




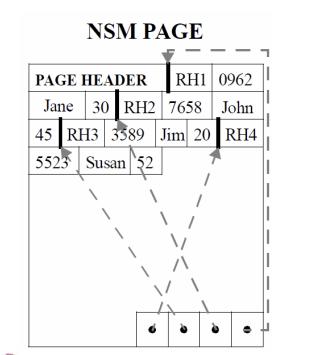
众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况下,数据一般采用一个一个的数据块进行存储,利用顺序读写提升性能。行存的实现一般是将一行数据完整的从头到尾连续存储(超长的字段一般会单独存储,行内记录逻辑地址),连续多行构成一个页,页的尾部通常会存储索引来解决record不定长时的快速查找问题,数据排列结构如下图所示:
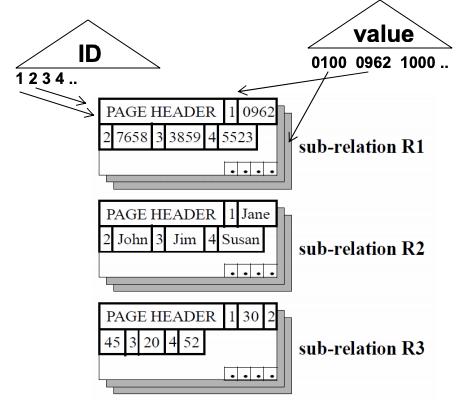
列存和行存的区别主要是在存储时将多行数据的相同column连续存储在一起,相同column的数据组成一个一个的块,排列结构如下图所示:
通过两者的存储方式我们可以看出,行存在insert/update/delete/point lookup query的场景是比较优的,因为涉及的行数据是连续存储的,理论上不存在读写放大,如处理一个query,通过使用table索引,可以快速寻址到页,然后根据页尾的索引能快速寻址到行首,将数据返回,这个特点非常符合OLTP的workload场景,所以在OLTP场景主要使用行存;但是行存不是完美的,例如需要遍历全表获取符合要求的行,但只取部分列进行分组/排序/聚合等操作,行存就不太适合了,在读取时,由于会读取大量的无效的列的数据,且数据量很大,在存储是系统瓶颈的时代无疑是一大灾难,而且会影响内存中cache的使用效率;在计算时,由于行数据在内存中是顺序存储在一起的,所以对 cpu cache 也很不友好。 列存就是解决上述问题的灵丹妙药,首先读取时只需要读取关心的列数据,在计算时也对cpu cache非常友好,所以存在大量复杂查询的数据分析场景(OLAP)主要使用列存。上帝开启了一扇门,也会关起一扇窗,列存在更新场景明显存在缺陷,每insert/update/delete 一行数据,由于会去更新存在在不同位置的column,会带来IO放大,且为随机IO。
其实在1983年列存概念就在Cantor论文【11】中提出了,85年Copeland and Khoshafian在SIGMOD上首次提出了DSM,参见《A decomposition storage model》论文【12】,但是在90s年到2000s年,列存的主要研究领域还是停留在怎么样打破内存墙,在2001年,Ailamaki等人提出了PAX(Partition Attributes Cross)【1】格式,开始研究怎么样结合列存的优势到行存中。2017年 google spanner 发表论文【2】,描述了自己如何使用PAX格式提升查询性能。

