


点击上方蓝字关注我们
一、Quivr介绍
Quivr可以帮助把你的本地文件向量化,然后存储到云端,随时可以查询对话。文档格式支持Text、Markdown、 PDF、音频和视频。GPT端支持ChatGPT-3/4和Claude。向量数据库使用的是Supabase ,音视频是基于Whisper的API处理成文本的,主要语言是Python开发。
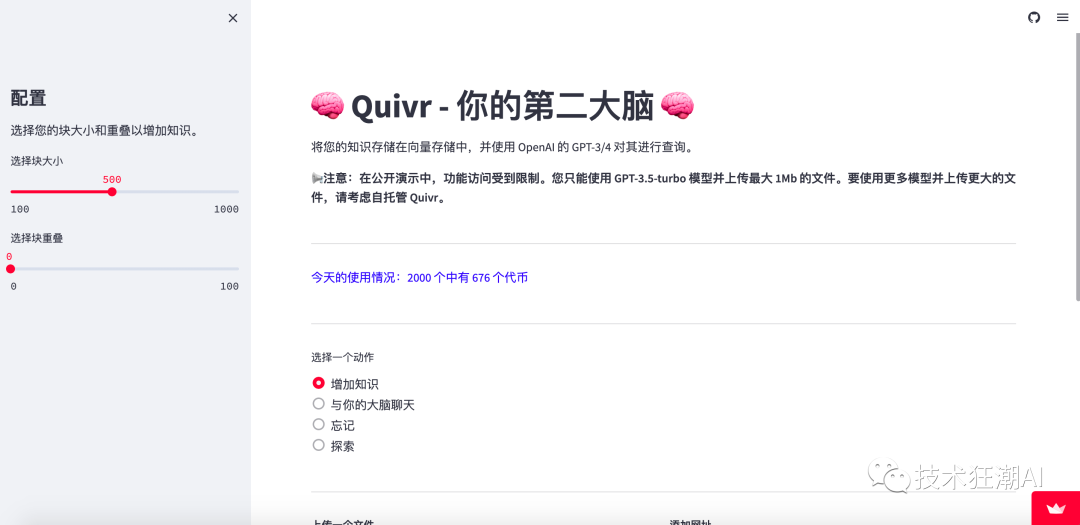
Quivr可以将我们的本地文件存储在向量数据库中,然后存储到云端,随时可以查询对话。使用 OpenAI 的 GPT-3/4 或者Claude 100k对其进行查询。
Quivr是一个功能强大而高效的数据管理工具。它可以轻松地处理各种类型的数据,无论是文本、图像还是代码片段等等。
Quivr兼容多种文件格式,包括文本、Markdown、PDF、Powerpoint、Excel、Word、音频和视频,使其成为一个非常适合多样化需求的数据管理工具。
Quivr采用先进的人工智能技术,可帮助您生成和检索信息,让您的数据管理更加智能和高效。这款设计迅捷高效的工具确保您在访问和使用数据时得到最快的响应速度。Quivr的速度和效率会在日常工作中让您受益无穷。
您的数据始终处于您的掌控之下,Quivr保证您的数据安全性,让您放心使用。
此外,Quivr开源且免费使用,让您更加自由地使用这个优秀的工具。
项目地址:https://github.com/StanGirard/quivr
📢注意:在公开的演示系统中,因为功能访问受到限制。只能使用 GPT-3.5-turbo 模型并上传最大 1Mb 的文件。如果需要使用更多模型并上传更大的文件,需要自行部署 Quivr托管。
二、Quivr特性
- 存储任何文件: Quivr可以处理几乎所有类型的数据。文本、图像、代码片段等等,您只需要说出来。
- 生成式人工智能 :Quivr使用先进的人工智能技术来帮助您生成和检索信息。
- 快速高效 :Quivr专为速度和效率而设计,以确保您能够尽快访问自己的数据。
- 安全可靠 :您的数据始终在您的控制下。
- 兼容文件格式 :TXT、CSV、MD、MARKDOWN、M4A、MP3、WEBM、MP4、MPGA、WAV、MPEG、PDF、HTML、PPTX、DOCX(每个文件限制200M)
- 开源免费 :Quivr是开源的,并且可以免费使用。
三、Quivr演示
接下来我们会基于GPT-3.5、GPT-4、Claude 100K三种GPT模型来演示Quivr上传本地文件到向量数据库并及时进行文本内容检索。
3.1、基于GPT-3.5模型演示

