




字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务。其中一个典型场景是 Kafka/ByteMQ/RocketMQ -> HDFS/Hive 。Kafka/ByteMQ/RocketMQ -> HDFS/Hive(下面均称之为 MQ dump,具体介绍可见 字节跳动基于 Flink 的 MQ-Hive 实时数据集成 ) 在数仓建设第一层,对数据的准确性和实时性要求比较高。
目前字节跳动中国区 MQ dump 例行任务数巨大,日均处理流量在 PB 量级。巨大的任务量和数据量对 MQ dump 的稳定性以及准确性带来了极大的挑战。
本文主要介绍 DTS MQ dump 在极端场景中遇到的数据丢失问题的排查与优化,最后介绍了上线效果。
HDFS 集群某个元数据节点由于硬件故障宕机。在该元数据节点终止半小时后,HDFS 手动运维操作将 HDFS 切主到 backup 节点后,HDFS 恢复服务。故障恢复后用户反馈 MQ dump 在故障期间有数据丢失,产出的数据与 MQ 中的数据不一致。
收到反馈后我们立即进行故障的排查。下面先简要介绍一下 Flink Checkpoint 以及 MQ dump 写入流程,然后再介绍一下故障的排查过程以及解决方案,最后是上线效果以及总结。
Flink 基于 Chandy-Lamport 分布式快照算法实现了 Checkpoint 机制,能够提供 Exactly Once 或者 At Least Once 语义。
Flink 通过在数据流中注入 barriers 将数据拆分为一段一段的数据,在不终止数据流处理的前提下,让每个节点可以独立创建 Checkpoint 保存自己的快照。每个 barrier 都有一个快照 ID ,在该快照 ID 之前的数据都会进入这个快照,而之后的数据会进入下一个快照。
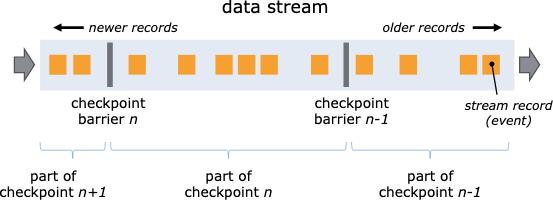
Checkpoint 对 Operator state 进行快照的流程可分为两个阶段:
- Snapshot state 阶段:对应 2PC 准备阶段。Checkpoint Coordinator 将 barries 注入到 Source Operator 中。Operator 接收到输入 Operator 所有并发的 barries 后将当前的状态写入到 state 中,并将 barries 传递到下一个 Operator。
- Notify Checkpoint 完成阶段:对应 2PC 的 commit 阶段。Checkpoint Coordinator 收到 Sink Operator 的所有 Checkpoint 的完成信号后,会给 Operator 发送 Notify 信号。Operator 收到信号以后会调用相应的函数进行 Notify 的操作。
