




我是 Redis,给开发者提供了 String(字符串)、Hashes(散列表)、Lists(列表)、Sets(无序集合)、Sorted Sets(可根据范围查询的排序集合)、Bitmap(位图)、HyperLogLog、Geospatial (地理空间)和 Stream(流)等数据类型。
接下来我要介绍的是,String 类型的使用技巧和使用场景,以及数据类型底层数据结构原理。
数据类型的使用技法和以及每种数据类型底层实现原理是你核心筑基必经之路,好好修炼。
筑基稳固,修炼心法,让你的程序更快还能做到极致节省内存。
String(字符串)
1. 是什么
字符串类型的使用最为广泛,比如计数器、缓存、分布式锁、用于存储登录后的用户信息,key = token,value = Java 对象序列化成 JSON 后的字符串。
如下指令。
SET user:token:666 {"name": "码哥",“gender”: “M”,“city”:"shenzhen"}
接下来,我先带你深入了解 String 类型,底层数据结构和使用场景。
MySQL:“你都是用 C 语言开发出来的,C 语言本就有字符串,吓唬谁呢。”
格局能不能打开一点,我并没有直接使用 C 语言的字符串,而是自己搞了一个 SDS 结构体来表示字符串。SDS 的全称是 Simple Dynamic String,中文叫做“简单动态字符串”。
MySQL:“搞 SDS 的目的是啥?”
字符串使用最为广泛,我要保证能支持丰富和高性能的字符串操作函数,能保存二进制数据,同时还能节省内存占用。
实现了你们领导平时经常对你们提出的既要又要还要的目标。
先看 C 语言字符串数组的结构。比如通过 char *s = "MageByte"定义字符串变量。
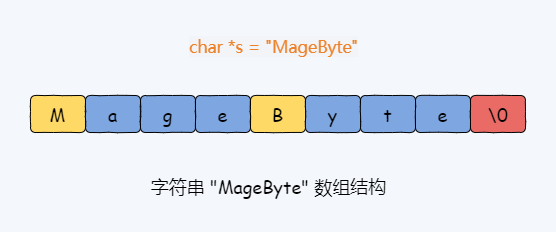
图 2-1
注意,数组的最后一个字符串是 "\0",它表示字符串的结束。
因为 C 语言标准库 string.h中的字符串有以下几点不足,所以我才设计了 SDS。
- C 语言使用
char*字符串数组来实现字符串,在创建字符串的时候就要需要手动检查和分配字符串空间。由于没有length属性记录字符串长度,想要获取一个字符串长度就要从头开始遍历,直到\0为止,作为唯快不破的我来说是不能容忍的。 - 无法做到“安全的二进制存储”:比如图片等二进制数据无法保存。无法存储
\0这种特殊字符是因为\0在 C 语言字符串中表示结尾。 - 字符串的扩容和缩容:char 数组的长度在创建字符串的时候就确定下来,如果想要追加数据,要重新申请一块空间,把追加后的字符串内容拷贝进去,再释放旧的空间,十分消耗资源。
2. 修炼心法
MySQL:“说说 SDS 结构体吧,你是如何解决这些问题的。”
为了存储字符串实际内容,我需要有一个 char 类型数组来存储,使用一个 int 类型的 len 字段用于记录 char 数组使用了多少字节。
除此之外,还要有一个 int 类型 的 alloc 字段记录分配的 char 数组总长度,alloc - len 就等于 char 类型的 buf 数组未使用的字节数(Redis 7.0 已经去掉了表示未使用字节数 free 字段)。
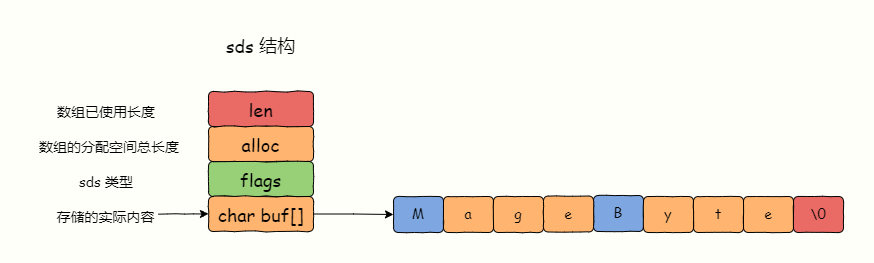
图 2-2
SDS 也遵循 C 字符串以空字符“\0”结尾的惯例,保存空字符的大小不计算在 SDS 的 len 属性中。
此外,添加空字符串“\0” 到字符串末尾等操作,都是由 SDS 函数自动完成的。
O(1) 时间复杂度获取字符串长度
SDS 中 len 保存了字符串的长度,实现了O(1) 时间复杂度获取字符串长度。
你注意到了没,SDS 结构有一个 flags 字段,表示的是 SDS类型。实际上 SDS 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,区别在于数组的 len 长度和分配空间长度 alloc。
比如 sdshdr8。
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len;
uint8_t alloc;
unsigned char flags;
char buf[];
};
len、alloc 字段都是 uint8_t 这个类型,在 Java 中 int 就是 32 位,而 C 语言里面有不同长度的 int 值,uint8_t 就是占 8 位的无符号 int 值,能表示的最大值就是 2^8-1,那它的 buf 数组,最大长度就是 2^8 -1。
节省内存
之所以这么设计,就是为了针对不同大小的字符串,使用不同的 SDS 类型保存,从而节省内存占用。
MySQL:“SDS 能存储多大的字符串?”
