




为了解决公司模型&特征迭代的系统性问题,提升算法开发与迭代效率,部门立项了特征平台项目。特征平台旨在解决数据存储分散、口径重复、提取复杂、链路过长等问题,在大数据与算法间架起科学桥梁,提供强有力的样本及特征数据支撑。平台从 Hive 、Hbase 、关系型数据库等大数据 ODS ( Operational Data store ) 层进行快速的数据 ETL ,将数据抽取到特征平台进行管理,并统一了数据出口,供数据科学家、数据工程师、机器学习工程师做算法模型的数据测试、训练、推理及其他数据应用。
本篇文章主要分享特征平台 flink on K8s 的部署实践,文章主要分以下几个方面进行介绍。首先本文对 K8s 基本概念及 Flink 任务执行图进行简要介绍,接着文章对比了现有的几种 Flink on K8s 部署方式,
为什么flink 要基于K8s做部署?
主要有以下几个优势:
- 容器环境容易部署、清理和重建:不像是虚拟环境以镜像进行分发部署起来对底层系统环境依赖小,所需要的包都可以集成到镜像中,重复使用。
- 更好的隔离性与安全性,应用部署以pod启动,pod之间相互独立,资源环境隔离后更安全。
- k8s集群能够利用好资源,机器学习、在线服务等许多任务都可以混合部署。
- 云原生的趋势,丰富的k8s生态,以及大数据计算上云原生的趋势
2.1 K8s 简介
Kubernetes 为您提供了一个可弹性运行分布式系统的框架。Kubernetes 会满足您的扩展要求、故障转移、部署模式等,Kubernetes 项目的本质,是为用户提供一个具有普遍意义的容器编排工具。
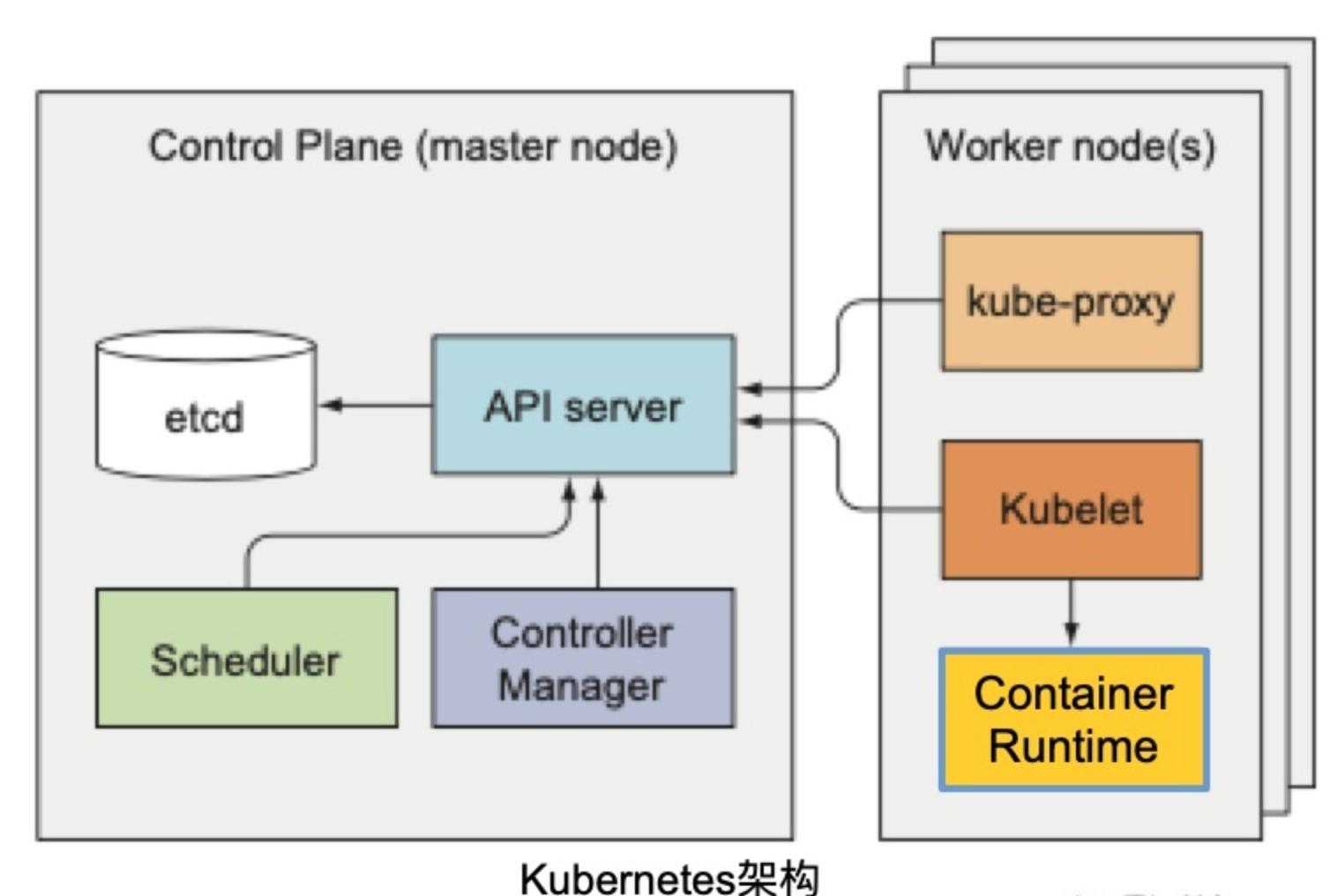
- K8S被称为云时代的操作系统(其中的镜像就类似软件安装包)
- 旨在提供“跨主机集群的自动部署、扩展以及运行应用程序容器的平台”
