




checkpoint
如果系统每次收到写入请求后,等待数据完全写入持久化存储再返回结果,这样数据丢失的可能性大大减少,但是一般持久化操作都是磁盘IO操作(甚至网络IO操作),处理的耗时比较长,这样读写的效率就会很低。(write through)
为了保证读写的效率,一般我们都会通过异步的方式来写数据,即先把数据写入内存,返回请求结果,然后再将数据异步写入。但是如果异步写入之前,系统宕机,会导致内存中的数据丢失。(write back)
当系统出现故障重启后,通常要对前面的操作进行replay。但是从头开始代价太高了,所以通过checkpoint来减少进行replay的操作数。checkpiont机制保证在某一时刻,系统运行所在的易失性存储数据与持久化存储的数据保持完全同步,当系统出现故障进行重启的时候,从这一点开始恢复(replay),从而保证 At-Least 语义.
接下来总结一下我遇到的使用checkpoint的工具(后续遇到再不断增加)。
数据库checkpoint
可以数据库故障恢复与检查点来学习checkpoint机制, 以下内容copy from 《数据库系统基础讲义》
事务对数据可进行操作时:先写运行日志;写成功后,在与数据库缓冲区进行信息交换。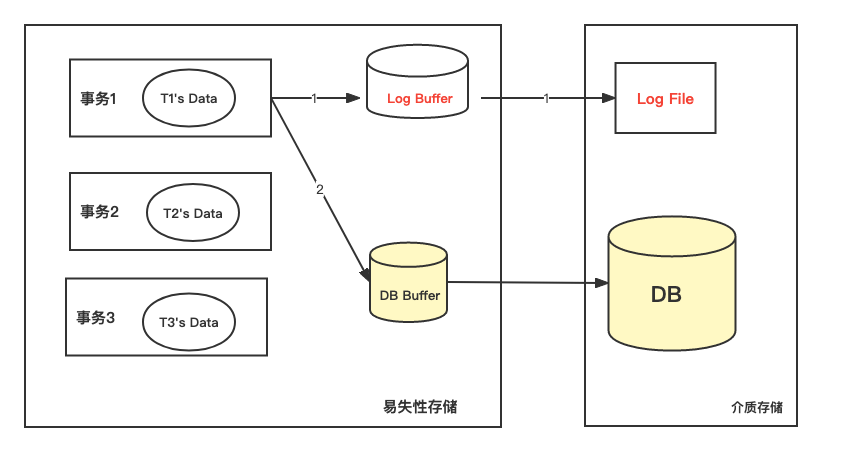
如果发生数据库系统故障可通过运行日志来恢复。根据运行日志记录的事物操作顺序重做事务(当事务发生故障时已正确结束)或撤销事务(当事物在发生故障时未结束)。
但是故障恢复是需要时间的。运行日志保存了若干天的记录,当发生系统故障时应从哪一点开始恢复呢?
DBMS在运行日志中定期的设置和更新检查点。检查点是这样的时刻:在该时刻,DBMS强制使内存DB Buffer中的内容与DB中的内容保持一致,即将DB Buffer中更新的所有内容写回DB中。即在检查点之前内存中数据与介质中数据是保持一致的。
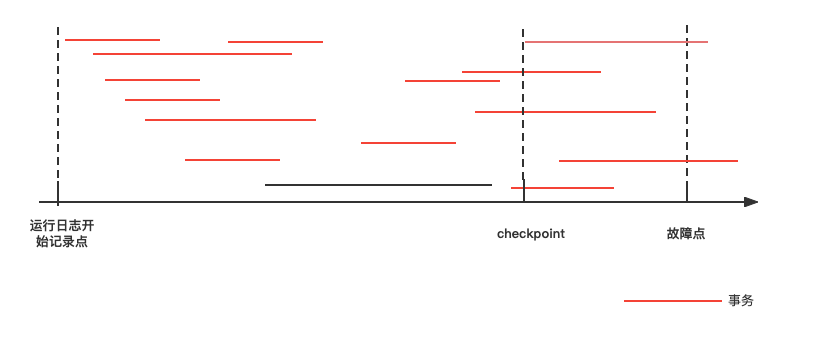
所以系统故障的恢复:
- 检查点之前结束的事物不需要恢复(已经写入DB)
- 检查点之后结束或者正在发生的事务需要依据运行日志进行恢复(不能确定是否写回DB):故障点结束前结束的重做,故障时刻未结束的撤销。=>重做在kafka中的一种形式为:Follower根据hw截断,并重新fetch
而对介质故障对恢复通过备份实现的。在某一时刻,对数据库在其他介质存储上产生的另一份等同记录。当发生介质故障时,用副本替换被破环的数据库。由于介质恢复影响全面,在用副本恢复后还需要依据运行日志进行恢复。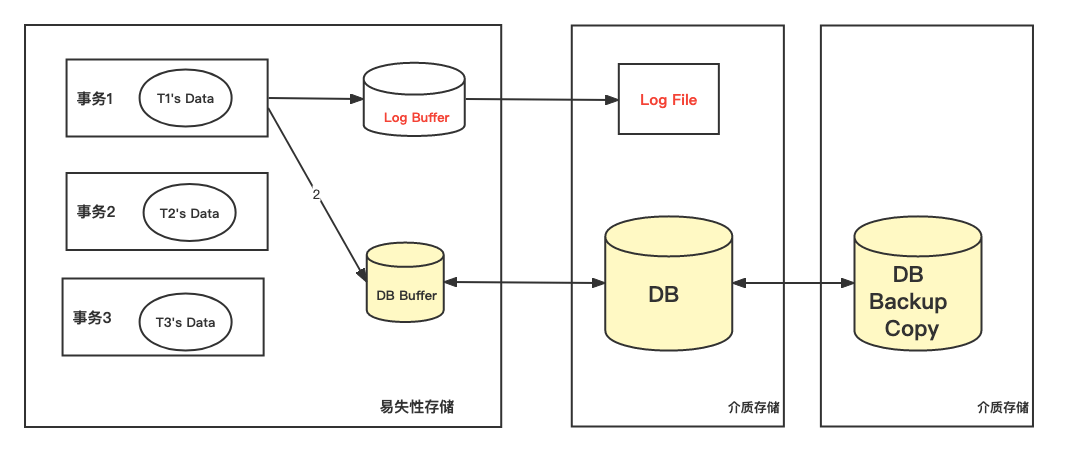
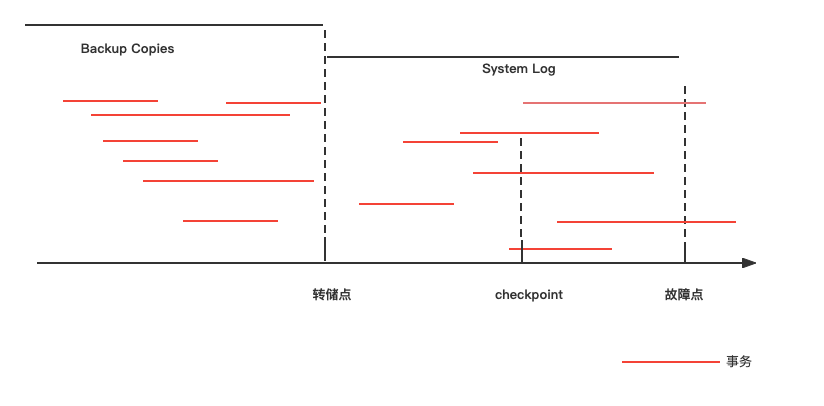
通过转储点来确定备份的时刻,转储点的设置有以下注意点:
- 备份转储周期与运行日志的大小密切相关,应注意防止衔接不畅而引起的漏洞。
- 过频,会影响系统工作效率;过疏,会造成运行日志过大,也影响系统运行性能。
Kafka checkpoint
Kafka的根目录下有四个检查点文件:
