option.ConnectionPassword=root123
- --hiveconf
- hive.server2.authentication=NOSASL
- --hiveconf
- hive.metastore.sasl.enabled=false
还有许多其他参数可以使用--conf来添加,这里只是一个简单的版本。
创建对应的Service
这里提供了ClusterIP、NodePort两种类型方便本地测试
apiVersion: v1
kind: Service
metadata:
name: spark-thrift-server-test
namespace: default
spec:
ports:
- name: thrift-server-tcp-10000
port: 10000
protocol: TCP
targetPort: 10000
- name: thrift-server-tcp-4040
port: 4040
protocol: TCP
targetPort: 4040
- name: thrift-server-tcp-45984
port: 45984
protocol: TCP
targetPort: 45984
- name: thrift-server-tcp-38141
port: 38141
protocol: TCP
targetPort: 38141
type: ClusterIP
selector:
app.kubernetes.io/name: spark-thrift-server-test
app.kubernetes.io/version: v3.1.1
apiVersion: v1
kind: Service
metadata:
name: spark-thrift-server-test2
namespace: default
spec:
ports:
- name: thrift-server-tcp-10000
port: 10000
targetPort: 10000
nodePort: 30001
- name: thrift-server-tcp-4040
port: 4040
targetPort: 4040
nodePort: 30002
- name: thrift-server-tcp-45984
port: 30003
targetPort: 30003
nodePort: 30003
- name: thrift-server-tcp-38141
port: 30004
targetPort: 30004
nodePort: 30004
selector:
app.kubernetes.io/name: spark-thrift-server-test
app.kubernetes.io/version: v3.1.1
type: NodePort
验证可用性
基于kubectl apply 创建上面的deploy和service之后,我们就可以查看是否已经正常运行了。
kubectl get pod
NAME READY STATUS
spark-thrift-server-test-5b66f7797d-whgf6 1/1 Running 0 69m
spark-thriftserver-ab977d84fb0199eb-exec-1 1/1 Running 0 68m
使用beeline连接
beeline -u "jdbc:hive2://localhost:30001/;auth=noSasl" -n hive -p hive
spark web ui本地访问
http://localhost:30002/jobs/
我这里是一个executor,大家可以基于kubectl edit deploy去修改executor相关的配置。
优势与不足
基于上面这种方式部署spark-thrift-server整体比较简单,并且在K8S的管理下,可以快速扩展executor pod的个数和内存,对运维来说会相对简单。 但是在使用过程中也遇到了一些问题:
- 大SQL阻塞问题 一个数据量很大的查询SQL会把所有资源全占了,会导致后面的SQL都等待,即使后面的SQL只需要几秒就能完成,结果就是一些业务延迟。 针对这种问题我们首先会对SQL进行查看,是否逻辑存在问题,并且通过配置开启了AQE相关的参数,此时Spark自身可以帮我们优化一些join的SQL以及数据倾斜的问题:
- --conf
- spark.sql.crossJoin.enabled=true
- --conf
- spark.sql.adaptive.enabled=true
- --conf
- spark.sql.adaptive.skewJoin.enabled=true
- --conf
- spark.sql.adaptive.join.enabled=true
- --conf
- spark.sql.shuffle.partitions=300
- --conf
- spark.sql.broadcastTimeout=600
- --conf
- spark.sql.adaptive.maxNumPostShufflePartitions=300
同时开启了动态资源配置,让其自身根据工作负载来衡量是否应该增加或减少executor
- --conf
- spark.dynamicAllocation.enabled=true
- --conf
- spark.dynamicAllocation.shuffleTracking.enabled=true
- --conf
- spark.dynamicAllocation.minExecutors=1
- --conf
- spark.dynamicAllocation.maxExecutors=10
- --conf