- 调度、资源管理、服务发现、健康检查、自动伸缩、滚动升级…
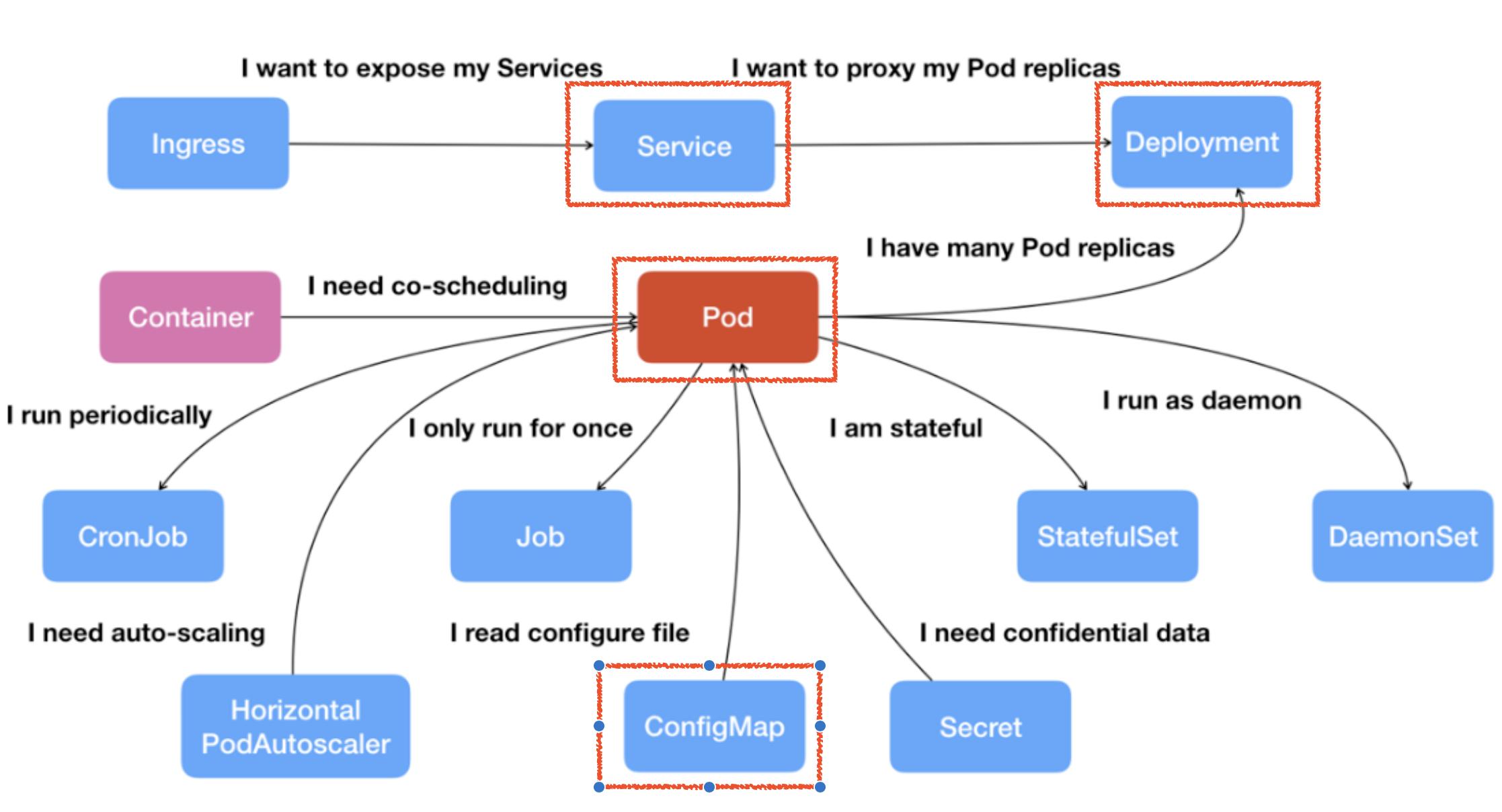
基本组件
Pod: K8s 的原子调度单位,是一个或多个 Container 的组合,Container 共享同一个网络、存储。
Deployment: 对一组相同 Pod 的高级抽象,可以自动重启恢复,保障高可用。
Service: 定义服务的访问入口,通过 Label Selector 绑定后端 Pod 副本集。如果 K8s 内部有一个服务,需要在外部进行访问,此时可以通过 Service 用 LoadBalancer 或者 NodePort 的方式将其暴露出去。如果不希望或不需要对外暴露服务,可以把 Service 设置为 Cluster IP 或者是 None 模式。
ConfigMap: K-V 结构数据,通常的用法是将 ConfigMap 挂载到 Pod ,作为配置文件提供 Pod 里新的进程使用。
Stateful - 有状态应用部署
Job与Cronjob-离线业务
2.2 Flink介绍
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算
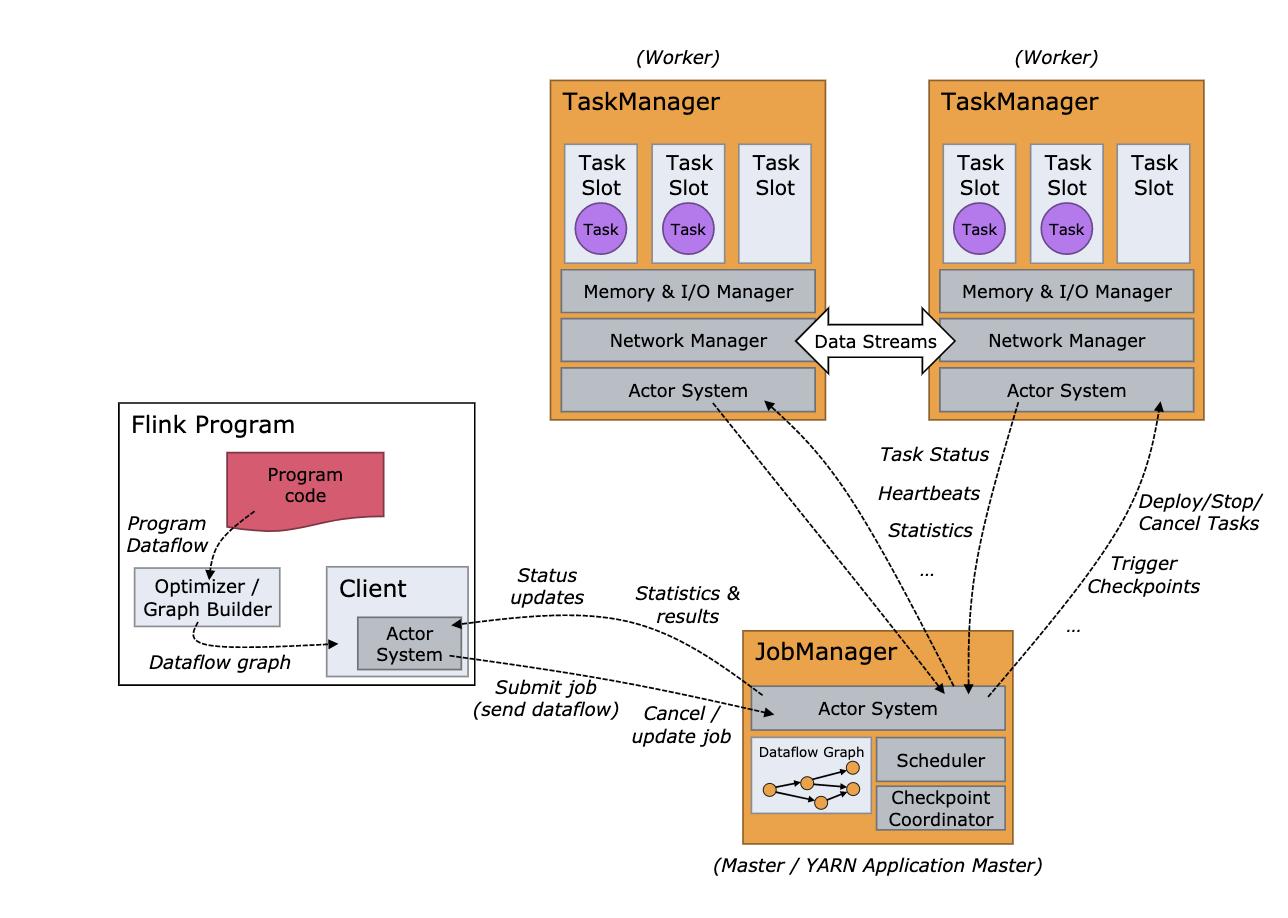
2.2.1 Flink 架构图
Flink 架构图跟常见的大数据组建类似,都是采用主流的主从架构,一个 JobManager,多个 TaskManager,并可对JobManager进行HA部署。
Flink 代码从提交到真正执行,需要经过几次 Graph 图的转换,过程如下:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
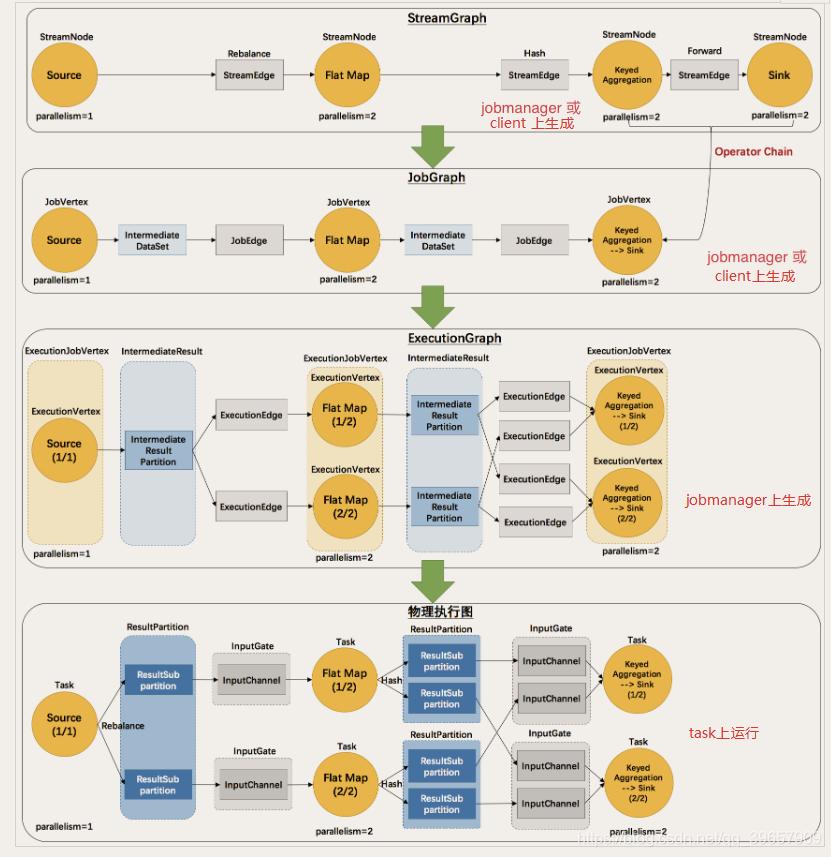