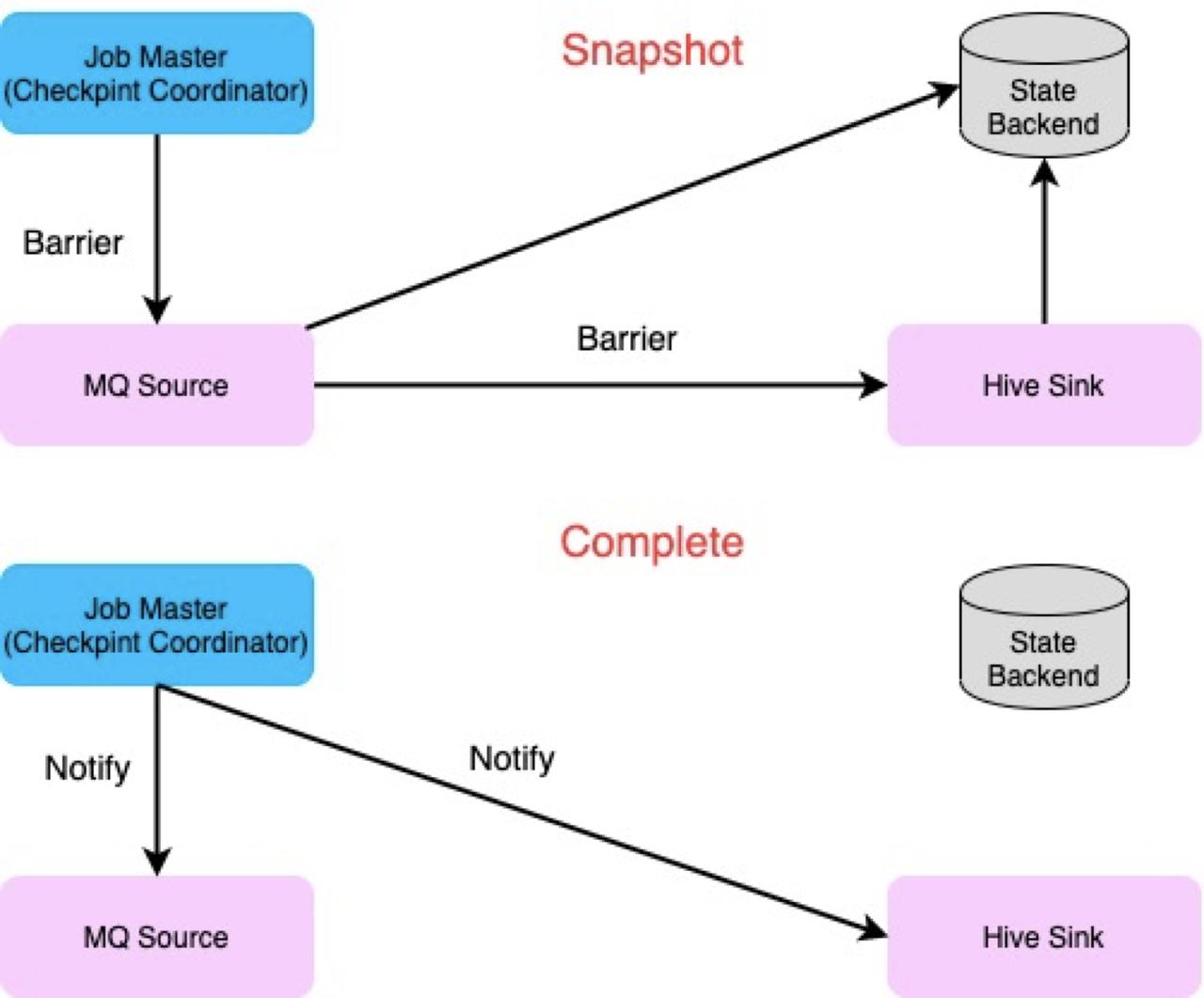
而在任务失败后,任务会从上一个 Checkpoint state 中进行恢复,进而实现 Exactly Once 或者 At Least Once 语义。
MQ dump 利用 Flink Checkpoint 机制和 2PC(Two-phase Commit) 机制实现了 Exactly Once 语义,数据可以做到不重不丢。
根据 Flink Checkpoint 的流程,MQ dump 整个写入过程可以分为四个不同的流程:
- 数据写入阶段
- SnapshotState 阶段
- Notify Checkpoint 完成阶段
- Checkpoint 恢复阶段
整个流程可以用下面的流程图表示:
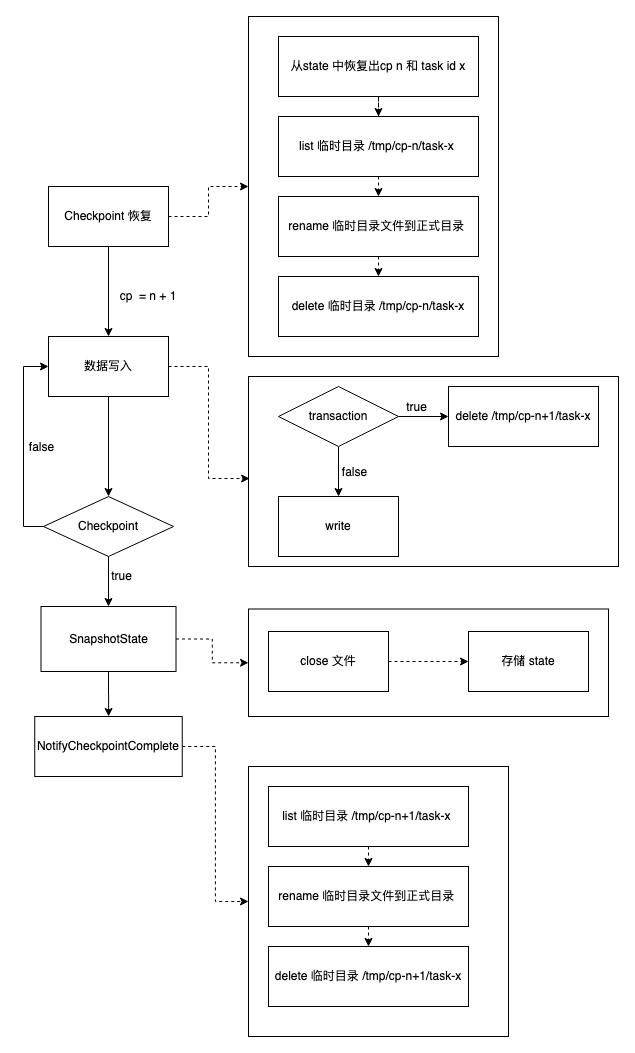
下面详细介绍上面各个阶段的主要操作。假设 Flink 任务当前 Checkpoint id 为 n,当前任务的 task id 为x。
数据写入阶段
写入阶段就主要有以下两个操作:
- 如果是当前 Checkpoint 第一次写入(transaction),先清理要写入临时文件夹
/tmp/cp-n/task-x
- 在临时文件夹中建立文件并写入数据
注意在写入数据之前我们会先清理临时目录。执行这个操作的原因是我们需要保证最终数据的准确性:
假设任务 x 在 Checkpoint n 写入阶段失败了(将部分数据写入到临时文件夹 /tmp/cp-n/task-x),那么任务会从上一个 Checkpoint n-1 恢复,下一个写入的 Checkpoint id 仍然为 n。如果写入前不清理临时目录,失败前遗留的部分脏文件就会保留,在 Checkpoint 阶段就会将脏文件移到正式目录中。
SnapshotState 阶段
SnapshotState 阶段对应 2PC 的两个阶段中的第一个阶段。主要操作是关闭正在写入的文件,并将任务的 state (主要是当前的 Checkpoint id 和 task id)存储起来。
Notify Checkpoint 完成阶段
该阶段对应 2PC 两个阶段中的第二个阶段。主要操作如下:
- List 临时目录文件夹
/tmp/cp-n/task-x
- 将临时目录文件夹下的所有文件 rename 到正式目录
- 删除临时目录文件夹
/tmp/cp-n/task-x
Checkpoint 恢复阶段
Checkpoint 恢复阶段是任务在异常场景下,从轻量级的分布式快照恢复阶段。主要操作如下:
- 从 Flink state 中恢复出任务的 Checkpoint id n 和 任务的 task id x
- 根据 Checkpoint id 和 任务的 task id x 获取到临时目录文件夹
/tmp/cp-n/task-x
- 将临时目录文件夹下的所有文件 rename 到正式目录
- 删除临时目录文件夹
/tmp/cp-n/task-x
了解完相关写入流程后,我们回到故障的排查。用户任务配置的并发为 8,也就是说执行过程中有 8 个task在同时执行。
Flink 日志查看
排查过程中,我们首先查看 Flink Job manager 和 Task manager 在 HDFS 故障期间的日志,发现在 Checkpoint id 为 4608 时, task 2/3/6/7 都产出了若干个文件。而 task 0/1/4/5 在 Checkpoint id 为 4608 时,都由于某个文件被删除造成写入数据或者关闭文件时失败,如 task 0 失败是由于文件 /xx/_DUMP_TEMPORARY/cp-4608/task-0/date=20211031/18_xx_0_4608.1635674819911.zstd 被删除而失败。
但是查看正式目录下相关文件的信息,我们发现 task 2、3 两个 task 并没有 Checkpoint 4608 的文件(文件名含有 task id 和 Checkpoint id 信息,所以可以根据正式目录下的文件名知道其是哪个 task 在哪个 Checkpoint 期间创建的)。故初步确定的原因是某些文件被误删造成数据丢失。 Task 2/3/6/7 在文件删除后由于没有文件的写入和关闭操作,task 正常运行;而 task 0/1/4/5 在文件删除后还有文件的写入和关闭操作,造成 task 失败。
HDFS 元数据查看
下一步就要去排查文件丢失的原因。我们通过 HDFS trace 记录表( HDFS trace记录表记录着用户和系统调用行为,以达到分析和运维的目的)查看 task 2 Checkpoint 4608 临时目录操作记录,对应的路径为 /xx/_DUMP_TEMPORARY/cp-4608/task-2。
| src_path | method | operation_cost_ms | toDateTime(local_timestamp_ms) | result |
|---|---|---|---|---|
