





随着实时计算的应用越来越广泛,同时实时数仓的概念逐渐深入人心,Flink 作为实时计算领域当之无愧的最优秀框架,其使用范围飞速扩张。对于一个优秀的大数据开发工程师来说,非常有必要熟练掌握 Flink 框架的使用和运维。
本文不会涉及对 Flink 框架的技术剖析,而是侧重于工程实践,力求实用。笔者会结合自己运维多个大型 Flink 任务的经验,对于『如何系统化地调优 Flink 任务、提升性能』给出一套完整的方法论。
解决问题的前提是发现问题。那么如何知道一个 Flink 任务是否存在性能问题呢?
Flink 作业性能不佳时一般有以下一些表现,可根据业务情况综合判断:
- 上游 Kafka Topic 出现堆积。正常运行的任务,其上游 Kafka Topic 的 Lag Size 通常为零。如果发现数据持续堆积,说明处理速度跟不上流入速度,可能存在性能问题。但这种情况在数据高峰期也可能发生,可根据业务对延迟的要求决定是否需要优化。
- QPS 曲线抖动。正常运行的任务,其 QPS 曲线一般平滑且稳定,有时也会随着输入 QPS 周期性波动。当发生性能问题时,往往会看到 QPS 曲线有明显抖动。有时 QPS 曲线并未抖动,但仍然出现堆积,同样说明性能不足。
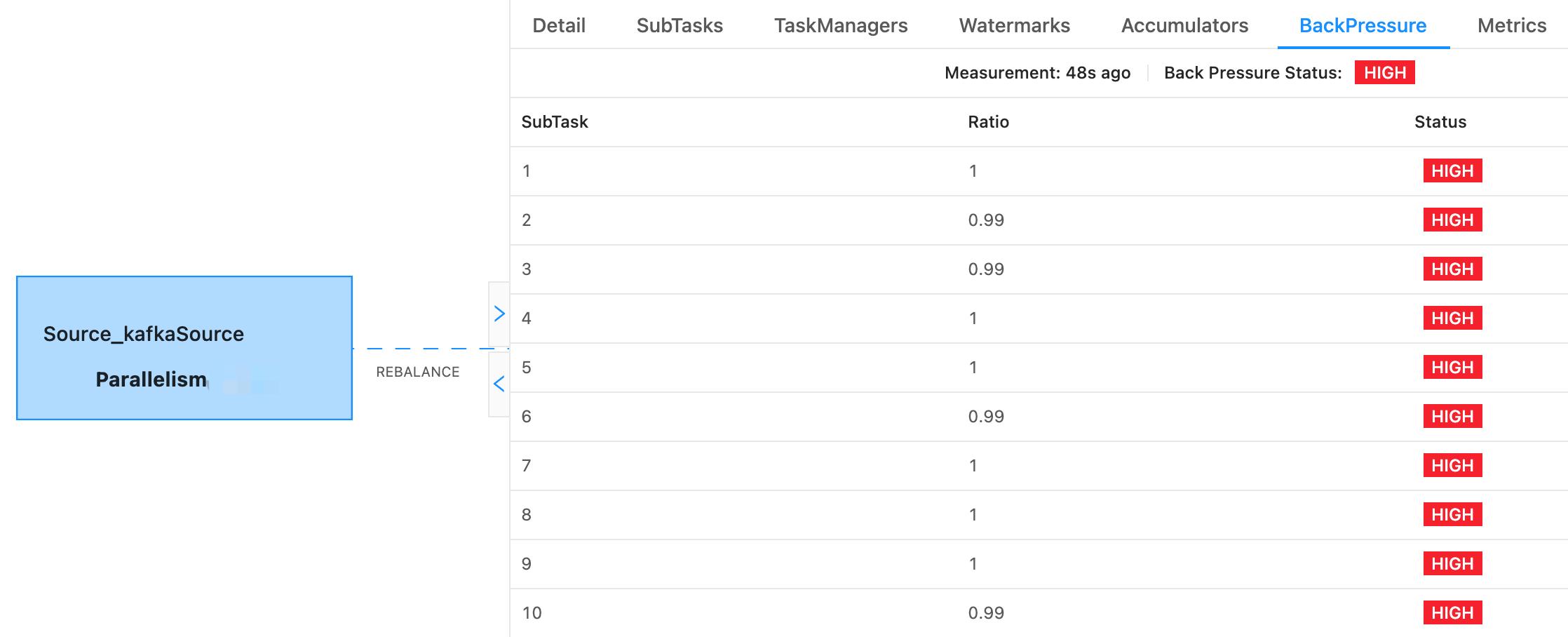
- 算子反压。如果任务性能不佳,几乎必定对应着某些算子上发生了反压。可以在 Flink UI 上查看每一个算子的反压情况。某个算子 A 出现反压,意味着这个算子的输出被阻塞,说明下游算子有性能问题,但并不一定是直接下游,因为反压是会连续向上游传导的。从上到下找到第一个没有反压的算子,通常就是性能瓶颈所在的算子。
- CPU 占用率高且伴随抖动。正常运行的任务,其 CPU 占用率应稳定在较低水平。当占用率过高时(例如 >75%),往往会出现性能问题,此时 CPU 占用率曲线也通常会出现抖动。
有时候不出现这些现象也不代表任务的性能没问题,因为任务平稳运行可能是靠堆资源堆出来的。本着追求极致的精神,我们应该力求把资源利用率优化到最好。当把计算资源压缩到尽可能低时,此时出现的性能问题才是我们调优和解决的对象。
