




M3KG-RAG(Multi-hop Multimodal Knowledge Graph-enhanced Retrieval-Augmented Generation)的核心目标是解决现有多模态RAG(检索增强生成)在音视频领域的两大局限:
- 现有多模态知识图谱(MMKG)模态覆盖不全(多聚焦图文,缺乏音视频深度支持)、多跳连接不足,难以支撑时空因果推理;
- 检索依赖共享嵌入空间的相似度匹配,易引入无关或冗余知识,降低回答可信度。
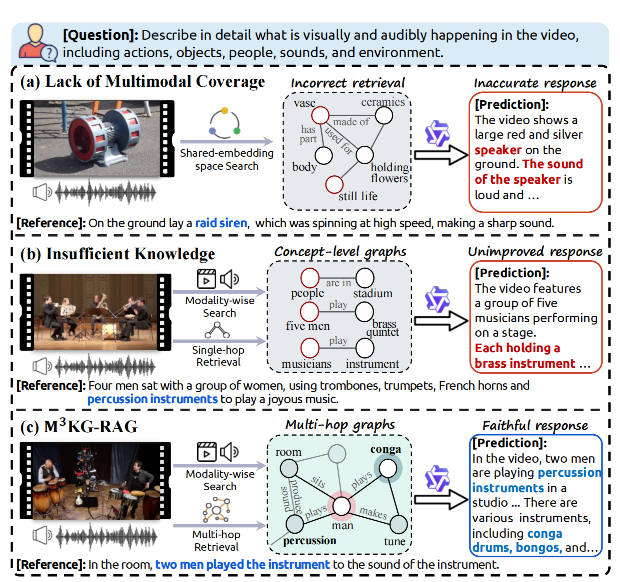
多模态 RAG 场景示意图。错误答案以 红色 显示,正确 答案以 蓝色 显示。(a) 共享嵌入搜索与音视频查询不匹配。(b) 噪声干扰的单跳事实提供的答案支持不足。(c) M3 KG-RAG 采用模态专属的多跳检索以获取答案支持的上下文。
M3KG-RAG通过“高质量多跳MMKG构建+精准检索与知识修剪”的端到端框架,为多模态大语言模型(MLLMs)提供查询对齐、支持回答的音视频知识,提升推理深度与回答忠实度。
方法
如下图:M3 知识图谱构建流水线的概述。该流水线包含三个步骤:(i) 上下文增强三元组提取,将多模态描述重写为知识密集型文本并提取实体-关系三元组;(ii) 知识锚定,将规范化实体链接到开放知识库以获取候选描述;(iii) 上下文感知描述优化,为每个实体选择并重写最符合上下文的描述;以及 自省环,其中检查智能体验证或重新运行不确定的输出,以确保图的质量。
(一)多跳多模态知识图谱(M³KG)构建:多智能体协同pipline
为解决现有MMKG的模态覆盖和多跳连接问题,M3KG-RAG设计了轻量型多智能体协同流水线,将原始多模态语料(文本、音频、视频)转化为含上下文丰富三元组的多跳知识图谱,全程兼顾自动化与质量控制。整个流程分为3个核心步骤+1个质量保障机制:
1. 上下文增强三元组提取
原始多模态语料中的文本描述往往语义通用(如“一个乐器在发声”),缺乏知识密度,无法直接作为MLLMs的外部知识。
- 第一步:通过“重写器(Rewriter)”将通用文本转化为知识密集型描述——融合爬取的外部信息(如视频标题、详细说明),补充特定概念(如乐器型号、场景背景)和属性,同时保持原语义与长度稳定性;
- 第二步:通过“提取器(Extractor)”解析重写后的文本,提取结构化的“头实体-关系-尾实体”三元组(如“苏格兰风笛-被演奏-舞台”“手鼓-发出-节奏声”),这些三元组天然包含跨模态(音视频)和时间线索,为多跳推理奠定基础。
2. Knowledge Grounding
提取的三元组中,实体可能存在表述变体(如“小型棕色狗”vs“狗”)或缺乏规范描述,导致MLLMs难以理解。
- 归一化:“Normalizer”去除实体的非必要修饰词、标准化单复数形式,将实体映射为可检索的规范概念(如“小型棕色狗”→“狗”);
- 外部关联:“Searcher”查询维基百科、韦氏词典等开放知识库,为规范实体获取百科式描述;若知识库无覆盖,则调用轻量LLM生成简洁准确的描述,确保每个实体都有可解释的知识支撑。
3. 上下文感知描述优化
同一实体可能存在多义性(如“bank”可指银行或河岸),需结合原始语料上下文消除歧义。
- 描述选择:“Selector”以重写后的知识密集型文本为依据,从候选描述中挑选与上下文最匹配的内容,过滤无关释义;
- 表述适配:“Refiner”将选中的规范描述调整为与原始实体表述一致的形式。
4. 自反思循环