- 第一层 StreamGraph 从 Source 节点开始,每一次 transform 生成一个 StreamNode,两个 StreamNode 通过 StreamEdge 连接在一起,形成 StreamNode 和 StreamEdge 构成的DAG。
- 第二层 JobGraph,依旧从 Source 节点开始,然后去遍历寻找能够嵌到一起的 operator,如果能够嵌到一起则嵌到一起,不能嵌到一起的单独生成 jobVertex,通过 JobEdge 链接上下游 JobVertex,最终形成 JobVertex 层面的 DAG。
- JobVertex DAG 提交到任务以后,从 Source 节点开始排序,根据 JobVertex 生成ExecutionJobVertex,根据 jobVertex的IntermediateDataSet 构建 IntermediateResult,然后 IntermediateResult 构建上下游的依赖关系,形成 ExecutionJobVertex 层面的 DAG 即 ExecutionGraph。
- 最后通过 ExecutionGraph 层到物理执行层。
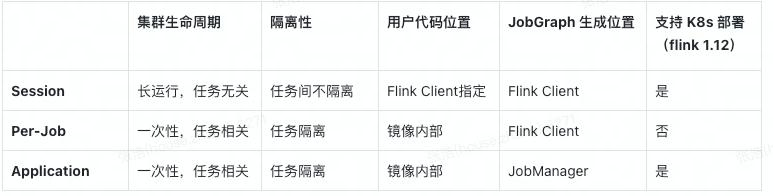
3.1 Flink 的部署模式 [1]
Session 模式
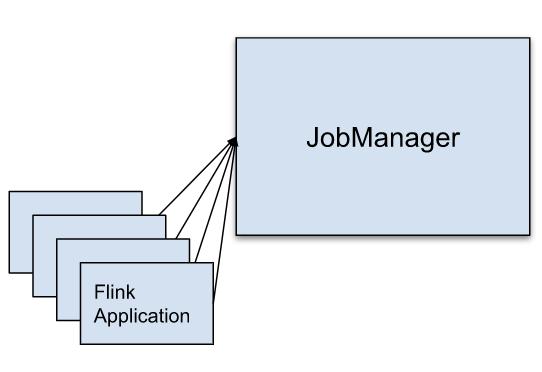
多个 Job 提交共享同一个 JobManager,Flink Cluster的实例已经被创建,并被所有Job共享的。Flink任务由Client提交,client做一些预备工作, 并在 Flink Client 上生成 JobGraph,这种方式的缺点是:一个Job导致的JobManager失败可能会导致所有的Job失败。
Per-Job 模式
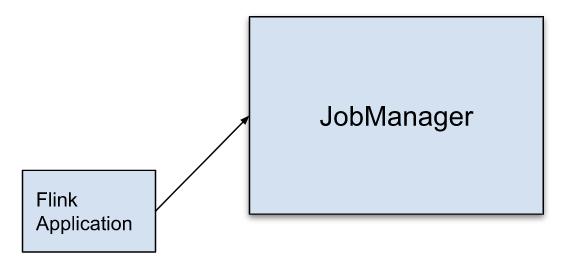