那么到底分配多少资源才算合适呢?这里提供一些 QPS per CPU 的经验数据供参考:
- 有状态处理:3000 QPS/CPU
- 无状态处理:10000 QPS/CPU
有状态处理是指多条数据之间需要维护上下文信息,例如涉及 GROUP BY 语义时,需要使用 Flink 的窗口函数,而窗口中就维护了状态信息。这类处理通常对 CPU 和内存都会造成压力,且窗口越长压力越大。
注意:这里给出的仅仅是粗略的经验值,由于业务情况不同,例如数据是否压缩、序列化格式、是否需要复杂计算等,均会造成一定偏差。另外,CPU 本身的优劣也会造成一定影响。
网上有大量的 Flink 性能调优案例分析,但实际上我们每次遇到性能问题时往往还是无从下手,这是因为没有从案例中总结出系统化的方法论。下面就来解决这个方法论的问题。
笔者在日常实践中发现,Flink 的性能问题几乎全都可以归结到以下 3 种原因。最妙的是,这 3 种原因是正交的,定位性能问题时不会因为各个因素互相耦合而把脑子搞乱:
经过上一步『问题发现』环节,假设我们已经通过反压找到了性能瓶颈所在的具体算子。
1. 算子延迟高
算子延迟高的原因多种多样,例如业务逻辑的复杂度太高、有频繁的磁盘或网络 IO、内存不足频繁 GC。这种情况下增大并行度可能有一定效果,但无法解决根本问题。
这种情况可以类比为:流水线上每个工人都很生疏,此时扩增人手也许能带来一定的速度提升,但也会带来很大的管理开销,根本的解决办法是提高每个工人的熟练度。
2. 并行度不足
有时候即使每个算子上的业务逻辑和算法都已经优化到无懈可击,但由于并行度太低,例如 10 个并行度消费 1000 个 partition,还是会造成作业整体性能不足。
这种情况可以类比为:流水线上每个工人都很熟练,但人手不够,因此造成生产速度不足,此时应该增加人手,扩大生产线。
3. 数据倾斜