软件系统永远摆脱不了随硬件系统的演化而不断演进的宿命,其使命就是最大化压榨硬件。随后的几年,由于CPU提速比磁盘带宽的提升快得多,导致两者gap越来越大,面临TB级别的数据仓库的出现,存储侧数据模型急待变革,而列存中有两种途径可以通过CPU周期来节省磁盘带宽:首先,我们可以编码数据元素成压缩格式;然后可以将数据密集填充(densepack)后存储,而要提升压缩率,列存的相同列的数据存储在一起使其具备先天优势;再加上能不再读取无效的列带来的带宽节省,使其更势不可挡,随之而来的列式存储相关的研究和工业系统如雨后春笋般出现。2005年,是列式存储的重生之年,首个完整的列式存储系统C-Store发表论文【3】【4】;同年,MonetDB/X100论文发表【5】。后续的几年也同样代表作频出:2010年,大名鼎鼎的Apache Parquet 的原型论文Google Dremel 论文发表;2011年,clickHouse【6】诞生;随后的2012年,出现了两篇论文,分别是C-Store研究团队创业研发的C-Store商业化版本的Vertica【7】和google的PowerDrill【8】;Hive也在2014年发表论文介绍了广为人知的Apache ORC【9】;然后在2015年,Apache Kudu【10】论文发表。这些具有代表性的列存系统记录了列存的发展和演进。
C-Store/Vertica
架构
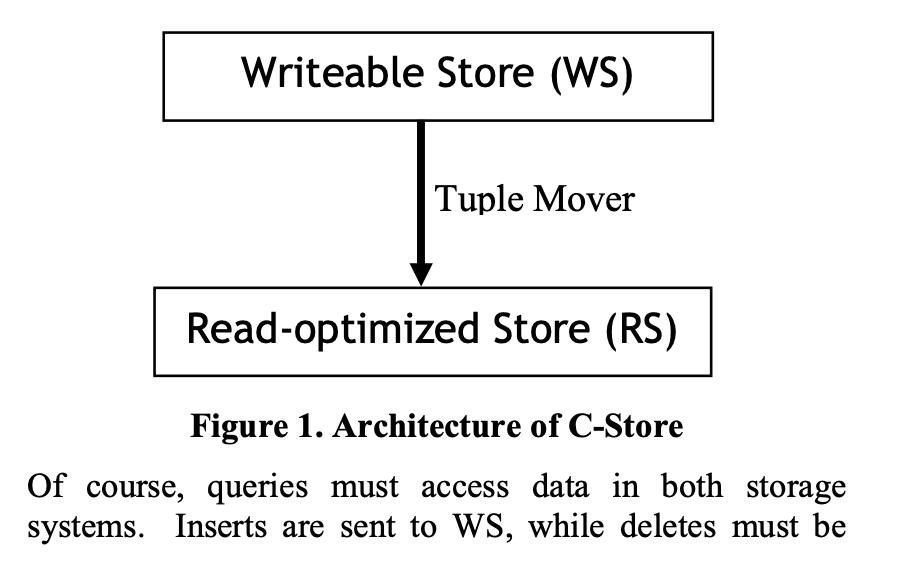
系统分为两层:
- WS:Writeable store,作用是提供高性能的 inserts和 updates;
- RS: Read-optimized Store,作用是提供针对读优化的高效查询,仅提供固定格式的insert方法;Tuple Mover 负责批量从WS搬运到RS;
Query 需要访问WS和RS,然后合并结果;inserts 只需要发送给WS,deletes必须记录到RS,后续 tuple mover 会做清理;updates 会被转换为delete + insert。
为了保证高速的搬运tuple,C-Store使用了 LSM-tree 的一个变体;
C-Store 支持snapshot isolation,每个query会选一个时间戳,系统保证能看到小于这个时间戳最大的committed的事务。
大多数商用优化器和执行器是基于行存的,RS 和 WS 都是列存的,所以需要做一个列存的优化器和执行器。
C-Store 的比较创新的 feature:
- 针对频繁 insert 和 update 优化的 WS + 针对 query 优化的 RS 的混合架构;
