




前期多模态RAG的多个相关方案都提到:文档的布局结构对文档多模态RAG的性能有增益。 《开源多模态RAG的视觉文档(OCR-Free)检索增强生成方案-VDocRAG》、《【RAG&多模态】多模态RAG-ColPali:使用视觉语言模型实现高效的文档检索》、《【RAG&多模态】多模态RAG-VisRAG:基于视觉的检索增强生成在多模态文档上的应用》、也在多模态GraphRAG初探:文档智能+知识图谱+大模型结合范式讲解了pipline的多模态GraphRAG实现思路。
下面再看一个思路,围绕解决在视觉丰富文档(VRDs,如含图表、多页报告、幻灯片的PDF)理解 的缺陷:
- 丢失布局与结构上下文 :传统RAG将文档拆分为孤立块(如段落)嵌入,忽略跨页依赖(如“章节标题-后续内容”关联)和布局层级(如“图表-标题-注释”的视觉关联),易漏检关键证据。
- 过度依赖语义嵌入 :仅通过文本/图像嵌入的相似度检索,无法处理依赖 符号/结构线索 的查询(如“统计所有源自Pew研究中心的图表”)——这类查询需聚合“图表类型+来源标注”等显式结构信息,而嵌入无法捕捉此类细节。
- top-k检索 :固定检索数量(如top-5/10),不适应查询复杂度(例:“介绍3个组织”仅需3页,“统计荷兰位置图片”需12页),导致“证据不足”或“噪声过多”。
LAD-RAG 通过以下方式解决传统 RAG 在VRD 中的三个关键局限性:
二、LAD-RAG框架
LAD-RAG 框架流程:在信息摄取阶段,大型视觉语言模型从每页文档中提取要素并编码至索引系统,同时构建捕获页面间与页面内关联的文档关系图以支持符号检索。在推理阶段,智能体解析问题并循环交互神经网络索引与文档关系图,从而检索相关证据,实现问题感知与结构感知的双重检索机制。左:摄入阶段构建双索引;右:推理阶段LLM智能体动态检索
2.1、第一阶段:Ingestion
摄入阶段的目标是通过“视觉语言模型(LVLM)+运行内存”构建包含布局结构和跨页依赖的文档表示,最终输出“符号文档图”和“索引”。
2.1.1 核心步骤1:文档元素提取与Running Memory维护
为捕捉跨页上下文,LAD-RAG模拟人类阅读习惯(逐页理解+记忆累积),分两步处理文档:
- 文档逐页元素提取 :使用GPT-4o(强视觉语言模型)逐页解析VRD,提取页面中所有本地化元素 (如段落、图表、表格、章节标题、脚注),并为每个元素生成“自包含描述”(用于后续节点构建)。
每个元素需包含5类关键信息(为后续符号图节点属性做准备):
- 布局位置(如“左上”“页脚”);
- 元素类型(如“figure”“section_header”);
- 显示内容(文本、图表数据、表格数值);