3.2、基于GPT-4模型演示
3.3、基于Claude 100k context模型演示
四、Quivr部署
4.1、前提条件
在继续部署之前,请确保已安装以下内容:
您还需要
Supabase
账户,以获得以下内容:
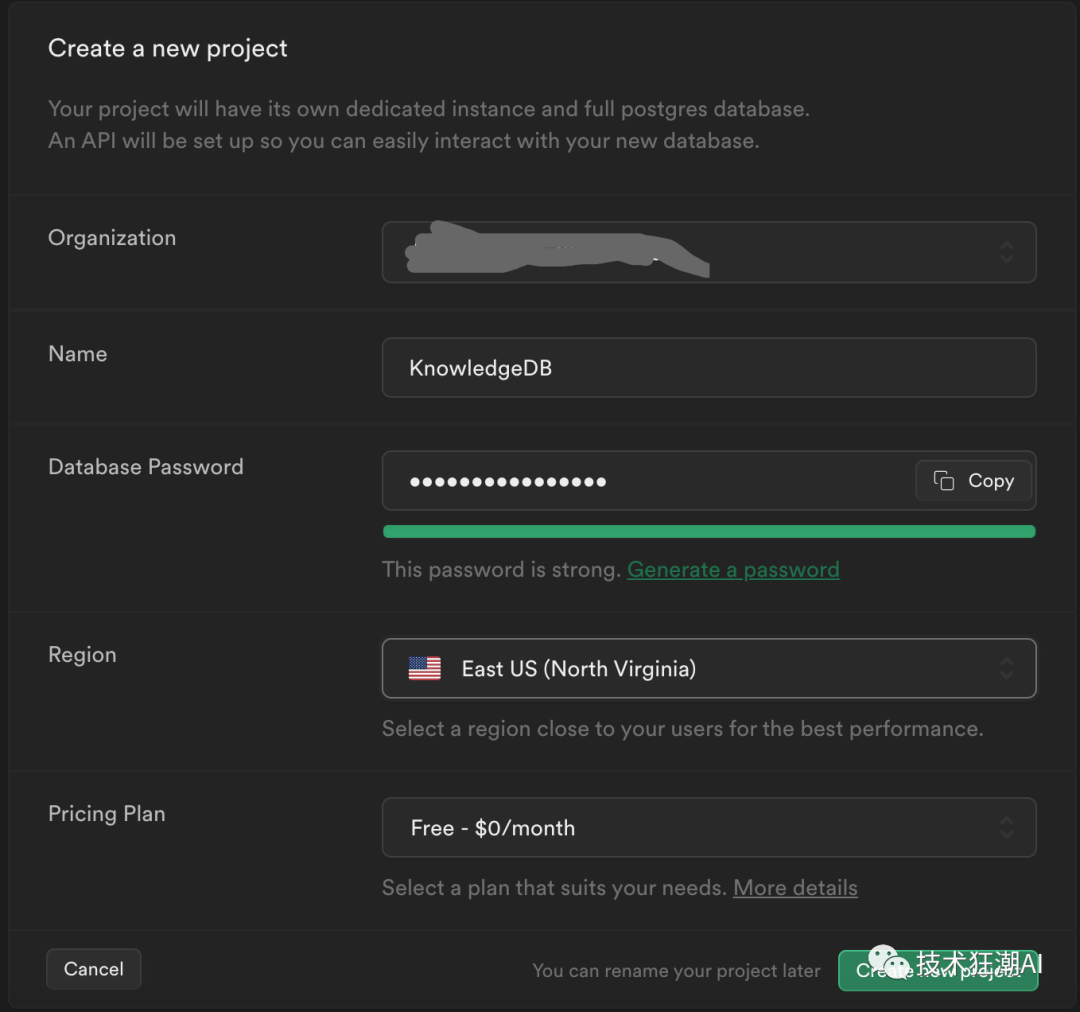
- Supabase项目API密钥
- Supabase项目URL
4.2、安装Quivr
4.2.1、克隆存储库
git clone git@github.com:StanGirard/Quivr.git && cd Quivr
- 因为包含隐藏文件,可以使用 ls -alh 命令查看所有文件
4.2.2、复制
.XXXXX\_env
文件
cp .backend_env.example backend/.env
cp .frontend_env.example frontend/.env
4.2.3、更新
frontend/.env
文件
NEXT_PUBLIC_ENV=local
NEXT_PUBLIC_BACKEND_URL=http://localhost:5050
NEXT_PUBLIC_SUPABASE_URL="XXXXXX"
NEXT_PUBLIC_SUPABASE_ANON_KEY="XXXXXXX"
4.2.4、更新
backend/.env
文件
SUPABASE_URL=XXXXX
SUPABASE_SERVICE_KEY=eyXXXXX
OPENAI_API_KEY=sk-XXXXXX
ANTHROPIC_API_KEY=XXXXXX
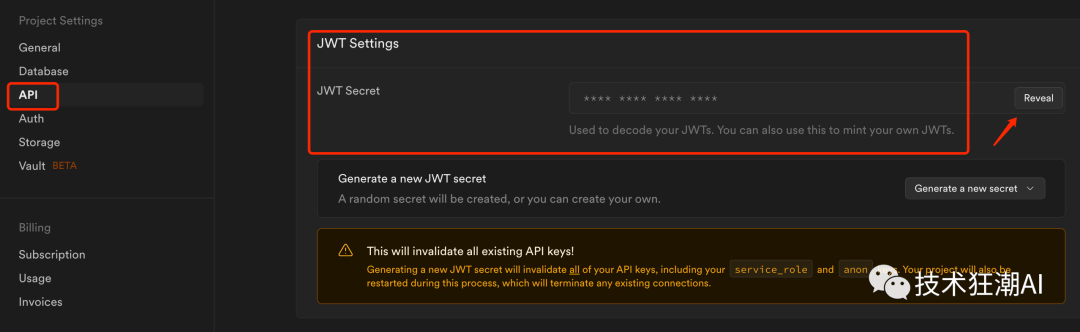
JWT_SECRET_KEY=Found in Supabase settings in the API tab
AUTHENTICATE="true"
请注意,supabase_url在您的Supabase仪表板下的项目设置-> API中对应的Project URL,supabase\_service\_key在您的Supabase仪表板下的项目设置-> API中找到。使用“Project API keys”部分中找到的anon public键。您 JWT\_SECRET\_KEY可以在 Project Settings -> JWT Settings -> JWT Secret 下的 supabase 设置中找到。