某个算子被分配了过多的数据消费不过来,而其他算子则有闲置的情况。由于作业中往往存在 shuffle 操作,那么此时发生堆积的算子就会成为整个作业的瓶颈。即使不存在 shuffle 操作,数据倾斜的坏处依然存在,一个显著的问题是会造成堆积算子与其余算子之间出现更大的数据乱序。这时无论是增大并行度还是调优算子的延迟都很难奏效,只能去消除数据倾斜。
这种情况可以类比为:流水线上某些工人被分配了过多的工作量,而其他工人虽然有空闲但却不能到别人的流水线上去帮忙,这种情况只能从工作量的分配上进行改善。
为了方便理解,列出这 3 种性能原因的类比表:
| Flink 任务 | 类比为:工厂生产线 |
|---|---|
| 算子延迟高 | 工人不够熟练 |
| 并行度不足 | 每个工人都很熟练,但人手太少 |
| 数据倾斜 | 每个工人都很熟练,人手也足够,但工作量分配不均匀,工作最多的人拖满了整体进度 |
从以上的分析可以看出:
- 这 3 类原因是正交的,可以独立、互不影响地出现在性能问题中,这意味着『解决一类问题不影响其他问题继续成为性能瓶颈』。
- 这 3 类原因是互补的,并且不存在除了这 3 类原因之外的其他原因(后者不能证明,但目前也没有想到反例)。
上述 3 类原因虽然全面,但过于粗糙,每种原因背后都存在多重多样的情况,我们优化性能问题的时候需要结合具体情况来分析决策。
下面简要地给出这 3 类原因的排查方向和优化思路:
1. 算子延迟高
算子延迟高的问题可以通过观察算子延迟曲线进行判定,通常在 Flink 的 metrics 指标组中可以找到。
对于一个良好的实时任务,其各个算子延迟都应该稳定在 10ms 以内,因为磁盘 IO 或同机房内网络 IO 也只是达到这个量级,纯粹的计算更没有理由比这些操作更慢。
具体来说,算子延迟高的常见原因有:
- 业务逻辑复杂,耗 CPU 较多(一般是压缩/解压、序列化/反序列化等造成的);
- 内存不足,导致 JVM 频繁发生 GC;
- 有较多/较慢的磁盘或网络 IO。
针对几类原因的分析思路如下:
-
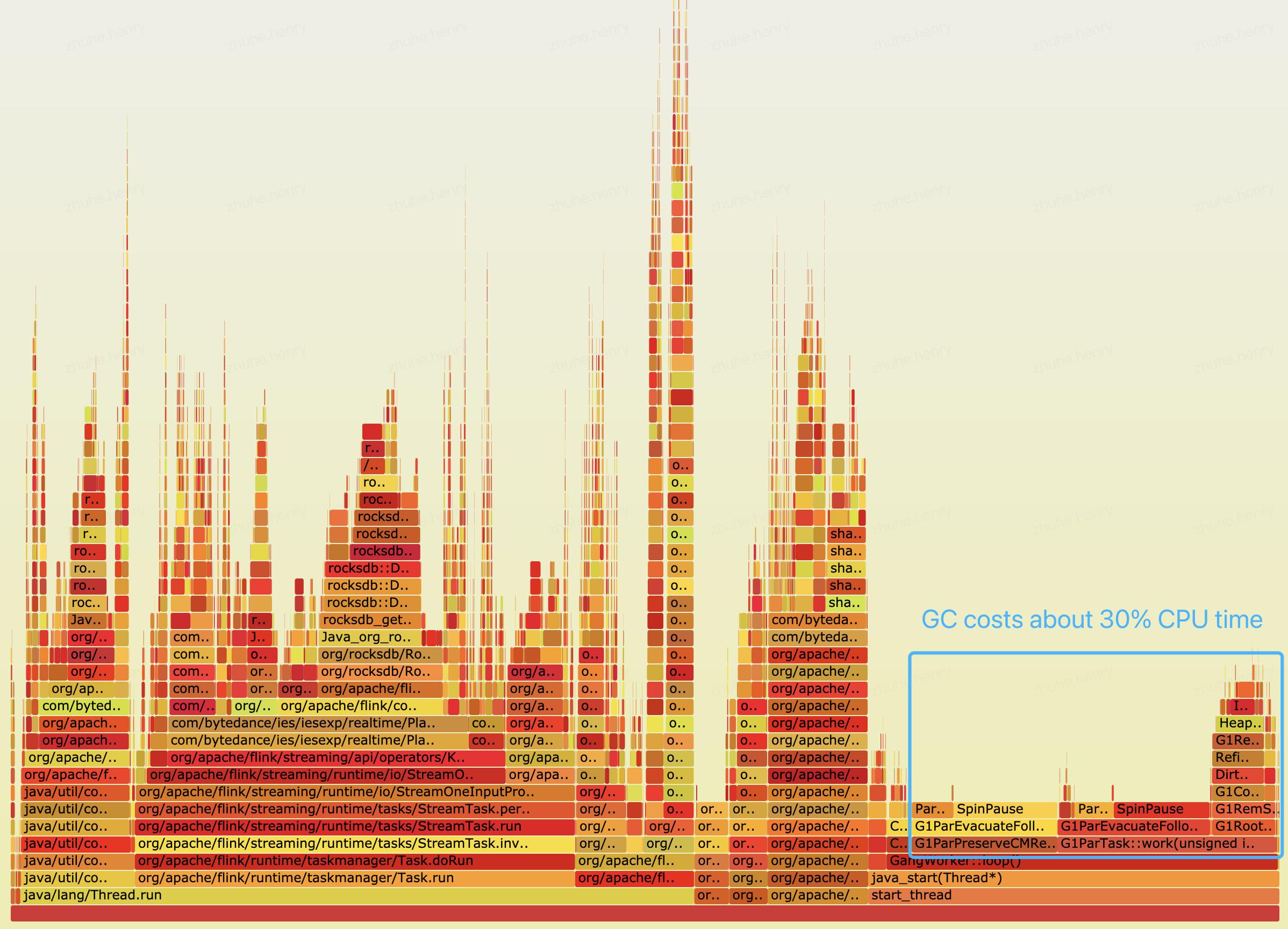
