




开篇
想必大家都有一个疑问?何为OLTP,OLAP?它又能够给我们带来什么?
引入 | 图解那些OLAP分析引擎中的DBMS
资讯
元宇宙(Metaverse),数据湖(Data Lake),信创自主可控,互联互通,数字化建设......
这些概念越来越火热,前些时候大部分工作集中在信创自主可控,现阶段已告一段落。信息化,数字化建设也是不可或缺的一环,遇到挑战,勇于迎对,不断的攻克技术难关是技术人的一种追求!数仓多维数据模型详细设计,欢迎一起加入交流探讨,希望能给读者在实际业务场景-OLAP分析演进过程中有些不一样的IDea。
场景
目前数据存储的业务类型-OLTP,OLAP......
1、 其中一种是企业知识库,权限系统,数据由本系统产生,数据量不是很大,但是数据增删改较多;
2、 另一种是统计分析类型,数据不由本系统产生,来自医院各生产系统,数据集规模极其庞大,并且数据查询较多。
思考
数据每天在源源不断产生,音视频,影像图片,文本......
1、 海量数据存储出现瓶颈,单台机器无法负载大规模数据集;
2、 单台机器IO读写请求,成为海量数据存储时高并发-大规模请求的瓶颈;
3、 随着时间的推移,数据规模越来越庞大-加并发MPP架构,数据存储横向水平扩展,存储服务增加/删除,但若所有节点参与运算,水平扩展到一定程度硬件必然很难hold,很容易出现短板,并且容量也有明显天花板,可结合批处理与MPP架构;
4、 大数据给传统的关系型数据库-DBMS带来巨大挑战,在海量数据场景下,数据实时分析-时延低、并发数高、支持SQL或类SQL,变得尤为重要!
现状
Oracle,ElasticSearch,MySQL集群架构
目前,Oracle中多个业务库,数据集极其庞大,MySQL中多个业务库,单表数据量超过千万级别......
随着数据一直在不断增长,往水平方方向扩展节点,虽然能在一定程度上缓解大数据带来的压力,但长久来看,数据库查询性能无疑受到了巨大的冲击!
传统关系型数据库+NOSQL型数据库,暂时存储的都是结构化类型数据(非结构化数据会经过一系列技术转化为结构化数据),当然,未来肯定还会有大量的非结构化数据存储。
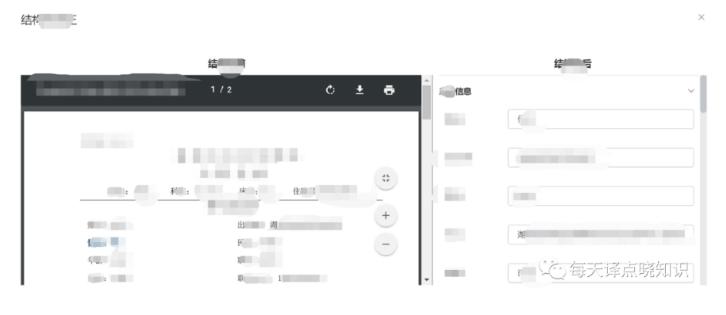
基于es倒排索引+宽表模型,数据检索性能大幅度提升,上一组案例效果。
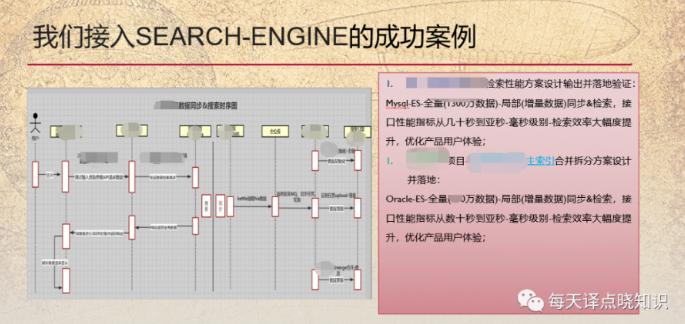
随着查询越来越复杂,数据规模持续增长,我们的数据分析目前也越来越复杂,数据规模也需考虑集中存储。
猜想
是否能够在数据库中,通过一系列高级分析算法,对数据进行分析与处理?