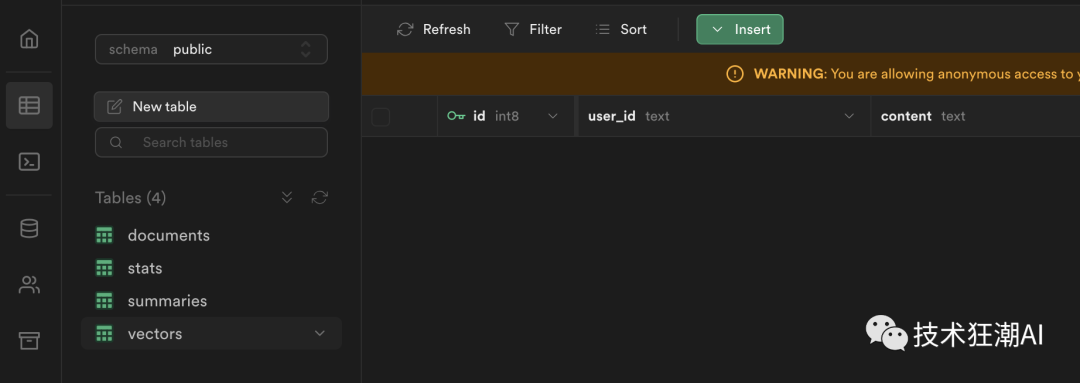
4.2.5、创建Supabase数据库和表
通过Web界面(SQL编辑器->“新查询”)在Supabase数据库上运行以下迁移脚本

