




目前,字节跳动数据质量平台对于批处理数据的质量管理能力已经十分丰富,提供了包括表行数、空值、异常值、重复值、异常指标等多种模板的数据质量监控能力,也提供了基于spark的自定义监控能力。另外,该平台还提供了数据对比和数据探查功能,为用户在数据开发阶段及时发现数据质量问题提供了便利的手段。本文分上下两次连载,作者系字节跳动数据平台-开发套件团队-高级研发工程师 于啸雨。
长期以来,数据质量平台的各项能力都只支持batch数据源(主要是Hive),没有流式数据源(如kafka)的质量监控能力。但其实流式数据与batch数据一样,也有着数据量、空值、异常值、异常指标等类型的数据质量监控需求,另外因流式数据的特殊性,还存在着数据延迟、短时间内的指标波动等特有的监控需求。\
此前部分数据质量平台用户为了监控流式数据质量,选择将流式数据dump到hive,再对hive数据进行监控。但这种方式的实时性较差,若有数据质量问题,只能在T+1后报出。且对于很多流式任务的“中间”数据,原本不需要落地,为了监控而落到hive,存在着大量的资源浪费。
为更好地满足流式数据用户的数据质量监控需求,同时填补数据质量平台在流式数据源方面的空白,字节跳动数据质量平台团队于2020年下半年,以Kafka数据写入延迟监控为切入点,陆续调研、开发、上线了一系列基于Flink StreamSQL的流式数据质量监控。
本文为系列文章的上篇,重点介绍字节跳动数据质量平台技术调研及选型的思考。
产品调研
在2020年下半年,我们决定支持流式数据的质量监控,随即开展了业内的技术调研。主要基于公开的分享或文档资料,调研了Apache Griffin,以及其他四家厂商对应的产品。
在2020年下半年,我们决定支持流式数据的质量监控,随即开展了业内的技术调研。主要基于公开的分享或文档资料,调研了Apache Griffin,以及其他四家厂商对应的产品。调研分析了相关友商的计算引擎、主要技术实现、产品形态、数据落地形式等,调研的汇总结果如下表所示:
| Apache Griffin | M厂 | W厂 | D厂 | |
|---|---|---|---|---|
| 计算引擎 | Spark | Flink | Spark | Spark + deequ + delta lake |
| 主要技术实现 | 将流转为batch,基于batch数据做计算。 | Flink中两个窗口聚合。 | Spark收集审计数据,发到审计中心。 | 在spark streaming程序中,由deequ分析器对datafram做计算。 |
| 产品形态 | 配置化、平台化 | 平台化 | - | 提供SDK,需用户写代码,编写分析器。 |
调研主要结论
1、各产品的计算引擎均使用Spark或Flink,二者都能解决需求,在稳定性和性能上也没有显著的差异。实际上各产品在计算引擎选取方面,主要考虑的是已方的技术栈、技术积累、计算引擎与已方技术架构的融合度等。如D厂的主要业务是做Spark的商业化产品,引擎自然地使用Spark;M厂的相应产品产生的背景也是基于Flink在该厂的应用和推广。
