




又是一年总结时,每年这个时候都是一个让人期盼的时候,此时我们可以放下思想包袱思考这一年自己都做了什么,有什么收获,对未来有怎样的憧憬,回首过往,是充实还是虚度?是时候给自己一个交代了。2022年,而我正式从一个技术人员转型为售前,但依然对技术充满着热爱,感谢这个平台能让自己有机会把最后一次的技术经验做分享,希望为同道中人提供参考,我分享的主题是基于国产化环境的金融级业务系统性能优化实践。
项目是一个金融级的业务系统,架构是基于微服务设计理念的分布式架构,环境上支持国产化软硬件、操作系统以及分布式数据库,具有高性能、低成本、弹性扩展、敏捷交付等特点,有效解决传统架构的性能瓶颈。系统从应用架构上构建了完善的业务中台能力,真正做到系统解耦,支持对业务服务场景进行整合重构,为产品创新和服务创新提供强有力的支撑。 系统总体架构设计如下所示:
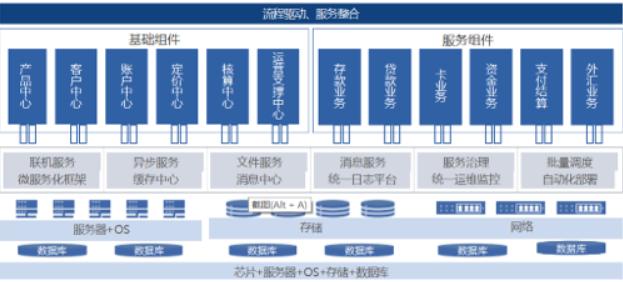
- 底层芯片采用国内主流ARM路线的CPU;
- 操作系统采用国产Kylin操作系统;
- 数据库采用国产分布式数据库,QianBase; QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续产品SeaQuest。SeaQuest将Neoview从其专有的硬件,和专有的NonStop OS操作系统中移植到通用的x86服务器和通用的Linux操作系统上。2014年,乘着大数据的浪潮,SeaQuest将底层的数据存储和访问引擎移植到HBase/Hadoop上,并创新地开发出HBase分布式事务处理等新技术,从而推出了Trafodion,并将全部代码开源,贡献给社区。
应客户的要求,为了能够让业务系统在国产化环境下性能达到最优,对系统从硬件到软件做了全方位的性能优化,包括BIOS、OS、DB以及应用等。
性能是指操作系统完成任务时的有效性、稳定性和响应速度。Linux平台经常会遇到系统不稳定、响应速度慢等问题,操作系统完成一个任务时,与硬件配置、系统配置、网络拓朴结构、路由设备、路由策略、接入设备、物理线路等多个方面都密切相关,任何一个环节出现问题,都会影响整个系统的性能。因此当应用出现问题时,应当从应用程序、操作系统、服务器硬件、网络环境等方面综合排查,定位问题出现在哪个部分,然后集中解决。
在服务器硬件、操作系统、应用程序、网络环境等方面,影响性能最大的是应用程序和操作系统两个方面,因为这两个方面出现的问题不易察觉,隐蔽性很强。而硬件、网络方面只要出现问题,一般都能马上定位。以下是性能优化的一些路径:
l CPU层面:尽可能提升cpu的使用效率、提升NUMA节点和内存数据的命中率、尽量减少CPU中断和上下文切换。
l 内存层面:尽可能提升内存数据命中率和访存速率、NUMA节点内CPU核心尽可能访存节点内内存数据。
l 磁盘层面:提升磁盘IO吞吐率、读写密集型业务尽可能IO分流。
l 网络层面:提升网络IO速率、尽量减少不必要的网络数据传输。
l 应用层面:提升线程并发数,充分利用CPU的多核特点,降低热点资源竞争、减少或避免锁、微服务化、分布式架构。
系统优化的基本过程:
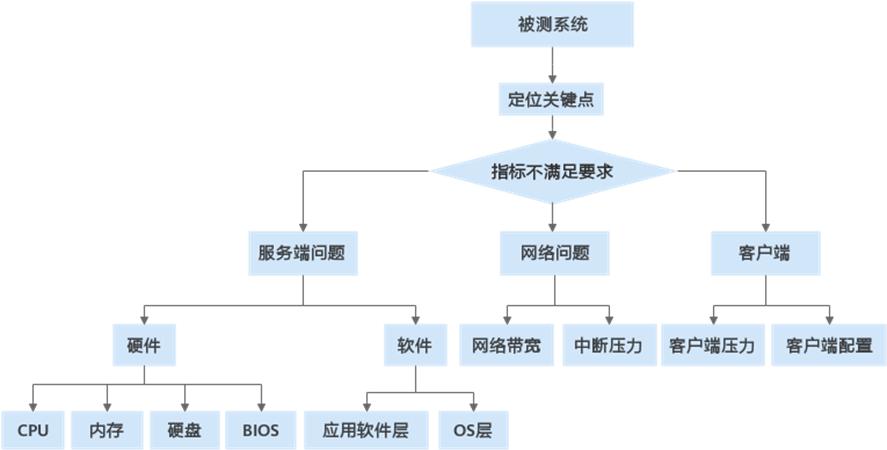
在应用系统优化前,需要设定一个预期目标值,例如:基于多少应用服务器、多少数据库服务器进行部署,要求最终的TPS,然后按照此目标对OS、DB、应用进行优化。
l CPU优化:
定时机制调整
sysctl –w kernel.timer_migration=0;禁止时钟迁移;
sysctl –w kernel.numa_balancing=0;关闭numa自动负载均衡;
配合实时补丁(GIC-ITS内核实时性补丁),避免cpu中断过多,绑核后,关闭自动numa负载均衡。
l 内存优化:
- 关闭swap
Swapoff关闭swap分区。(物理内存充足的情况,不需要swap进行缓存)。
Swap分区状态查询:
 关闭swap,命令 swapoff:
关闭swap,命令 swapoff:

- 内存页优化 TLB(Translation lookaside buffer)为页表(存放虚拟地址的页地址和物理地址的页地址的映射关系)在CPU内部的高速缓存简称页表缓存。TLB的命中率越高,页表查询性能就越好。 TLB的一行为一个页的映射关系,也就是管理了一个页大小的内存:TLB管理的内存大小 = TLB行数 x 内存的页大小 同一个CPU的TLB行数固定,因此内存页越大,管理的内存越大,相同业务场景下的TLB命中率就越高。