- 同一个table 表的内容根据不同但有重叠且按不同attribute进行排序的projections进行冗余存储,以便query能选择最优的projections进行查询;
- 使用不同的coding算法重度压缩列;
- 构建基于列存的优化器和执行器;
- 使用有重叠的projections 来提升性能和获取高可用;
- 使用snapshot isolation,避免2PC 和 query时加锁;
数据模型
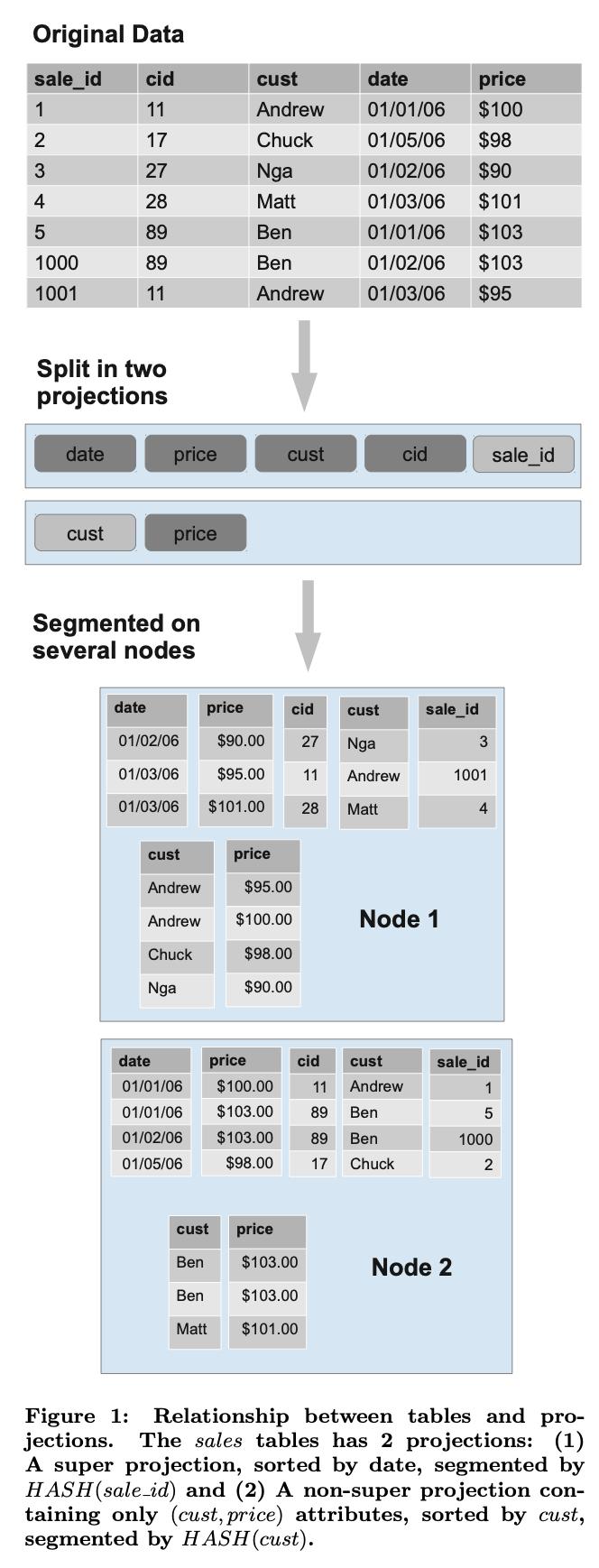
C-Store 支持标准的关系型数据模型,一个数据库包含多张表,每张表包含多个attribute(column)。数据在C-Store里面不是根据逻辑数据类型进行物理存储的。反之大多数rowstore是直接存储物理表的,然后添加各种各样的index来加速访问,C-Store 只实现了 projections。一个 projection 与一个逻辑表T绑定,包含该逻辑表中的一个或者多个attributes。一个projection也可以包含其他表的任意数量的attributes,只要有一个外键能链接绑定的表到包含这个attribute的表。
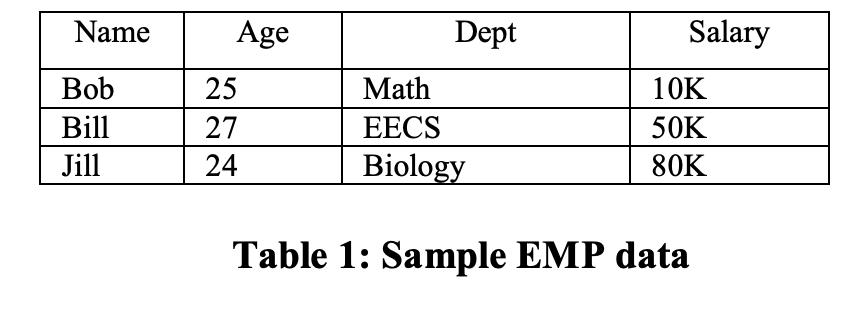
如上表EMP(name,age,salary,dept),和表DEPT(dname,floor)的关系,可能的projections的构成如下:

Projection中的tuples是按列存储的。因此,如果一个projection中有K个attributes,那么就会有K个数据结构,每个存储一个单独的column,每个按照相同的key来进行排序。排序的key可以是projection中的任意一个或者多个column。projection中的tuples按照key从左到右进行排序。我们通过在projection后面append排序key,用一个竖条隔开来表明排列顺序。如下图所示:

然后,每个projection 会按照水平分区为一个或多个segments,每个segment会分配一个SID来唯一标示(SID > 0)。C-Store只支持基于排序key的range 分区。
在查询时,C-Store必须能从一个或者多个projection的多个segment中重建完整的table rows,所以需要join不同的projections的segments,主要是通过storage keys 和 join indexes 来完成:
- Storage keys:每个segment会使用storage key(SK)来组追每个 column的每条数据。依照对应的storage key 同一个segment中不同columns的数据可以归属到同一个逻辑row上。