添加描述
为每次 Job 提交启动专用 JM,JM 将只执行此作业,然后退出。在 Flink Client 上生成 JobGraph,
可以理解为 Client 模式的Application Mode,这种模式充分利用资源管理框架的优势,例如Yarn,Mesos等,达到更强的资源隔离性,flink应用之间不会相互影响。一个Job一个Cluster实例。
Application 模式
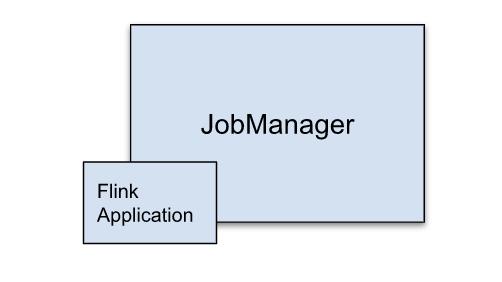
Flink提交的程序,被当做集群内部Application,不再需要Client端做繁重的准备工作例如执行main函数
数,生成JobGraph,下载依赖并分发到各个节点等),main函数被提交给JobManager执行。
一个Application一个Cluster实例。
3.3 Standalone 部署的不足
- 用户需要对 K8s 有一些最基本的认识,这样才能保证顺利将 Flink 运行到 K8s 之上。
- Flink 感知不到 K8s 的存在。
- 目前主要使用静态的资源分配。需要提前确认好需要多少个 TaskManager,如果 Job 的并发需要做一些调整,TaskManager 的资源情况必须相应的跟上,否则任务无法正常执行。
- 无法实时申请资源和释放资源。如果维持一个比较大的 Session Cluster,可能会资源浪费。但如果维持的 Session Cluster 比较小,可能会导致 Job 跑得慢或者是跑不起来。
3.4 Navtive 部署的优势
- 资源申请方式:Flink 的 Client 内置了一个 K8s Client,可以借助 K8s Client 去创建 JobManager,当 Job 提交之后,如果对资源有需求,JobManager 会向 Flink 自己的 ResourceManager 去申请资源。