create extension if not exists vector;
create table if not exists vectors (
id bigserial primary key,
user_id text,
content text,
metadata jsonb,
embedding vector(1536)
);
CREATE OR REPLACE FUNCTION match_vectors(query_embedding vector(1536), match_count int, p_user_id text)
RETURNS TABLE(
id bigint,
user_id text,
content text,
metadata jsonb,
embedding vector(1536),
similarity float)
LANGUAGE plpgsql
AS $$
# variable_conflict use_column
BEGIN
RETURN query
SELECT
id,
user_id,
content,
metadata,
embedding,
1 -(vectors.embedding <=> query_embedding) AS similarity
FROM
vectors
WHERE vectors.user_id = p_user_id
ORDER BY
vectors.embedding <=> query_embedding
LIMIT match_count;
END;
$$;
create table
stats (
-- A column called "time" with data type "timestamp"
time timestamp,
-- A column called "details" with data type "text"
chat boolean,
embedding boolean,
details text,
metadata jsonb,
-- An "integer" primary key column called "id" that is generated always as identity
id integer primary key generated always as identity
);
-- Create a table to store your summaries
create table if not exists summaries (
id bigserial primary key,
document_id bigint references vectors(id),
content text, -- corresponds to the summarized content
metadata jsonb, -- corresponds to Document.metadata
embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
);
CREATE OR REPLACE FUNCTION match_summaries(query_embedding vector(1536), match_count int, match_threshold float)
RETURNS TABLE(
id bigint,
document_id bigint,
content text,
metadata jsonb,
-- we return matched vectors to enable maximal marginal relevance searches
embedding vector(1536),
similarity float)
LANGUAGE plpgsql
AS $$
# variable_conflict use_column
BEGIN
RETURN query
SELECT
id,
document_id,
content,
metadata,
embedding,
1 -(summaries.embedding <=> query_embedding) AS similarity
FROM
summaries
WHERE 1 - (summaries.embedding <=> query_embedding) > match_threshold
ORDER BY
summaries.embedding <=> query_embedding
LIMIT match_count;
END;
####
**4.2.6、构建并启动Quivr**
为了构建依赖更快一点,我们可以使用阿里云的镜像源进行下载,需要修改前后端项目中的Dockfile文件
如果你在国内使用pip安装缓慢,可以考虑切换至阿里的源:pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
镜像同步版本可能不及时,如果出现这种情况建议切换至官方源:pip config set global.index-url https://pypi.org/simple
* **修改backend/Dockerfile文件:**
FROM python:3.11
EXPOSE 5050/tcp
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt --timeout 100 -i https://mirrors.aliyun.com/pypi/simple/
COPY . /code/
CMD ["uvicorn", "api:app", "--reload", "--host", "0.0.0.0", "--port", "5050"]
* **`修改frontend/Dockerfile文件:`**
FROM node:18-alpine
# 将 apk 安装包源替换为阿里云镜像源
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories
# 配置 pip 镜像源
RUN mkdir ~/.pip && echo '[global]\nindex-url = https://mirrors.aliyun.com/pypi/simple/\n' > ~/.pip/pip.conf
# Install Python and essential build tools
RUN apk add --update --no-cache python3 make g++ && ln -sf python3 /usr/bin/python
RUN python3 -m ensurepip
RUN pip3 install --no-cache --upgrade pip setuptools
# Create the directory on the node image
# where our Next.js app will live
RUN mkdir -p /app
# Set /app as the working directory
WORKDIR /app
# Copy package.json and package-lock.json
# to the /app working directory
COPY package*.json ./
# Install dependencies in /app
RUN yarn config set registry https://registry.npm.taobao.org && yarn install
# Copy the rest of our Next.js folder into /app
COPY . .
# Ensure port 3000 is accessible to our system
EXPOSE 3000
# Run yarn dev, as we would via the command line
CMD ["yarn", "dev"]
如果部署在Linux服务器上,需要在服务器上打开代理才行调用OpenAI的接口
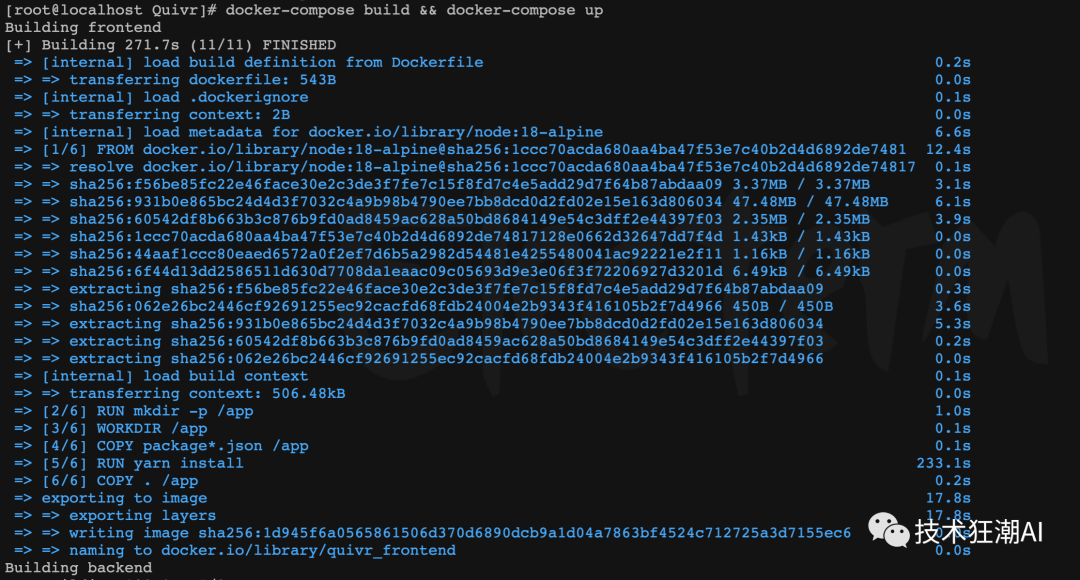
修改了前后端的Docker容器构建脚本后,开始执行下面的构建脚本
docker-compose build && docker-compose up
如果出现如下界面展示情况,构建过程没有出现错误,代表项目顺利部署完成。