修改前后可以通过如下命令观察TLB的命中率($PID为进程ID):
# perf stat -p $PID -d -d -d
输出结果包含如下信息,其中1.21%和0.59%分别表示数据的miss率和指令的miss率。
1,090,788,717 dTLB-loads # 520.592 M/sec
13,213,603 dTLB-load-misses # 1.21% of all dTLB cache hits
669,485,765 iTLB-loads # 319.520 M/sec
3,979,246 iTLB-load-misses # 0.59% of all iTLB cache hits
- 内核内存页优化
# getconf PAGESIZE
修改linux内核的内存页大小,需要在修改内核编译选项后重新编译内核,简要步骤:
(1)执行make menuconfig
(2)在源码(/usr/src/)目录键入
# make menuconfig ARCH=arm 后出现上面menu:(menuconfig主界面)选择PAGESIZE大小为64K
Kernel Features-->Page size(64KB)
(3)编译和安装内核
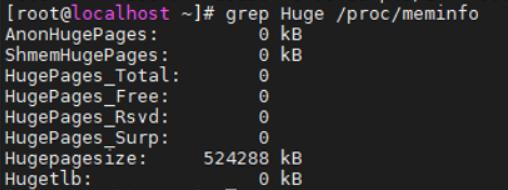
- hugepage优化
echo never > /sys/kernel/mm/transparent_hugepage/enabled ;关闭透明大页,提高物理内存访问量。
效果如下所示:
l 磁盘I/O优化:
CPU的缓存、内存和磁盘之间的访问速度逐级数量级递减,当CPU计算所需要的数据并没有读取到缓存或者内存中时,就需要从磁盘读取,会导致进程出现数据等待,影响计算效率。所以IO子系统优化最主要的目的就是减少CPU计算数据从磁盘读取的等待事件,从而提升计算效率。一般情况扩展提升缓存、内存、磁盘的效率等是一些常见手段;另外也可以从计算数据的读取规律层面进行优化,如:开启数据库预读等特性,降低磁盘IO等待。
- 调整磁盘文件预读参数 文件预取的原理,就是根据局部性原理,在读取数据时,会多读一定量的相邻数据缓存到内存。如果预读的数据是后续会使用的数据,那么系统性能会提升,如果后续不使用,就浪费了磁盘带宽。在磁盘顺序读的场景下,调大预取值效果会尤其明显。
文件预取参数由文件read_ahead_kb指定,通过命令来查找。
# find / -name read_ahead_kb
此参数的默认值128KB,可使用echo来调整,将预取值调整为4096KB:
# echo 4096 > /sys/block/sda/queue/read_ahead_kb
- 磁盘IO调度方式优化 文件系统在通过驱动读写磁盘时,不会立即将读写请求发送给驱动,而是延迟执行, 这样Linux内核的I/O调度器可以将多个读写请求合并为一个请求或者排序(减少机械磁盘的寻址)发送给驱动,提升性能。
目前Linux版本主要支持3种调度机制:
-
CFQ,完全公平队列调度 早期Linux内核的默认调度算法,它给每个进程分配一个调度队列,默认以时间片和请求数限定的方式分配IO资源,以此保证每个进程的IO资源占用是公平的。这个算法在IO压力大,且IO主要集中在某几个进程的时候,性能不太友好。
-
DeadLine,最终期限调度 这个调度算法维护了4个队列,读队列,写队列,超时读队列和超时写队列。当内核收到一个新请求时,如果能合并就合并,如果不能合并,就会尝试排序。如果既不能合并,也没有合适的位置插入,就放到读或写队列的最后。一定时间后, I/O调度器会将读或写队列的请求分别放到超时读队列或者超时写队列。这个算法并不限制每个进程的IO资源,适合IO压力大且IO集中在某几个进程的场景,比如大数据、数据库使用HDD磁盘的场景。
3.NOOP,也叫NONE,是一种简单的FIFO调度策略。
因为固态硬盘支持随机读写,所以固态硬盘可以选择这总最简单的调度策略,性能最好。
修改方式:
cat /sys/block/sdg/queue/scheduler
 修改方法:
修改方法:
echo mq-deadline> /sys/block/sdg/queue/scheduler
l 应用优化:
应用优化主要是针对JVM的优化调整。JVM包括即时编译(JIT)、内存管理(垃圾回收GC技术)和Runtime技术,其中堆栈管理、线程锁、热点资源竞争、GC管理是性能调优中最为常见的关注点。