- 自包含摘要(脱离上下文也可理解的描述,如“2023年美国移民意愿柱状图,对比公众与拉丁裔群体”);
- 视觉属性(字体、颜色、大小)。
- Running Memory(M)累积跨页信息
维护一个“动态记忆库”,类似人类阅读时的“持续理解”,逐页累积三类高-level信息:
- 章节结构(如“1. 引言 → 1.1 研究背景”的层级);
- 实体提及(如反复出现的“Pew研究中心”“大数据转型案例”);
- 主题进展(如“从‘问题提出’到‘案例分析’的逻辑流”)。
当处理新页面时,通过内存关联新元素与历史信息(如“新图表属于第2章案例分析”),为后续跨页边的构建提供依据。
2.1.2 核心步骤2:构建符号文档图(G)
符号文档图是将文档的“结构与布局关系"图的构成如下:
| 组成 | 具体设计 | 作用 | | --- | --- | --- | | 节点(Nodes) | 每个节点对应1个页面元素(如1个图表、1个段落),属性即3.1中提取的“布局位置、元素类型、摘要”等信息 | 实现“细粒度检索”(如仅检索所有“figure”节点) | | 边(Edges) | 连接节点的两类关系:
引用关系 (如“段落引用图表”“脚注引用章节”);
布局/结构关系 (如“元素属于同一章节”“跨页延续的附录内容”) | 捕捉跨元素/跨页依赖,支持“结构化检索”(如“找到附录A的所有延续页面”) |
边的构建依赖“运行内存”——例如,内存中记录“第22页‘附录A’是章节层级的叶子节点”,处理第23页时,通过内存识别“第23页内容是附录A的延续”,并建立“第22页附录节点→第23页附录节点”的“continues”边。
2.1.3 核心步骤3:神经-符号双索引存储
摄入阶段的最终输出是两类互补索引,为推理阶段的多模态检索提供基础:
- 符号索引(G) :即完整的文档图对象,存储节点/边的显式结构属性(如“元素类型=figure”“边类型=continues”),支持“基于规则的结构化查询”(如“筛选所有属于第3章且引用图表的段落”)。
- 神经索引(E) :对所有节点的“自包含摘要”进行向量嵌入(如用E5/BGE模型),构建向量数据库,支持“基于语义相似度的检索”(如“找到与‘大数据转型案例’语义相似的节点”)。
双索引避免传统RAG仅依赖嵌入的局限,也避免纯符号检索缺乏语义理解的问题。
相关提示词:
用于提取文档图结点的提示。
用于跨文档页面构建和更新运行记忆的提示。
用于文档图谱构建的摄取过程中所使用的提示
2.2、第二阶段:推理——LLM智能体动态检索证据
推理阶段的目标是通过LLM智能体(仍基于GPT-4o)动态交互双索引,根据查询需求自适应选择检索策略,直到收集到“完整且低噪声”的证据。