预期
成熟的海量数据解决方案
1、 生态圈丰富,成功案例较多,开源;
2、 统一数据中心,支持未来数据增长,动态扩展;
3、 支持目前业务体系,标准化接口,助力科学计算,支持Python,ETL,R,BI......
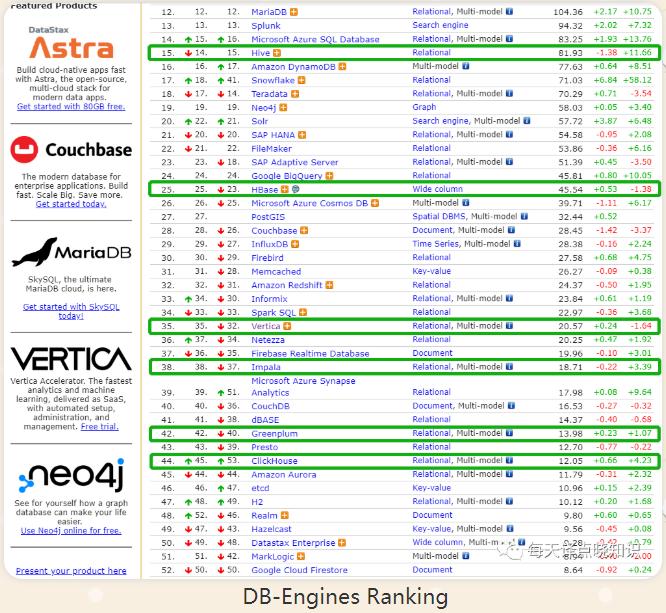
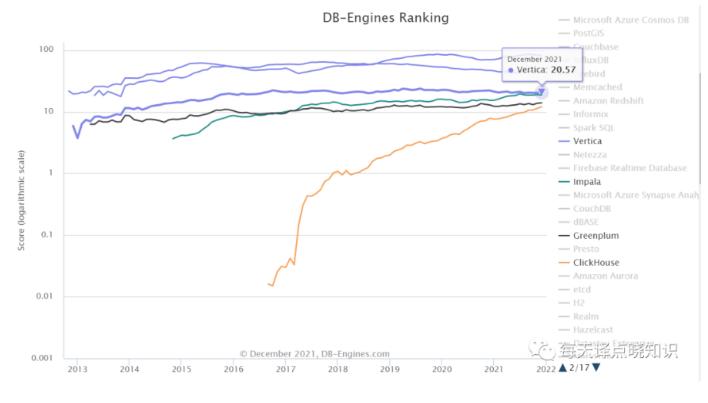
回到DB-Engines Ranking,Hive、HBase、Vertica、Impala、Greenplum、 ClickHouse.
其中,
Hive: 使用一种类似SQL查询语言,作用在分布式存储系统的文件之上,通常用于进行离线数据处理操作-MapReduce,支持多种不同的执行引擎-Hive on MapReduce、Hive on Tez、Hive on Spark.