alloc 表示当前 sds 结构允许容纳的最大字符长度, 比如 uint32_t alloc 的取值范围是 0~2^32 = 4294967296。理论上 char 数组最大长度为 4294967296,一个 char 字符占用一个字节,可以存储 4 G,更不用说 sdshdr64 了。
这些都是理论值,实际上 Redis 内部会限制最大的字符串长度是 512M。
编码格式
我还对 String 类型的数据采用了三种编码格式来存储,分别是 int、embstr、raw,你可使用 OBJECT encoding key 来查值对象所使用的编码类型。
编码选择流程如图 2-3 所示。
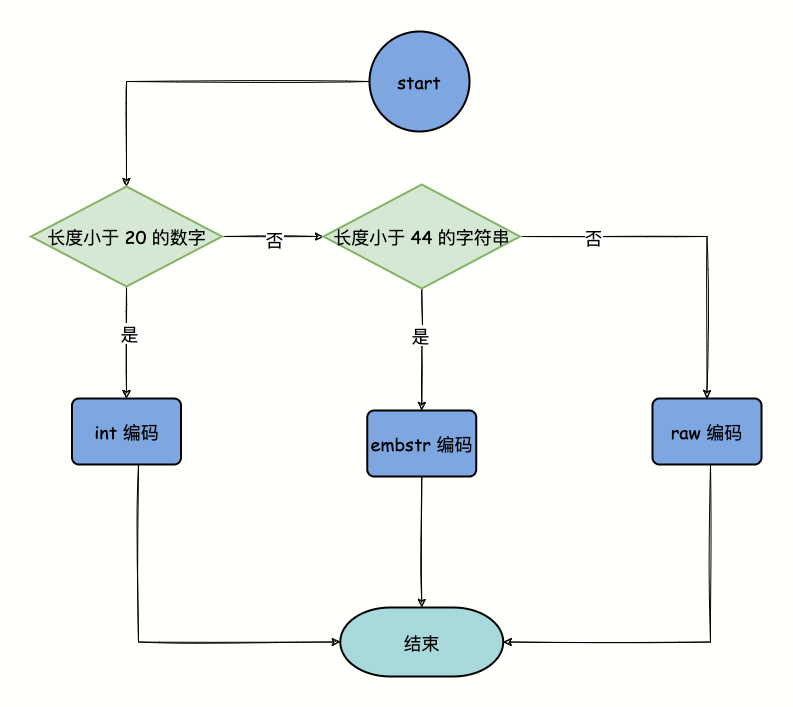
图 2-3
- int 编码,8 个字节的长整型,值是数字类型且数字的长度小于 20
- embstr,小于等于 44 字节的字符串。
- 大于 44 字节的字符串。
MySQL:“
__attribute__ ((__packed__))是什么玩意?”
这是我使用了专门的编译优化手段来节省内存空间。作用就是告诉编译器,不要使用字节对齐的方式,而是采用紧凑的方式分配内存。
默认情况下,编译器会按照 8 字节对齐的方式分配内存,即使这个变量的大小不到 8 字节。
使用了 __attribute__ ((__packed__)) 定义结构体,编译器会按照实际占用来分配内存空间。
二进制安全
SDS 不仅可以存储 String 类型数据,还能存储二进制数据。SDS 并不是通过“\0” 来判断字符串结束,用的是 len 标志结束,所以可以直接将二进制数据存储。
空间预分配
在需要对 SDS 的空间进行扩容时,不仅仅分配所需的空间,还会分配额外的未使用空间。
通过预分配策略,减少了执行字符串增长所需的内存重新分配次数,降低由于字符串增加操作的性能损耗。
惰性空间释放
当对 SDS 进行缩短操作时,程序并不会回收多余的内存空间,如果后面需要 append 追加操作,则直接使用 buf 数组 alloc - len中未使用的空间。
通过惰性空间释放策略,避免了减小字符串所需的内存重新分配操作,为未来增长操作提供了优化。
3. 出招实战:分布式 ID 生成器
我相信你会经常遇到要生成唯一 ID 的场景,比如标识每次请求、生成一个订单编号、创建用户需要创建一个用户 ID。
分布式 ID 生成器需要满足以下特性。