2、除Apache Griffin由于采用了先流转批、再复用批处理能力的策略,指标产出延迟为分钟级外,其它指标产出延迟均为秒级。需注意的是指标产出延迟并非报警的延迟。实际报警的延迟时间还受所采用的报警引擎的触发方式、轮询执行周期等影响。
3、各产品均未由计算引擎直接触发报警,而是由计算引擎计算出对应的数据质量指标数据,存到下游sink后,再基于sink中的数据,检测及触发报警。同时还可基于sink中的数据提供灵活的报表、可视化服务。这其实是业内较为普遍的作法,即计算引擎只负责计算,后续监控和报警功能由专门的监控报警引擎负责。
调研选型结果
选型Flink SQL
基于上述友商调研,考虑到当前字节跳动在流计算方面主要的计算引擎为Flink,在kafka/各类MQ - Flink的数据流实时计算方面已经有了很多的技术积累,使用Flink的接入成本相对更低,且能获得更充足的技术支持,我们决定选择Flink作为流式数据质量监控的计算引擎。确定使用Flink为计算引擎后,在实际实现时,仍有两个选择:可以使用Flink SQL API,也可以使用更为底层的Flink DataStream API。
我们最终决定选择使用Flink SQL API,原因如下:
从性能上看,使用SQL API不会比使用DataStream API性能差。Flink SQL最终也会编译成Java代码执行,二者并无本质差别。
从功能上看,当前Flink SQL的语法已经很丰富,支持kafka、RocketMQ等常用流式数据源和MySQL、TSDB等sink。另外字节跳动Flink团队也会根据公司内用户的需求,开发一些定制化的功能,如支持kafka header数据字段等。Flink SQL能够满足大部分的流式数据质量监控的功能需求。
从使用友好程度上看,在进行规则配置转化时,SQL API相对DataStream API更友好,更易于实现,更便于调试。在增加新的流式监控类型和新feature时,开发人员主要需考虑如何拼SQL计算对应的监控指标,且可直接使用Dataleap数据开发平台的Flink SQL作业进行调试。另外,直接使用SQL API,更容易支持用户自定义SQL指标的监控规则。
流式数据质量监控的技术架构
以Kafka数据源为例,流式数据质量监控的技术架构及流程图如下所示:
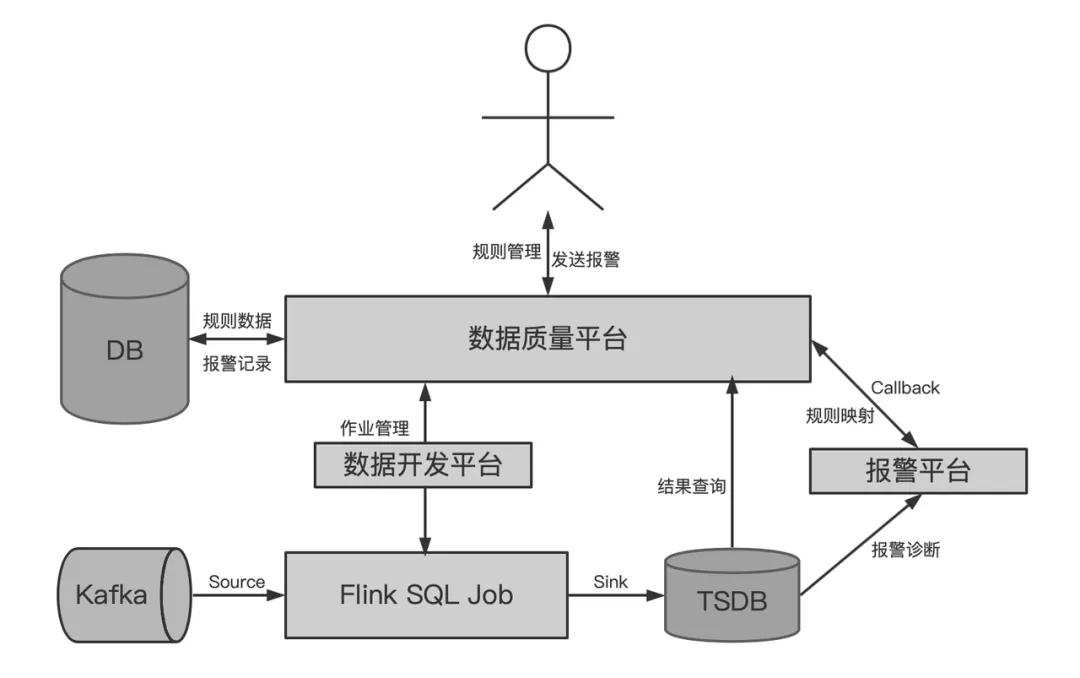
每个流式监控规则从创建到执行和触发报警的主要流程如下:
1、用户在数据质量平台上创建监控规则。
2、数据质量平台收到规则创建请求后,会做以下三件事:
- 将规则元数据保存到DB。
- 根据规则的报警指标定义,在数据开发平台上创建对应的Flink SQL任务。
- 将报警条件映射为报警平台的触发规则。
3、Flink SQL作业将消费Kafka的数据,计算监控指标,并写到TSDB中。
4、报警平台将基于TSDB中的时序数据,周期性地检测是否触发报警。若触发报警,将回调数据质量平台。
5、数据质量平台根据报警平台的回调请求,处理后续报警发送逻辑。
Flink SQL作业的执行逻辑