####
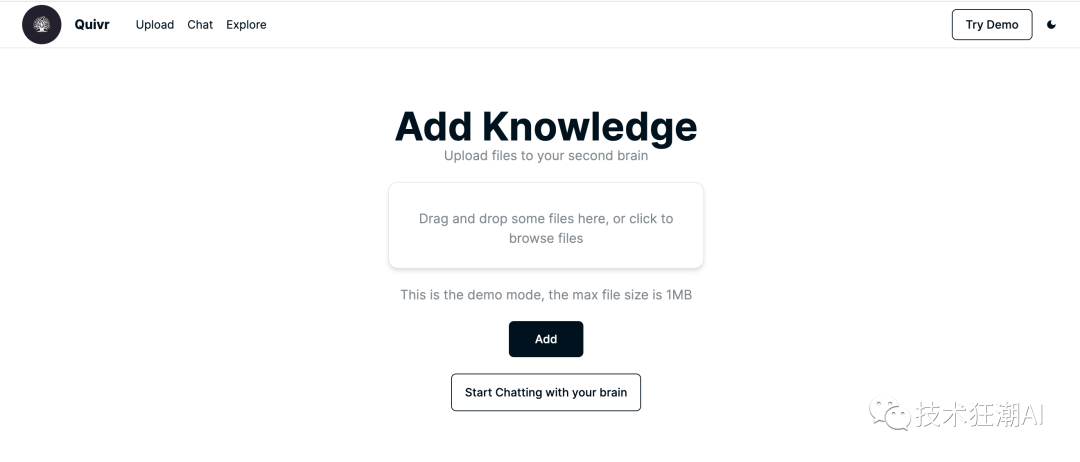
**4.2.7、访问Quivr**
启动成功后在浏览器直接访问3000端口,可以看到项目主页:
***五、实现原理***
Quivr兼容多种文件格式,包括文本、Markdown、PDF、Powerpoint、Excel、Word、音频和视频,使其成为一个非常适合多样化需求的数据管理工具。
###
5.1、文件加载器(计算元数据)

例如上传Markdown文件时会调用Markdown Loader。( **使用LangChainAI实现** )
1、加载 Markdown
2 - 计算文件的 SHA1
3 - 添加 SHA1 作为元数据
4 - 添加到Supabase vectorstore ,下次如果文件具有相同的 SHA1 则不会上传 😎

###
5.2、文件存储(拆分&向量化)

###
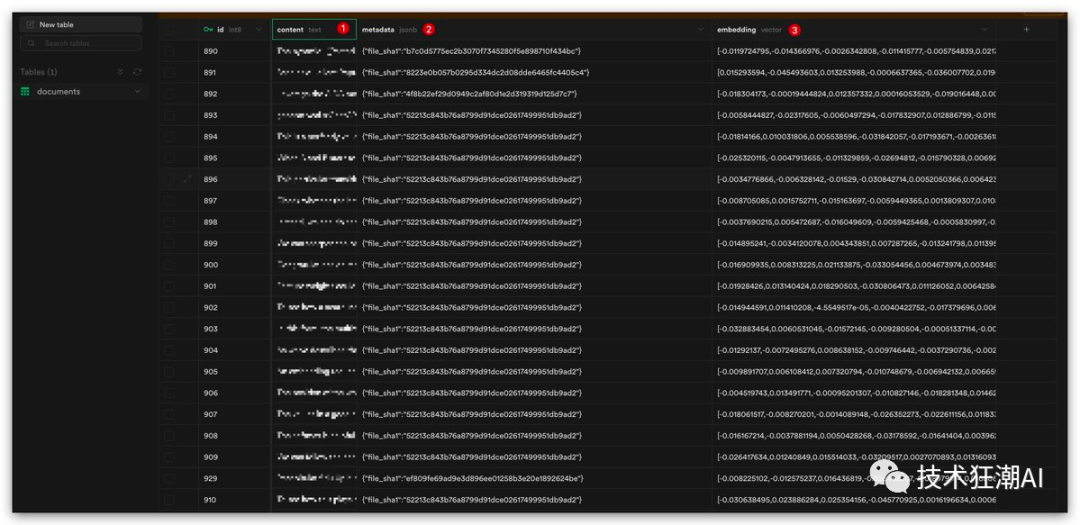
然后将文档拆分并存储到Supabase vectorstore中,存储的主要信息包括:
1 - 它是文件的内容
2 - 文件的元数据信息
3 - 使用OpenAI Embeddings来计算文件的向量值
###
5.3、重复文件校验

