




工程化概念
定义
- 工程化即系统化、模块化、规范化的一个过程。与其说软件工程是一门科学,不如说它更偏向于管理学和方法论。
解决什么问题
- 如果说计算机科学要解决的是系统的某个具体问题,或者更通俗点说是面向编码的,那么工程化要解决的是如何提高整个系统编码、测试、维护阶段的生产效率。
模块化
模块化是工程化的基础:只有能将代码模块化,拆分为合理单元,才能使其具备调度整合的能 力,才有架构和工程一说。
使用模块化的好处:
-
解决命名冲突
-
提供复用性
-
提高代码可维护性
-
到底什么是模块化?
简单来说就是,对于 一个复杂的应用程序,与其将所有代码一股脑儿地放在一个文件中,不如按照一定的语法,遵循确定的规则(规范)将其拆分到几个互相独立的文件中 。 这些文件应该具有原子特性,也就是说,其内部完成共同的或类似的逻辑,通过对外暴露一些数据或调用方法,与外部完成整合 。 这样一来,每个文件彼此独立,开发者更容易开发和维护代码,模块之间又能够互相调用和通信,这是现代化开发的基本模式 。
其实,不论是我们的日常生活还是其他科学领域,都离不开模块化的概念,它主要体现了可复 用性、可组合性 、 中心化 、 独立性等原则 。 在模块化的基础上结合工程化,又可以衍生出很多概念和话题,如基千模块化的 treeshaking技 术、模块循环加载的处理等 。 不过不要着急 , 我们先来看一下前端模块化的发展历程 。
模块化的发展历程
- 早期“假“模块化时代
- 规范标准时代
- ES 原生时代
立即执行函数 IIFE 模式
在早期,实现模块化最常见的手段就是通过立即执行函数(IIFE) ,构造一个私有作用域,再通过闭包(从某种角度上看,闭包简直就是一个天生解决数据访问性问题的方案),将需要对外暴露的数据和接口输出。我们称之为IIFE 模式
const module = (function(){
// ... 声明各种变量、函数都不会污染全局作用域
var foo = 'bar'
var fn1 = function (){
// ...
}
var fn2 = function (){
// ...
}
return {fn1, fn2}
})()
我们在调用 module 时,如果想要访问没暴露的变量 foo,是访问不到具体数据的。
了解了这种模式,我们就可以在此基础上结合顶层 window 对象进行实现模块化的初级功能。
(function(window){
var data = 'data'
function foo(){
console.log(`foo executing, data is ${data}`)
}
function bar(){
data = 'modified data'
console.log(`bar executing, data is now${data}`)
}
window.module1 = {foo, bar}
})(window)
数据 data 完全做到了私有,外界无法修改 data 值。 那么如何访问 data 呢?这时就需要模块内部设计并暴露相关接口。上述代码只需要调用模块 module! 暴露给外界 (window) 的函数即可:module1.foo()。修改 data值的途径,也只能由模块 moduleI 提供:module1.bar()。
进一步思考,如果 module} 依赖外部模块 module2(jQuery),该怎么办?