| /xx/_DUMP_TEMPORARY/cp-4608/task-2 | getFileInfo | 2 | 2021/10/31 18:23:02 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2 | delete | 1111895 | 2021/10/31 18:22:09 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2 | delete | 167990 | 2021/10/31 18:10:56 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2 | delete | 107077 | 2021/10/31 18:10:05 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2 | delete | 68885 | 2021/10/31 18:09:57 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2 | delete | 119439 | 2021/10/31 18:08:17 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2 | delete | 148846 | 2021/10/31 18:07:46 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2 | delete | 115081 | 2021/10/31 18:06:52 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2 | delete | 96490 | 2021/10/31 18:05:08 | 1 |
从 HDFS trace 操作记录中可以发现文件夹的删除操作执行了很多次。
然后再查询 task 2 Checkpoint 4608 临时目录下的文件操作记录。可以看出在 2021-10-31 18:08:58 左右实际有创建两个文件,但是由于删除操作的重复执行造成创建的两个文件被删除。
| src_path | method | operation_cost_ms | toDateTime(local_timestamp_ms) | result |
|---|---|---|---|---|
| /xx/_DUMP_TEMPORARY/cp-4608/task-2/date=20211031/17_xx_2_4608.1635674938391.zstd | complete | 8 | 2021/10/31 18:08:58 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2/date=20211031/17_xx_2_4608.1635674938391.zstd | fsync | 10 | 2021/10/31 18:08:58 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2/date=20211031/17_xx_2_4608.1635674938391.zstd | addBlock | 9 | 2021/10/31 18:08:58 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2/date=20211031/18_xx_2_4608.1635674938482.zstd | complete | 9 | 2021/10/31 18:08:58 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2/date=20211031/18_xx_2_4608.1635674938482.zstd | fsync | 8 | 2021/10/31 18:08:58 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2/date=20211031/18_xx_2_4608.1635674938482.zstd | addBlock | 24 | 2021/10/31 18:08:58 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2/date=20211031/18_xx_2_4608.1635674938482.zstd | create | 12 | 2021/10/31 18:08:58 | 1 |
| /xx/_DUMP_TEMPORARY/cp-4608/task-2/date=20211031/17_xx_2_4608.1635674938391.zstd | create | 12 | 2021/10/31 18:08:58 | 1 |
问题的初步原因已经找到:删除操作的重复执行造成数据丢失。
根本原因
我们对以下两点感觉比较困惑:一是为啥删除操作会重复执行;二是在写入流程中,删除操作要不是发生在数据写入之前,要不发生在数据已经移动到正式目录之后,怎么会造成数据丢失。带着疑惑,我们进一步分析。
忽略 Flink Checkpoint 的恢复流程以及 Flink 状态的操作流程,只保留与 HDFS 交互的相关步骤,DTS MQ dump 与 HDFS 的操作流程可以简化为如下流程图:
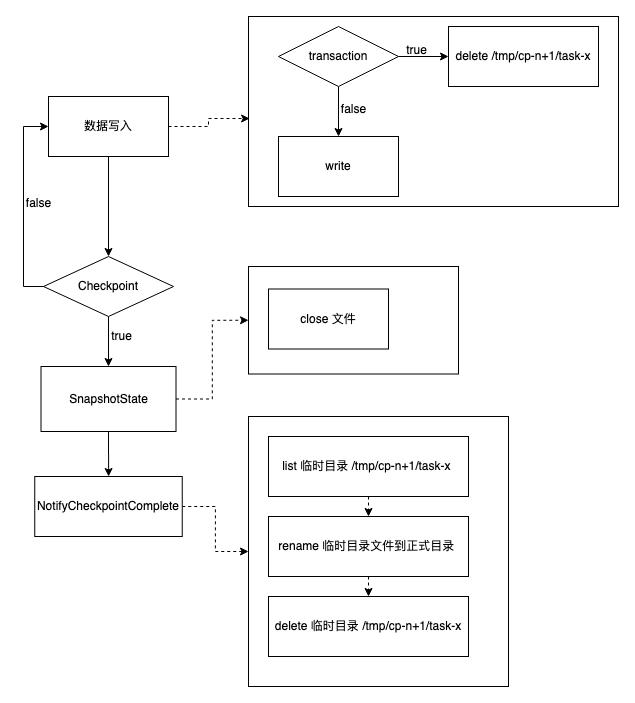