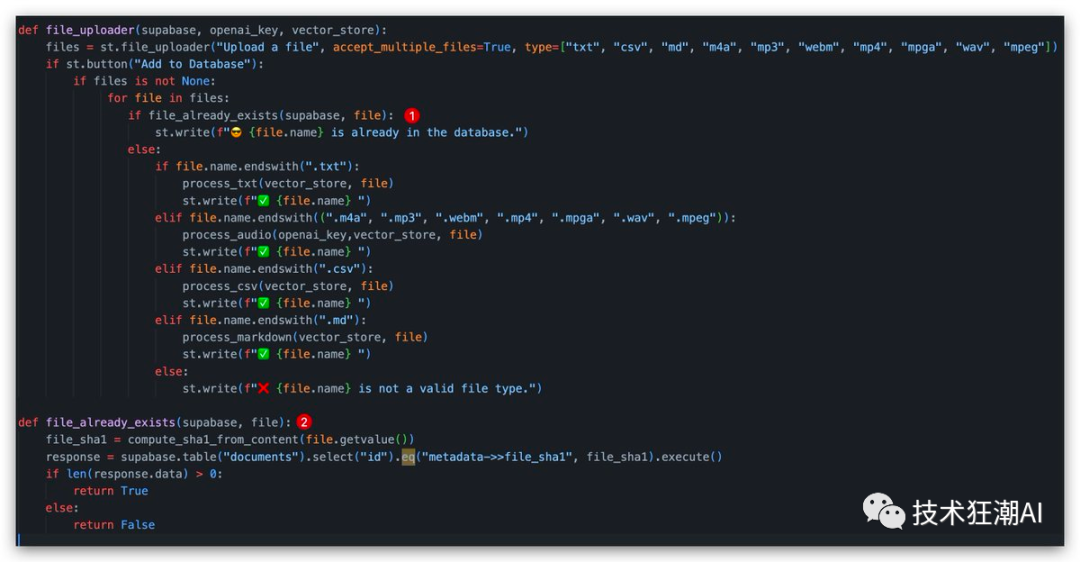
文件已经上传,每当上传新文件时:
1 - 通过计算文件 SHA1 来检查它是否已经存在
2 - 通过查询Supabase元数据列来检查它
5.4、模型选择

1 - 选择模型(GPT3.5 或 GPT4)
2 - 使用Supabase vectorstore 创建 CoversationalRetrievalChain
3 - 发送问题,然后在Streamlit中显示查询结果