- Join indexes:为了从不同的projections中重构一个table中所有的records,C-Store使用join indexes来完成。
假如T1 和T2 是两个能cover table T的projections,从T1中M个segments 到T2中的N个segments逻辑上是M张表的一个集合,
(s: SID in T2, k: Storage Key in Segment s)
一个T1中给定segment的tuple对应的Join index 中的一个entry包含T2 中对应tuple的segment ID和storage key。为了从T1/.../Tk 的 segments中重建T的数据,必须有可能按照某个排列顺序O* 通过一组 join indices 来找到mapping了T表中的每个attribute的路径。
例如要通过EMP1/2/3来重建EMP表的话,至少需要两组join indexes。如果我们选择age作为公共的排列顺序,我们需要按照EMP1的顺序构建两个indexes来分别map EMP2和EMP3;或者创建一个join index来map EMP2和EMP3,一个来map EMP3和EMP1。EMP3 map EMP1 的例子如下图所示:
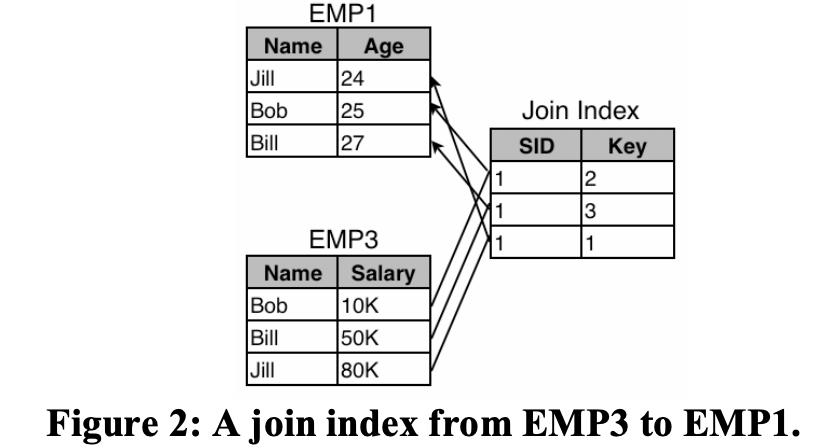
实践中我们更希望将一个column存储在多个projections中,这样能让我们维护更少的join indexes。因为在update场景维护join indexes 会非常昂贵。
在C-Store系统中,projections的segments和他们相连的join indexes的segment必须位于不同的node上,C-Store的administrator可以选择性的指定数据库表必须是k-safe的。指定后,任意K个节点失效时仍然允许所有表能成功重建出来。
Apache ORC
hive架构
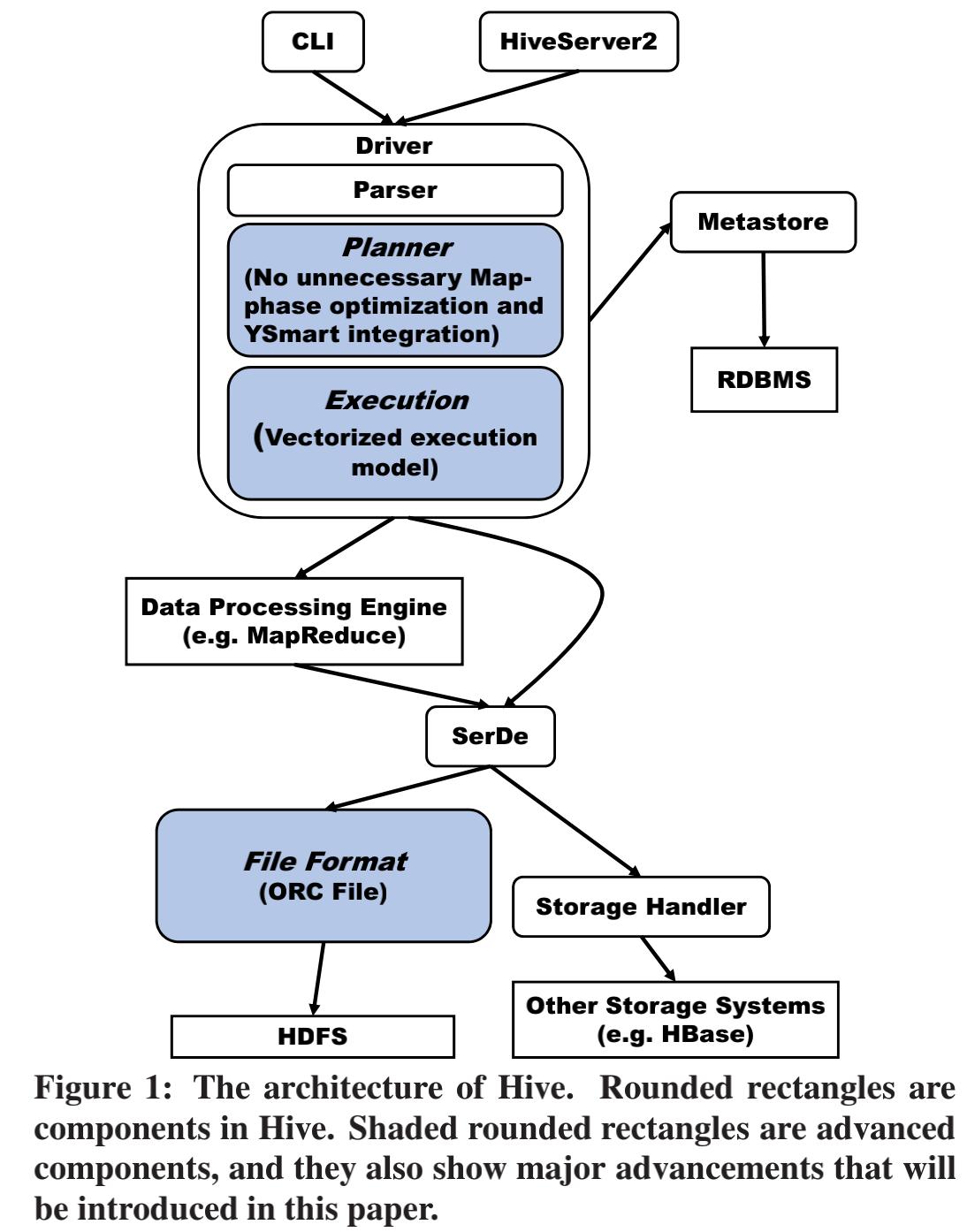
提供两种接口 CLI + HiveServer2;
执行语句的过程:
driver首先parse 语句,生成AST tree,planner选择一个特定的查询计划实现来分析各种类型的语句;在分析的过程中,Driver需要向MetaStore检索需要的元数据,元数据存储在PGSQL里面;
hive 翻译queries 为下层数据执行引擎可执行的任务,当前是hadoop 的 MapReduce. 对于一个查询来讲,query planner 遍历 AST tree 组装 operator tree 来表达一个query的数据操作;