在整个写入流程中涉及到 delete 的操作有两个地方:一个是在写入文件之前;一个是在将临时文件重命名到正式目录之后。在第二个删除操作中,即使删除操作重复执行,也不影响最终数据的准确性。因为在之前的重命名过程中已经将所有数据从临时文件夹移动到正式目录。
所以我们可以确定是在写入文件之前的删除操作的重复执行造成最终的数据丢失。
在 task-2 的日志中我们发现 HDFS client 在 18:03:37-18:08:58 一直在尝试调用 HDFS 删除接口删除临时目录,但是由于java.net``.SocketTimeoutException 一直删除失败。在时间点18:08:58 删除操作执行成功。而这个时间点也基本与我们在 HDFS trace 数据中发现删除操作的执行记录时间是对应的。通过日志我们发现建立文件以及关闭文件操作基本都是在 18:08:58 这个时间点完成的,这个时间点与 HDFS trace 中的记录也是对应上的。
咨询 HDFS 后,HDFS 表示 HDFS 删除操作不会保证幂等性。进而我们判断问题发生的根源为:在故障期间,写入数据前的删除操作的多次重试在 HDFS NameNode 上重复执行,将我们写入的数据删除造成最终数据的丢失。如果重复执行的删除操作发生在文件关闭之前,那么 task 会由于写入的文件不存在而失败;如果重复删除命令是在关闭文件之后,那么就会造成数据的丢失。
MQ dump 在异常场景中丢失数据的本质原因是我们依赖删除操作和写入操作的顺序性。但是 HDFS NameNode 在异常场景下是无法保证两个操作的顺序性。
方案一:HDFS 保证操作的幂等性
为了解决这个问题,我们首先想到的是 HDFS 保证删除操作的幂等性,这样即使删除操作重复执行也不会影响后续写入的问题,进而可以保证数据的准确性。但是咨询 HDFS 后,HDFS 表示 HDFS在现有架构下无法保证删除的幂等性。
参考 DDIA (Designing Data-Intensive Applications) 第 9 章中关于因果关系的定义:因果关系对事件施加了一种顺序——因在果之前。对应于MQ dump 流程中删除操作是因,发生在写入数据之前。我们需要保证这两个关系的因果关系。而根据其解决因果问题的方法,一种解决思路是 HDFS 在每个client 请求中都带上序列号顺序,进而在HDFS NameNode 上可以保证单个client的请求因果性。跟HDFS 讨论后发现这个方案的实现成本会比较大。
方案二:使用文件 state
了解 HDFS 难以保证操作的幂等性后,我们想是否可以将写入前的删除操作去除,也就是说在写入 HDFS 之前不清理文件夹而是直接写入数据到文件,这样就不需要有因果性的保证。