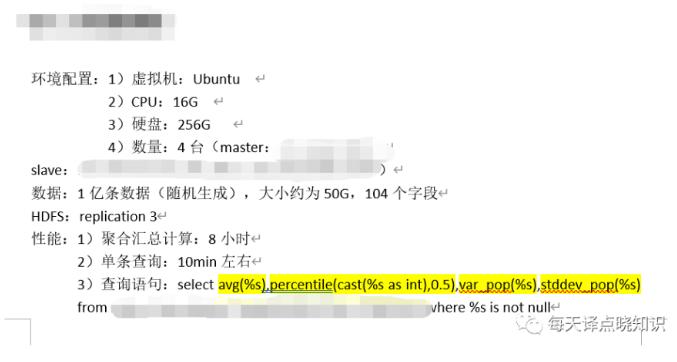
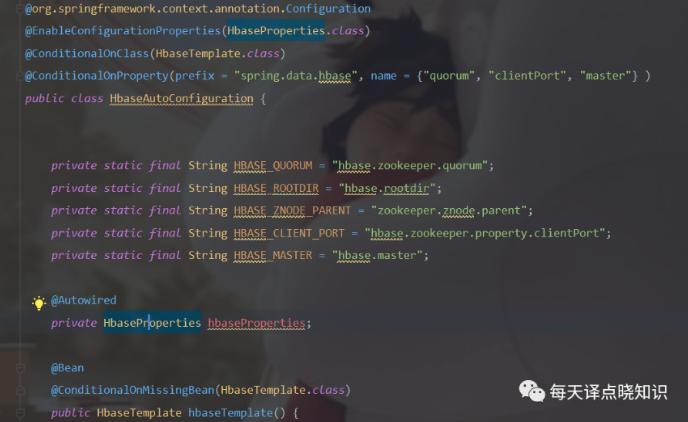
HBase: 分布式、面向列开源数据库,不同于一般的关系型数据库,HBase基于列的而不是基于行的模式。
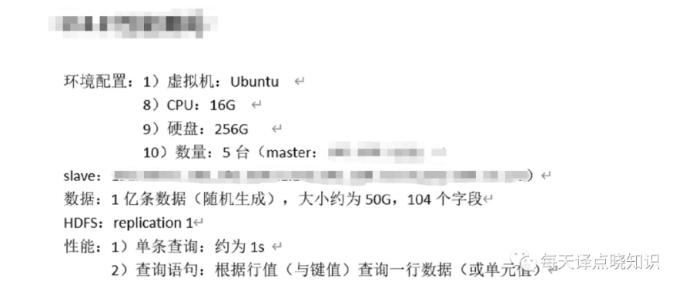
Java接入:
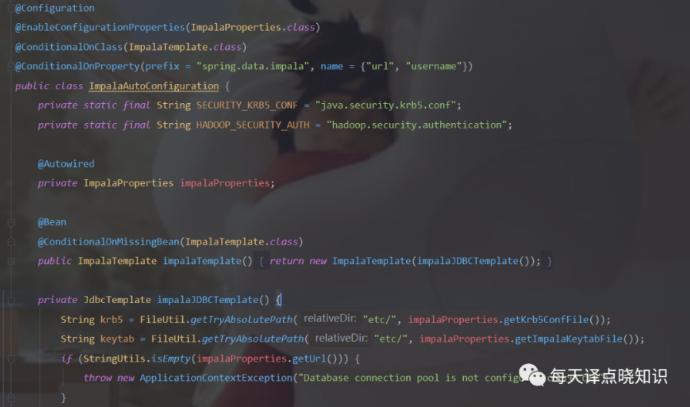
Impala: 开源,基于HDFS/HBase的MPP SQL引擎,拥有和Hadoop一样的可扩展性、它提供了类SQL-类Hsql语法,在多用户场景下亦能拥有较高的响应速度和吞吐量,兼顾数据仓库,具有实时,批处理,多并发等优点。

Java接入:
在阐述Vertica(简称V)、 ClickHouse(简称C)、Greenplum(简称G)这三款MPP之前,我们不妨以北京地铁线路图为例:
北京地铁一天的吞吐量多大,周末的吞吐量又是多少?想象-地铁就好比MPP-海量数据的并行处理。

拍摄于中关村-鼎好大厦(北京大学正对面)2019-01
达到预期可选择的方案
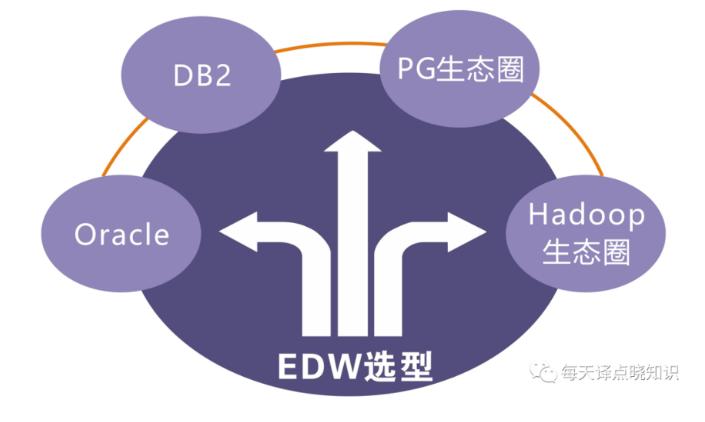
对现状的构思
海量的数据并行处理,标准的SQL,成熟的案例V-C-G......