这个时候 Flink 的 ResourceManager 会直接跟 K8s 的 API Server 通信,将这些请求资源直接下发给 K8s Cluster,告诉它需要多少个 TaskManger,每个 TaskManager 多大。当任务运行完之后,它也会告诉 K8s Cluster 释放没有使用的资源。相当于 Flink 用很原生的方式了解到 K8s Cluster 的存在,并知晓何时申请资源,何时释放资源。
- Native 是相对于 Flink 而言的,借助 Flink 的命令就可以达到自治的一个状态,不需要引入外部工具就可以通过 Flink 完成任务在 K8s 上的运行。
3.5部署方案最终选择
通过Flink standalone和 native 模式的分析,standalone需要配合 kubectl + yaml 部署,Flink 无法感知 K8s 集群的存在,资源被动申请,而Native部署仅使用 flink 客户端 kubernetes-session.sh or flink run 部署,Flink 主动与 K8s 申请资源,而成为最佳的部署方式,另外因为任务主要是离线批处理,每个appllication可以包含多个job 比较适合业务需求。
这边只演示 k8s native部署模式,Standalone 部署需要手动去提前创建 ConfigMap、Service、JobManager Deployment、TaskManager Deployment 等比较麻烦。
4.1 K8s 集群
K8s >= 1.9 or Minikube
KubeConfig (可以查看、创建、删除 pods 和 services)
启用 Kubernetes DNS
具有 RBAC 权限的 Service Account 可以创建、删除 pods
4.2 PyFlink 镜像