- 优化建议 根据实际业务需求和硬件资源给JVM选择合理的堆栈空间配置,建议进行多轮测试验证后敲定一套JVM内存使用参数,可以达到更好的效果。最后要选择合理的GC算法,合理的GC算法可以有效提升CPU和内存的操作效率,从而提升Java应用的性能。合理的JVM参数需要经过多轮的验证测试,逐个实验,从而达到最佳效率。
- 优化参数
-XX:CMSInitiatingPermOccupancyFraction:当永久区占用率达到这一百分比时,启动CMS回收
-XX:CMSInitiatingOccupancyFraction:设置CMS收集器在老年代空间被使用多少后触发
-XX:+CMSClassUnloadingEnabled:允许对类元数据进行回收
-XX:CMSFullGCsBeforeCompaction:设定进行多少次CMS垃圾回收后,进行一次内存压缩
-XX:NewRatio:新生代和老年代的比
-XX:ParallelCMSThreads:设定CMS的线程数量
-XX:ParallelGCThreads:设置用于垃圾回收的线程数
-XX:SurvivorRatio:设置eden区大小和survivior区大小的比例
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :新生代使用并行回收收集器
-XX:+UseParallelOldGC:老年代使用并行回收收集器
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串行收集器
-XX:+UseCMSCompactAtFullCollection:设置CMS收集器在完成垃圾收集后是否要进行一次内存碎片的整理
-XX:UseCMSInitiatingOccupancyOnly:表示只在到达阀值的时候,才进行CMS回收
-Xms:** **设置堆的最小空间大小。
-Xmx:** **设置堆的最大空间大小。
-XX:NewSize** **设置新生代最小空间大小。
-XX:MaxNewSize** **设置新生代最大空间大小。
-XX:PermSize** **设置永久代最小空间大小。
-XX:MaxPermSize** **设置永久代最大空间大小。
-Xss:** **设置每个线程的堆栈大小。
-XX:NewRatio设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
除了调整JVM之外,为了是系统发挥出最大性能,这里还将CPU与数据库实现了绑核优化,具体调整如下:
Ø 应用绑核:每一个服务绑0-15核,每个微服务各启了1个实例,绑核时候要通过localaloc设置内存亲和性。
Ø 数据库绑核:数据库绑核,hbase numa14.5--lotalalloc,mxosrvr numa 2.3.6-153替换核心应用为0210版,绑核时候要通过localaloc设置内存亲和性。
Ø 更换主备网卡,改变中断绑核方式。
Ø 打开tuned服务,更换network-latency。
Ø 关闭nohz,减少IO的延时波动。
Ø 升级内核,修改grub参数
Ø 数据库升级为服务器编译版本
Ø 使用isolcpus参数进行核隔离
Ø 修改内存页避免cache miss
Ø 定时器迁移
sysctl –w kernel.timer_migration=0
sysctl –w kernel.numa_balancing=0
Ø 使用GIC-ITS内核实时性补丁
经过多轮的性能测试,优化效果如下:
- 单笔交易性能 单交易性能的调优分为绑核系统调优和面向IO性能调优两个方向,经过优化后,TPS从最初的1000并发4200上升到5400.
- 磁盘I/O情况 对于网络IO性能问题,更换为mellanox网卡,不再有PCIE降速问题,netperf测试数据提升30%。
- 稳定性测试 在长时间压力测试下,服务器经常出现假死状态,经过对CPU进行NUMA绑核,避免跨路,更新QOS固件增加硬件环境稳定性,假死现象得以解决。
做过优化的技术同仁一定都知道优化系统的痛苦,在优化过程中会遇到很多困难,比如说系统环境问题,性能问题的定位,参数的设置等等,需要优化人员具备敏锐的嗅觉,可以从繁杂的环境中快速定位问题所在,并给出合理的解决方案。虽然过程很痛苦,但是优化的结果会让人有很大的成就感。最后,希望本次分享可以帮助到有需要的人,我为人人,人人为我!