用户在数据质量平台上配置kafka数据的监控规则时,有可能会为一个topic配置多个监控规则,为节约资源,便于统一管理,数据质量平台将相同topic的所有监控规则放在同一个Flink SQL作业中计算。Flink SQL作业的构成如下图所示。
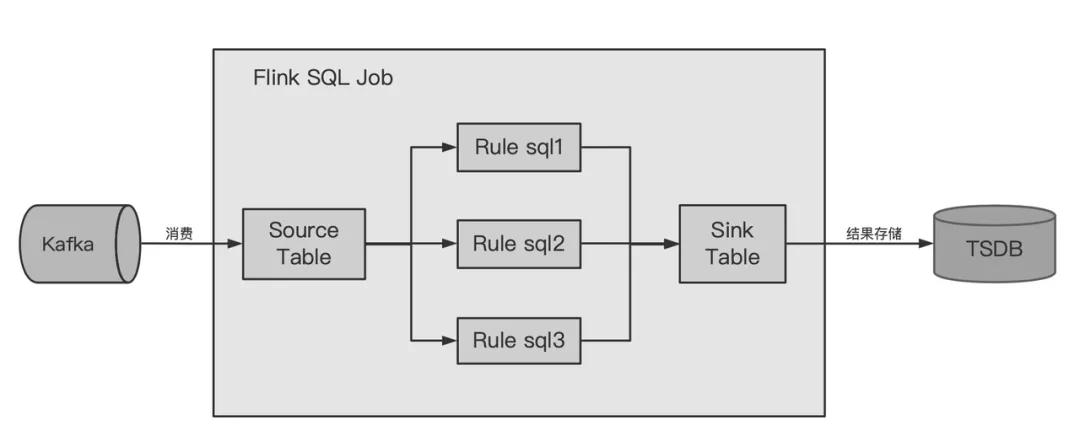
从逻辑上,该Flink SQL作业分为source、rule、sink三个阶段:
source阶段: 本阶段的主要目标是根据Kafka topic等配置,创建Kafka Source Table,Flink底层执行逻辑是消费Kafka的数据,并根据Source Table的schema进行解析、提取相应的字段,供后续Rule阶段使用。根据需求,创建的Kafka Source Table支持从消息header中取字段,支持json和pb格式,也支持按百分比取样消费数据(针对数据量较大的topic的采样监控策略)。
rule阶段: 本阶段执行所有监控规则的实际计算逻辑,每个监控规则对应一个或多个rule sql,由各个rule sql计算相应的监控指标,insert到Sink Table表中。
sink阶段: 本阶段的主要目的是将计算结果存到TSDB中。
上述三个阶段,在Flink SQL作业中,分别用创建Kafka Source Table的DDL,计算指标结果的Rule Sqls、创建TSDB Sink Table的DDL三类SQL来描述。以下的SQL示例,即展示了某个topic配置了3个监控规则,其Flink作业所包含的SQL逻辑:
-- SOURCE TABLE DDL:定义了Kafka数据源及消费策略
create table data_source (
app_id BIGINT,
name VARCHAR,
_meta_timestamp BIGINT,
time_formatted VARCHAR,
price DOUBLE,
type VARCHAR
) with (
'format.type' = 'json',
'update-mode' = 'append',
'metadata.fields.mapping' = 'timestamp=_meta_timestamp',
'connector.version' = '0.10',
'format.derive-schema' = 'true',
'connector.topic' = 'kafka_topic',
'connector.group.id' = 'kafka_group_id',
'connector.startup-mode' = 'latest-offset',
'connector.type' = 'kafka',
'format.skip-dirty' = 'true',
...
);`
-- SINK TABLE DDL:定义了****TSDB** **Sink**
create table data_sink(
type varchar,
name varchar,
val double,
tags varchar
) with (
'connector.type' = 'tsdb',
'connector.tsdb.table' = 'tsdb_table',
...