FROM flink:1.12.1-scala_2.11-java8
# 安装 python3 and pip3 及需要的debug工具
RUN apt-get update -y && \
apt-get install -y python3.7 python3-pip python3.7-dev \
&& rm -rf /var/lib/apt/lists/*
RUN rm -rf /usr/bin/python
RUN ln -s /usr/bin/python3 /usr/bin/python
# 安装 Python Flink
RUN pip3 install apache-flink==1.12.1
# 如果有引用第三方 Python 依赖库, 可以在构建镜像时安装上这些依赖
#COPY /path/to/requirements.txt /opt/requirements.txt
#RUN pip3 install -r requirements.txt
# 如果有引用第三方 Java 依赖, 也可以在构建镜像时加入到 ${FLINK_HOME}/usrlib 目录下
RUN mkdir -p $FLINK_HOME/usrlib
COPY /path/of/external/jar/dependencies $FLINK_HOME/usrlib/
COPY /path/of/python/codes /opt/python_codes
Docker build 部署需要的 pyflink 镜像
Flink image -> PyFlink image -> PyFlink App image
4.3 Flink Application native部署
操作方式:flink application on k8s native模式非常简单,直接一条命令搞定了Application模式的运行提交 Job
./bin/flink run-application -p 2 -t kubernetes-application \
-Dkubernetes.cluster-id=app-cluster \
-Dtaskmanager.memory.process.size=4096m \
-Dkubernetes.taskmanager.cpu=2 \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dkubernetes.container.image=demo-pyflink-app:1.12.1 \
-pyfs /opt/python_codes \
-pym new_word_count
启动流程图:
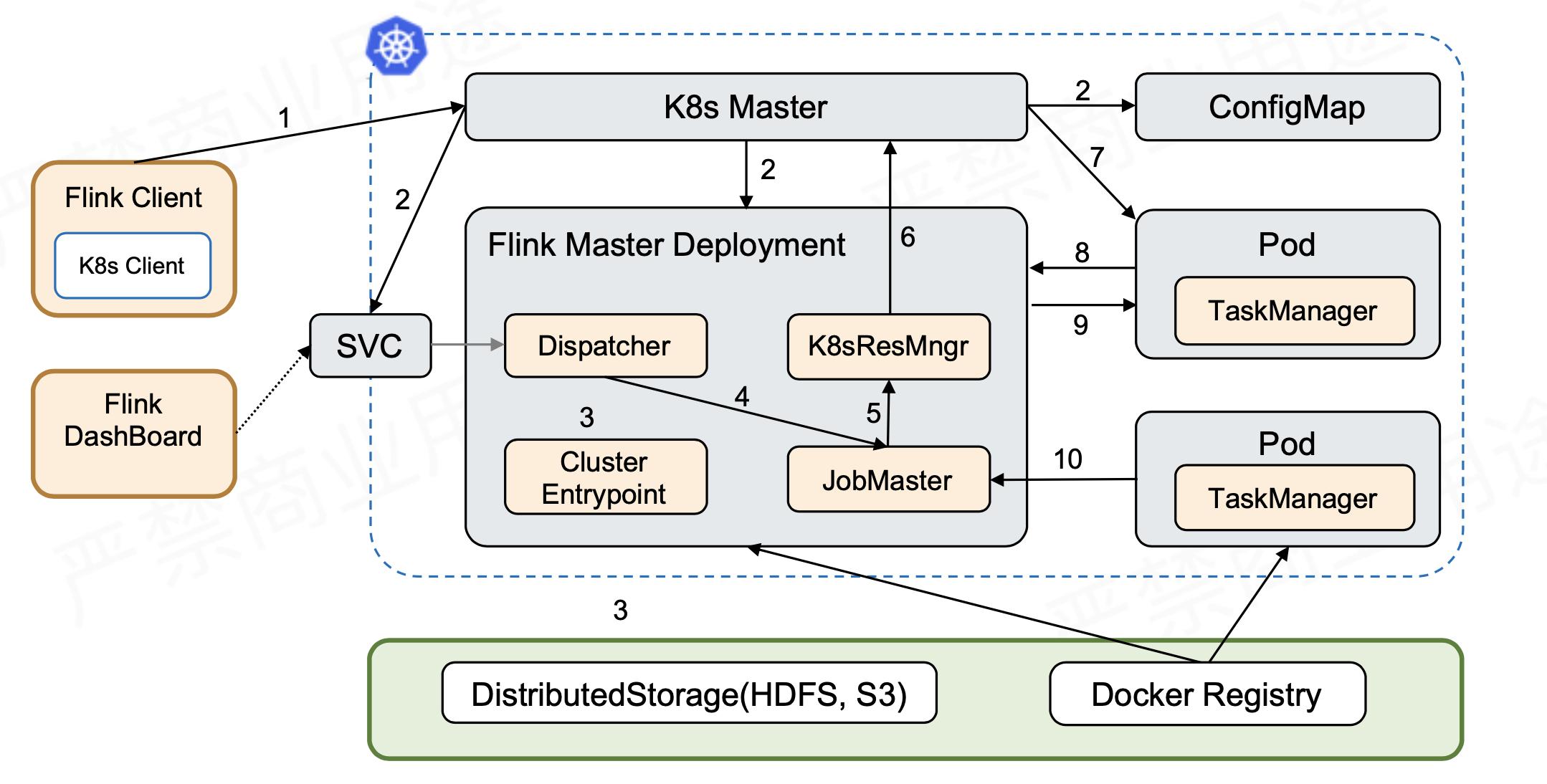
- 首先创建出了 Service、Master 和 ConfigMap 这几个资源以后,Flink Master Deployment 里面已经带了一个用户 Jar,这个时候 Cluster Entrypoint 就会从用户 Jar 里面去提取出或者运行用户的 main,然后产生 JobGraph。之后再提交到 Dispatcher,由 Dispatcher 去产生 Master,然后再向 ResourceManager 申请资源,后面的逻辑的就和 Session 的方式是一样的。
- 它和 Session 最大的差异就在于它是一步提交的。因为没有了两步提交的需求,如果不需要在任务起来以后访问外部 UI,就可以不用外部的 Service。可直接通过一步提交使任务运行。通过本地的 port-forward 或者是用 K8s ApiServer 的一些 proxy 可以访问 Flink 的 Web UI。此时,External Service 就不需要了,意味着不需要再占用一个 LoadBalancer 或者占用 NodePort。