###
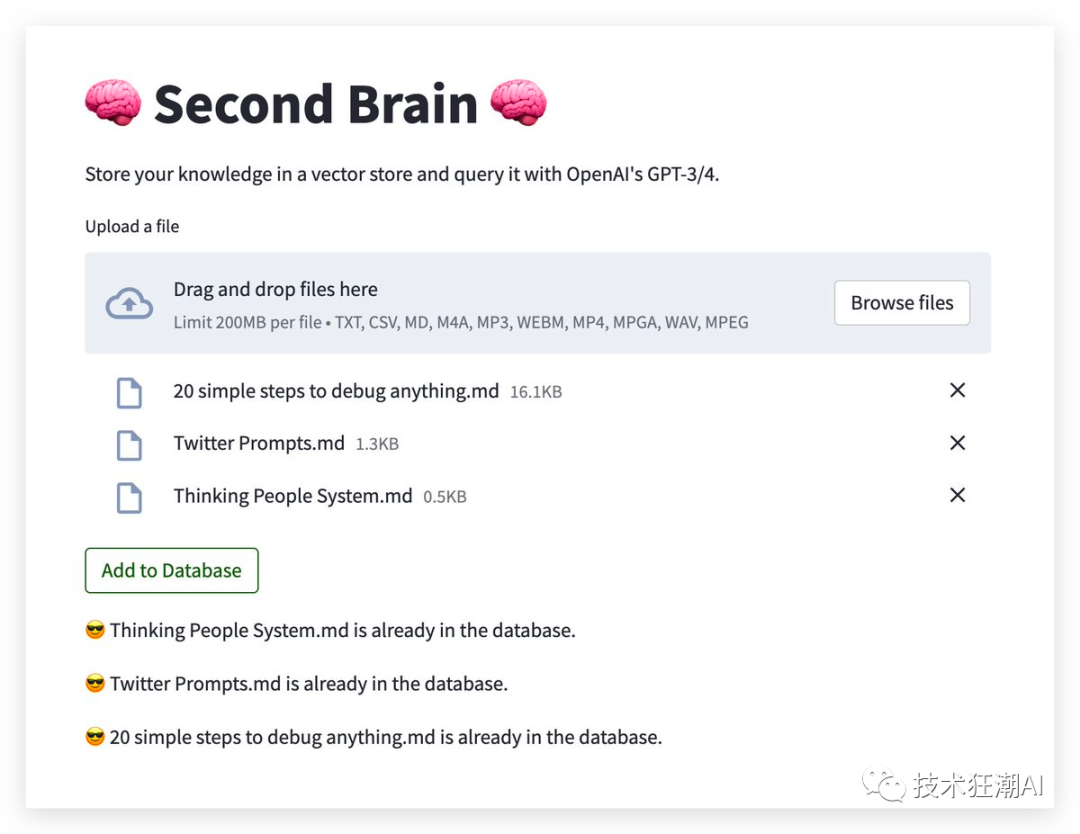
5.5、文件上传

现在我们可以上传文件,例如 Markdown,音频文件(将由 Whisper 转录为文本)后上传到Supabase中
###
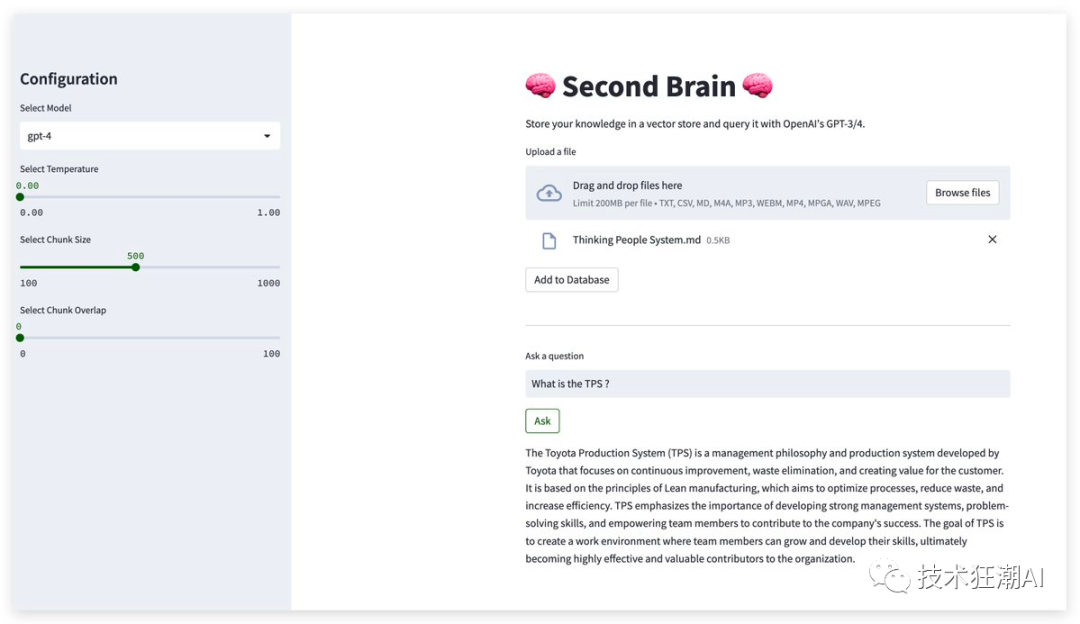
5.6、对话检索

最后使用OpenAI GPT4 或 GPT3.5 的接口查询
***六、FAQ***
###
6.1、安装Docker最新版(24.0.1)