);
-- RULE SQL 1:计算字段app_id的空值率
INSERT INTO data_sink
SELECT
'COUNTER' AS type,
'r0' AS name,
CAST(1.0 AS DOUBLE) AS val,
CONCAT('{', IF(`app_id` is null, 'app_id=nit', 'app_id=normal') , ',' , IF(`name` is null, 'name=nit', 'name=normal') ,'}') AS tags
FROM data_source;
-- RULE SQL 2:以time_formatted为事件时间,计算数据写入延迟
INSERT INTO data_sink
SELECT
'TIMER' AS type,
'r1' AS name,
CAST((_meta_timestamp - UNIX_TIMESTAMP(time_formatted, 'yyyy-MM-dd HH:mm:ss') * 1000) AS DOUBLE) AS val,
'{}' AS tags
FROM data_source;
-- RULE SQL 3:计算指标app_id的取值范围
INSERT INTO data_sink
SELECT
'TIMER' AS type,
'r2.app_id' AS name,
CAST(app_id AS DOUBLE) AS val,
'{}' AS tags
FROM data_source
WHERE app_id IS NOT NULL;
Flink SQL作业的管理
流式监控的Flink SQL作业被托管到Dataleap数据开发平台上。数据开发平台对流式作业有较完善的运维和管理机制。因此,在作业管理方面,数据质量平台仅需要处理以下几点:
1、规则的新建、删除、关闭等操作时,向数据开发平台提交Flink SQL作业的创建或更新
2、借助数据开发平台的能力,实现作业的启停、重启、监控等运维操作。
3、另外,用户可在数据质量平台上对监控作业的资源进行调整(如下图所示),对资源配置的调整会实时更新到对应的Flink SQL作业中。
报警的诊断和管理
在创建规则时,数据质量平台会将报警条件映射为报警平台的报警规则。报警平台将周期性地根据报警规则查询TSDB,诊断报警。若满足报警条件,将回调数据质量平台。由数据质量平台负责后续的报警内容生成和发送,并记录报警时间和结果。
采用这种方式,流式监控的报警卡片内容、报警发送方式、报警级别、报警接收人等配置均由数据质量平台维护。这部分与已有的batch监控基本相同,直接复用了已有能力。
另外,用户在ACK(报警屏蔽)时,数据质量平台将记录ACK信息,但不将ACK信息报给报警平台。在后续处理报警平台的回调时,会加一层过滤,不向用户发送已ACK(处于屏蔽状态)的报警,但仍保存报警信息,供用户查看屏蔽期间内的报警结果。
监控结果展示
监控的Flink SQL作业将计算结果sink到了TSDB,因此在用户查看历史监控指标结果时,数据质量平台可实时从TSDB拉取结果进行展示。
此外,数据质量平台也在页面上将TSDB的表名、metric名透传给用户,便于用户更灵活地查看监控结果,或将监控结果配置到自己的Grafana看板中。
流式监控现状
支持的监控类型
目前,在字节跳动,数据质量平台已上线支持了时间字段延迟、空值监控、字段监控和自定义指标监控四种监控类型。
1、时间字段延迟
时间字段延迟实际是指数据的生产延迟或者写入延迟,是指数据从产生到写入kafka的延迟情况。实际的计算方式是数据写入kafka的时间(从消息header中获取的kafka LogAppendTime)减去用户配置的代表事件时间的字段时间。如用户配置的字段时间是11:50:00,写入kafka的LogAppendTime是11:50:01,则认为写入延迟为1秒。
2、空值监控
空值监控用于检查用户指定字段的空值率,超过阈值即报警。其计算方式也很直接,直接计算特定时间段内,指定字段空值的数量/总的数据条数。
3、字段监控
字段监控的处理逻辑更为简单,直接将字段的值(30秒的聚合结果)写入TSDB。主要使用场景是用来监控字段的值是否在预期的范围内。
4、自定义指标监控
自定义指标监控是基于用户自定义的SQL计算结果进行的监控。用户可根据Flink SQL的语法,将需要监控的指标用SQL的形式表达出,然后对计算结果配置报警条件。
问题与挑战
基于Flink SQL的流式数据质量监控,目前面临的问题与挑战主要有:
1、使用FlInk SQL时,要求数据能够序列化成指定schema的流式表,因此其前提是数据的schema已知且符合预期。若用户需要对数据的schema进行监控,比如数据能否成功解析、或某些字段的类型是否正确,则很难用Flink SQL实现。
2、流式监控作业本身是一个Flink流式作业,因此其也存在着其它流式作业共有的问题。如计算资源如何合理分配、消费延迟等。若监控作业本身消费延迟,将会影响流式数据质量监控报警的时效性。目前我们对监控作业消费延迟、资源使用等指标配置了监控报警。在资源不足、消费延迟时仍需要人工干预处理。
除上述问题外,目前产品和技术上也存在着一些细节问题,这里不再赘述了。
从整体上看,该方案架构较为简洁,充分利用了Flink SQL以及一些其它基础组件和平台的能力,也复用了数据质量平台batch监控的一些能力,以较低的技术成本提供了较为丰富的流式数据监控功能。
附-参考资料
http://griffin.apache.org/docs/profiling.html
How to Monitor Data Stream Quality Using Spark Streaming and Delta Lake
本文中的技术方案和能力现在已经通过火山引擎大数据研发治理套件DataLeap面向企业开放。
火山引擎大数据研发治理套件DataLeap:一站式数据中台套件,帮助用户快速完成数据集成、开发、运维、治理、资产、安全等全套数据中台建设,帮助数据团队有效的降低工作成本和数据维护成本、挖掘数据价值、为企业决策提供数据支撑。