- 有序性之单调递增,想要分而治之、二分法查找就必须实现。另外,MySQL 是你们用的最多的数据库,B+ 树为了维护 ID 的有序性,就会频繁的在索引的中间位置插入而挪动后面节点的位置,甚至导致频繁的页分裂,这对于性能的影响是极大的。
- 全局唯一性,ID 不唯一就会出现主键冲突。
- 高性能,生成 ID 是高频操作,如果性能缓慢,系统的整体性能都会受到限制。
- 高可用,也就是在给定的时间间隔内,一个系统总的可用时间占的比例。
- 存储空间小,用 MySQL 的 InnoDB B+树来说,普通索引(非聚集索引)会存储主键值,主键越大,每个 Page 页可以存储的数据就越少,访问磁盘 I/O 的次数就会增加。
Redis 集群能保证高可用和高性能,为了节省内存,ID 可以使用数字的形式,并且通过递增的方式来创建新的 ID。
防止重启数据丢失,你还需要把 Redis AOF 持久化开启。
MySQL:“开启 AOF 持久,为了性能设置成 everysec 策略还是有可能丢失一秒的数据,所以你还可以使用一个异步机制将生成的最大 ID 持久化到一个 MySQL。”
好主意,在生成 ID 之后发送一条消息到 MQ 消息队列中,把值持久化到 MySQL 中。
我提供了 INCR 指令,它能把 key 中存储的数字加 1 并返回客户端。如果 key 不存在,那么 key 的 value 先被初始化成 0,再执行加 1 操作并返回给客户端。
该指令的值限制在 64 位有符号数字之内。
设计思路
-
假设订单 ID 生成器的 key 是“counter:order”,当应用服务启动的时候先从数据库中查询出最大值 M。执行
EXISTS counter:order判断是否存在 key。- Redis 中不存在 key “counter:order”,执行
SET counter:order M将 M 值作写入 Redis。 - Redis 中存在 key “counter:order”,值为 K,那么就比较 M 和 K 的值,执行
SET counter:order max(M, N)将最大值写入 Redis,相等的话就不操作。
- Redis 中不存在 key “counter:order”,执行
-
应用服务启动完成后,每次需要生成 ID 的时候,应用程序就向 Redis 服务器发送
INCR counter:order指令。 -
应用程序将获取到的 ID 值发送到 MQ 消息队列,消费者监听队列把值更新到 MySQL。
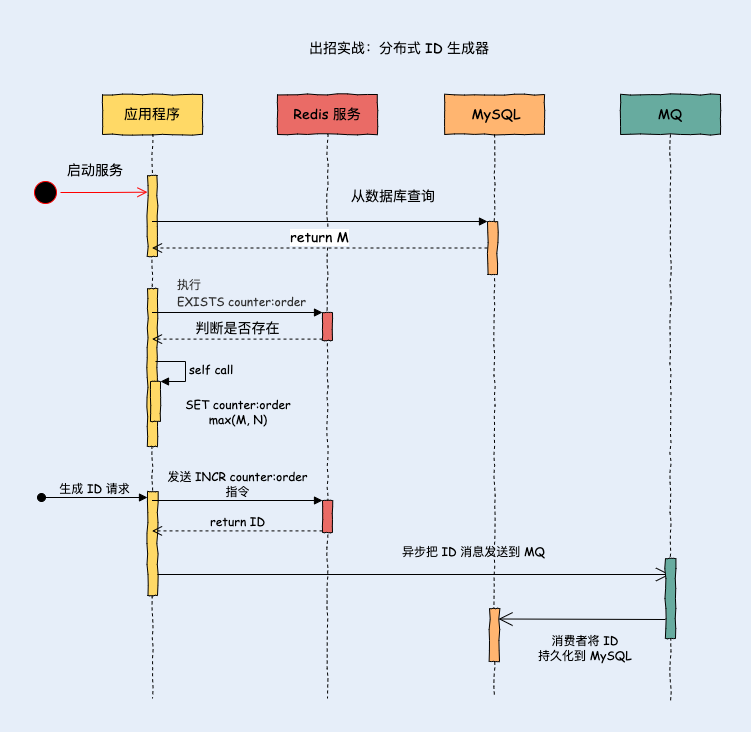
图 2-4