###
不能低于17,否则会出现不支持
`--iidfile`
的错误,安装新版本需要先卸载老版本,具体可查阅官方文档:
https://docs.docker.com/engine/install/centos/
。
>
>
> `--iidfile`
> 标志是在 Docker 17.05 版本中引入的。因此,如果您使用的是 Docker 17.05 版本或更高版本,则应该支持
> `--iidfile`
> 标志。如果您使用的是旧版本的 Docker,则可能不支持
> `--iidfile`
> 标志。
>
>
####
**6.1.1、卸载旧版本**
旧版本的 Docker 名称为
`docker`
或
`docker-engine`
。在尝试安装新版本之前卸载任何此类旧版本以及相关的依赖项。
$ sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
`yum`
可能会报告您没有安装这些软件包。
当您卸载 Docker 时,存储在其中的图像、容器、卷和网络
`/var/lib/docker/`
不会自动删除。
####
**6.1.2、安装方法**
您可以根据需要以不同的方式安装 Docker Engine:
* 您可以 设置 Docker 的存储库并从中安装,以简化安装和升级任务。这是推荐的方法。
* 您可以下载 RPM 包并 手动安装并完全手动管理升级。这在诸如在无法访问 Internet 的气隙系统上安装 Docker 等情况下非常有用。
* 在测试和开发环境中,您可以使用自动化的
便捷脚本
来安装 Docker。
####
**6.1.3、使用 rpm 存储库安装**
在新主机上首次安装 Docker Engine 之前,您需要设置 Docker 存储库。之后,您可以从存储库安装和更新 Docker。
####
**6.1.4、设置存储库**
安装
`yum-utils`
包(提供
`yum-config-manager`
实用程序)并设置存储库。
$ sudo yum install -y yum-utils
$ sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
####
**6.1.5、安装 Docker 引擎**
1. 安装 Docker Engine、containerd 和 Docker Compose:
要安装最新版本,请运行:
$ sudo yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
如果提示接受 GPG 密钥,请验证指纹是否匹配
`060A 61C5 1B55 8A7F 742B 77AA C52F EB6B 621E 9F35`
,如果匹配,则接受。
此命令安装 Docker,但不会启动 Docker。它还会创建一个
`docker`
组,但是默认情况下不会向该组添加任何用户。
要安装特定版本,首先列出存储库中的可用版本:
$ yum list docker-ce --showduplicates | sort -r
docker-ce.x86\_64 3:24.0.0-1.el8 docker-ce-stable
docker-ce.x86\_64 3:23.0.6-1.el8 docker-ce-stable
<...>
返回的列表取决于启用了哪些存储库,并且特定于您的 CentOS 版本(
`.el8`
在此示例中由后缀表示)。
通过其完全限定的包名称安装特定版本,即包名称 (
`docker-ce`
) 加上版本字符串(第 2 列),由连字符 (
`-`
) 分隔。例如,
`docker-ce-3:24.0.0-1.el8`
。
替换
`<VERSION\_STRING>`
为所需的版本,然后运行以下命令进行安装:
$ sudo yum install docker-ce-<VERSION\_STRING> docker-ce-cli-<VERSION\_STRING> containerd.io docker-buildx-plugin docker-compose-plugin
此命令安装 Docker,但不会启动 Docker。它还会创建一个
`docker`
组,但是默认情况下不会向该组添加任何用户。
2. 启动Docker。
$ sudo systemctl start docker
3. 通过运行映像验证 Docker 引擎安装是否成功
`hello-world`
。
$ sudo docker run hello-world
此命令下载测试图像并在容器中运行它。当容器运行时,它会打印一条确认消息并退出。
您现在已经成功安装并启动了 Docker 引擎。
###
6.2、安装Docker Compose

###
>
>
> 请注意,Compose standalone 使用
> `-compose`
> 语法而不是当前的标准语法
> `compose`
> 。 例如,
> `docker-compose up`
> 在使用 Compose standalone 时键入,而不是
> `docker compose up`
> .
>
>
4. 要下载并安装独立的 Compose,请运行:
$ curl -SL https://github.com/docker/compose/releases/download/v2.18.1/docker-compose-linux-x86\_64 -o /usr/local/bin/docker-compose
5. 将可执行权限应用于安装目标路径中的独立二进制文件。
6. 使用测试和执行组合命令
`docker-compose`
。
如果安装后命令
`docker-compose`
失败,请检查您的路径。
`/usr/bin`
您还可以创建指向路径中任何其他目录的符号链接。例如:
$ sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
###
6.3、Python版本需要安装3.11版本

###
在 CentOS 中将 安装Python 3.11
* 首先,您需要安装 EPEL 存储库。EPEL 存储库包含许多额外的软件包,这些软件包不包含在 CentOS 的官方存储库中。您可以使用以下命令安装 EPEL 存储库:
sudo yum install epel-release
* 接下来,您需要安装一些必要的软件包和工具,以便编译 Python 3.11。您可以使用以下命令安装这些软件包:
sudo yum install gcc openssl-devel bzip2-devel libffi-devel zlib-devel wget
* 然后,您需要下载 Python 3.11 的源代码。您可以从 Python 官方网站下载最新版本的源代码,然后使用以下命令下载并解压缩源代码:
wget https://www.python.org/ftp/python/3.11.0/Python-3.11.0.tgz
tar xzf Python-3.11.0.tgz
* 接下来,进入解压缩后的 Python 源代码目录,并使用以下命令编译和安装 Python 3.11:
cd Python-3.11.0
./configure --enable-optimizations
make altinstall
注意,使用
`make altinstall`
命令而不是
`make install`
命令,这将确保您的系统上同时存在 Python 2.7 和 Python 3.11。
* 最后,您需要验证 Python 3.11 是否正确安装。您可以使用以下命令检查 Python 3.11 的版本:
python3.11 --version
如果您看到类似于以下内容的输出,则表示 Python 3.11 已经成功安装:
Python 3.11.0
请注意,升级 Python 版本可能会影响到系统的其他部分,因此请在操作之前备份您的系统,并确保您知道如何恢复到先前的状态。
###
6.4、回答总是用英文回复,如何支持中文回答更友好一点

###
因为项目默认使用的英文Prompt,所以导致回复都是采用英文回复,可以修改backend/llm/LANGUAGE\_PROMPT.py 文件中的英文Prompt即可。