如果怀疑算子的业务逻辑复杂,耗 CPU 较多,那么可以通过 CPU 火焰图定位具体问题。CPU 火焰图可以分析一个进程一段时间内的 CPU 耗时分配在各个函数调用栈上的比例,由此可以定位到业务逻辑中最耗 CPU 的部分。
-
JVM GC 问题导致算子延迟高是非常常见的。Flink 任务的 metrics group 中一般都配有 GC 监控。理想的情况下,JobManager 和 TaskManager 应当从不发生 Full GC,如果频繁发生就说明内存管理有问题。
排除掉 Full GC 之后,算子的 GC 耗时就取决于 Young GC 了,后者的平均耗时一般应该在 100ms 以内,对于不涉及大内存操作(10GB 量级)的任务应该在 10ms 以内。GC 耗时高通常预示着内存不足,但未必是因为分配的内存不够,也可能是 GC 策略不合适导致内存使用效率低,或存在内存泄露等,需要进一步定位。
-
如果怀疑延迟是由于磁盘 IO 造成的,那么可以找到某些 Task Manager 查看其单机磁盘监控,是否有磁盘 IO 次数过高,或者数据 size 过大。
如果怀疑延迟是由于网络 IO 造成的,那么可以查看对应 API 提供方的延迟数据。例如任务访问了 Redis、HBase 等外部资源,那么这些基础设施本身都会有相应的延迟监控,可以从中判定延迟的来源。
2. 并行度不足
并行度不足的问题比较容易发现,一般可以观察任务总体的 CPU 占用,以及各个 Task Manager/Container 的 CPU 占用。如果 CPU 占用率一直接近 100%,甚至处于超发状态,且排除了算子延迟高的问题,那么通常就是并行度不足造成的。
并行度不足的解决方法很简单,就是增加资源。一般是增加 Task Manager 的个数,从而扩大并行度。
3. 数据倾斜
数据倾斜的问题一般出现在发生 shuffle 操作的任务中,典型的就是 GROUP BY 语义。
可以通过观察算子反压现象加以定位,如果在某个算子的所有实例中只有部分实例出现反压现象,那么这些实例很可能遇到了数据倾斜。但也有可能是这些实例对应的节点负载过高,被动造成了性能问题,这种情况只需要简单排查一下这个节点的资源监控即可。