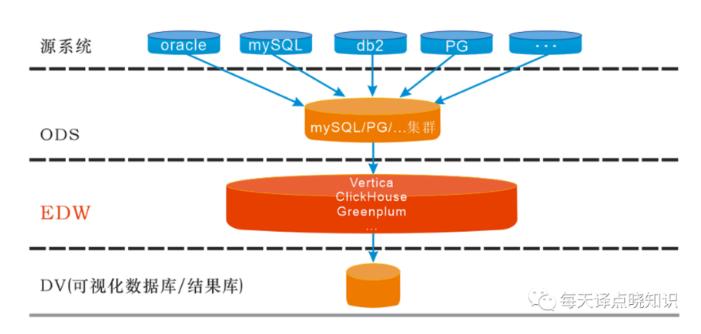
BigData-OLAP分析引擎演进
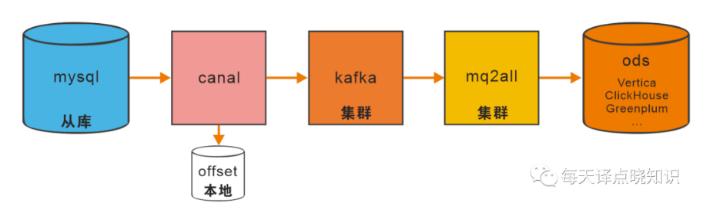
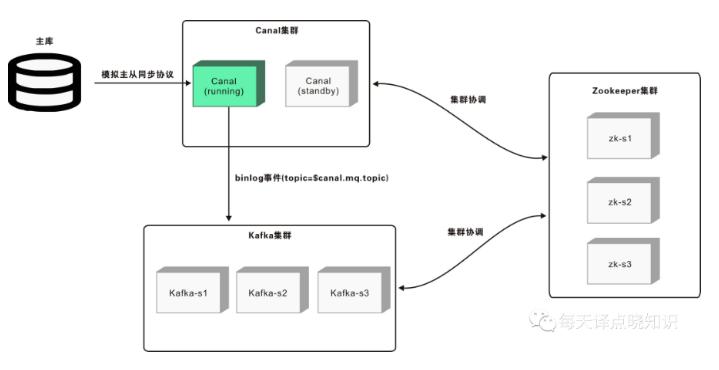
基于V、 C、G构建离线/实时数仓生态-OLAP体系,可综合其场景择优选取,
其中,
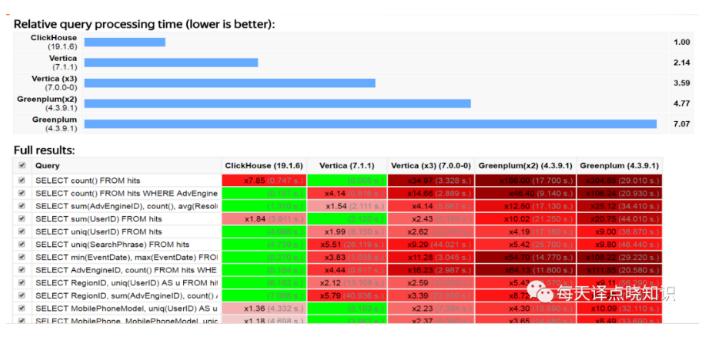
引入大宽表分析性能优异
Vertica: 无Master的MPP架构
基于列存储的MPP架构的数据库管理系统(DBMS),可以支持存放多至PB(Petabyte)级别的结构化数据。
1、 无共享的MPP体系架构-集群中的所有节点对等,没有主节点或其他共享资源,通过增加节点,即可线性地扩展集群的计算能力和数据处理容量;
2、 列式存储和计算-通过列式计算和强大的主动数据压缩,大幅降低成本高昂的磁盘,执行查询的速度大幅度提升;
3、 实时分析-内存与磁盘混合存储架构,原生支持kafka消息系统的连接,数据实时装载,秒级分析;
4、 数据库内分析库-开箱即用的数据库内时序插值和关联、事件窗口和会话处理等众多分析功能包;
5、 标准SQL支持-支持关系数据库事务处理和ACID规范,提供ODBC、JDBC等接口规范驱动,兼容传统关系型数据库系统的开发、使用以及管理习惯,与现有的ETL和报表工具相集成;
6、 可扩展的数据库内分析框架-采用面向用户定义的过程式分析的强大开发框架,数据库内部处理->开放式访问。
ClickHouse: 面向列的数据库管理系统 (DBMS)
不同列的值分别存储,同一列的数据存储在一起。而面向行的DBMS-
MySQL、Postgres、SQL Server......