(function(window, $){
var data = 'data'
function foo(){
console.log(`foo executing, data is ${data}`)
console.log($)
}
function bar(){
data = 'modified data'
console.log(`bar executing, data is now${data}`)
}
window.module1 = {foo, bar}
})(window, jQuery)
事实上,这就是现代模块化方案的基石。至此,我们经历了模块化的第一阶段: “假“模块化 时代。这种实现极具阿 Q 精神,它并不是语言原生层面上的实现,而是开发者利用语言,借助 JavaScript 特性,对类似的功能进行了模拟,为后续方案打开了大门。
CommonJS
CommonJS 规范最早是 Node 独有的规范,目前也仍然广泛使用,比如在 Webpack 中就能见到它。浏览器中使用需要用到Browserify解析。 Node 在实现中并非完全按照规范实现,而是对模块规范进行了一定的取舍,同时也增加了少许自身需要的特性。 CommonJS 对模块的定义十分简单,主要分为模块引用、模块定义和模块标识 3 个部分。
1. 模块引用 在 CommonJS 规范中,存在require() 方法,这个方法接受模块标识,以此引入一个模块的 API 到当前上下文中。var math = require('math');
- 模块按照代码引入的顺序进行加载。
- 模块可以被多次引用、加载 。 在第一次被加载时,会被缓存,之后都从缓存中直接读取结果
2. 模块定义 在模块中,对应引入的功能,上下文提供了exports 对象用于导出当前模块的方法或者变量,并且它是唯一导出的出口。
- 在 Node 中,一个文件就是一个模块。在模块中,存在一个
module对象,它代表模块自身,而exports是module的属性。 - 将方法挂载在
exports对象上作为属性即可定义导出的方式。加载某个模块,其实就是引入该模块的module.exports属性。 module.exports属性输出的是值的拷贝,一旦这个值被输出 ,模块内再发生变化也不会影响 到输出的值 。
// a.js
module.exports = {
a: 1
}
// or
exports.a = 1
// b.js
var module = require('./a.js')
module.a // -> log 1
// 文件即模块,文件内的所有代码都运行在独立的作用域中,因此不会污染全局空间
// 这里其实就是包装了一层立即执行函数
-
在上述代码中,
module.exports和exports很容易混淆,可点击展开查看内部大致实现。var module = { id: 'xxxx', // 我总得知道怎么去找到它吧 exports: {} // exports 就是个空对象 } // 这行代码是为什么 exports 和 module.exports 用法相似的原因 var exports = module.exports var load = function (module) { // 导出的东西 var a = 1 module.exports = a return module.exports }; // 当 require 的时候去找到独特的 id,然后将要使用的东西用立即执行函数包装下,over重要的是 module 这里,module 是 Node 独有的一个变量
另外虽然两者用法相似,但是不能对
exports直接赋值,不会有任何效果。
因为
var exports = module.exports这句代码表明了exports和module.exports享有相同地址,通过改变对象的属性值会对两者都起效,但是如果直接对exports赋值就会导致两者不再指向同一个内存地址,修改并不会对最终返回的module.exports起效。
3. 模块标识 模块标识其实就是传递给require()方法的参数,它必须是符合小驼峰命名的字符串,或者以.、..开头的相对路径,或者绝对路径。它可以没有文件名后缀.js。模块的定义十分简单,接口也十分简洁。它的意义在于将类聚的方法和变量等限定在私有的作用域中,同时支持引入和导出功能以顺畅地连接上下游依赖。
AMD 和 CMD
目前这两种实现方式已经过时,只需要了解这两者是如何使用的即可
AMD:
AMD 规范是 CommonJS 模块规范的一个延伸,它的全称是 Asynchronous Module Definition,即“异步模块定义”。按照该标准加载模块时是异步的,这种标准是完全适用于浏览器的 。
define(id?,dependencies?,factory);
// 模块 id 和 依赖 是可选的,与 Node 模块相似的地方在于 factory 的内容就是实际代码的内容
下面的代码定义了一个简单的模块:
define(['./a', './b'], function(a, b) {
var exports = {};
// 加载模块完毕可以使用
a.do()
b.do()
exports.sayHelloFromA = function() {
alert('hello from module:' + a.id)
};
return exports;
})
不同之处在于 AMD 模块需要用define来明确定义一个模块,而在 Node 实现中是隐式包装的。
它们的目的是进行作用域隔离,仅在需要的时候被引入,避免掉过去那种通过全局变量或者全局命名空间的方式,以免变量污染和不小心被修改。另一个区别则是内容需要通过返回的方式实现导出。
CMD:
CMD 规范由国内的玉伯提出,与 AMD 规范的主要区别在于定义模块和依赖引入的部分。
- AMD 需要异步加载模块,而 CMD 在加载模块时,可以通过同步的形式 (require) ,也可以通过异步的形式 (require.async) 。
- CMD 遵循依赖就近原则, AMD 遴循依赖前置原则。
也就是说,在 AMD 中,我们需要把模块所需要的依赖都提前声明在依赖数组中,然后通过形参传递依赖到模块内容中:
define(['dep1','dep2'], function(dep1, dep2){
return function() {};
});
而 CMD 中,支持动态引入。将 require、exports和module通过形参传递给模块,然后在具体代码逻辑内,在使用依赖模块前,随时调用require()引入依赖的模块即可 。
define(function(require, exports, module){
// 加载模块
// 可以把 require 写在函数体的任意地方实现延迟加载
var a = require('./a')
a.doSomething()
})
ES Module
在有 Babel 的情况下,我们可以直接使用 ES6 原生实现的模块化方案 ES Module,最后也会编译成require/exports
// file1.js
export function a() {}
export function b() {}
// file2.js
export default function() {}
// 引入模块
import {a, b} from './file1.js'
import XXX from './file2.js'
ES模块化导出有 export 和 export default 两种。两种导出模块的方式不同,在另一个模块中引用的方式也不一样。这里建议减少使用 export default 导出。
- 一方面 export default 会导出整体对象结果,不利于通过 tree shaking 进行分析
- 另一方面 export default 导出的结果可以随意命名变量,不利于团队统一管理
CommonJS 和 ES Module 的区别?