也可以在 Flink UI 中单独查看每一个 SubTask 的 Records Sent 和 Bytes Sent 值,观察是否有部分 SubTask 吞吐量明显更大的情况。
如果有分 Task Manager 的 CPU 监控的话,也可以作为参考,看是否存在个别 Task Manager 资源占用明显高于其他的情况,如果有则很可能这些 Task Manager 上发生了数据倾斜。
数据倾斜的治理思路大家并不陌生,大致跟离线数据倾斜相同,有以下几个解决方案:
- 观察倾斜的数据是否为脏数据,如果是,则在 shuffle 操作之前将倾斜的数据清洗掉;
- 将引起倾斜的 hot key 附加一个随机数,在 shuffle 之前将其打散,待处理完成之后再清洗恢复;
- 将引起倾斜的 hot key 单独起一个任务进行处理,待处理完成后再将所有结果合并起来。
以上优化思路看起来简单直接,但事实上,上述 3 大类原因中的每一种细分情况都需要大量的知识和经验来辅助判断,需要多从实践中总结和学习。
Flink 官方文档中推荐了一些最佳实践,但许多并不适用于大型 Flink 任务(并行度 > 1000),这里总结为『逆向』操作(即不符合官方推荐做法的意思)。
这个列表不宜直接遵守,其目的是,当你在运维大型 Flink 任务时,如果发现了无论如何也解决不了的性能/稳定性问题,可以参考一下,思考是否掉进了『最佳实践』的陷阱里。
1. 慎用 CheckPoint
Flink 的 CheckPoint 是一个非常有用的功能,可以在任务失败之后完全恢复到最近一次 CheckPoint 的状态,用于实现 end to end 的 exactly once 语义。
但在一些大型 Flink 任务中,有时候维护的 state 会非常重,导致每次 CheckPoint 都需要将百 GB 甚至 TB 量级的数据写入到磁盘中,任务性能被严重拖慢,且 CheckPoint 容易生成失败或超时。