- replication-offset-checkpoint:对应HW,有定时任务刷写,由broker端参数 replica.high.watermark.checkpoint.interval.ms来配置
- recovery-point-offset-checkpoint:对应LEO,有定时任务刷写,由broker端参数 replica.flush.offset.checkpoint.interval.ms 来配置
- log-start-offset-checkpoint: 对应LogStartOffset,有定时任务刷写,由broker端参数 log.flush.start.offset.checkpoint.interval.ms 来配置
- cleaner-offset-checkpoint: 清理检查点文件,用来记录每个主题的每个分区已清理的偏移量。
StackOverFlow上从checkpiont机制的角度来进行解释:
- recovery-point-offset-checkpoint is the internal broker log where Kafka tracks which messages (from-to offset) were successfully checkpointed to disk. 即 recovery-point-offset-checkpoint 表示成功checkpoint到磁盘的偏移量,重启后需要从这一点恢复,将后面的消息截断。
- replication-offset-checkpoint is the internal broker log where Kafka tracks which messages (from-to offset) were successfully replicated to other brokers. 即 replication-offset-checkpoint 表示成功checkpoint到其他broker上面的消息,Follower重启后将其设为hw, 从这一点执行截断,防止出现数据不一致。
Flink checkpoint
A checkpoint in Flink is a consistent snapshot of:
- The current state of an application
- The position in an input stream
Flink 容错机制的核心部分是通过持续创建分布式数据流和算子状态的快照。这些快照充当一致的检查点(snapshots),系统可以在发生故障时回退到这些检查点(checkpoints)。
Flink 使用 Chandy-Lamport algorithm 算法的一种变体,称为异步 barrier 快照(asynchronous barrier snapshotting)。当 checkpoint coordinator(job manager 的一部分)指示 task manager 开始 checkpoint 时,它会让所有 sources 记录它们的偏移量,并将编号的 checkpoint barriers 插入到它们的流中。这些 barriers 流经 job graph,标注每个 checkpoint 前后的流部分。