- ES 模块的设计思想是尽量静态化,这样能保证在编译时就确定模块之间的依赖关系,每个模块的输入和输出变量也都是确定的。而 CommonJS 和 AMD 模块无法保证在编译时就确定这些内容,它们都只能在运行时确定。这是 ES 模块和其他模块规范最显著的差别。
- CommonJS 模块输出的是一个值的拷贝,就算导出的值变了,之前导入的值也不会改变,所以如果想更新值,必须重新导入一次。 ES 模块输出的是值的引用。采用实时绑定的方式,导入导出的值都指向同一个内存地址,所以导入值会跟随导出值变化。
- CommonJS 是同步导入,因为用于 node 服务端,文件都在本地,同步导入即使卡住对主线程影响也不大。而 ES Module 是异步导入,因为用于浏览器,需要下载文件,如果也采用同步导入会对渲染有很大影响。
ES 模块为什么要设计成静态的?
将 ES 块设计成静态的, 一个明显的优势是:通过静态分析,我们能够分析出导入的依赖。 如果导入的模块没有被使用,我们便可以通过 tree shaking 等手段减少代码体积,进而提升运行性能。这就是基于 ESM 实现 tree shaking 的基础 。
这么说可能过于笼统,下面从设计的角度分析这种规范的利弊 。 静态性需要规范去强制保证,因此 ES 模块规范不像 CommonJS 规范那样灵活,其静态性会带来如下一些限制。
- 只能在文件顶部引入依赖。
- 导出的变量类型受到严格限制。
- 变量不允许被重新绑定,引入的模块名只能是字符串常量,即不可以动态确定依赖 。
这样的限制在语言层面带来的便利之一是,我们可以通过分析作用域,得出代码中变量所属的作用域及它们之间的引用关系,进而可以推导出变量和导入依赖变量之间的引用关系,在没有明显引用时,可以对代码进行去冗余 。

Babel
babel-handbook/plugin-handbook.md at master · jamiebuilds/babel-handbook
原理
babel 本质就是编译器,它的转译过程分为三个阶段:
- 解析(Parse): 将代码解析生成抽象语法树( 即AST ),即词法分析与语法分析的过程。
- 转换(Tansform): 对于 AST 进行变换一系列的操作,babel 接受得到 AST 并通过 babel-traverse 对其进行遍历,在此过程中对相应节点进行添加、更新及移除等操作。
- 生成(Generate): 将变换后的 AST 再转换为 JS 代码, 使用到的模块是 babel-generator。
CSS 工程
如何维护大型项目的 z-index,如何维护 CSS 选择器和样式之间的冲突 ?
CSS Modules
CSS Modules 是指:项目中的所有 class 名默认都是局部起作用的。 其实, CSS Modules 并不是一个官方规范,更不是浏览器的机制 。 因为它依赖我们的项目构建过程,因此基于它的实现往往需要借助 webpack或其他构建工具,将 class 名唯一化,从而使其只在局部起作用。
.style_test_1923235023 { color: red; }
`
This is a test.
`
其中, class 名是动态生成的,在整个项目中这个名字是唯一的。通过命名规范的唯一性,达到了避免样式冲突的目的。不过,这样的解决方案似乎有一个问题:如何实现样式复用?
因为生成了全局唯一的 class 名,所以我们如何像传统方式那样实现样式复用呢?