需要知道的是,开启 CheckPoint 并不一定能达成端到端的 exactly once 语义,这取决于下游的接收方是不是幂等的。如果不是,当任务失败重启时,CheckPoint 反而会导致数据重复消费。对于某些业务,这并没有比数据丢失好到哪儿去。
所以,当你的 Flink 任务不 care 偶然且少量的数据丢失时,关闭 CheckPoint 不仅没有坏处,反而可以提升作业性能。
2. 慎用 EventTime
对于 Flink 的 Timing System,我们一般选择 ProcessingTime 或 EventTime 的其中一个。具体如何选择通常基于业务来判断,例如你需要按照用户下单的时间来处理数据,那么毫无疑问应当采用 EventTime 配合 Watermark。否则,出于性能考虑默认采用 ProcessingTime。
Flink 官方文档对 EventTime 做了浓墨重彩的介绍,但却没有强调一个重要的点,那就是 EventTime 对作业性能有着严重的损耗,尤其是对于存在 shuffle 操作的大型 Flink 任务。这是因为 EventTime 的乱序以及 Watermark 的传导和对齐机制会导致数据在 shuffle 操作两端出现严重的等待、滞后、进而拥堵。这种情况下,如果任务用到了窗口状态,那么内存占用会持续上涨,最终崩溃。
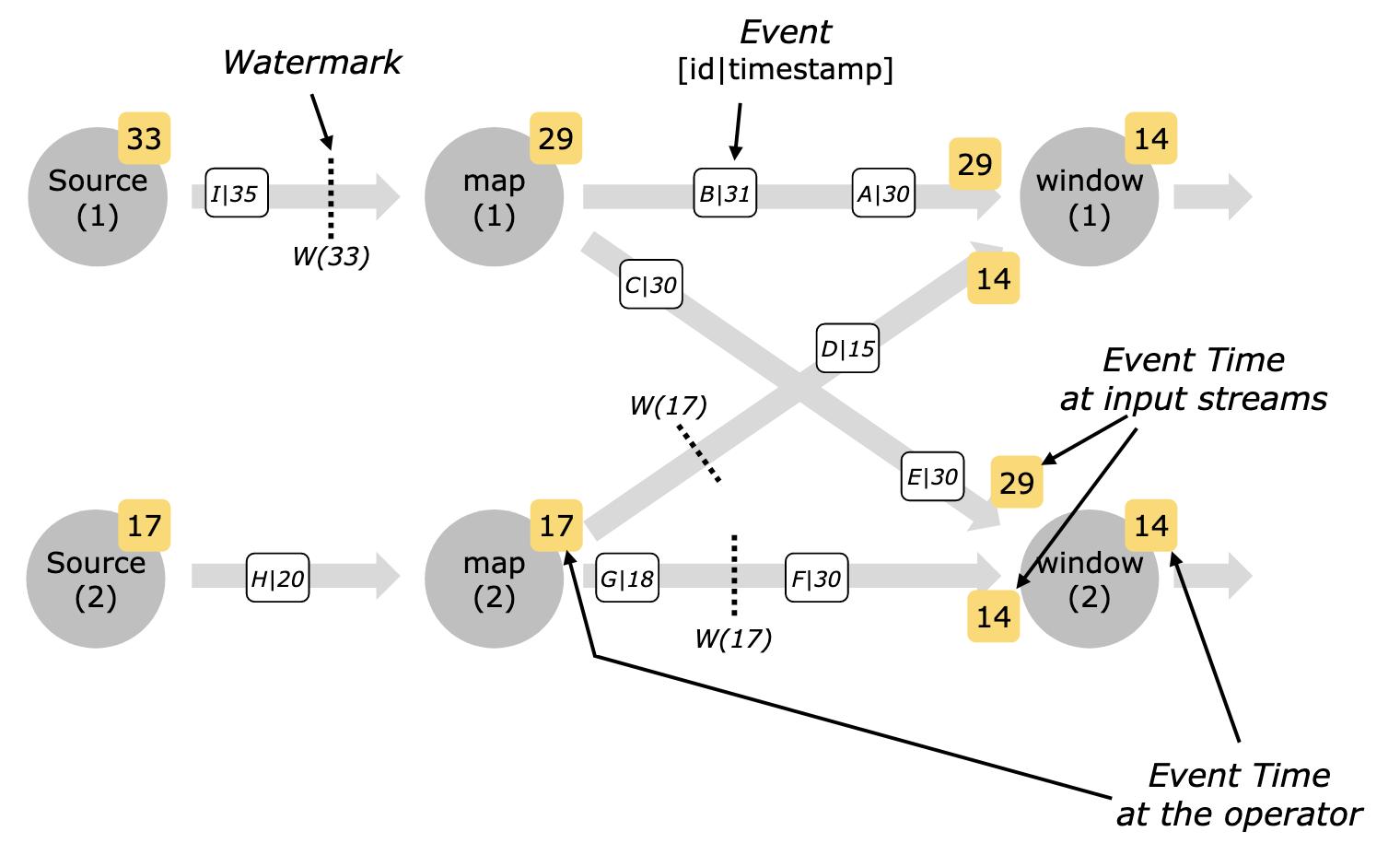
如果你已经遇到了这个问题,那么应该把 EventTime 换成 ProcessingTime。虽然这不太符合业务要求,但至少能够让任务平稳运行。为了满足业务需求,你可能需要基于 Flink 输出的数据的时间字段进行额外的处理。
本文介绍了大型 Flink 任务的运维和调优经验,立足实践,力求实用。
本文精华部分在于如何拆解 Flink 的性能问题,具体从以下三个正交的角度入手:
- 算子延迟高
- 并行度不足
- 数据倾斜
以及对这三类问题的具体优化思路。
最后介绍了一些不符合最佳实践的『逆向』操作,展示了工程实践中有时不得不『屈服于现实』的无奈。
希望本文对从事大数据开发的同学有所帮助。