- spark.dynamicAllocation.initialExecutors=2
- --conf
- spark.dynamicAllocation.executorIdleTimeout=60s
- --conf
- spark.dynamicAllocation.schedulerBacklogTimeout=3s
基于上面的配置,可以在一定程度减少job阻塞的情况。但是并不能完全避免。
- SQL不能满足所有需求 因为在一些项目中已经涉及到了一些算法相关的业务,仅仅通过SQL并不能满足其需要,那么就需要通过向K8S集群提交jar包或者python包来运行Spark任务了。
简单介绍
在下半年经过一些调研后,我们最终选用了Spark-Operator来实现任务的提交。它是Google开源的一个组件。是基于CRD和自定义Controller来实现的。在提交任务后,可以在K8S上以惯用方式指定、运行和监视Spark应用程序。下图是其官方的设计图:
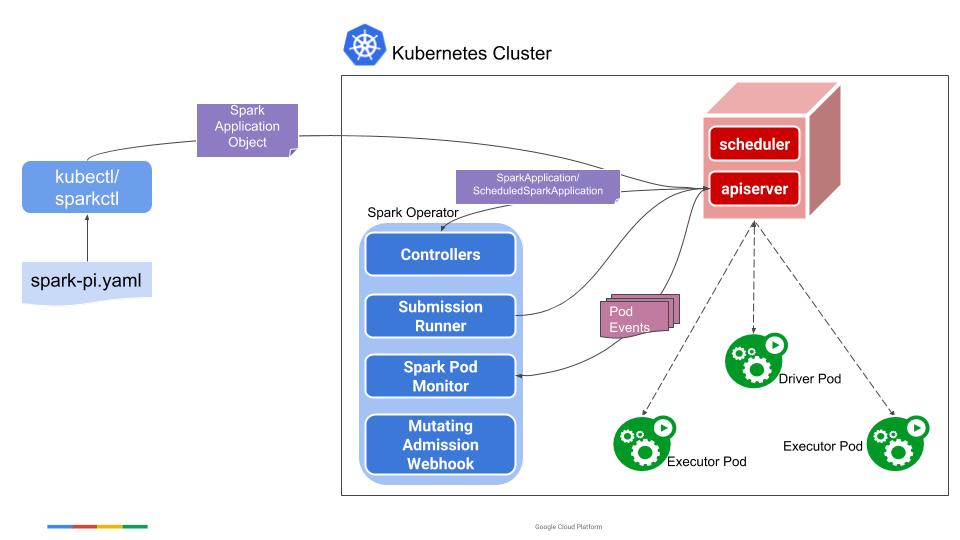
可以看到SparkApplication作为自定义的controller会监听多种事件,如创建、更新、删除。并且有monitor组件会想controller汇报pod的状态。 具体每个事件监听后controller做了哪些东西大家可以参考官方的设计文档,里面对每个事件都做了完整的说明。
部署
和原生方式提交任务不同的是,使用Spark-Operator需要先部署其自身的pod到K8S集群中。相当于是定义CRD到集群并且启动自定义controller来监听后续的kubectl命令。 在部署之前我们首先需要从官方下载对应的镜像,我这里选择了v1beta2-1.3.7-3.1.1版本。也可以下载项目自行构建。
可以选择基于helm部署
helm install spark-operator-v3 spark-operator/spark-operator -n spark-operator --set image.repository="registry.lz/rep/spark-operator" --set image.tag="v1beta2-1.3.7-3.1.1"
查看部署结果
kubectl get pods -n spark-operator
NAME READY STATUS RESTARTS AGE
spark-operator-v3-ff8878fb8-pjn4l 1/1 Running 0 1h
关于部署,更详细的可以参考官方的文档或者我的笔记。到此我们就可以基于Spark-Operator提交任务到K8S上了。
任务提交
我们可以直接基于官方的examples/spark-pi.yaml文件来进行任务的提交,在spark-pi.yaml中定义了资源实例的信息,这种方式就可以指定jar包进行提交任务到K8S集群,在实际使用中要做的就是替换mainApplicationFile,mainClass等主要参数:
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v3.1.1"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.12-3.1.1.jar"
sparkVersion: "3.1.1"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 3.1.1
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 3.1.1
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
最终进行提交和查询运行状态:
## 创建实例
kubectl apply -f examples/spark-pi.yaml
## 查询任务运行情况
kubectl get pod -n spark-operator
NAME READY STATUS RESTARTS AGE
spark-pi-driver 1/1 Running 0 16s
spark-pi-fce77890f26045a6-exec-1 1/1 Running 0 4s
此时去查看operator的日志会发现其提交任务的方式也是基于spark-submit命令来完成。
到这里需要注意一点:
在资源定义的yaml文件中基于image来指定了需要拉起spark的镜像,基于mainApplicationFile指定了运行的jar路径。examlpe中mainApplicationFile使用了local:///这种方式,需要我们提前将jar包打入镜像内。而后续业务的jar包会经常新增或者修改,每次都重新打镜像会不通用。
其实这不算一个问题,因为mainApplicationFile最终会对应到spark-submit的application-jar参数,它本身是支持hdfs:// path 或者 a http:// 的,因此在任务提交之前将每个任务自身的yaml文件按需组织即可。
如果需要外部的jar依赖,也可以在yaml中新增deps.jars参数
spec:
deps:
jars:
- local:///opt/spark-jars/gcs-connector.jar
在实际使用中,我们会定义一个spark实例任务的模板,每次提交前根据页面配置替换常见的几个参数如:mainClass、mainApplicationFileh以及executor的个数、内存、core。
扩展: 如果自定义jar的Url地址spark-submit不支持怎么办?
此时可以对spark镜像进行改造,使其在启动前可以基于shell脚本去下载对应的资源文件到镜像本地。一个简单的实现:
#!/bin/bash