如果我们知道临时文件夹中哪些文件是我们需要的,在重命名阶段就可以直接将需要的文件重命名到正式目录而忽略临时文件夹中的脏文件,这样在写入之前就不需要删除文件夹。故我们的解决方案是将写入的文件路径存储到 Flink state 中,从而确保在 commit 阶段以及恢复阶段可以将需要的文件移动到正式目录。
最终,我们选择了方案二解决该问题,使用文件 state 前后处理流程对比如下图所示:
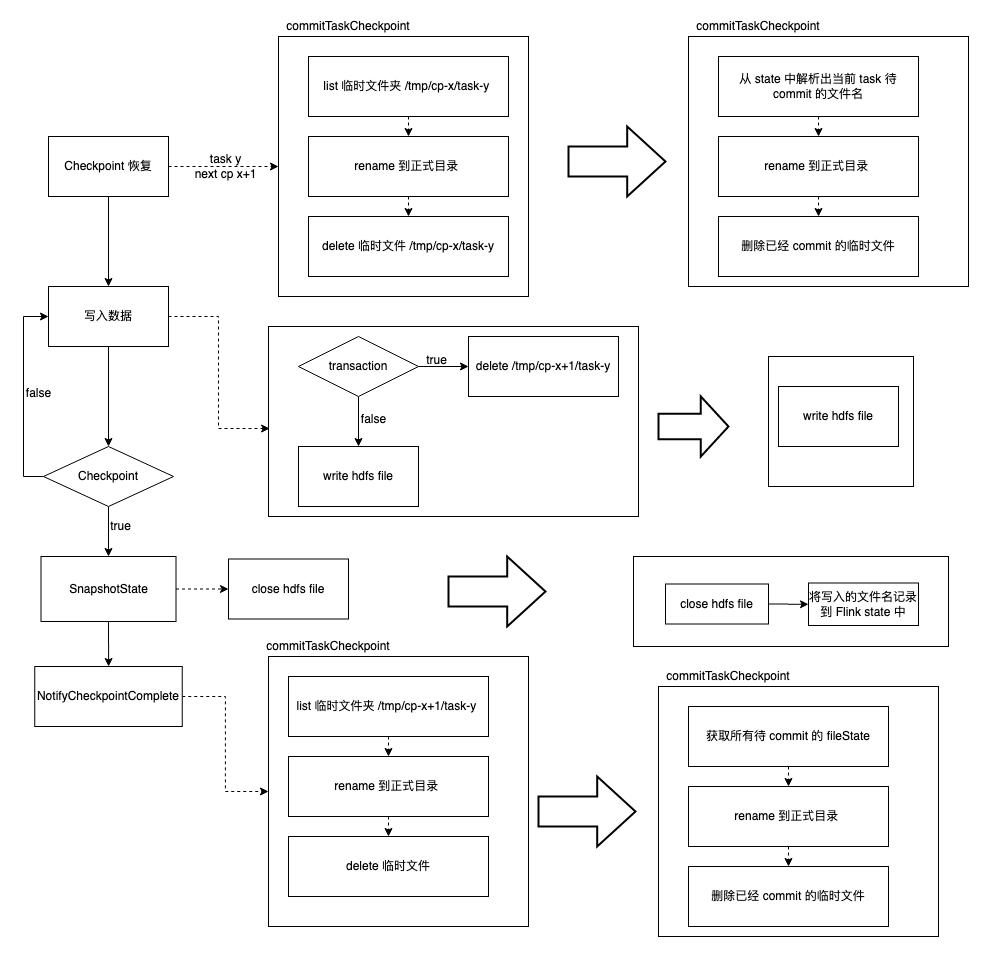
目前文件 state 已经在线上使用了,下面先介绍一下实现中碰到的相关问题,然后再描述一下上线后效果。
文件 state 实现细节
文件移动幂等性
通过文件 state 我们可以解析出当前文件所在的临时目录以及将要写入的正式目录。通过以下流程我们保证了移动的幂等性。
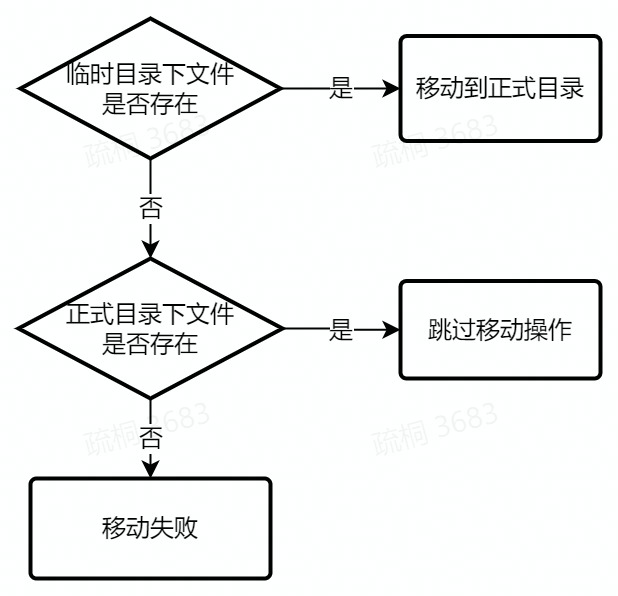
通过以上的流程即使文件移动失败,再次重试时也能够保证文件移动的幂等性。
可观测性
实现文件 state 后,我们增加了 metric 记录创建的文件数量以及成功移动到正式目录的文件数量,提高了系统可观测性。如果文件在临时目录和正式目录都不存在时,我们增加了移动失败的 metric ,并增加了报警,在文件移动失败后可以及时感知到,而不是等用户报告数据丢失后再排查。
上线后线上 metric 效果如下:

总共有四个指标,分别为创建文件的数量、重命名成功文件的数量、忽略重命名文件的数量、重命名失败的文件数量,分别代表的意义如下:
- 创建文件的数量:state 中所有文件的数量,也就是当前 Checkpoint 处理数据阶段创建的所有文件数量。
- 重命名成功文件的数量:NotifyCheckpointComplete 阶段将临时文件成功移动到正式目录下的文件数量。
- 忽略重命名文件的数量:NotifyCheckpointComplete 阶段忽略移动到正式目录下下的文件数量。也就是临时文件夹中不存在但是正式目录存在的文件。这种情况通常发生在任务有 Failover 的情况。 Failover 后任务从 Checkpoint 中恢复,失败前已经重命名成功的文件在当前阶段会忽略重命名。
- 重命名失败的文件数量:临时目录以及正式目录下都不存在文件的数量。这种情况通常是由于任务发生了异常造成数据的丢失。目前线上比较常见的一个 case 是任务在关闭一段时间后再开启。由于 HDFS TTL 的设置小于任务关闭的时长,临时目录中写入的文件被 HDFS TTL 策略清除。这个结果实际是符合预期的。
前向兼容性
预期中上线文件 state 后写入数据前不需要删除要写入的临时文件,但是为了保证升级后的前向兼容性,我们分两期上线了文件 state :
- 第一期写入数据前保留了删除操作
- 第二期删除了写入数据前的删除操作