在operator tree 生成以后,the query planner 应用一组优化到 operator tree,然后,整个operator tree 将被传给 task compiler,它将把 operator tree 转换为被可执行任务代替的多个步骤。
如MapReduce task compiler生成DAG map of task,在query planning的最后,会在生成的task上进行另外一个阶段的优化。在查询计划生成map reduce 任务之后,Driver将submit 任务到MapReduce engine。
然后是执行这些task,task将根据特定的文件格式对数据进行读写,对于特点的文件格式,会提供一个序列化-反序列化的库来序列化-反序列化数据。MapReduce任务完成后,Driver将获取的结果返回给用户。
除了将数据直接存储在HDFS之外,还能存储到其他系统上,如HBASE。但是需要提供对应的storage handler。
在hive中,存储效率主要决定于SerDes和文件格式。hive本来使用hadoop提供的两种简单的文件格式,textfile和sequencefile。textfile是无格式的文本数据,sequencefile是一个由二进制key/value对组成的平坦文件。
因为这两种格式的文件是对数据类型无感知的,所以需要SerDes来序列化每行数据然后在写入到HDFS,在读取时,需要根据他们的原本的schema来反序列化数据。因为是采用row-by-row的存储方式,所以很难进行密集压缩;
在hive 0.4中,Record Columnar File(RCFile)被引进。因为RCFile是列存文件格式,所以在存储效率上获得了很大的提升。然而,RCFile仍然是数据类型无感知的,还是需要有对应的SerDe来同一时间序列化一个单行数据。
这种结构下,数据类型有关的特定的压缩算法不能被有效使用。因此,Hive的存储效率上首要关键的缺陷是数据类型无感知的文件格式,及单行单次的序列化机制阻止了数据被有效的压缩。
尽管RCFile是列存文件格式,但是SerDe不能分解一个复杂的数据类型,因此,当一个query需要访问一个复杂类型的field时,所有的该类型的fields都要被读取,这个带来了数据读取低效的问题。
再加上RCFile主要是为了sequential data scan设计的。它没有任何索引,也不能充分利用query提供的语义信息跳过不需要的数据。因此,该存储格式第二个主要的缺陷是数据读取效率被index和复杂数据类型不能分解的列两个问题限制了。
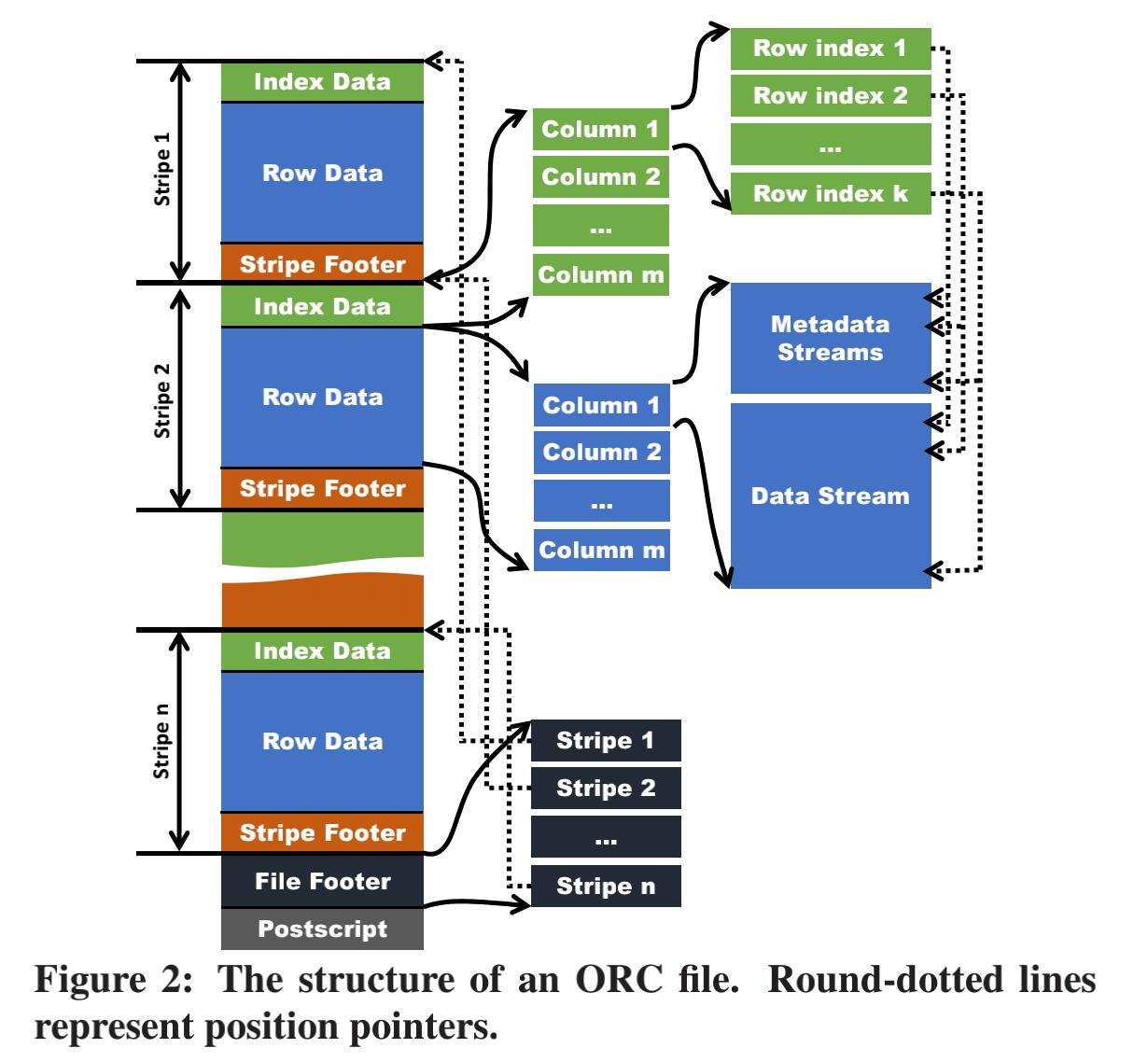