# echo commands to the terminal output
set -ex
# 这里可以下载文件到容器内部,容器启动后可以进入查看
if [[ -n "${SPARK_JOB_JAR_URI}" ]]; then
mkdir -p ${SPARK_HOME}/job
echo "Downloading job JAR ${SPARK_JOB_JAR_URI} to ${SPARK_HOME}/job/"
wget -nv -P "${SPARK_HOME}/job/" "${SPARK_JOB_JAR_URI}"
fi
# Handover to Spark base image's entrypoint.
exec "/opt/entrypoint.sh" "$@"
~
这块脚本中间的内容可以自行去实现下载逻辑,这里简单的实现了wget下载文件到对应目录中。其中SPARK_JOB_JAR_URI是基于环境变量来传递的:
driver:
envVars:
SPARK_JOB_JAR_URI: "wget下载文件的地址"
最后基于Dockerfile构建Spark镜像
FROM registry.cn-hangzhou.aliyuncs.com/lz18xz/lizu:v3.1.1
USER root
COPY mysql-connector-java-8.0.11.jar $SPARK_HOME/jars
RUN chmod 644 $SPARK_HOME/jars/mysql-connector-java-8.0.11.jar
RUN sed -i s@/deb.debian.org/@/mirrors.aliyun.com/@g /etc/apt/sources.list
RUN sed -i s@/security.debian.org/@/mirrors.aliyun.com/@g /etc/apt/sources.list
RUN apt-get update && apt-get install -y vim
RUN apt-get -qqy install iputils-ping
RUN apt-get -qqy install apt-transport-https wget
COPY custom-entrypoint.sh /opt
RUN chmod 775 /opt/custom-entrypoint.sh
ENTRYPOINT ["/opt/custom-entrypoint.sh"]
这样pod启动之前就会先去执行custom-entrypoint脚本中的内容。此时我们就可以直接使用local:///的方式指定jar包了。
最后,我们还需要在数据平台中对Spark-Operator提交任务的方式进行集成,让其可以和其他任务一样被调度。这里简单介绍一下具体的实现:
引入依赖
<dependency>
<groupId>io.fabric8</groupId>
<artifactId>kubernetes-client</artifactId>
</dependency>
定义资源实例
这一步就是将资源实例yaml文件中的内容通过java代码定义出来。当然也可以直接定义一个yaml字符串模板,就无需定义java的bean了。不管使用哪种方式,只需要我们将里面的参数填充就可以。
public class SparkGenericKubernetesResource extends GenericKubernetesResource {
private SparkOperatorSpec spec;
public SparkOperatorSpec getSpec() {
return spec;
}
public void setSpec(SparkOperatorSpec spec) {
this.spec = spec;
}
}
public class SparkOperatorSpec {
private String type;
private String mode;
private String image;
private String imagePullPolicy;
private String mainClass;
private String mainApplicationFile;
private String sparkVersion;
private RestartPolicy restartPolicy;
private List<Volume> volumes;
private Driver driver;
private Executor executor;
}
提交实例
public void createSparkOperatorJob(String namespace,
SparkGenericKubernetesResource sparkGenericKubernetesResource) {
try {
CustomResourceDefinitionContext context = getSparkCustomResourceDefinitionContext();
MixedOperation<GenericKubernetesResource, GenericKubernetesResourceList, Resource<GenericKubernetesResource>> resourceMixedOperation =
client.genericKubernetesResources(context);
resourceMixedOperation.inNamespace(namespace)
.createOrReplace(sparkGenericKubernetesResource);
} catch (Exception e) {