4.4 生产化流程
Flink应用编写流程如下图:

这块产品主要是采用flink sql去完成 功能,运行模式比较统一,注册source、sink、 执行sq,因此可以采用同一份代码,提供给用户sql编辑框或者用户界面上选择所需要读取的库表字段后端组合成sql语句,最终统一任务运行形成一个离线计算平台,通过动态传递参数进行flink应用的提交和执行。
后端在数据库中配置好source和sink的类型以及连接信息暴露给前端。
前端去选择对应的数据源比如说mysql、hive,然后选择所需要读取的库表,展示table schema ,用户 可以选择需要读取的库表字段。同时选择需要存储的数据汇如说elasticsearch、mysql等,获取这些动态参数后,通过k8s java client 去创建 job去提交flink应用。
flink应用启动时获取这些db、库表信息、库表字段后传递给FLink程序,flink程序构造成flinksql去执行应用,具体不在详细执行。
本文为大家分享 flink on K8s 部署的实践经验,简要介绍了 K8s 基本概念与 Flink 执行图,对 Flink 不同的部署方式进行了对比,并使用具体 demo 分析了 Pyflink on K8s 部署的过程中组件间的协调过程,协助大家在上手使用的同时了解底层执行过程。
[1] Apache Flink 1.12 Documentation: Deployment
[2] Apache Flink 1.12 Documentation: Kubernetes Setup
[3] Apache Flink 1.12 Documentation: Native Kubernetes
[4] Flink on K8s技术演进:如何原生地在Kubernetes上运行Flink?-InfoQ