The Table Placement Method
一个table存储在ORC File时,首先会水平分区到多个stripe;在一个stripe中数据是按照列存的方式存储column;一个stripe的所有column存储在同一个文件中,一个stripe典型大小为256MB。
每个stripe中包含三部分内容:
- Stripe footer;
message StripeFooter {
// the location of each stream
repeated Stream streams = 1;
// the encoding of each column
repeated ColumnEncoding columns = 2;
}
-
Row data;
-
Column;采用多个stream进行存储,stream分为两类:
- Metadata streams;有些类型包含一个,有些类型包含多个;如 int 型的column只需要一个PRESENT stream,用来存储表示列值是否为NON-NULL的bitmap;如二进制流的column,则需要两个metadata streams,除PRESENT外,多出一个LENGTH stream 用来存储每个value的长度;
- Data stream;用来存储column value;
-
-
Index data;
-
ROW_INDEX stream;每个原始column一个;
-
多个 RowIndexEntry;每个row group(default 10000 行 rows)对应一个entry;
- Row group在meta/data stream中的起始位置和该row group 的统计信息;
-
-
message RowIndexEntry {
repeated uint64 positions = 1 [packed=true];
optional ColumnStatistics statistics = 2;
}
message RowIndex {
repeated RowIndexEntry entry = 1;
}
从以上table placement 方式可以看出,ORC File针对RC File有三点提升:
- 提供了更大的stripe 缺省大小,大小为256M;RC File为4M;这样可以更好的利用磁盘顺序读的高带宽,而且能读更少不需要的数据;
- 能够做复杂数据结构的解析,这样就不用读取那么多不必要的数据;解析方式为将一个复杂数据类型的column分解为多个子column;解析后形成了一个树形结构,非叶子结点作为metadata存储在metadata stream 中,叶子结点作为data存储在data stream中,解析方式如下图所示;