第一期保留删除操作的原因如果文件 state 上线后有异常的话,回滚到之前的版本需要保证数据的准确性。而只有保留删除操作才能保证回滚后数据的准确性。否则如果之前的 Checkpoint 文件夹中有脏文件存在,回滚到文件 state 之前的版本的话,由于没有文件 state 存在,会将脏文件也移动到正式目录中,影响最终数据的准确性。
切主演练
上线后与 HDFS 进行了 HDFS 集群切主演练。演练了以下两个场景:
- HDFS 集群正常切主
- HDFS 集群主节点失败超过10分钟
而测试过程是建立两组不同的任务消费相同的 Kafka topic,写入不同的 Hive 表。然后建立数据校验任务校验两组任务数据的一致性。一组任务使用 HDFS 测试集群,另一组任务使用正常集群。
将测试集群进行多次 HDFS 正常切主和异常切主,校验任务显示演练结束前后两组任务写入数据的一致性。结果验证了该方案可有效解决 HDFS 操作非幂等的丢数问题。
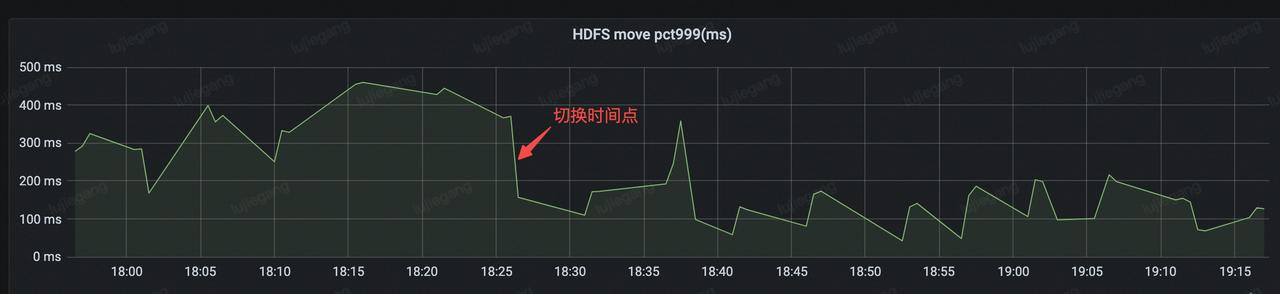
性能效果
使用文件 state 后,在 Notify Checkpoint 完成阶段不需要调用 HDFS list 接口,可以减少一次 HDFS 调用,理论上可以减少 Notify Checkpoint 阶段与 HDFS 交互时间。下图展示了上线(18:26 左右)前后 Notify 阶段与 HDFS 交互的 metrics。可以看出上线前的平均处理时间在 300ms 左右,而上线后平均处理时间在 150 ms 左右,减少了一半的处理时间。
随着字节跳动产品业务的快速发展,字节跳动一站式大数据开发平台功能也越来越丰富了,提供了离线、实时、增量等场景下全域数据集成解决方案。而业务数据量的增大以及业务的多样化给数据集成带来了很大的挑战。比如我们扩展了添加 Hive 分区的策略,以支持实时数仓近实时 append 场景,使数据的使用延迟下降了 75% 。
字节跳动流式数据集成仍在不断发展中,未来主要关注以下几方面:
- 功能增强,增加简单的数据转换逻辑,缩短流式数据处理链路,进而减少处理时延
- 架构升级,离线集成和实时数据集成架构统一
- 支持 auto scaling 功能,在业务高峰和低峰自动扩缩容,提高资源利用率,减少资源浪费
本文中介绍的《字节跳动流式数据集成基于 Flink Checkpoint 两阶段提交的实践和优化》,目前已通过火山引擎数据产品大数据研发治理套件 DataLeap 向外部企业输出。
大数据研发治理套件 DataLeap 作为一站式大数据中台解决方案,可以实现全场景数据整合、全链路数据研发、全周期数据治理、全方位数据安全。
欢迎关注字节跳动数据平台同名公众号