throw new TaskException("fail to create job", e);
}
}
这里需要传入提交资源的自定义信息,我们可以通过查看自定义crd的定义yaml文件来获取。(spark-operator部署完成后,就会有对应的crd被创建到集群中)
kubectl edit crd sparkapplications.sparkoperator.k8s.io
private CustomResourceDefinitionContext getSparkCustomResourceDefinitionContext() {
return new CustomResourceDefinitionContext.Builder()
.withGroup("sparkoperator.k8s.io")
.withVersion("v1beta2")
.withScope("Namespaced")
.withName("spark-operator-task")
.withPlural("sparkapplications")
.withKind("SparkApplication")
.build();
}
任务监控
提交任务完成后,最终还要对spark任务的进行监控,查看其运行情况:
private void registerOperatorJobWatcher(K8sSparkOperatorTaskMainParameters k8STaskMainParameters) {
CountDownLatch countDownLatch = new CountDownLatch(1);
Watcher<GenericKubernetesResource> watcher = new Watcher<GenericKubernetesResource>() {
@Override
public void eventReceived(Action action, GenericKubernetesResource resource) {
if (action != Action.ADDED) {
int jobStatus = getK8sJobStatus(resource);
logger.info("watch spark operator :{}", jobStatus);
if (jobStatus == EXIT_CODE_SUCCESS || jobStatus == EXIT_CODE_FAILURE) {
countDownLatch.countDown();
}
}
}
@Override
public void onClose(WatcherException e) {
logStringBuffer.append(String.format("[K8sJobExecutor-%s] fail in k8s: %s",
sparkGenericKubernetesResource.getMetadata().getName(), e.getMessage()));
countDownLatch.countDown();
}
@Override
public void onClose() {
logger.warn("Watch gracefully closed");
}
};
Watch watch = null;
try {
watch = k8sUtils.createBatchSparkOperatorJobWatcher(
sparkGenericKubernetesResource.getMetadata().getName(), watcher);
countDownLatch.await();
} catch (Exception e) {
} finally {
if (watch != null) {
watch.close();
}
}
}
public Watch createBatchSparkOperatorJobWatcher(String jobName,
Watcher<GenericKubernetesResource> watcher) {
try {
CustomResourceDefinitionContext context = getSparkCustomResourceDefinitionContext();
MixedOperation<GenericKubernetesResource, GenericKubernetesResourceList, Resource<GenericKubernetesResource>> resourceMixedOperation =
client.genericKubernetesResources(context);
return resourceMixedOperation.withName(jobName).watch(watcher);
} catch (Exception e) {
throw new TaskException("fail to register spark operator batch job watcher", e);
}
}
Watcher相当于一个异步的监控,在其eventReceived事件中可以不断的获取到任务的状态。配合CountDownLatch就可以完成需要的功能。
当前Spark on K8S又或者是Flink on K8S的热度都很高,Flink官方在新的版本中也已经支持了Flink Operator。有了Spark on K8S的基础,其实也就基本知道如何使用Flink Operator。 通过上面的实现方式,我们已经验证了其可行性,并且已经在小部分场景下使用。后续会在公司负责K8S同事的协助下逐步完善整个流程,并且明年逐步在其他业务中进行使用。