从原理上想 ,全局唯一的 class 名是在构建过程中生成的,所以如果能够在构建过程中进行标识,表示该 class 将被复用,就可以解决问题了。
这样的方式需要依靠composes关键字实现:
.common {
color: red;
}
.title {
composes: common;
font-size: 24px;
}
使用 composes 关键字在 title 中关联了 common 样式
<div
class="_style_title_09082423 _style_commin_23230082">
This is a test.
</div>
div 的 class 中加入了 _style_commin_23230082,这样就实现了样式复用
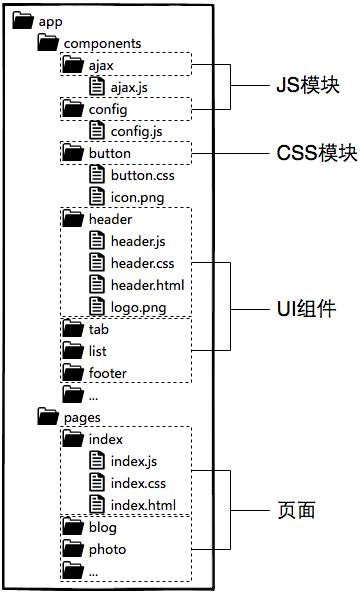
路由原理
前端路由实现起来其实很简单,本质就是监听 URL 的变化,然后匹配路由规则,显示相应的页面,并且无须刷新。目前单页面使用的路由就只有两种实现方式。
- hash 模式
- history 模式
www.test.com/##/ 就是 Hash URL,当 ## 后面的哈希值发生变化时,不会向服务器请求数据,可以通过 hashchange 事件来监听到 URL 的变化,从而进行跳转页面。
History模式是 HTML5 新推出的功能,比之 Hash URL 更加美观。
项目的组织设计
随若业务复杂度的直线上升,前端项目不管是从代码量上,还是从依赖关系上都呈爆炸式增长。同时,由于团队中一般不止有一个业务项目,所以“多个项目之间如何配合”、“如何维护相互关系”、“公司自己的公共库版本如何管理”,这些问题随着业务扩展纷纷浮出水面。 一名合格的高级前端工程师,必需能在宏观上妥善处理这些问题 。
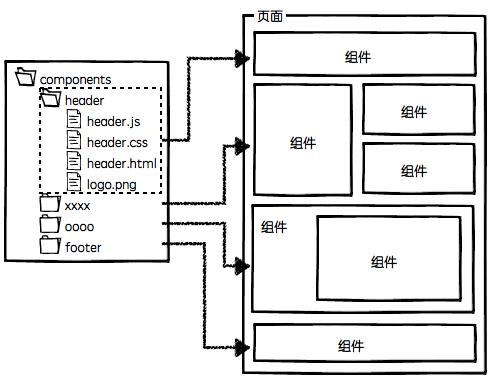
monorepo 和 multirepo
- multirepo:顾名思义,就是将应用按照模块分别在不同的仓库中进行管理
- monorepo 就是将应用中所有的模块一股脑儿全部放在同一个项目中,不需要单独发包、测试,且所有代码都在一个项目中管理,一同部署上线,能够在开发阶段更早地复现 bug, 暴露问题。
这就是项目代码在组织上的不同哲学: 一种倡导分而治之, 一种倡导集中管理 。 究竟是把鸡蛋 放在同一个篮子里,还是倡导多元化,这就要根据团队的风格及面临的实际场景进行选型了 。
multirepo 存在以下问题:
- 开发调试及版本更新效率低下
- 团队技术选型分散,不同库的实现风格可能存在较大差异(比如有的库依赖Vue,有的依赖 React )
- changelog 梳理困难,Issues 管理混乱 (对于开源库来说 )
而 monorepo 缺点也非常明显,具体如下:
- 库体积超大,目录结构复杂度上升
- 需要使用维护 monorepo 的工具,这就意味着学习成本比较高
常用自动化工程工具
-
使用前端构建工具
- gulp、grunt、Broccoli
-
javascript 编译工具
- Babel、Browserify、Webpack
-
开发辅助工具
- 数据 mock、livereload
-
使用CI集成工具
- jenkins、Travis CI
-
使用脚手架工具
- yeoman、create-app
以上就是我对前端模块化的总结和理解,希望给大家带来帮助,谢谢~