Checkpoint n 将包含每个 operator 的 state,这些 state 是对应的 operator 消费了严格在 checkpoint barrier n之前的所有事件,并且不包含在此(checkpoint barrier n)后的任何事件后而生成的状态。
当 job graph 中的每个 operator 接收到 barriers 时,它就会记录下其状态。 拥有两个输入流的 Operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment) 以便当前快照能够包含消费两个输入流 barrier 之前(但不超过)的所有 events 而产生的状态。

Flink 的 state backends 利用写时复制(copy-on-write)机制允许当异步生成旧版本的状态快照时,能够不受影响地继续流处理。只有当快照被持久保存后,这些旧版本的状态才会被当做垃圾回收。
GFS checkpoint
Copy From 《google file system》
操作日志(operate log) 保存了关键的元数据变化历史记录。它是GFS的核心: 不仅仅因为这是唯一持久化的元数据记录,而且也是因为操作记录作为逻辑时间基线,定义了并行操作的顺序。 由于操作日志是极关键的,我们必须将其可靠保存。在元数据改变并且持久化之前,对于客户端来说都是不可见的(也就是说保证原子性)。否则,就算是chunkserver完好的情况下,我们也可能会丢失整个文件系统,或者最近的客户端操作。因此,我们把这个文件保存在多个不同的主机上,并且只有当刷新这个相关的操作记录到本地和远程磁盘之后,才会给客户端操作应答。master可以每次刷新一批日志记录,以减少刷新和复制这个日志导致的系统吞吐量。 master通过replay操作日志恢复自身文件系统状态。为了减少启动时间,我们必须尽量减少操作日志的大小。master在日志增长超过某一个大小的时候,执行checkpoint动作保存自己的状态,这样可以使下次启动的时候从本地硬盘读出这个最新的checkpoint,然后replay有限记录数。checkpoint是一个类似B-树的格式,可以直接映射到内存,而不需要额外的分析。这更进一步加快了恢复的速度,提高了可用性。 因为建立一个checkpoint可能会花一点时间,于是我们这样设定master的内部状态: 新建立的checkpoint可以不阻塞新的状态变化。master切换到一个新的log文件,并且在一个独立的线程中创建新的checkpoint。 新的checkpoint包含了在切换到新log文件之前的状态变化。当这个集群有数百万文件的时候,创建新的checkpoint会花上几分钟的时间。当checkpoint建立完毕,会写到本地和远程的磁盘。 对于master的恢复,只需要最新的checkpoint以及后续的log文件。旧的checkpoint及其log文件可以删掉了,虽然我们还是保存几个checkpoint以及log,用来防止比较大的故障产生。在checkpoint的时候得故障并不会导致正确性受到影响,因为恢复的代码会检查并且跳过不完整的checkpoint。
我是新人loserwang,希望大家多多支持。转载请先与本人联系。