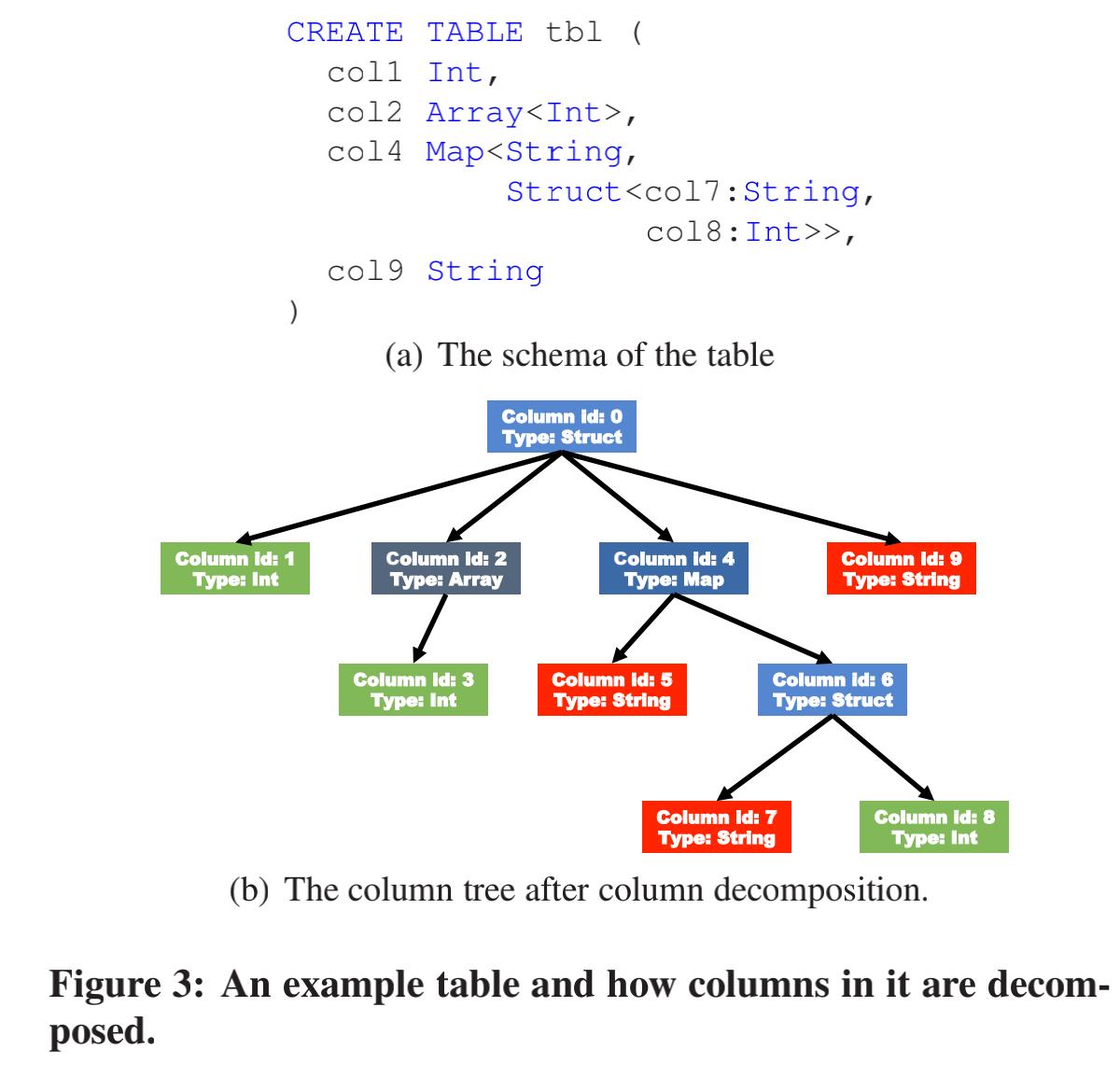
- 用户可以选择stripe边界和HDFS block 边界是否对齐;如果不对齐,写者将会填充数据在HDFS block尾部凑满一个block,带来写放大;
Indexes
-
数据统计;常见的统计有value个数/最小值/最大值/和/长度。对于复杂数据结构来说,子column也要记录数据统计;ORC File有三层统计:
- 文件层统计:经常被用于查询优化和相应简单的aggregation 查询;
- stripe层统计:针对每个column;经常被用于分析哪些stripe会被用于query;不需要的stripe不会从HDFS读出;
- index group层统计(stripe内部的细粒度统计):一个column的数据会被逻辑拆分为多个固定数据条数的index group(默认为10000条),利用每个index group的数据统计,query执行引擎可以下推适当的谓词到一个ORC File中,ORC reader也不用读取不需要的index group;index group越小,统计越细,但是数据统计的大小就越大,这儿需要做tradeoff。
-
Position Pointers;读一个ORC file 时,需要知道两种positions来提升数据读取操作的性能:
- 因为stripe 里的 column 有多个逻辑index group,所以读者需要知道每个index group 在metadata stream 和 data stream 中的起始位置;
- 一个ORC file 包含多个stripe,一个ORC file 里的多个 HDFS block 也包含多个stripe,需要高效的获取到一个 stripe 的起始位置,这个pointer 存储在 ORC file的 file footer中;
Compression
ORC File 采用两层压缩算法:
stream 层;一个stream 会根据特定的stream 中的数据类型做特定算法的压缩;一个column 存储在一个或者多个 stream中;我们可以将stream 划分为四种基本type,每种type 制定特定的 encoding 算法。四种type如下:
- byte stream;存储基础的字节,不能encoding;
- Run Length Byte Stream;存储字节流,只存储重复的字节和出现次数;
- Integer Stream;存储 int 型 value;可以使用run length encoding 和 delta encoding;