这里文章核心的介绍了LLM智能体与三大检索工具。
智能体的核心能力是“理解查询需求→选择检索工具→迭代优化证据集”,其可调用三类工具(对应不同检索场景):
| 工具名称 | 功能 | 适用场景 | | --- | --- | --- | | NeuroSemanticSearch | 向神经索引(E)发送查询,返回语义相似度最高的节点(如“检索‘大数据转型案例’相关节点”) | 查询依赖语义理解(无显式结构要求) | | SymbolicGraphQuery | 向符号索引(G)发送结构化查询,筛选符合属性/关系的节点(如“筛选所有‘type=figure’且‘属于第2章’的节点”) | 查询依赖结构/符号线索(如“统计特定来源的图表数量”) | | Contextualize | 输入1个节点,基于文档图的“社区检测”(Louvain算法)扩展其“结构邻近节点”(如“输入‘附录A’节点,扩展所有属于同一社区的附录延续节点”) | 需补充节点的上下文(如“找到与目标节点相关的所有章节内容”) |
社区检测细节 :Louvain算法会将文档图中“结构/语义高度关联的节点”聚类为“社区”(如“第3章的所有图表+段落+标题”构成一个社区),Contextualize工具通过调用社区信息,快速扩展出“完整的上下文证据”,避免漏检。
这一阶段提示词
实验性能
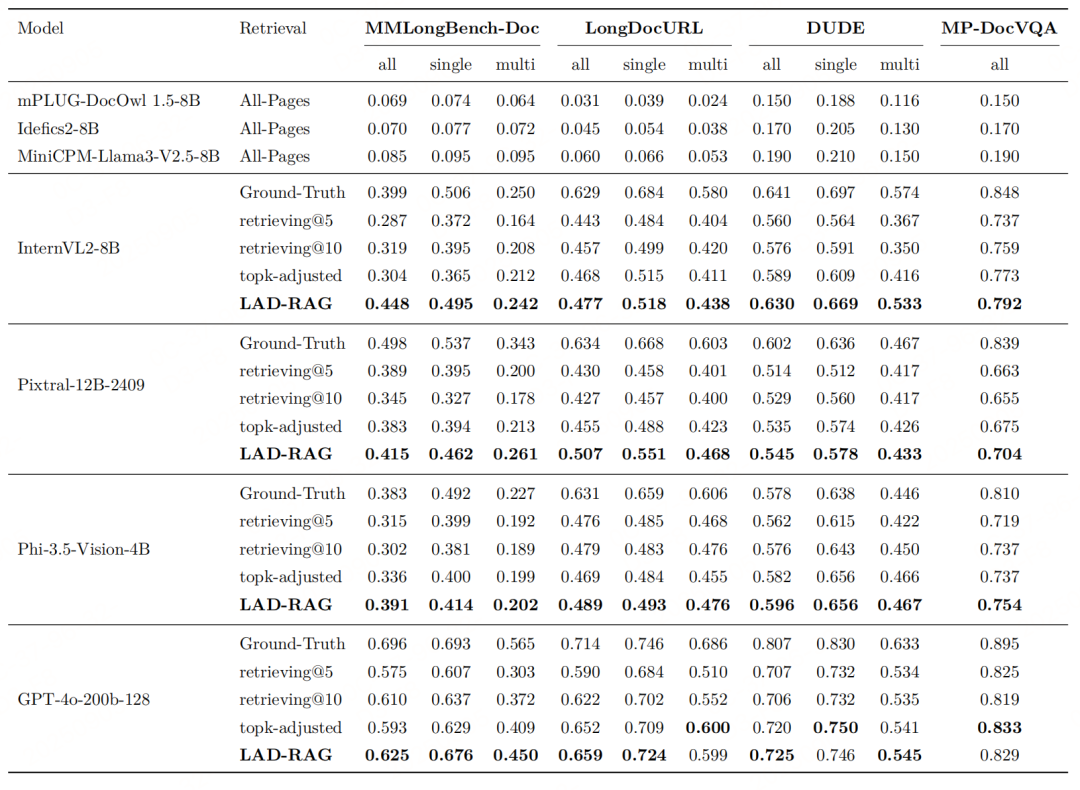
各模型在不同检索类型(经 topk 调整:证据数量与 LAD-RAG 相同)及 top-k 下的准确率得分。 单/多参考分别指需要单页或多页证据的问题。
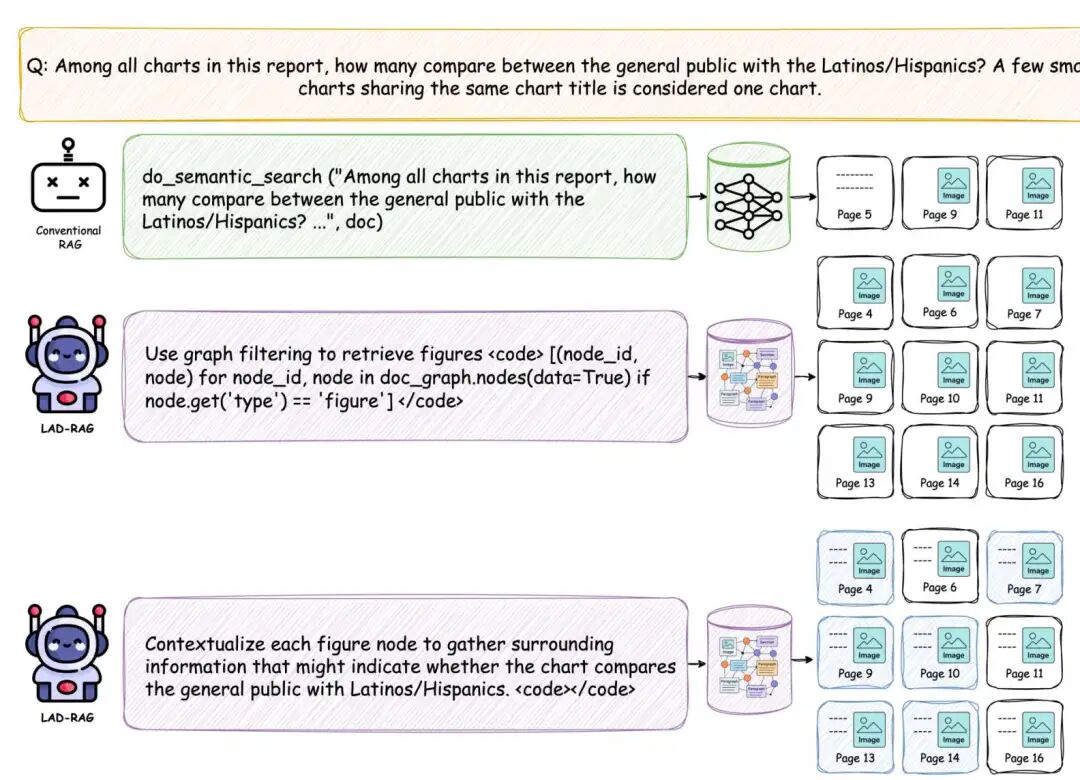
案例研究显示,LAD-RAG 成功检索出所有对比普通大众与拉丁裔/西班牙裔群体的图表。传统语 义检索器不仅遗漏大量相关图表,还会混入无关内容,而 LAD-RAG 则动态选择符号检索方案:先筛选 所有图形结点,再利用周边布局进行语境化分析,最终判定是否符合查询要求。这种基于图谱引导的多步 骤流程实现了精准且完备的证据收集。

案例研究展示 LAD-RAG 检索多页参考文献的过程。当语义搜索仅能定位参考文献首页时,因语义 重叠较弱而遗漏后续内容,LAD-RAG 动态切换至基于图形的上下文关联技术,成功恢复所有结构相关 的结点,实现完整证据覆盖。
MMLongBench-Doc 问答准确率细分。
在 LongDocURL 上的问答准确率细分
参考文献:LAD-RAG: Layout-aware Dynamic RAG for Visually-Rich Document Understanding,https://arxiv.org/pdf/2510.07233v1