为避免LLM生成描述时出现幻觉或错位,引入“Inspector”进行质量控制:对生成的实体描述打分(0-10分,评估与实体本义的匹配度),低于阈值的描述返回对应智能体重生,最多迭代3次,确保图谱知识的可靠性。
最终构建的M³KG满足“全模态关联”特性:每个三元组都至少链接到一段音频或视频数据,确保多模态查询(如音频片段、视频片段)能精准匹配到对应的结构化知识。
(二)多模态RAG框架
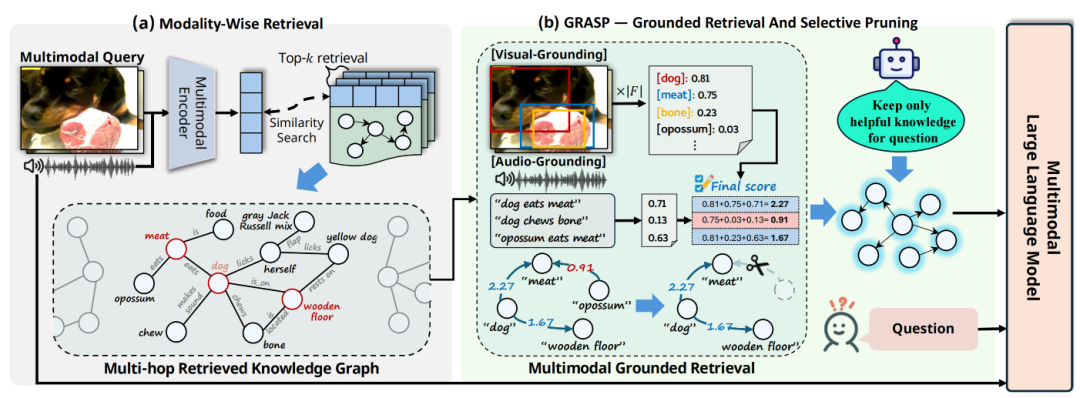
多模态 RAG 框架概述。该框架包含两个组成部分:(a) 模态专属检索,从 M3 知识图谱中检索与查询对齐的多跳三元组; 以及 (b) GRASP(基于实体的检索与选择性剪枝),利用视觉和/或音频定位模型检查实体是否存在,并剪除与主题无关或无信 息量的三元组。随后将得到的子图提供给多模态大语言模型,以进行与查询相关的、基于证据的音视频推理。
构建M³KG后,核心挑战转为“如何从海量多跳知识中筛选出仅与查询相关、且对回答有用的内容”,该框架通过“模态感知检索+GRASP修剪”实现双重精准过滤:
1. 模态感知检索
现有多模态检索的核心问题是“模态鸿沟”——共享嵌入空间中,跨模态相似度匹配(如用文本嵌入检索视频知识)易产生偏差。M3KG-RAG采用“同模态匹配”策略:
- 针对音频查询:用音频编码器(如CLAP)将查询编码,在M³KG的音频数据索引中检索最相似的Top-k音频项,再关联到对应的三元组;
- 针对视频查询:用视频编码器(如InternVL2)编码,检索视频数据关联的三元组;
- 针对音视频联合查询:拼接音视频嵌入后检索,确保检索结果与查询模态天然对齐,减少跨模态匹配的噪声。
2. GRASP:Grounded检索与选择性修剪
模态感知检索得到的“初始子图”仍可能包含与查询实体无关、或对回答无用的知识,GRASP通过两步修剪实现:
(1)多模态Grounded Filtering
验证三元组是否真实存在于查询的音视频流中,过滤“虚假关联”的知识:
- 视觉接地:对视频查询采样4帧关键帧,用GroundingDINO模型检测帧中是否存在三元组的实体(如“风笛”“鼓”),通过置信度评分过滤无对应实体的三元组;
- 音频接地:将三元组转化为自然句子(如“苏格兰风笛被演奏”),用文本-音频接地模型(TAG)评估句子与音频查询的相关性,过滤无音频支撑的三元组;
- 音视频联合查询:融合视觉和音频评分,保留双模态均支持的三元组。
(2)回答有用性修剪(Answer-Utility Pruning)
即使三元组与查询相关,也可能对回答无帮助(如查询“演奏的乐器是什么”时,“舞台是木质的”相关三元组)。此时调用轻量LLM,基于“保守保留”原则对三元组进行二分类:仅保留对回答问题有直接或间接支持的三元组,删除冗余、无关内容。
(三)知识增强生成
将修剪后的精准子图知识与多模态查询融合,输入MLLMs进行生成:
- 融合方式:将查询与子图中的三元组结构化呈现——每个三元组包含“头实体+其精炼描述-关系-尾实体+其精炼描述”(如“<苏格兰风笛,一种苏格兰传统管乐器>-被演奏-<舞台,用于表演的场地>”);
- 核心作用:为MLLMs提供结构化的多跳知识(如“风笛-被演奏-舞台”“演奏者-操作-风笛”),而非零散文本,帮助模型进行跨模态关联推理,同时避免幻觉。
实验性能
参考文献
M3KG-RAG: Multi-hop Multimodal Knowledge Graph-enhanced Retrieval-Augmented Generation,https://arxiv.org/pdf/2512.20136v2