- Bit Field Stream;存储 bool 型 value;
由于kudu和parquet在其他分享中做过分享,此处就不再赘述。通过对典型列存系统的分析,我们可以看到一般系统会对表数据进行切片,C-Store的segment,ORC的stripe,kudu的tablet等等,然后会进一步拆为一个column的粒度,C-Store的projection(可以是多个column),ORC的stream,kudu的cfile等等;然后进一步拆分为可寻址和可索引的更小的单位,ORC的row group,kudu的page等等,通常在这个粒度上构建索引,帮助高效的查询,做到尽量少读取不必要的数据。并且在每一层会构建统计信息,帮助做更优的执行计划和谓词下推等性能优化。大家可能发现了列存通常没有为更新做太多优化,因为场景一般是后台批量bulk loading,所以在HTAP场景会出现delta store这个角色来帮助进行高效更新。进几年比较流行的列存系统基本都是在离线场景下使用,但是随着业务对数据的实时性要求的不断提高,学术界进来大量出现了关于HTAP系统的研究,接下来的系统演进让我们拭目以待。
【1】PAX:https://research.cs.wisc.edu/multifacet/papers/vldb01_pax.pdf
【2】spanner:https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/46103.pdf
【3】https://w6113.github.io/files/papers/cstore-vldb05.pdf
【4】C-Store: A Column-oriented DBMS论文分析
【5】http://cidrdb.org/cidr2005/papers/P19.pdf
【6】https://clickhouse.tech/docs/en/development/architecture/
【7】https://vldb.org/pvldb/vol5/p1790_andrewlamb_vldb2012.pdf
【8】https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/40379.pdf
【9】http://web.eecs.umich.edu/~mosharaf/Readings/Hive.pdf
【10】https://kudu.apache.org/kudu.pdf
【12】http://www.inf.ufpr.br/eduardo/ensino/ci763/papers/DSM-columns.pdf