简言之,与一行相关的所有值在物理上彼此相邻存储。当然,不同的数据存储顺序更适合不同的场景。系统负载越高,定制系统设置以匹配使用场景的要求就越重要,并且这种定制变得越细粒度。
近期,ClickHouse的Star数量也不断持续增长,热度也一直不减-后起新秀。
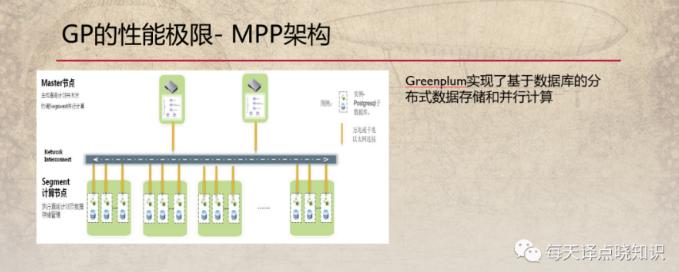
Greenplum: 有Master的MPP架构
Greenplum本身自带HA,虽然不能代替目前OLTP 的数据存储,但是它对OLAP却是方向,OLAP可以先做成统─数据存储,使得业务系统可以稳步的切入使用Greenplum,ETL也可使用Greenplum,实现统一的数据存储方案。
1、 大规模并行处理架构-提供了横向扩展,无共享体系结构的数据和查询并行化设计;
2、 PB规模数据加载-高性能加载使用MPP技术,加载速度随着增加节点而不断增加;
3、 创新的查询优化器-针对大数据工作负载而设计的基于成本的查询优化器。可将交互式和批处理模式应用到PB级别的大型数据集上,但不会降低查询性能和吞址量;
4、 多态数据存储和执行-表或者分区存储,执行和压缩设置可以按照数据访问方式进行配置。用户为每个表或者分区选择面向行或者列的存储和处理;
5、 高级的机器学习-可扩展的数据库内分析库,通过用户定义的函数扩展了SQL功能;
6、 外部数据访问-通过外部表语法访问和查询所有数据,支持传统的内部部署和下一代公共数据湖。
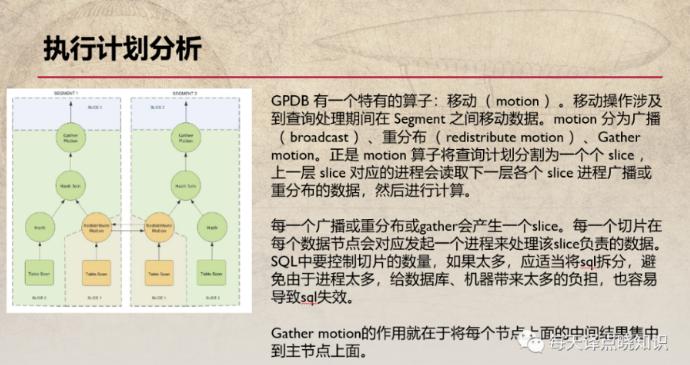
接下来,详看其执行计划分析。
延伸思考
OLTP,OLAP,HTAP可支撑对应业务体系规模?TB || PB?OLAP,HTAP在数据分析领域,相比OLTP能够给我们带来?
在高并发海量数据场景下,数据实时分析、批处理、预计算都有着极其重要的意义。